未指定数据源的表数据源如何选择的?
假设又有一个user表;对于user表未配置分片策略;
主要的配置信息为:
1、 2个数据源;
2、 只对order进行分表;;
spring:
application:
name: shardingjdbcDemo
main:
allow-bean-definition-overriding: true
shardingsphere:
数据源信息
datasource:
名称为dbsource-0的数据源
dbsource-0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/db1?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=false
username: root
password: 123456
名称为dbsource-1的数据源
dbsource-1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/db2?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=false
username: root
password: 123456
names: dbsource-0,dbsource-1
规则的配置
rules:
sharding:
tables:
配置表的规则
t_order:
actual-data-nodes: dbsource-$->{0..1}.t_order_$->{0..1}
分库策略
database-strategy:
standard: 用于单分片键的标准分片场景
sharding-column: user_id
sharding-algorithm-name: db-inline
分表策略
table-strategy:
标准策略
standard:
sharding-column: user_id
sharding-algorithm-name: table-inline
配置主键id的策略
keyGenerateStrategy:
column: order_id
key-generator:
type: SNOWFLAKE
props:
worker-id: 1
分片算法
sharding-algorithms:
db-inline:
type: INLINE
props:
algorithm-expression: dbsource-$->{user_id % 2}
table-inline:
type: INLINE
props:
algorithm-expression: t_order_$->{((user_id+1) % 4).intdiv(2)}
props:
sql-show: true
sql-comment-parse-enabled: true
执行插入数据
@Test
void userInsert() {
User user = new User();
user.setId(Long.valueOf("1"));
user.setUserName("user_name");
userMapper.insert(user);
}
会发现一个现象;
1、 当user表在datasource1的时候数据总是插入到datasource1;
2、 当datasource1中没有表,而datasouce2中有表,就会插入到datasource1;
3、 当两个数据源都有表的时候,还是会向datasource1中插入;;
查询同理,所以在不配置任何的情况下,会根据数据源依次找到对应的存在的表执行操作,直到找到就不接着向下找了;
原因是针对不分片的表,shardingjdbc 已经缓存了那些表是在数据源0中存在的,那些是在1 中存在的,所以能够在执行操作的时候路由到存在的表中;
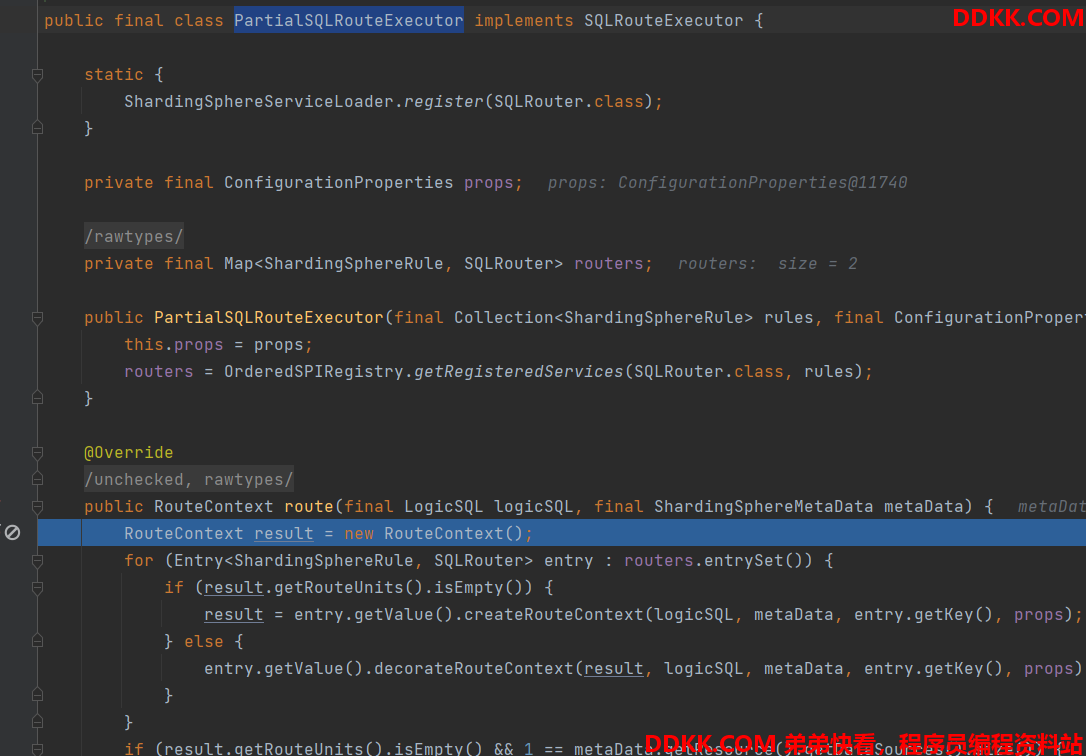
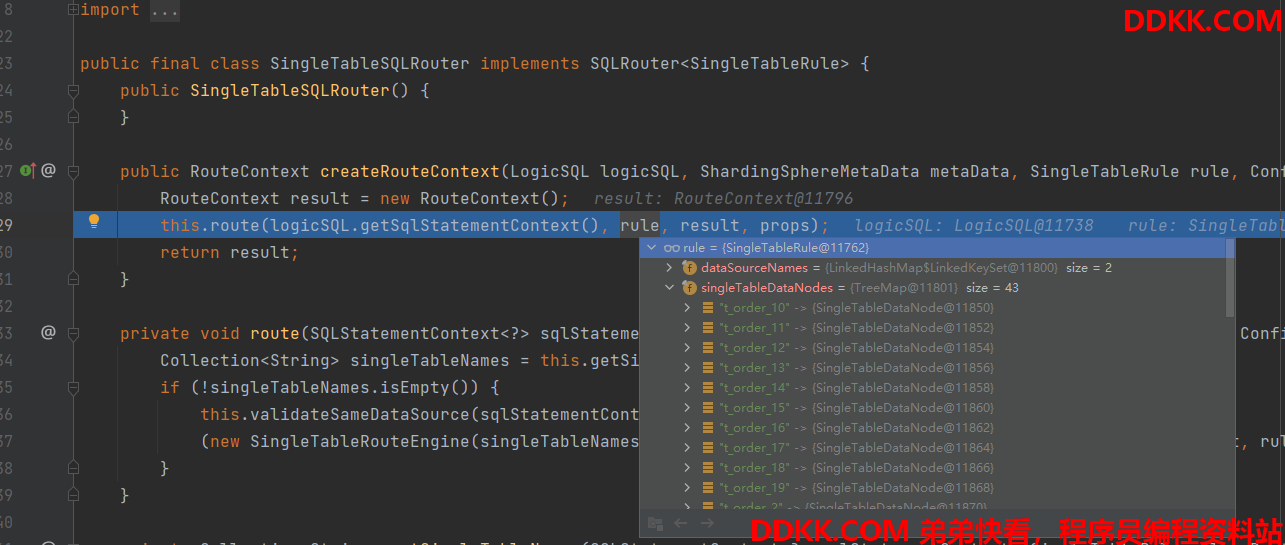
可以通过源码看到走单表的sql路由的时候,能已经提前查出此数据源中的所有表了,就能根据是否是否存在此表做对应的路由了
在4.x 版本中有一个默认数据源的配置 .5.x 已经去掉了;
指定默认策略
defaultDatabaseStrategy: # 默认数据库分片策略
defaultTableStrategy: # 默认表分片策略
defaultKeyGenerateStrategy: # 默认的分布式序列策略
defaultShardingColumn: # 默认分片列名称
这4种配置,可以定义一些默认的策略和配置;