hadoop的起源
- 阶段一
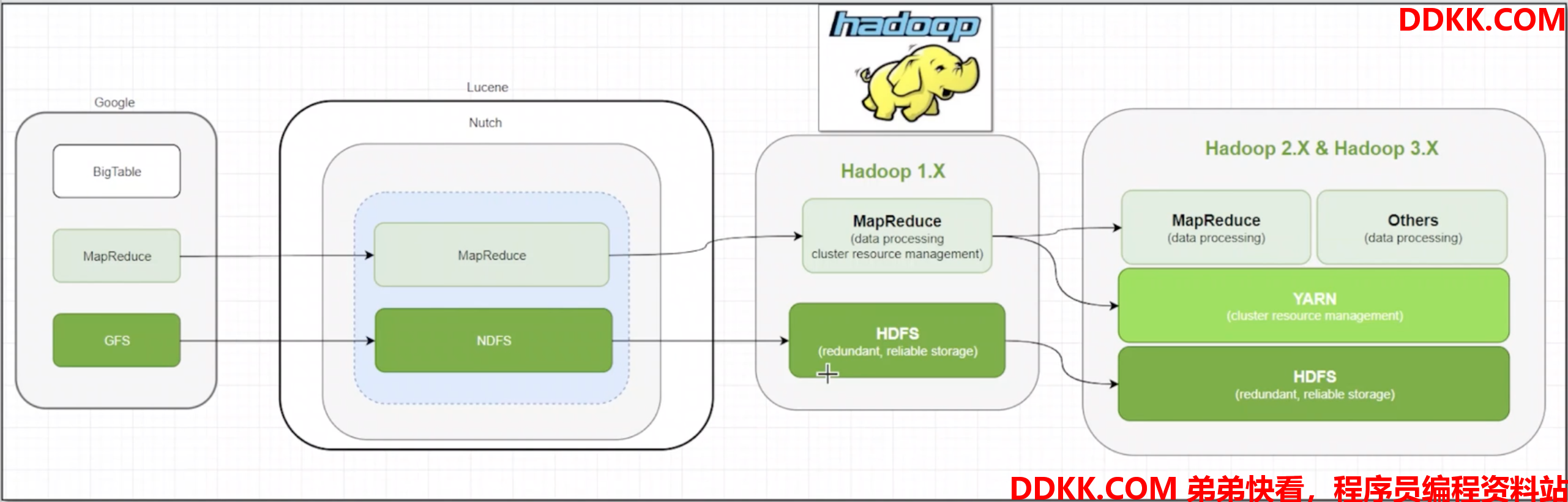
Hadoop最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
- 阶段二
2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
- 阶段三
Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。
狭义上来说,hadoop就是单独指代hadoop这个软件,
广义上来说,hadoop指代大数据的一个生态圈,包括很多其他的软件
hadoop的版本及选择
-
hadoop发展版本
-
0.x版本:hadoop较早的一个开源版本,在此基础上发展的1.x和2.x版本
-
1.x版本:hadoop的第二代开源版本,主要修复了0.x版本的一些bug
-
2.x版本:架构发生了重大变化,引入了yarn平台,也是现在生产环境中使用最多的版本
-
3.x版本:在2.x版本基础上引入了一些hdfs新性质,且已发展为稳定版本,未来公司使用趋势
-
hadoop发行版本
-
Apache版本
最基础的版本适合入门学习
- Cloudera版本
大型互联网企业使用
- Hortonworks版本
文档很不错
- ……
hadoop的运行模式
- 本地运行模式
无需任何守护进程,所有进程都在一个JVM上运行。在独立模式下调试MR程序的时候非常高效方便。所以一般该模式下一般是学习或开发阶段调试使用
- 伪分布式运行模式
hadoop的守护进程运行在本地机器上,模拟一个小规模的集群,换句话说可以配置一台机器的hadoop集群
伪分布式是完全分布式的一个特例
- 完全分布式运行模式(重点)
hadoop守护进程运行在一个集群上,需要多台机器来实现完全分布式服务的安装
hadoop的架构模块

-
hadoop由三个模块组成
-
分布式存储HDFS
-
分布式计算MapReduce
-
资源调度引擎YARN
-
关键词
-
分布式
-
主从架构
HDFS架构剖析
-
分块存储
-
在hadoop2.x中,保存文件到HDFS时,会默认按128M的单位将文件分割成一个个block块
-
数据以block块的形式存储在HDFS文件系统中
- block块的大小可以在hdfs-site.xml中进行修改
- hdfs-default.xml
<property>
<name>dfs.blocksize</name>
<value>块的大小,以字节为单位</value> <!-- 只写数值即可 -->
</property>
-
副本存储
-
为了保存block块的安全性,也就是数据的安全性,在hadoop2.x中采用文件,默认保存三个副本,我们可以更改副本的数量来提高数据的安全性
-
副本的数量可以在hdfs-site.xml中进行修改
<property>
<name>dfs.replication</name>
<value>3</value> <!-- 默认为3 -->
</property>
-
抽象成块的好处
-
可以存放很大的文件
-
使用块抽象而不是文件,可以很好简化存储子系统
-
块非常适合数据备份,进而提供输入容错性和可用性
-
HDFS架构
-
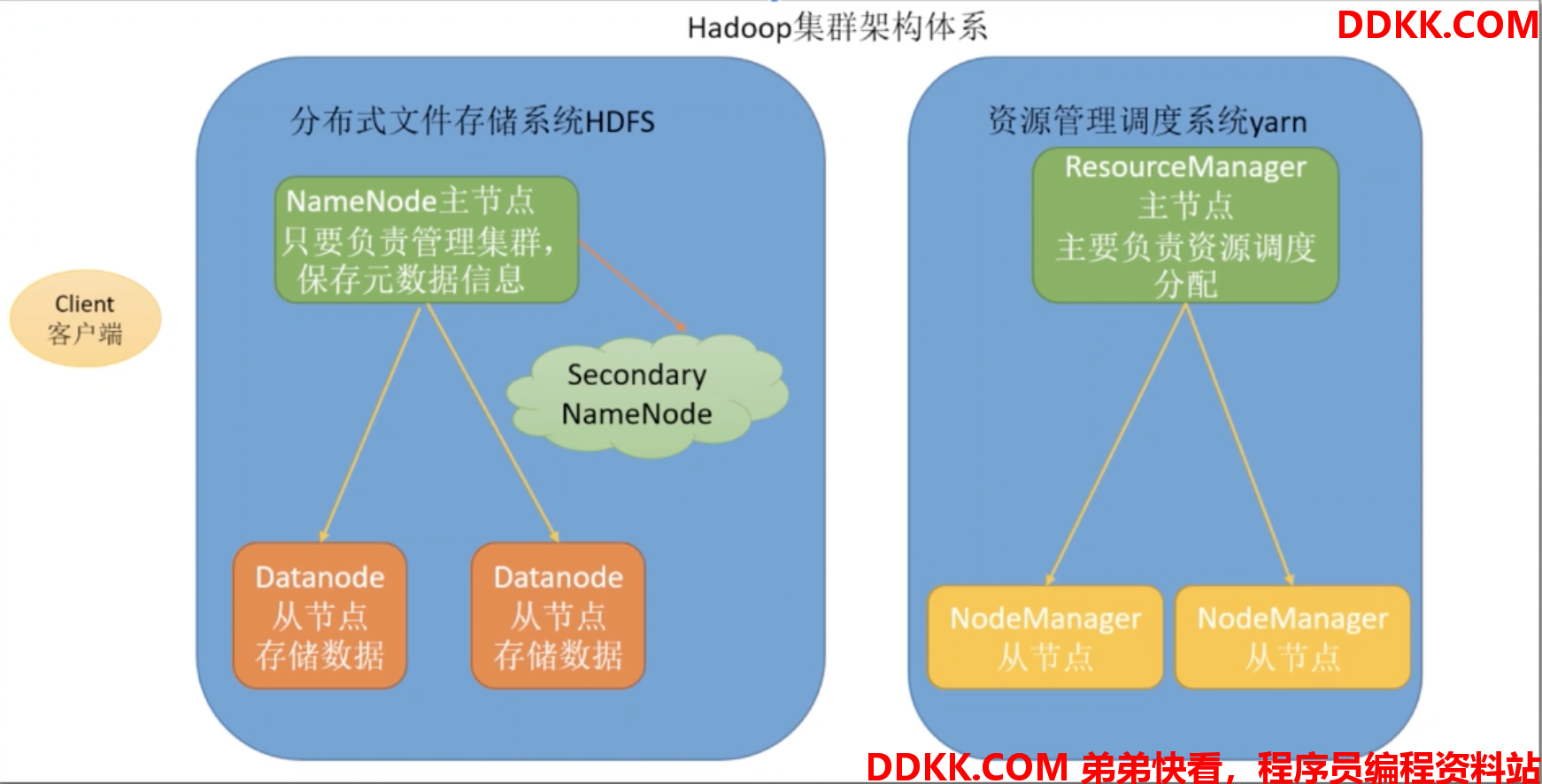
HDFS集群包括:NameNode、DataNode、Secondary NameNode
-
NameNode:负责管理整个系统的元数据,以及每一个路径(文件)所对应的数据块信息
-
DataNode:负责管理用户的文件数据块,每一个数据块都可以在多个datanode上存储多个副本
-
Secondary NameNode:用来监控HDFS系统状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。最主要的作用是辅助namenode管理元数据信息。