时间语义
“时间”,从理论物理和哲学的角度解释,可能有些玄妙;但对于我们来说,它其实是生活中再熟悉不过的一个概念。一年365天,每天24小时,时间就像缓缓流淌的河,不疾不徐、无休无止地前进着,它是我们衡量事件发生和进展的标准尺度。如果想写抒情散文或是科幻小说,时间无疑是个绝好的题材。但这跟数据处理有什么关系呢?其实从上面的描述中已经可以发现,时间本身就有着“流”的特性,它可以用来判断事件发生的先后以及间隔;所以如果我们想要划定窗口来收集数据,一般就需要基于时间。对于批处理来说,这似乎没什么讨论的必要,因为数据都收集好了,想怎么划分窗口都可以;而对于流处理来说,如果想处理更加实时,就必须对时间有更加精细的控制。那怎样对时间进行“精细的控制”呢?在我们的认知里,时间的流逝是一个客观的事实,只要有一个足够精确的表就可以告诉我们准确的时间了。在计算机系统里,这不就是系统时间吗?那所谓的“时间语义”又是什么意思呢?
一、 Fink中的时间语义
对于一台机器而言,“时间”自然就是指系统时间。但我们知道,Flink是一个分布式处理系统。分布式架构最大的特点,就是节点彼此独立、互不影响,这带来了更高的吞吐量和容错性;但有利必有弊,最大的问题也来源于此。在分布式系统中,节点“各自为政”,是没有统一时钟的,数据和控制信息都通过网络进行传输。比如现在有一个任务是窗口聚合,我们希望将每个小时的数据收集起来进行统计处理。而对于并行的窗口子任务,它们所在节点不同,系统时间也会有差异;当我们希望统计8点9点的数据时,对并行任务来说其实并不是“同时”的,收集到的数据也会有误差。那既然一个集群中有JobManager作为管理者,是不是让它统一向所有TaskManager发送同步时钟信号就行了呢?这也是不行的。因为网络传输会有延迟,而且这延迟是不确定的,所以JobManager发出的同步信号无法同时到达所有节点;想要拥有一个全局统一的时钟,在分布式系统里是做不到的。另一个麻烦的问题是,在流式处理的过程中,数据是在不同的节点间不停流动的,这同样也会有网络传输的延迟。这样一来,当上下游任务需要跨节点传输数据时,它们对于“时间”的理解也会有所不同。例如,上游任务在8点59分59秒发出一条数据,到下游要做窗口计算时已经是9点零1秒了,那这条数据到底该不该被收到8点9点的窗口呢?所以,当我们希望对数据按照时间窗口来进行收集计算时,“时间”到底以谁为标准就非常重要了。
重新梳理一下流式数据处理的过程。如图所示,在事件发生之后,生成的数据被收集起来,首先进入分布式消息队列,然后被Flink系统中的Source算子读取消费,进而向下游的转换算子(窗口算子)传递,最终由窗口算子进行计算处理。
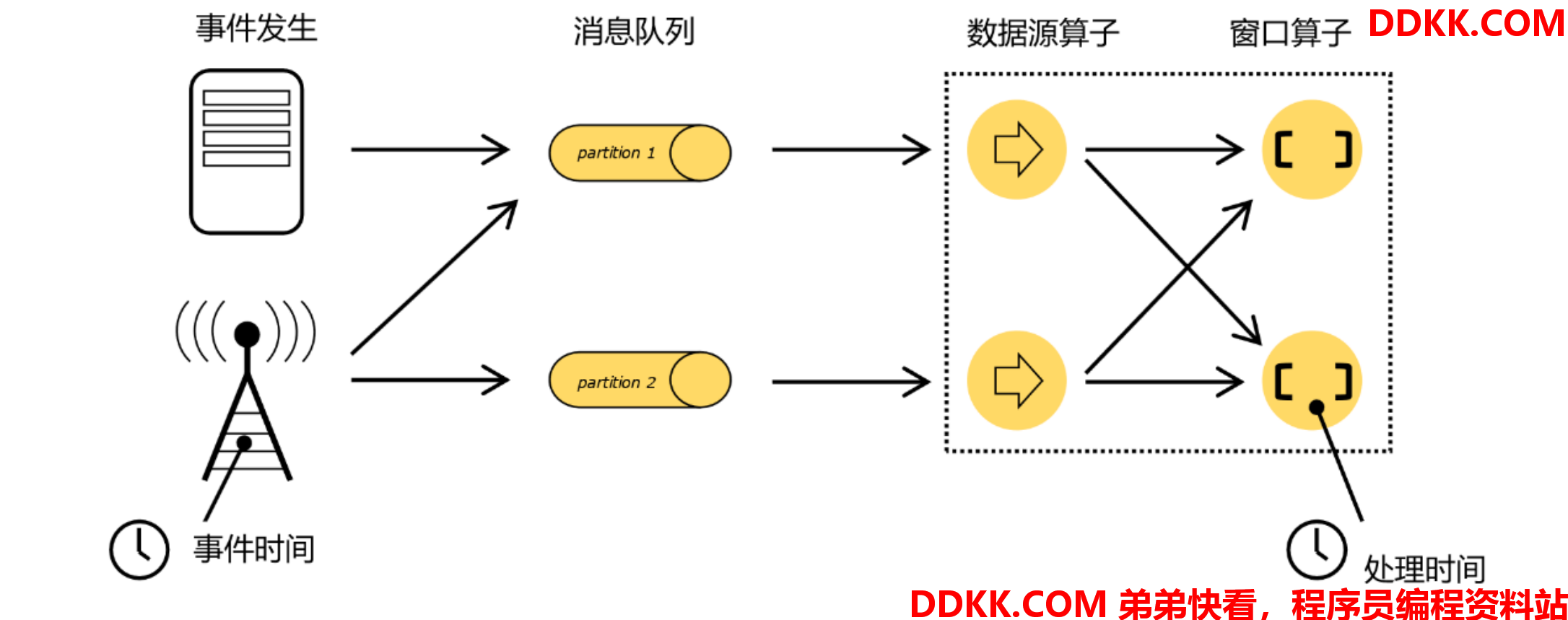
很明显,这里有两个非常重要的时间点:
- 一个是数据产生的时间,我们把它叫作“事件时间”(EventTime);
- 另一个是数据真正被处理的时刻,叫作“处理时间”(ProcessingTime)。我们所定义的窗口操作,到底是以那种时间作为衡量标准,就是所谓的“时间语义”(NotionsofTime)>。由于分布式系统中网络传输的延迟和时钟漂移,处理时间相对事件发生的时间会有所滞后。
1.处理时间(Processing Time)
处理时间的概念非常简单,就是指执行处理操作的机器的系统时间。如果我们以它作为衡量标准,那么数据属于哪个窗口就很明显了:只看窗口任务处理这条数据时,当前的系统时间。比如之前举的例子,数据8点59分59秒产生,而窗口计算时的时间是9点零1秒,那么这条数据就属于9点—10点的窗口;如果数据传输非常快,9点之前就到了窗口任务,那么它就属于8点—9点的窗口了。每个并行的窗口子任务,就只按照自己的系统时钟划分窗口。假如我们在早上8点10分启动运行程序,那么接下来一直到9点以前处理的所有数据,都属于第一个窗口;9点之后、10点之前的所有数据就将属于第二个窗口。这种方法非常简单粗暴,不需要各个节点之间进行协调同步,也不需要考虑数据在流中的位置,简单来说就是“我的地盘听我的”。所以处理时间是最简单的时间语义。
**2. 事件时间(Event Time) **
是指每个事件在对应的设备上发生的时间,也就是数据生成的时间。数据一旦产生,这个时间自然就确定了,所以它可以作为一个属性嵌入到数据中。这其实就是这条数据记录的“时间戳”(Timestamp)。
在事件时间语义下,我们对于时间的衡量,就不看任何机器的系统时间了,而是依赖于数据本身。打个比方,这相当于任务处理的时候自己本身是没有时钟的,所以只好来一个数据就问一下“现在几点了”;而数据本身也没有表,只有一个自带的“出厂时间”,于是任务就基于这个时间来确定自己的时钟。由于流处理中数据是源源不断产生的,一般来说,先产生的数据也会先被处理,所以当任务不停地接到数据时,它们的时间戳也基本上是不断增长的,就可以代表时间的推进。当然我们会发现,这里有个前提,就是“先产生的数据先被处理”,这要求我们可以保证数据到达的顺序。但是由于分布式系统中网络传输延迟的不确定性,实际应用中我们要面对的数据流往往是乱序的。在这种情况下,就不能简单地把数据自带的时间戳当作时钟了,而需要用另外的标志来表示事件时间进展,在Flink中把它叫作事件时间的“水位线”(Watermarks) 。关于水位线的概念和用法,我们会稍后介绍。
二、哪种时间语义更重要?
已经了解了Flink中两种不同的时间语义,那实际应用的时候,到底应该用哪个呢?
1、从《星球大战》说起
为了更加清晰地说明两种语义的区别,我们来举一个非常经典的例子:电影《星球大战》。
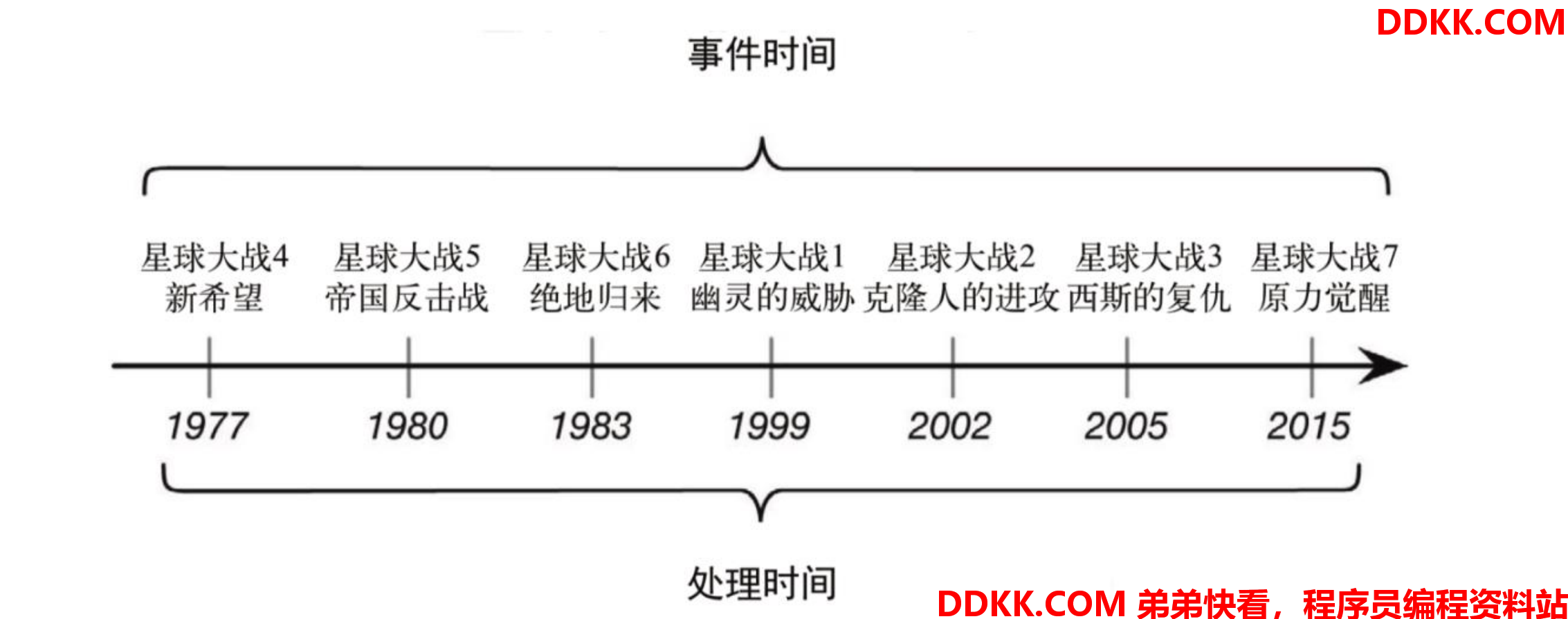
《星球大战》是一部经典的科幻电影,在1977拍摄上映之后就引起了巨大的反响,票房爆棚好评如潮。我们知道,但凡一部商业电影叫好又叫座,那十有八九都是要拍续集的——于是6年内又上映了两部续集,这就是当时轰动一时的星战三部曲。好IP总是要反复拿来用,所以十几年后又有了星战前传三部曲,到了2015年之后又以每年一部的频率继续拍摄后传和外传。而星战系列的命名也很有趣,是按照故事时间线的发展来的:经典三部曲是系列的四、五、六部,之后是前传一、二、三,2015年开始的后传就从第七部算起了。如图所示,我们会发现,看电影其实就是处理影片中数据的过程,所以影片的上映时间就相当于“处理时间”;而影片的数据就是所描述的故事,它所发生的背景时间就相当于“事件时间”。
现在我们考虑一下,作为没有看过星战的新影迷,如果想要入坑一览,该选择什么样的观影顺序呢?这就要看我们具体的需求了:如果你是剧情党,重点想看一个完整的故事,那最好的选择无疑就是按照系列的编号,沿着故事发展的时间线来看;而如果你是特效党,更想体验炫目的视觉效果和时代技术的发展,那就按照电影的拍摄顺序来观看,不过剧情可能就需要多脑补一下了。所以,两种时间语义都有各自的用途,适用于不同的场景
**2、数据处理系统中的时间语义 **
在计算机系统中,考虑数据处理的“时代变化”是没什么意义的,我们更关心的,显然是数据本身产生的时间。比如我们计算网站的PV、UV等指标,要统计每天的访问量。如果某个用户在23点59分59秒有一次访问,但我们的任务处理这条数据的时间已经是第二天0点0分01秒了;那么这条数据,是应该算作当天的访问,还是第二天的访问呢?很明显,统计用户行为,需要考虑行为本身发生的时间,所以我们应该把这条数据统计入当天的访问量。这时我们用到的窗口,就是以事件时间作为划分标准的,跟处理时间无关。所以在实际应用中,事件时间语义会更为常见。一般情况下,业务日志数据中都会记录数据生成的时间戳(timestamp),它就可以作为事件时间的判断基础。
3、两种时间语义的对比
实际应用中,数据产生的时间和处理的时间可能是完全不同的。很长时间收集起来的数据,处理或许只要一瞬间;也有可能数据量过大、处理能力不足,短时间堆了大量数据处理不完,产生“背压”(backpressure)。通常来说,处理时间是我们计算效率的衡量标准,而事件时间会更符合我们的业务计算逻辑。所以更多时候我们使用事件时间;不过处理时间也不是一无是处。对于处理时间而言,由于没有任何附加考虑,数据一来就直接处理,因此这种方式可以让我们的流处理延迟降到最低,效率达到最高。但是我们前面提到过,在分布式环境中,处理时间其实是不确定的,各个并行任务时钟不统一;而且由于网络延迟,导致数据到达各个算子任务的时间有快有慢,对于窗口操作就可能收集不到正确的数据了,数据处理的顺序也会被打乱。这就会影响到计算结果的正确性。所以处理时间语义,一般用在对实时性要求极高、而对计算准确性要求不太高的场景。而在事件时间语义下,水位线成为了时钟,可以统一控制时间的进度。这就保证了我们总可以将数据划分到正确的窗口中,比如8点59分59秒产生的数据,无论网络传输的延迟是多少,它永远属于8点~9点的窗口,不会错分。但我们知道数据还可能是乱序的,要想让窗口正确地收集到所有数据,就必须等这些错乱的数据都到齐,这就需要一定的等待时间。所以整体上看,事件时间语义是以一定延迟为代价,换来了处理结果的正确性。由于网络延迟一般只有毫秒级,所以即使是事件时间语义,同样可以完成低延迟实时流处理的任务。另外,除了事件时间和处理时间,Flink还有一个“摄入时间”(IngestionTime)的概念,它是指数据进入Flink数据流的时间,也就是Source算子读入数据的时间。摄入时间相当于是事件时间和处理时间的一个中和,它是把Source任务的处理时间,当作了数据的产生时间添加到数据里。这样一来,水位线(watermark)也就基于这个时间直接生成,不需要单独指定了。这种时间语义可以保证比较好的正确性,同时又不会引入太大的延迟。它的具体行为跟事件时间非常像,可以当作特殊的事件时间来处理。在Flink中,由于处理时间比较简单,早期版本默认的时间语义是处理时间;而考虑到事件时间在实际应用中更为广泛,从1.12版本开始,Flink已经将事件时间作为了默认的时间语义。