一、前言
在生产环境中,业务对于mysql的需求存在两个不同层次的需求:一种是存小部分业务数据,低负载的访问,第一要求是数据的安全性;第二种是存大量业务数据,复杂业务查询场景。对于第二种需求,需要高性能的mysql集群加专业的数据库运维才能满足业务需求,类似于vitess这样的专门为大规模mysql集群辅助系统;对于第一种需求,考虑到业务需求和资源性价比,可以使用部署在Kubernetes的集群的mysql来提供服务。
考虑到数据库复杂的运维需求,使用Kubernetes operator模式是比较好的一个选择。在网站https://github.com/operator-framework/awesome-operators上列举了5个mysql operator:
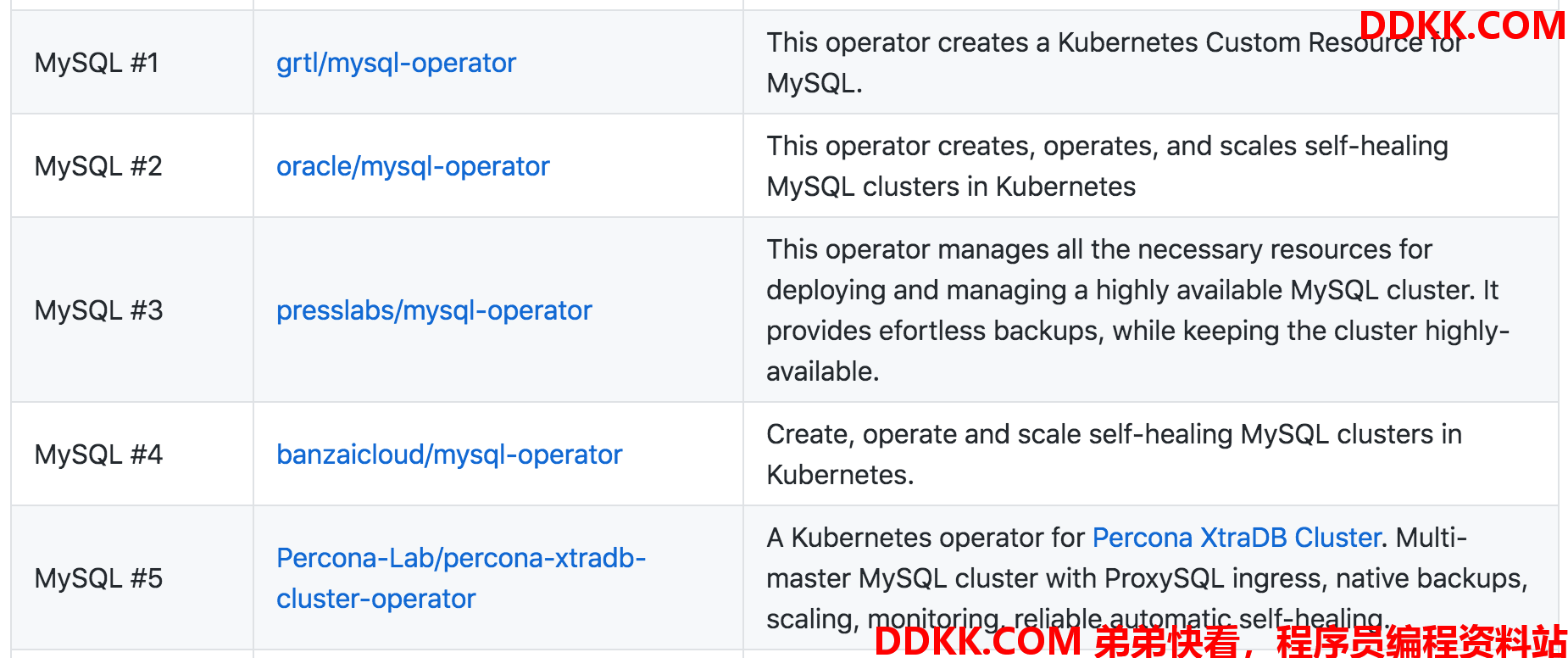
截止2020年5月为止,其中#1、#2、#4已经一年甚至两年以上都没有更新了,#3和#5还在正常更新中。其中#3是一主多从的模式,主从进行异步/半同步同步(可用性和分区容忍性,并不保证数据一致性),使用github的orchestrator进行选主和切换管理;而#5是使用多主模式,借助Galera Lib进行同步完整复制(强调数据一致性和可用性),使用ProxySQL进行ingress控制。
二、Presslabs Mysql Operator方案分析
2.1 方案架构
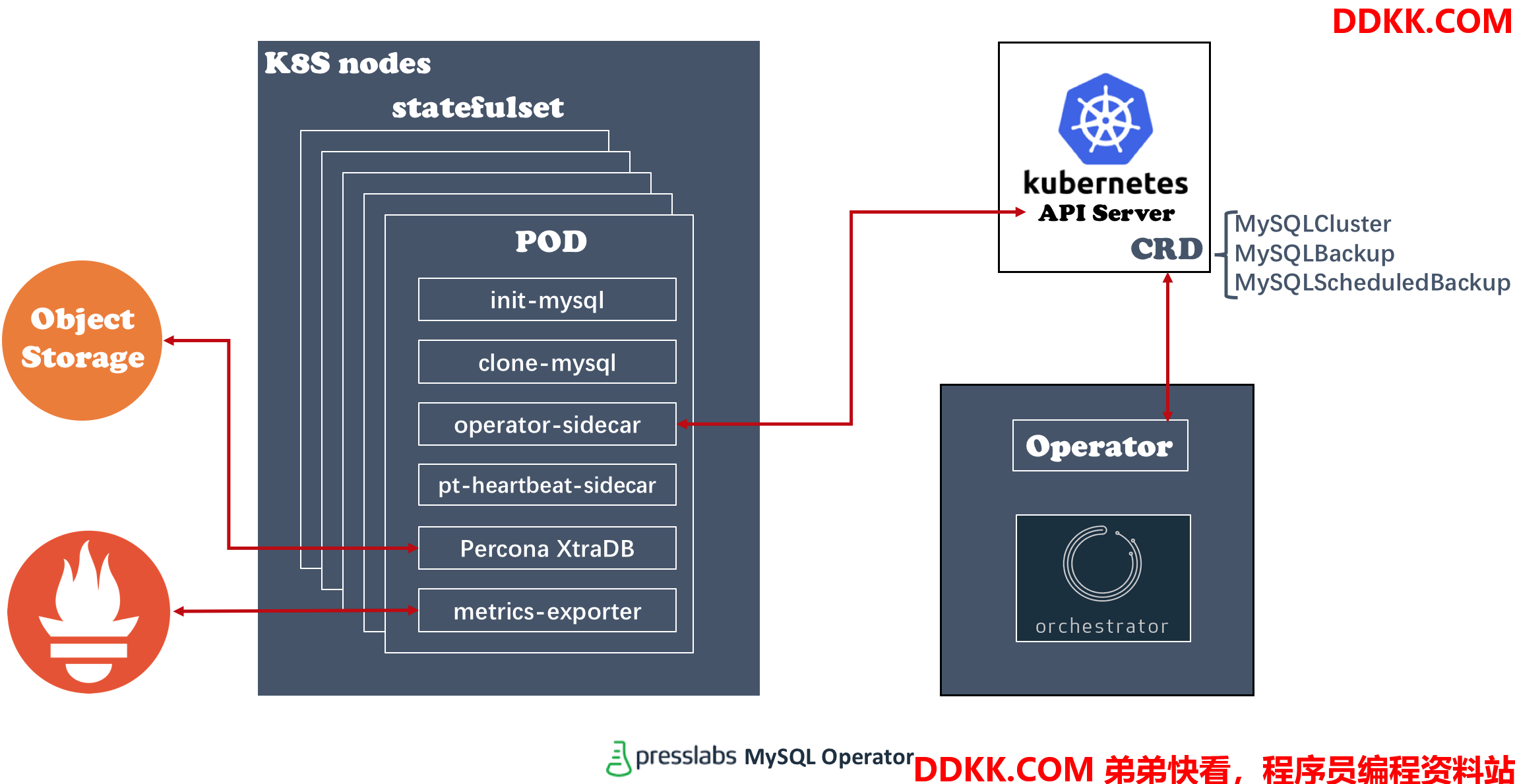 Presslabs MySQL Operator架构
Presslabs MySQL Operator架构
在presslabs的mysql operator方案中:
- 部署的MySQL Operator运行的POD由两个container组成:一个是operator container,用来响应CRD部署请求(包括创建集群、创建备份等动作:MySQLCluster、MySQLBackup、MySQLScheduledBackup);另一个是orchestrator container,用来管理mysql集群实例master的选举。
- Operator会响应MySQLCluster这个CRD的创建请求,建立一个statefulset,每个POD包含6个container(init-mysql、clone-mysql、operator-sidecar、pt-heartbeat-sidecar、metrics-exporter、Percona Container)。
- Percona DB的备份工作可以通过MySQLBackup或者MySQLScheduledBackup CRD进行,可以使用OSS作为备份的目的地。
- 每个POD直接运行了metrics的导出服务,可以直接使用promethes收集数据库的运行状态。
2.2 功能特点
这个mysql集群operator方案的特点如下:
- 异步/半同步复制
- 集群自愈
- 读高可用
- 一定条件下写高可用
- 自动发现和避免同步延迟
- 自动备份和恢复(现在备份支持通过access key备份到公有云Vendor的OSS,但是不支持PV等方式)
根据项目在github发布的v1.0 Roadmap,灵活配置备份策略、ProxySQL基础、MySQL8.0的支持、SSL支持等功能还在规划中。
 集群的异步复制方案
集群的异步复制方案
参考文档:
- https://github.com/presslabs/mysql-operator
- https://www.presslabs.com/news/mysql-deployments-kubernetes/
- https://lvee.org/en/abstracts/309
2.3 集群的HA方案
Presslabs MySQL Operator使用github维护的orchestrator进行集群的HA管理,它提供了如下功能:
- 服务发现:发现MySQL节点的基本信息,例如replication状态、配置情况等
- 拓扑重构:可以通过命令/UI进行快速的replication拓扑结构的编排,例如可以快速将一个slave mysql节点的复制来源从master改成另外一个slave
- 服务自愈:通过比较强大的算法和策略,保证服务的自愈,在github官网,开发者使用了“holistic”这个词表明了他们对这个功能的自信,并且号称要解决“false positives and false negatives”问题,很少HA系统敢哪怕声称要挑战这个问题,更不用说解决了
github声称除了代码和版本,其它的操作动作比如commit、issues、reviews、新建用户或者仓库等都是通过mysql进行持久化的。所以他们是重度依靠orchestrator进行mysql的HA保障的。当然,人家也说的很清楚,不同业务的HA需求是不一样的,比如他们在设计HA方案的时候,考虑的是如下一些问题,可以给大家一些启发(为了原汁原味,将原文附上):
- How much outage time can you tolerate?
- How reliable is crash detection? Can you tolerate false positives (premature failovers)?
- How reliable is failover? Where can it fail?
- How well does the solution work cross-data-center? On low and high latency networks?
- Will the solution tolerate a complete data center (DC) failure or network isolation?
- What mechanism, if any, prevents or mitigates split-brain scenarios (two servers claiming to be the master of a given cluster, both independently and unknowingly to each other accepting writes)?
- Can you afford data loss? To what extent?
以上这些准则也可以为我们设计其它业务系统的可用性提供参考。
2.4 成本和性能
据Presslabs的分析和测试,使用他们的WordPress托管服务的客户,99%以上的case对于数据库的QPS需求在100以下,原来配给WordPress的标准配置是使用1CPU的Google Cloud SQL服务,QPS最高在3000左右,价格在$50/月;而使用Kubernetes部署的MySQL,2CPU配置的worker节点价格同样也是$50/月,但是通过MySQL Operator在Kubernetes部署MySQL服务,在一个节点上stack了5组MySQL服务 ,每个的QPS在1000左右,足以满足客户的需求,并使得5组MySQL服务的总体成本从$250/月下降到$50/月:
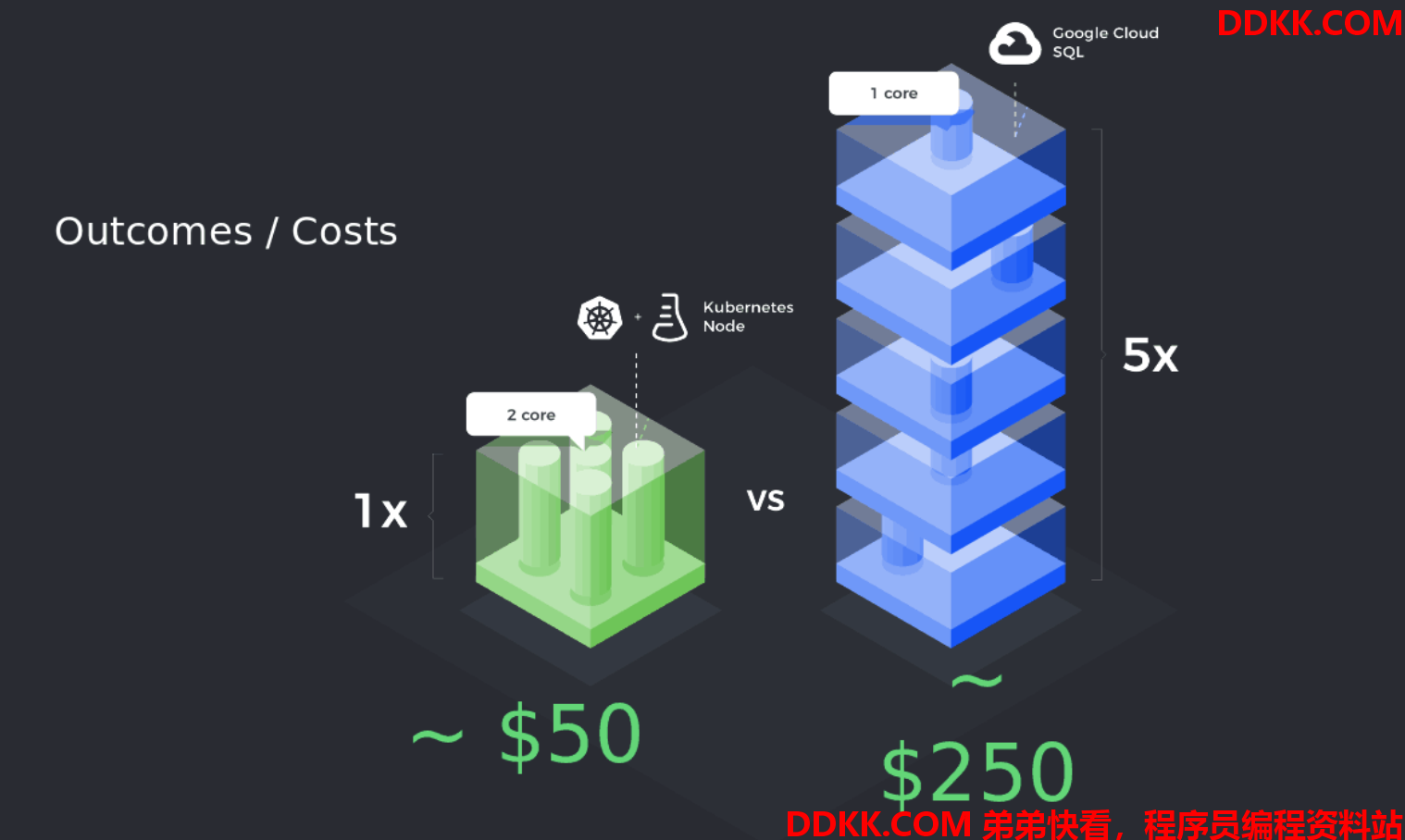
从这里也可以看出来,上云和云原生并不是基础设施成本控制的银弹,将业务需求和技术能力灵活结合,才能做到对症下药,将吹过的牛B落到实处。对此,Presslabs的CEO还感觉良好的说了以下的话:

参考文档:
- https://github.com/openark/orchestrator
- https://github.blog/2016-12-08-orchestrator-github/
- https://github.blog/2018-06-20-mysql-high-availability-at-github/
三、Percona XtraDB Clustser (PXC) Operator方案分析
3.1 Percona XtraDB集群(PXC)方案介绍
PXC是兼容MySQL的开源数据库方案,它的架构如下:
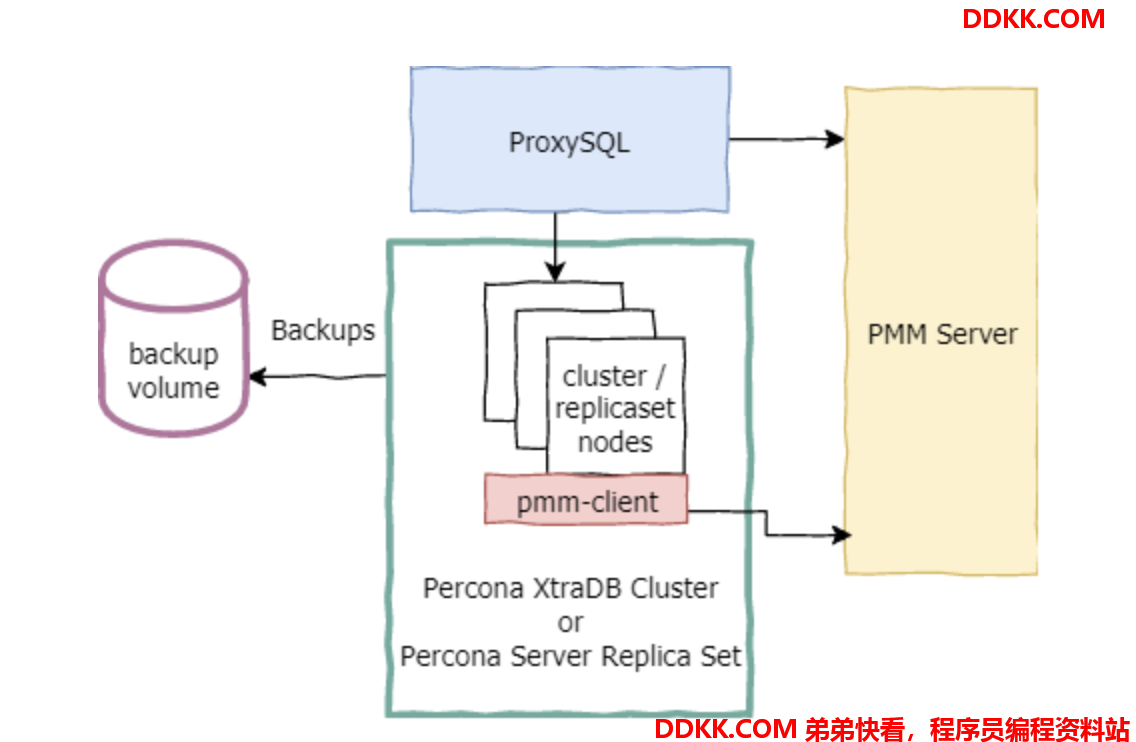 PXC架构
PXC架构
PXC集群的组成如下:
- PXC节点
- ProxySQL代理
- PMM,监控和管理服务器
- 持久化和备份存储
PXC具有以下特点:
- 同步复制,强数据一致性
- 多主复制,多节点可写
- 通过galera进行多slave并行复制
- 使用ProxySQL进行读写管控
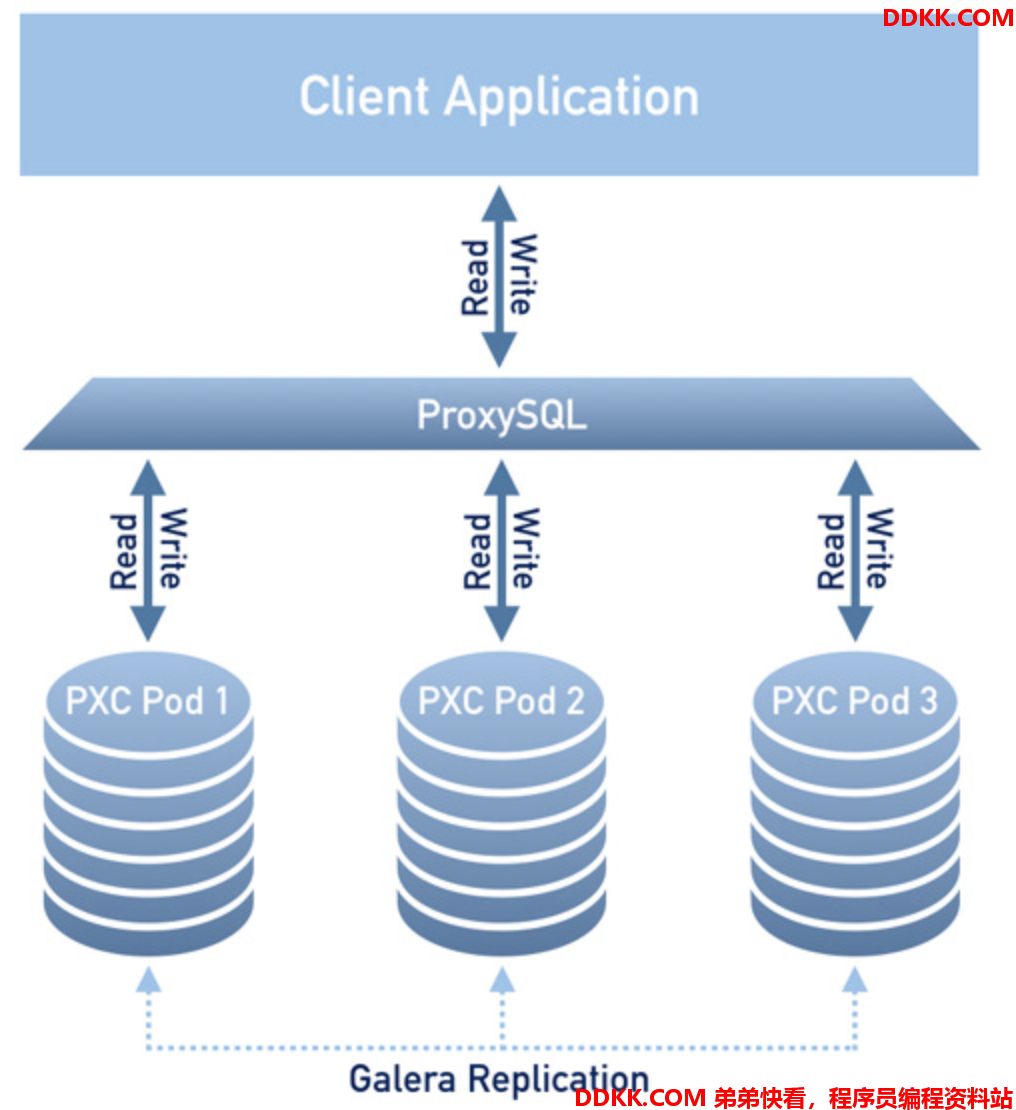 PXC通过Galera进行多点数据并行复制
PXC通过Galera进行多点数据并行复制
3.2 PXC在Kubernetes的部署方案
PXC在Kubernetes的部署方案如下:
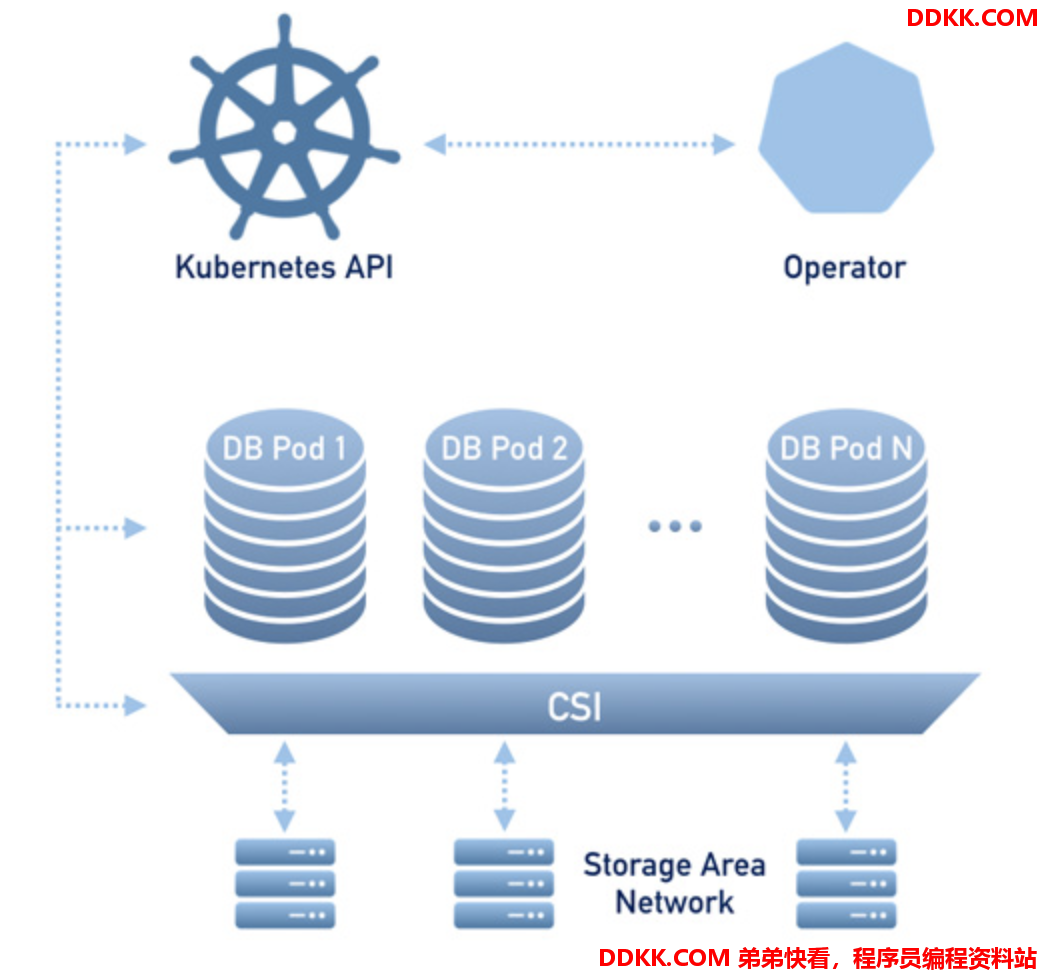 PXC Kubernetes部署方案
PXC Kubernetes部署方案
在这个部署方案的特点如下:
- 通过node affinity尽量将PXC node打散到不同的Kubernetes节点
- 通过PVC进行数据持久化
- Operator控制器需要向API Server注册PerconaXtraDBCluster CRD并且响应针对这个CRD的创建、删除和更新操作