Docker
Docker 从 1.11 版本开始,其容器的运行就不再是简单的通过 Docker Daemon 来启动,而是通过集成 containerd、runc 等多个组件来协同完成。
- Docker Daemon:守护进程,属于 CS 架构,负责和 Docker Client 端交互,并管理 Docker 镜像和容器。
- Containerd:负责对集群节点上的容器生命周期进行管理,并为 Docker Daemon 提供 gRPC 接口。
工作原理架构图:
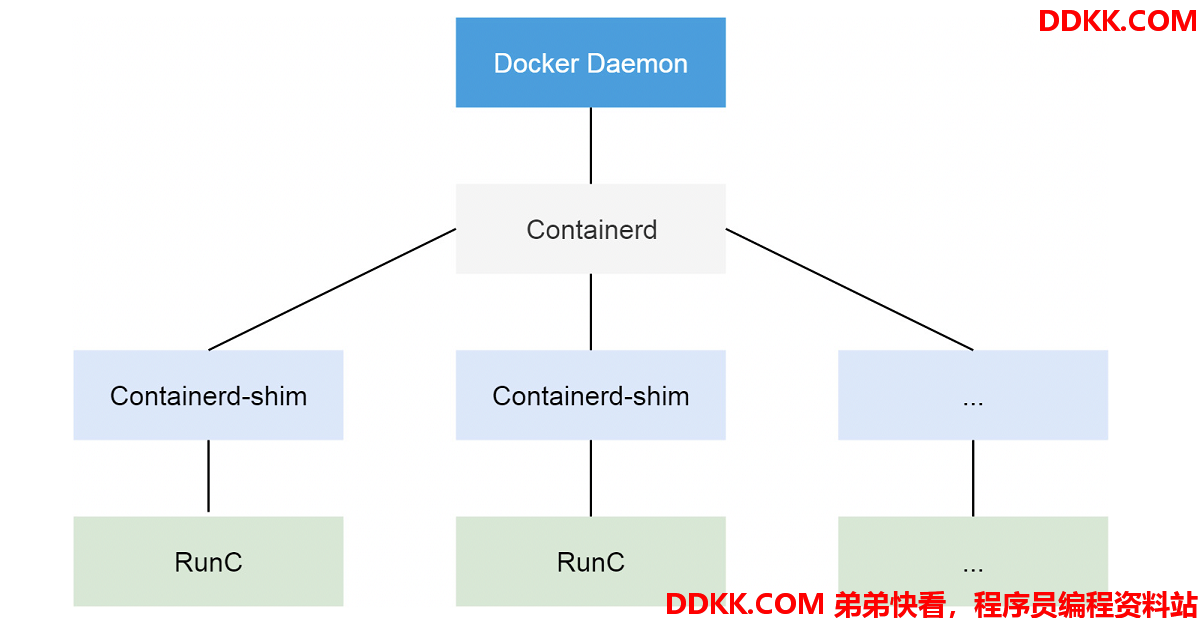
目前Docker 创建容器的流程:
1、 用户通过DockerDaemon提交容器创建请求,DockerDaemon再请求Containerd发起创建;
2、 Containerd收到创建请求后,创建一个Containerd-shim进程去操作容器这样做的原因在于:;
容器进程需要一个父进程做状态收集、维持 stdin 等工作,如果父进程直接使用 Containerd 进程,可能会出现因为 Containerd 进程挂掉,整个宿主机所有容器都跟着挂的情况。所以专门搞了一个 Containerd-shim 进程来规避这个问题。
1、 Containerd-shim再通过RunC来进行容器的创建;
容器的创建需要遵循开放容器标准(
OCI,一个文档,主要规定了容器镜像的结构、以及容器需要接收哪些操作指令)做一些 Namespaces 和 Cgroups 的配置,以及挂载 root 文件系统等操作。而 RunC(Docker 捐献的libcontainer改名而来)则是该标准的一个参考实现。通过 RunC 可以创建一个符合规范的容器,除此之外,同类产品还有 Kata、gVisor 等。
所以,整个过程其实就是 Containerd-shim 调用 RunC 创建容器,创建完成后 RunC 退出,Containerd-shim 进程成为容器的父进程(该进程在宿主机可以直接通过 ps -ef 看到),负责收集容器状态上报给 Containerd。并在容器中 PID 为 1 的进程退出后对容器子进程进行清理,避免出现僵尸进程。
Docker 为了做 Swam 进军 PaaS 市场,将容器操作都迁移到 Containerd。可惜最终 Swarm 惨败给 Kubernetes,最后 Docker 就把 Containerd 项目捐献给了 CNCF 基金会(Cloud Native Computing Foundation,云原生计算基金会)。
CRI
Kubernetes 提供了一个 CRI 的容器运行时接口,那么这个 CRI 到底是啥?
在Kubernetes 早期,当时主流的容器就只有 Docker,所以 Kubernetes 是通过硬编码的方式直接调用 Docker API。但随着容器技术的不断发展以及 Google 的主导,出现了更多的容器运行时。Kubernetes 为了支持更多更精简的容器运行时,Google 就和红帽主导推出了 CRI 标准,用于将 Kubernetes 平台和特定的容器运行时解耦。
CRI(Container Runtime Interface,容器运行时接口),本质上就是 Kubernetes 定义的一组与容器运行时进行交互的接口,所以只要实现了这套接口的容器运行时都可以对接到 Kubernetes 平台上来。同时,这也意味着角色的转变,以前都是 Kubernetes 去适配容器运行时的接口,现在是别的容器运行时要去遵循 Kubernetes 给出来的接口标准。
不过在Kubernetes 推出 CRI 的时候还没有现在的统治地位,很多容器运行时自身可能并不会去适配这些 CRI 接口,于是就有了 shim 垫片。其职责就在于适配容器运行时本身的接口到 Kubernetes 的 CRI 接口上。日常听到比较多的就是 dockershim,Kubernetes 和 Docker 进行适配的 shim 垫片。其结构如下:
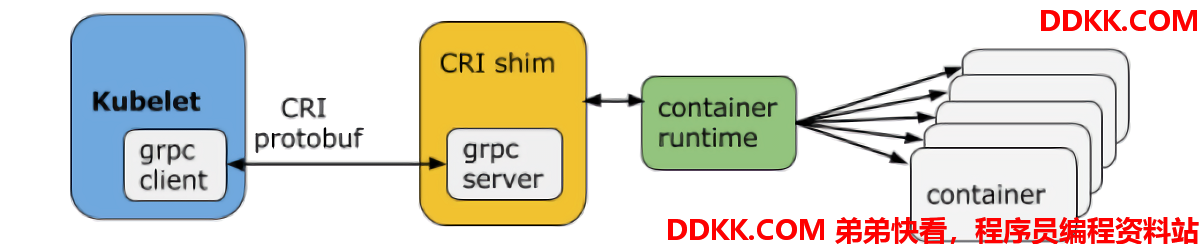
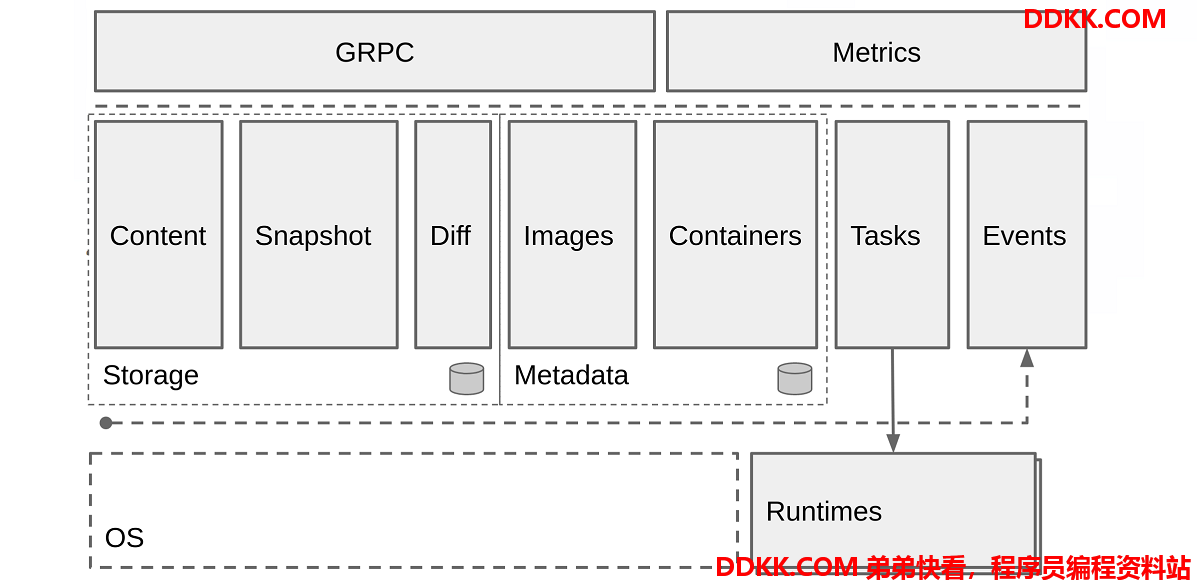
CRI定义的 API 主要包含两个 gRPC 服务:
- ImageService:拉取、查看和删除镜像等操作。
- RuntimeService:用来管理 Pod 和容器的生命周期,以及与容器交互的调用(exec/attach/port-forward)等操作。
在2022 年 5 月 3 日,Kubernetes 1.24 版本发布,正式移除了内置的 dockershim。从此时开始,新版本的 Kubernetes 还想要以 Docker 作为容器运行时,就需要单独安装适配器垫片 cri-dockerd 了。
下面是1.24 版本之前的 Kubernetes 以 Docker 作为容器运行时的调用流程:
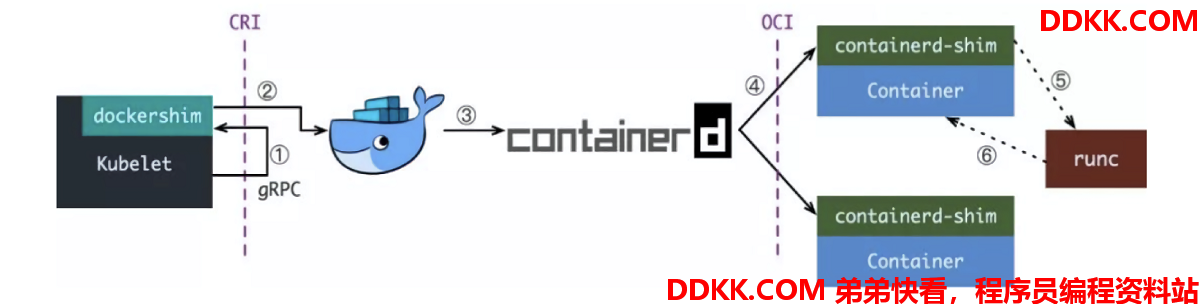
通过调用链路可以发现,整个调用链路是很长的:当在 Kubernetes 中想要创建一个 Pod 时,首先需要 kubelet 通过 CRI 接口调用自身集成的 dockershim。dockershim 在收到请求后,转化成 Docker Daemon 能识别的请求并发到 Docker Daemon 上请求创建一个容器,后续才就是真正的容器创建流程。
说到底,通过 Docker 转换这个流程完全就是多余,因为 Containerd 本身就是实现了 CRI 的服务。只是 Docker 在用户交互上做的跟友好而已。但其实在使用 Kubernetes 的时候,直接对于 Docker 的操作几乎很少。所以完全可以不需要它。
关于Containerd 的发展过程如下:
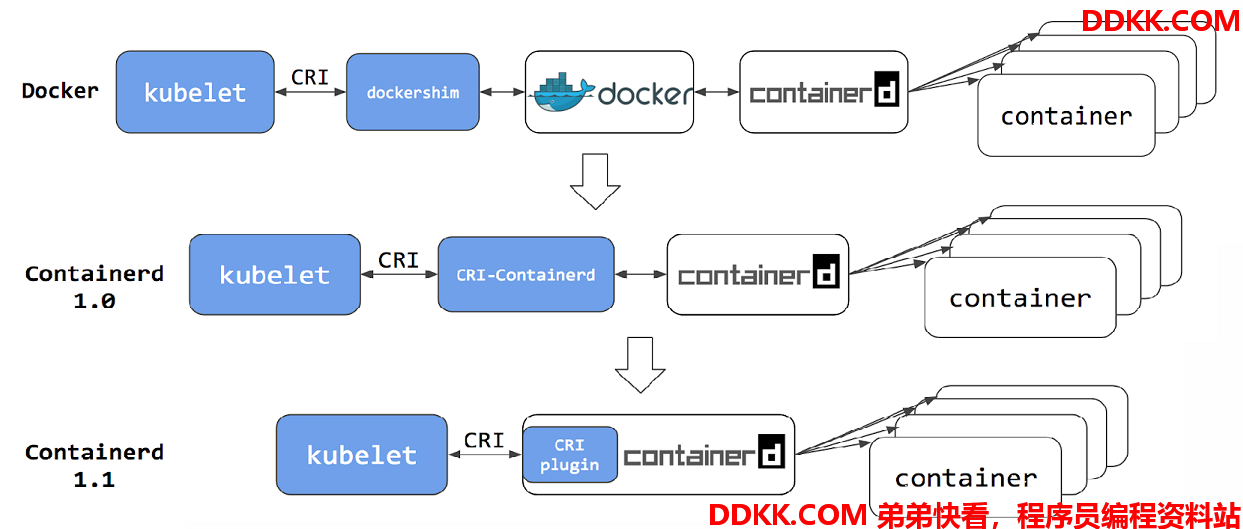
在Containerd 1.1 之后,已经完全消除了中间环节,适配器 shim 也被继承到了 Contained 的主进程中,调用变得更加简洁。
当然用户依旧还是能够使用 Docker 镜像的,但前提是这些镜像必须都是镜像仓库中的。直接使用 Docker 打包在本地的镜像对于 Contained 来说是无法访问到的。
同时,Kubernetes 社区也做了个专门用于 Kubernetes 的容器运行时 CRI-O,直接兼容 CRI 和 OCI 规范。但是对于用户来说,Docker 大家还是更为熟悉,所以更多的还是选择 Containerd 作为容器运行时。
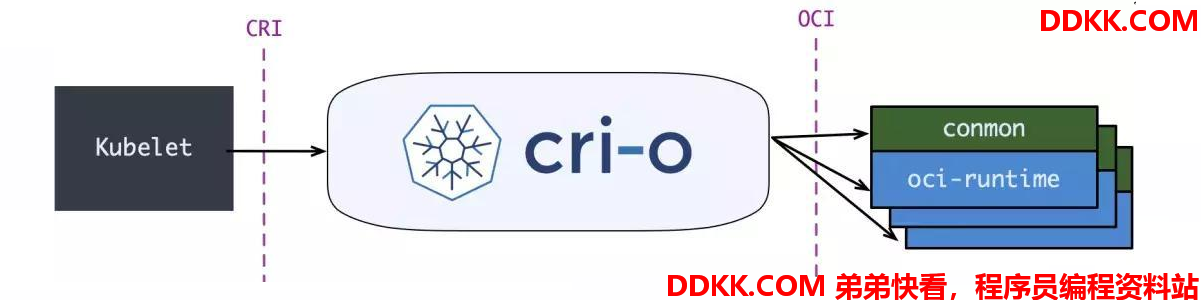
Containerd
Containerd 是从 Docker Engine 里分离出来的一个独立的开源项目,目标是提供一个更加开放、稳定的容器运行基础设施。分离出来的 Containerd 具有更多的功能,涵盖整个容器运行时管理的所有需求,提供更强大的支持。作为一个工业级标准的容器运行时,它强调简单性、健壮性和可移植性,可以负责下面这些事情:
- 管理容器的生命周期(从创建容器到销毁容器)
- 拉取/推送容器镜像
- 存储管理(管理镜像及容器数据的存储)
- 调用 RunC 运行容器(与 RunC 等容器运行时交互)
- 管理容器网络接口及网络
官方架构图:
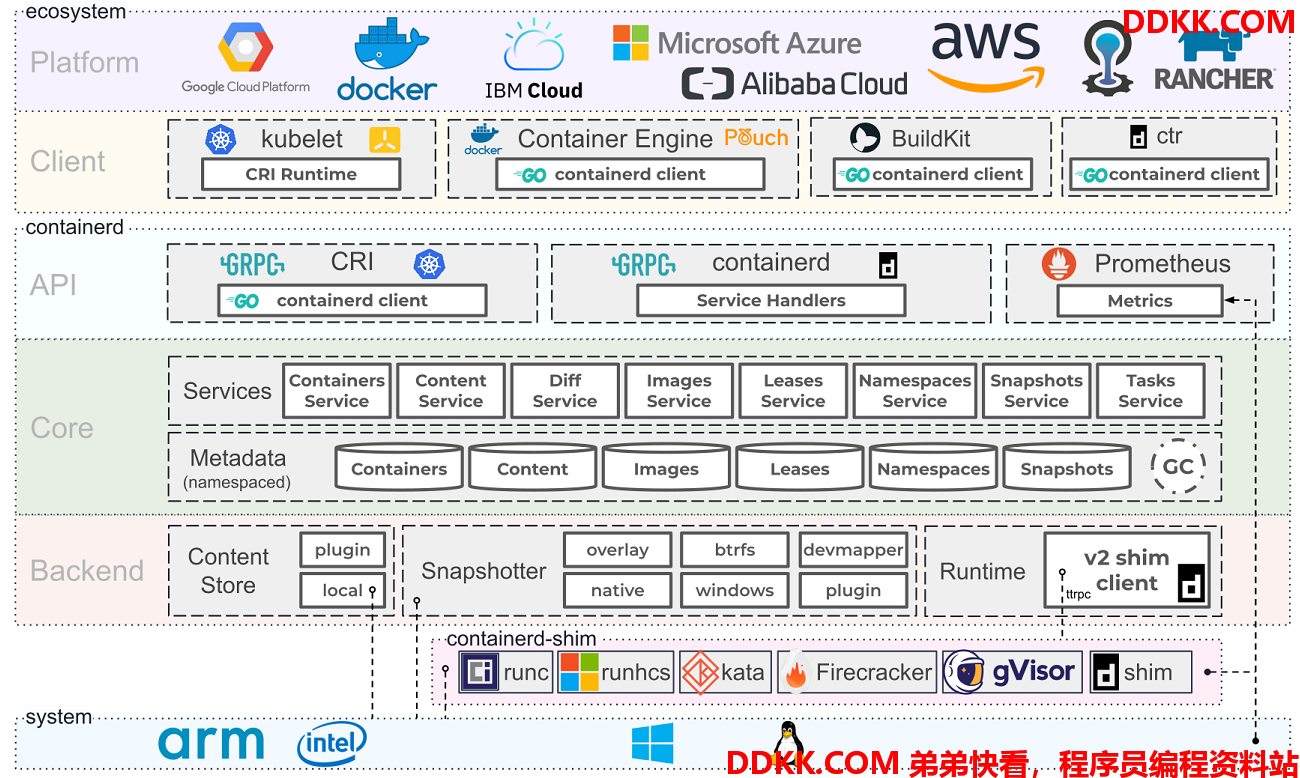
可以看出 Containerd 采用的也是 C/S 架构,服务端通过 unix domain socket 暴露低层的 gRPC API 接口出去,客户端通过这些 API 管理节点上的容器,每个 Containerd 只负责一台机器。
为了解耦,Containerd 将系统划分成了不同的组件,每个组件都由一个或多个模块协作完成,每一种类型的模块都以插件的形式集成到 Containerd 中,而且插件之间是相互依赖的。
总体来看,Containerd 可以分为三个大块:Storage、Metadata 和 Runtime。
安装配置 Containerd
由于Containerd 需要调用 runc,所以需要先安装 RunC,不过 Containerd 提供了一个包含相关依赖的压缩包 cri-containerd-cni-${VERSION}.${OS}-${ARCH}.tar.gz,可以直接使用这个包来进行安装。
下载最新版 Containerd:
这里cri-containerd-cni 安装包的最新版本是 1.6.18,系统是 CentOS 7.9。
# 安装依赖
yum -y install vim lrzsz wget zip unzip tree
# 更新 libseccomp,解决容器启动报错
rpm -e libseccomp-2.3.1-4.el7.x86_64 --nodeps
wget https://vault.centos.org/centos/8/BaseOS/x86_64/os/Packages/libseccomp-2.5.1-1.el8.x86_64.rpm
rpm -ivh libseccomp-2.5.1-1.el8.x86_64.rpm
# 下载安装包
wget https://github.com/containerd/containerd/releases/download/v1.6.18/cri-containerd-cni-1.6.18-linux-amd64.tar.gz
# 直接解压到系统目录
tar -C / -zxf cri-containerd-cni-1.6.18-linux-amd64.tar.gz
# 创建配置文件目录,并生成默认配置
mkdir /etc/containerd
containerd config default > /etc/containerd/config.toml
# 启动 Containerd
systemctl enable containerd --now
# 查看安装信息
ctr version
如图所示:

用过docker 的就知道,这是 C/S 架构的典型特征。
命令行工具 nerdctl
和docker 类似,Containerd 也有自己的客户端工具,就是:ctr
通过命令可以查看命令行工具的用法:
ctr --help
但是这些命令和 docker 的用法很不一样且很难用,会很大程度增加学习成本,并不推荐直接使用,这里就不详细说明了,感兴趣的可以自己去找相关文档研究。
为了更好的对接 docker 转过来的用户,社区提供了另外一个几乎和 docker 一模一样,并且还兼容了 docker-compose 的语法的命令行工具,:nerdctl
Github 上面提供了两种类型的安装包:
- nerdctl-xxx.tar.gz:只包含 nerdctl 工具。
- nerdctl-full-xxx.tar.gz:包含 nerdctl,Containerd,RunC 等所有依赖工具,意味着不需要单独安装 Containerd,直接用这个就行。
这里就是一台新的机器,安装 full 版本:
# 安装依赖
yum -y install vim lrzsz wget zip unzip tree
# 更新 libseccomp,解决容器启动报错
rpm -e libseccomp-2.3.1-4.el7.x86_64 --nodeps
wget https://vault.centos.org/centos/8/BaseOS/x86_64/os/Packages/libseccomp-2.5.1-1.el8.x86_64.rpm
rpm -ivh libseccomp-2.5.1-1.el8.x86_64.rpm
# 下载 nerdctl full 安装包
wget https://github.com/containerd/nerdctl/releases/download/v1.2.0/nerdctl-full-1.2.0-linux-amd64.tar.gz
# 解压安装
tar -C /usr/local -zxf nerdctl-full-1.2.0-linux-amd64.tar.gz
# 创建配置文件目录,并生成默认配置
mkdir /etc/containerd
containerd config default > /etc/containerd/config.toml
# 启动 Containerd
systemctl enable containerd --now
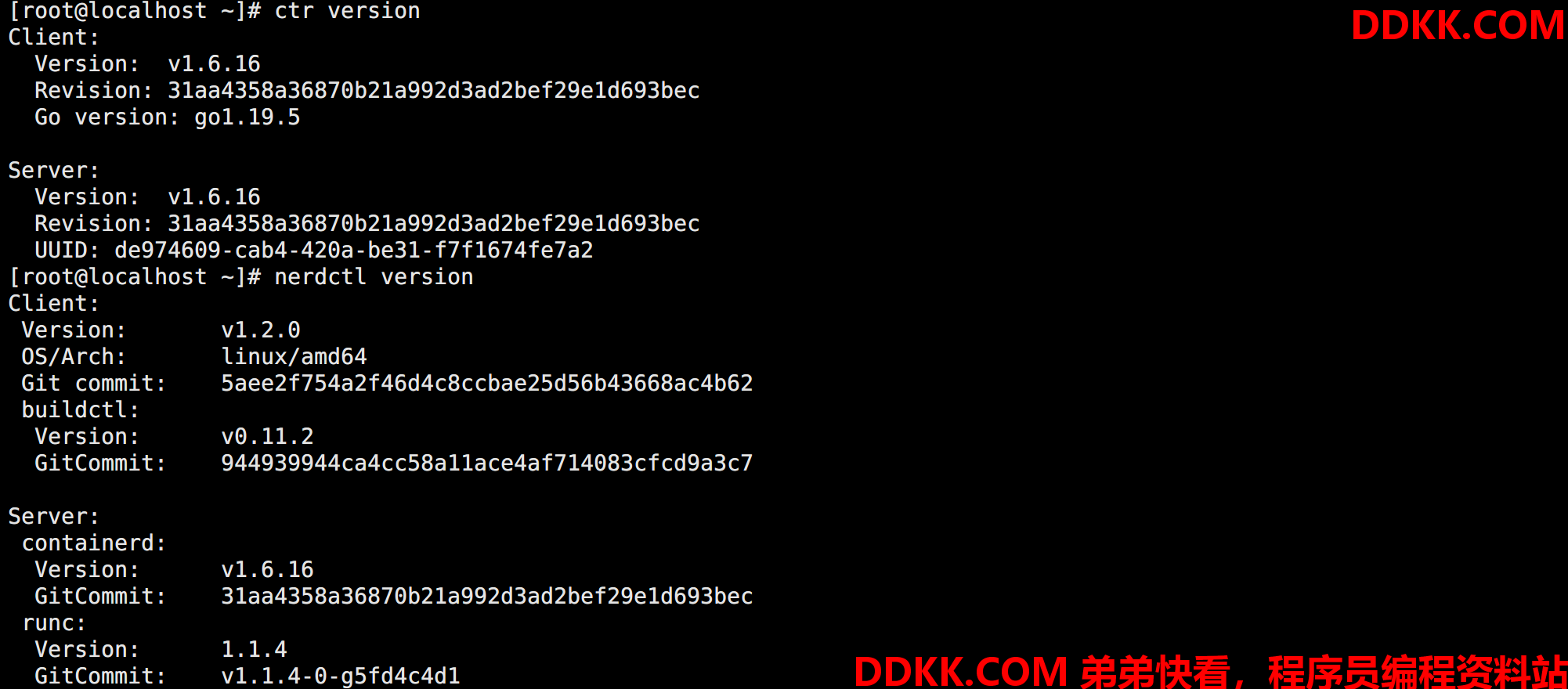
# 查看 Containerd 版本
ctr version
# 查看 nerdctl 版本
nerdctl version
如图所示:
此时通过 nerdctl 就能像使用 docker 一样对镜像,容器进行操作了。
为了习惯操作,甚至可以建立一个命令别名,直接当 docker 使用。
cd
echo "alias docker='nerdctl'" >> .bashrc
source .bashrc
执行操作:
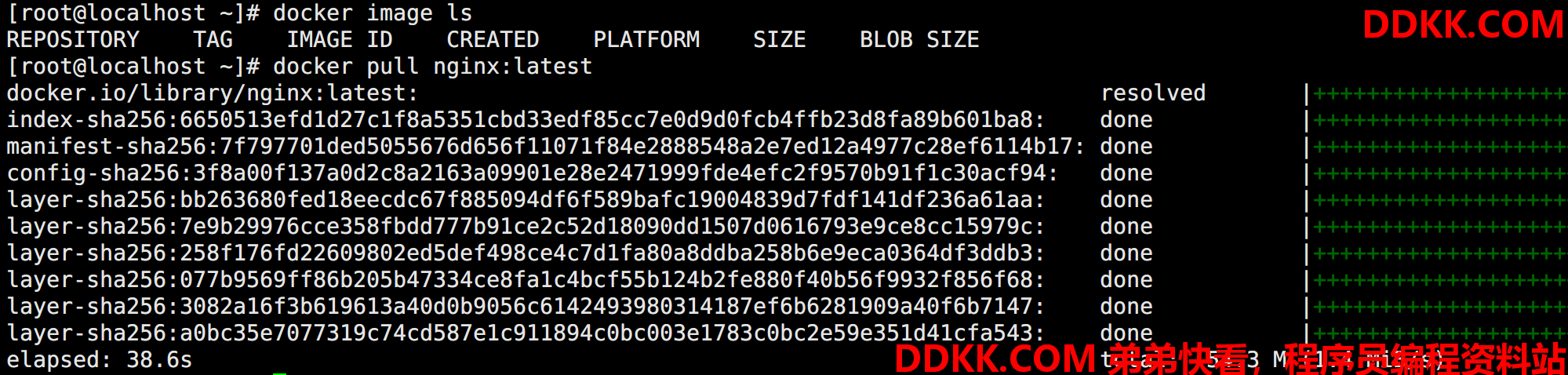
具体命令的用法几乎完全可以参考 docker 的用法。
CGroups
CGroups(Linux Control Group),其作用是限制一组进程使用的资源(CPU、内存等)上限,是 Containerd 容器技术的核心实现原理之一,首先需要了解几个基本概念:
- Task:CGroup 中的 Task 可以理解为一个进程,但它实际上是进程 ID 和线程 ID 列表。
- CGroup:控制组,一个控制组就是一组按照某种标准划分的 Tasks,可以理解为资源限制是以进程组为单位实现的,一个进程加入到某个控制组后,就会受到相应配置的资源限制。
- Hierarchy:CGroup 的层级组织关系。CGroup 以树形层级组织,每个 CGroup 子节点默认继承其父节点的配置属性,这样每个 Hierarchy 在初始化会有 root CGroup。
- Subsystem:子系统,表示具体的资源配置,如 CPU 使用,内存占用等,Subsystem 附加到 Hierarchy 上后可用。
CGroups 支持的子系统包含以下几类,即为每种可以控制的资源定义了一个子系统:
- cpuset:为 CGroup 中的进程分配单独的 CPU 节点,绑定特定的 CPU。
- cpu:限制 CGroup 中进程的 CPU 使用份额。
- cpuacct:统计 CGroup 中进程的 CPU 使用情况。
- memory:限制 CGroup 中进程的内存使用,并能报告内存使用情况。
- devices:控制 CGroup 中进程能访问哪些文件设备(设备文件的创建、读写)。
- freezer:挂起或恢复 CGroup 中的 Task。
- net_cls:可以标记 CGroup 中进程的网络数据包,然后可以使用 tc 模块对数据包进行控制。
- blkio:限制 CGroup 中进程的块设备 IO。
- perf_event:监控 CGroup 中进程的 perf 时间,可用于性能调优。
- hugetlb:hugetlb 的资源控制功能。
- pids:限制 CGroup 中可以创建的进程数。
- net_prio:允许管理员动态的通过各种应用程序设置网络传输的优先级。
通过上面的各个子系统,可以看出使用 CGroups 可以控制的资源有:CPU、内存、网络、IO、文件设备等。
CGroups 具有以下几个特点:
- CGroups 的 API 以一个伪文件系统(/sys/fs/cgroup/)的实现方式,用户的程序可以通过文件系统实现 CGroups 的组件管理。
- CGroups 的组件管理操作单元可以细粒度到线程级别,用户可以创建和销毁 CGroups,从而实现资源载分配和再利用。
- 所有资源管理的功能都以子系统的方式实现,接口统一子任务创建之初与其父任务处于同一个 CGroups 的控制组。
查看当前系统支持的 CGroups 子系统:
cat /proc/cgroups
通过挂载信息也可以看到挂载的 CGroups:
df -h | grep cgroup
如图所示:
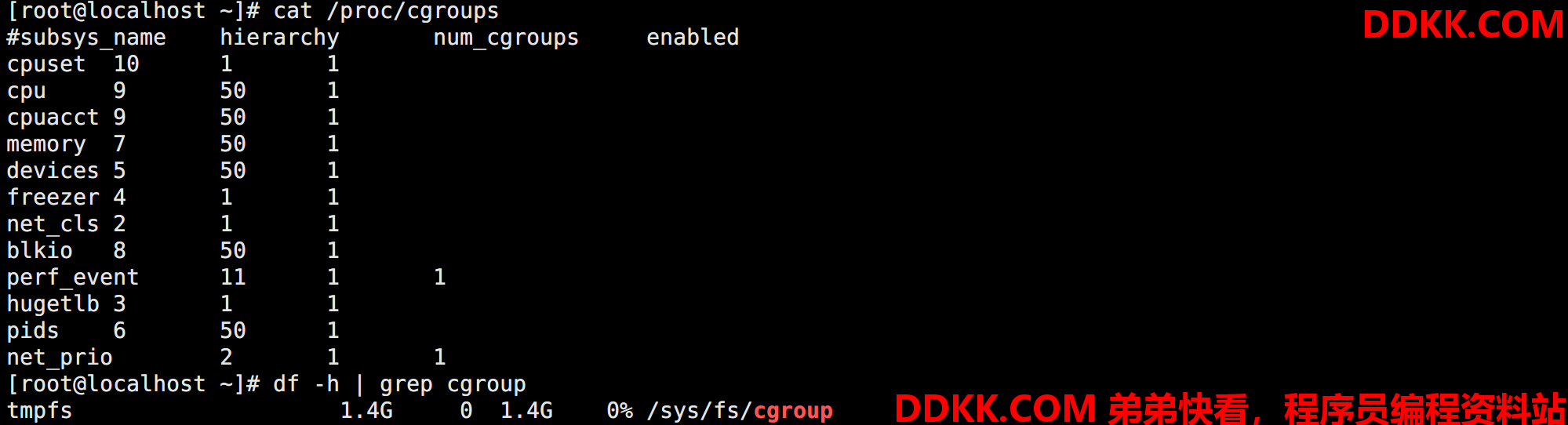
可以看到被挂载到了 /sys/fs/cgroup,cgroup 其实是一种文件系统类型,所有的操作都是通过文件来完成的。
挂载目录下的每个子目录就对应着一个子系统,cgroup 是以目录形式组织的,/ 是 cgroup 的根目录,但是这个根目录可以被挂载到任意目录。
例如CGroups 的 memory 子系统的挂载点是 /sys/fs/cgroup/memory,那么 /sys/fs/cgroup/memory/ 对应 memory 子系统的根目录。该目录下还包含了 system.slice 等目录,进入可以看到之前运行的 Containerd 的配置目录 containerd.service,它的所有内存相关的 CGroups 配置都在下面。
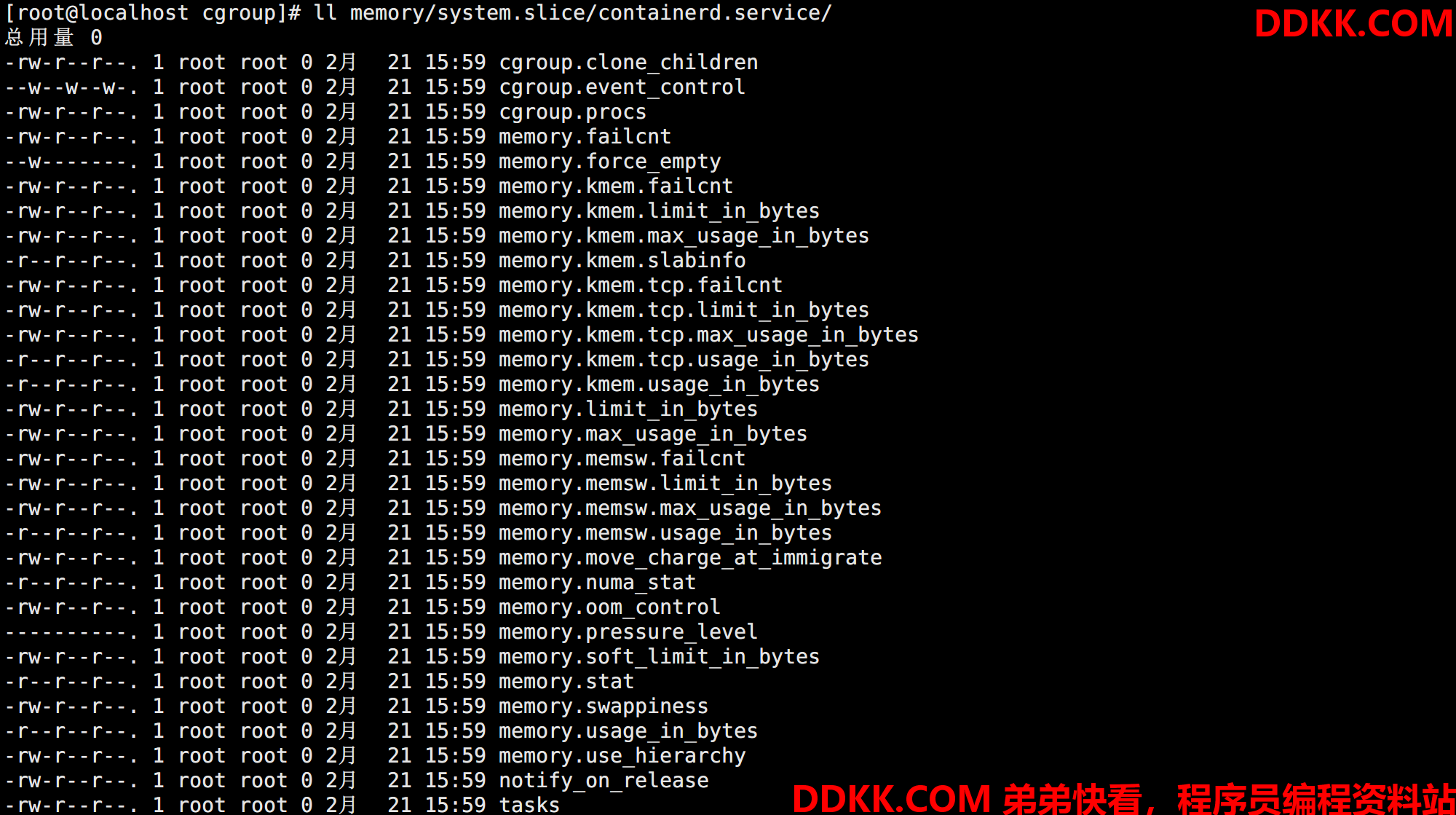
如果linux 系统使用 systemd 初始化系统,初始化进程会生成一个 root cgroup,每个 systemd unit 都将会被分配一个 cgroup。
容器运行时的 cgroup 是可以配置的,如 containerd 可以选择使用 cgroupfs 或 systemd 作为 cgroup 驱动,containerd 默认使用的是 cgroupfs。但这样对于使用了 systemd 的 linux 发行版来说,就同时存在了两个 cgroup 管理器:
- 对于该服务器上启动的容器使用的是 cgroupfs。
- 对于其他 systemd 管理的进程使用的是 systemd。
这样在服务器资源负载高的情况下可能会变的不稳定。因此对于使用了 systemd 的 linux 系统,推荐将容器运行时的 cgroup 驱动使用 systemd。
测试 CGroups
使用nerdctl 运行一个 Containerd 容器:
nerdctl run -d -m 50m --name nginx-demo nginx:latest
执行之后再 /sys/fs/cgroup/memory/default 下面会生成以容器 ID 命名的文件夹:

通过查看 memory.limit_in_bytes 文件可以看到启动容器的时候限制的内存配置,同时通过 Tasks 文件可以看到容器启动之后在宿主机中使用的 PID:
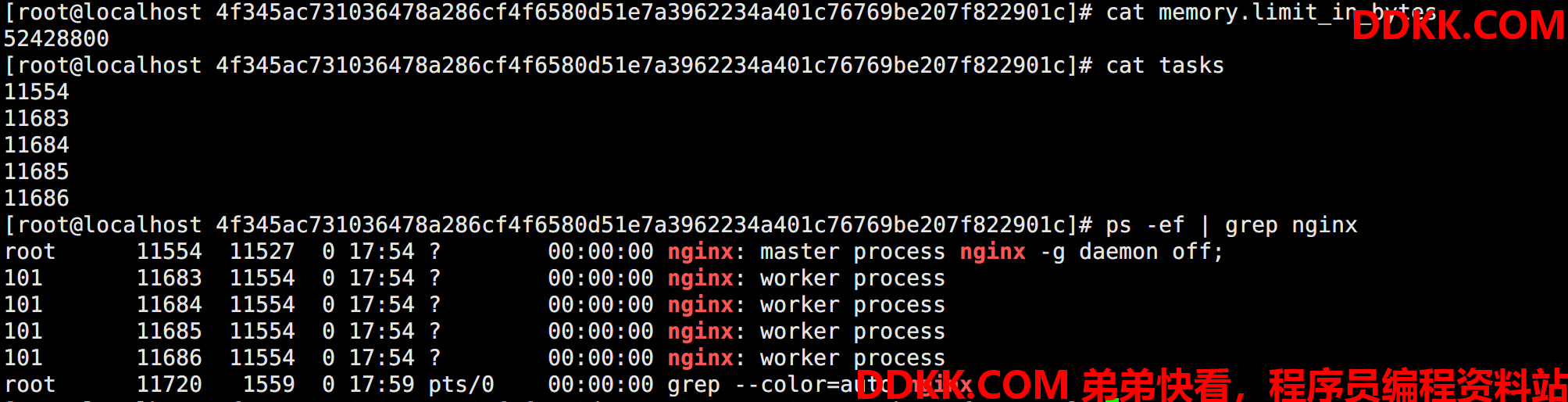
删除容器,这个文件夹也会跟着删除。
Namespaces
Namespace 也称命名空间,是 Linux 提供的用于隔离进程树、网络接口、挂载点以及进程间通信等资源的方法
在服务器上启动多个服务的时候,这些服务其实是会相互影响的,每一个服务都能看到其他服务的进程,也可以访问宿主机器上的任意文件,一旦服务器上的某一个服务被入侵,那么入侵者就能够访问当前机器上的所有服务和文件,这是大家不愿意看到的。作为用户,更希望运行在同一台机器上的不同服务能做到完全隔离,就像运行在多台不同的机器上一样。容器其实就通过 Linux 的 Namespaces 技术来实现的对不同的容器进行隔离。
linux 共有 6(7)种命名空间:
- ipc namespace:管理对 IPC 资源(进程间通信、信号量、消息队列和共享内存)的访问。
- net namespace:网络设备、网络栈、端口等隔离。
- mnt namespace:文件系统挂载点隔离。
- pid namespace:用于进程隔离。
- user namespace:用户和用户组隔离(3.8以后的内核才支持)。
- uts namespace:主机和域名隔离。
- cgroup namespace:用于 cgroup 根目录隔离(4.6以后版本的内核才支持)。
通过lsns 命令可以看到当前系统创建的命名空间。

/proc/<pid>/ns 目录下记录指定进程所属的命名空间:

这些namespace 都是链接文件, 格式为 namespaceType:[inode number],inode number 用来标识一个 namespace,可以理解为 namespace id,如果两个进程的某个命名空间的链接文件指向同一个,那么其相关资源在同一个命名空间中,也就没有隔离了。
通过查看运行的容器,可以知道其名称空间使用情况:

可以看到容器运行都单独创建了属于自己的命名空间,和系统的进行了隔离。