每当创建一张数据表的时候我们就面临着选择什么样的数据类型,选多大的等等问题,很多人凭感觉选了类型估计了大小,但这么做往往后期出错或浪费空间,因此根据特性选择合适的类型及大小很有必要。
一、CHAR 与 VARCHAR
都用来存储字符串,CHAR属于固定长度的字符类型,VARCHAR属于可变长度的字符类型,它们的保存和检索方式不同。
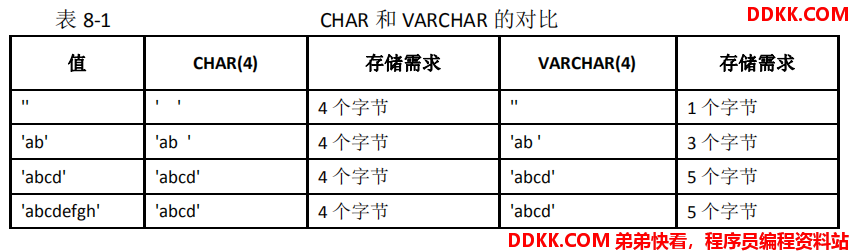
从上表可以看出,固定长度的字符串存储空间是固定的,不管内容如何,而变长字符串的存储空间随着内容有所变动;这里需要注意一点,当字符串的长度超过给定的长度时,如果是非”严格模式“会截掉尾部多余的长度(如上面最后一行);如果是”严格模式“,该值不会被保存且会出现错误提示。
这两种类型进行索引时也不相同,比如从表中查数据,CHAR类型会先删除掉字符串尾部的空格然后再呈现出来,而VARCHAR则不会,例如:
mysql> create table vc (v varchar(4), c char(4));
Query OK, 0 rows affected (0.02 sec)
mysql> insert into vc values('ab ','ab ');
Query OK, 1 row affected (0.01 sec)
mysql> select concat(v,'+'),concat(c,'+') from vc;
+---------------+---------------+
| concat(v,'+') | concat(c,'+') |
+---------------+---------------+
| ab + | ab+ |
+---------------+---------------+
1 row in set (0.00 sec)
对于字符串长度变化不大且对查询速度又较高要求的数据可以考虑使用CHAR类型,但是对于不同的存储引擎也会有一些差别:
- MyISAM存储引擎:建议使用固定长度的数据列代替可变长度的数据列;
- MEMORY存储引擎:目前都是使用的固定长度的数据行存储,因为不管是什么类型都是作为CHAR类型处理的;
- InnoDB存储引擎:建议使用VARCHAR类型。因为根据它的内部存储机制,对于固定长度和可变长度没有太大差别,都是使用指针指向数据,因此从性能上来说CHAR不一定会比VARCHAR好,而且从空间上来考虑VARCHAR更合适。
二、TEXT 与 BLOB
前面说的CHAR 与 VARCHAR 都是存少量字符串的,对于大块的文本需要用到TEXT 与 BLOB 。二者的主要区别在于BLOB可以用来保存二进制数据,例如图片;而TEXT只能保存文本数据。对两者进行细分又可分为TEXT、MEDIUMTEXT、LONGTEXT 和 BLOB、MEDIUMBLOB、LONGBLOB,主要的差别在于存储的长度和字节的不同,因此根据要求选用最小的。
1. BLOB 和 TEXT 引发的性能问题
在执行大量删除更新操作的时候会在数据库表中留下很大的 “ 空洞 ” ,这些空洞会造成很多性能问题,因此需要定期使用OPTIMIZE TABLE功能对这类表进行碎片整理,清除这种 “ 空洞 ” 。下面是一个具体的例子:
一、创建一个表并往里面重复的插入3条有些微区别的数据
mysql> create table t (id varchar(100),context text);
Query OK, 0 rows affected (0.03 sec)
mysql> insert into t values(1,repeat('haha',100));
Query OK, 1 row affected (0.01 sec)
mysql> insert into t values(2,repeat('haha',100));
Query OK, 1 row affected (0.00 sec)
mysql> insert into t values(3,repeat('haha',100));
Query OK, 1 row affected (0.00 sec)
mysql> insert into t select * from t;
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
。。。。
mysql> insert into t select * from t;
Query OK, 196608 rows affected (7.65 sec)
Records: 196608 Duplicates: 0 Warnings: 0
二、切换到information_schema数据库查看表t的大小
mysql> use information_schema;
Database changed
mysql> select concat(round(sum(DATA_LENGTH/1024/1024),2),'MB') as data from tables where table_schema='test1' and table_name='t';
+----------+
| data |
+----------+
| 176.70MB |
+----------+
1 row in set (0.00 sec)
三、回到原数据库删除表t中id为1的记录,这个记录占该表的1/3
mysql> use test1;
Database changed
mysql> delete from t where id=1;
Query OK, 131072 rows affected (5.88 sec)
四、再次去到information_schema数据库查看,发现删除后数据大小没有变
mysql> use information_schema;
Database changed
mysql> select concat(round(sum(DATA_LENGTH/1024/1024),2),'MB') as data from tables where table_schema='test1' and table_name='t';
+----------+
| data |
+----------+
| 176.70MB |
+----------+
1 row in set (0.00 sec)
五、回到test1数据库清理碎片
mysql> use test1;
Database changed
mysql> optimize table t;
+---------+----------+----------+-------------------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+---------+----------+----------+-------------------------------------------------------------------+
| test1.t | optimize | note | Table does not support optimize, doing recreate + analyze instead |
| test1.t | optimize | status | OK |
+---------+----------+----------+-------------------------------------------------------------------+
2 rows in set (6.14 sec)
六、再去information_schema查看大小情况,此时可以看到数据减小了,但不是标准的1/3
mysql> use information_schema;
Database changed
mysql> select concat(round(sum(DATA_LENGTH/1024/1024),2),'MB') as data from tables where table_schema='test1' and table_name='t';
+----------+
| data |
+----------+
| 134.66MB |
+----------+
1 row in set (0.00 sec)
2. 使用合成索引提高大文本字段(TEXT、BLOB)的查询性能
合成索引就是根据大文本字段的内容来建立一个散列值,就相当于我保存的网页连接来指代页面的内容,这样查找的时候不用比较大段的文本,只需要比较这个链接,很明显,这极大的提高了查询速度;但是要注意,这种方式只适合精确匹配,对模糊查询及范围查询没有用处(对比网页链接的例子很容易理解,一个链接只对应一个页面,并不能通过链接之间的关系来找多个页面)。散列值可以用MD5()函数、SHA1()函数、CRC32()函数甚至是自己定义的函数来生成,请注意这样生成的散列值末尾不要带空格,因为CHAR类型会去除尾部空格造成不匹配的影响。
下面看一个例子:
删除之前存在的t表重新创建一个并插入数据
mysql> drop table t;
Query OK, 0 rows affected (0.01 sec)
mysql> create table t (id varchar(100),context blob,hash_value varchar(40));
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t values(1,repeat('beijing',2),md5(context));
Query OK, 1 row affected (0.01 sec)
mysql> insert into t values(2,repeat('beijing',2),md5(context));
Query OK, 1 row affected (0.00 sec)
mysql> insert into t values(3,repeat('beijing 2008',2),md5(context));
Query OK, 1 row affected (0.00 sec)
mysql> select * from t;
+------+--------------------------+----------------------------------+
| id | context | hash_value |
+------+--------------------------+----------------------------------+
| 1 | beijingbeijing | 09746eef633dbbccb7997dfd795cff17 |
| 2 | beijingbeijing | 09746eef633dbbccb7997dfd795cff17 |
| 3 | beijing 2008beijing 2008 | 1c0ddb82cca9ed63e1cacbddd3f74082 |
+------+--------------------------+----------------------------------+
3 rows in set (0.00 sec)
使用散列值来精准查找数据
mysql> select * from t where hash_value=md5(repeat('beijing 2008',2));
+------+--------------------------+----------------------------------+
| id | context | hash_value |
+------+--------------------------+----------------------------------+
| 3 | beijing 2008beijing 2008 | 1c0ddb82cca9ed63e1cacbddd3f74082 |
+------+--------------------------+----------------------------------+
1 row in set (0.00 sec)
从上面的例子可以看出散列值可以用来精准匹配,但如果非要进行模糊匹配怎么办?MySQL提供了前缀索引,如下例:
mysql> create index idx_blob on t(context(100));
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> desc select * from t where context like 'beijing%' \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t
partitions: NULL
type: ALL
possible_keys: idx_blob
key: NULL
key_len: NULL
ref: NULL
rows: 3
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
三、浮点数与定点数
浮点数类型有float、double等,如果一个字段被定义为浮点类型且指定了宽度,那么当数据的宽度超过时会自动四舍五入;
定点数与浮点数不同,它实际上是以字符串形式存放的,因而没有类型误差,更准确。如果插入的数值精度大于定义的精度,默认模式SQLMode下会先警告再四舍五入进行插入;TRADITIONAL传统模式下会报错,数据无法插入。
看例子:
mysql> drop table t;
Query OK, 0 rows affected (0.02 sec)
mysql> create table t (f float(8,1),d decimal(8,1));
Query OK, 0 rows affected (0.02 sec)
mysql> desc t;
+-------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+-------+
| f | float(8,1) | YES | | NULL | |
| d | decimal(8,1) | YES | | NULL | |
+-------+--------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
mysql> insert into t values (1.23456,1.23456);
Query OK, 1 row affected, 1 warning (0.00 sec)
mysql> select * from t;
+------+------+
| f | d |
+------+------+
| 1.2 | 1.2 |
+------+------+
1 row in set (0.00 sec)
mysql> insert into t values (1.25456,1.25456);
Query OK, 1 row affected, 1 warning (0.00 sec)
mysql> select * from t;
+------+------+
| f | d |
+------+------+
| 1.2 | 1.2 |
| 1.3 | 1.3 |
+------+------+
2 rows in set (0.00 sec)
单精度类型的数据超过7位时会产生误差,比如下面的例子:
mysql> create table te (c1 float(10,2),c2 decimal(10,2));
Query OK, 0 rows affected (0.02 sec)
mysql> insert into te values(131072.32,131072.32);
Query OK, 1 row affected (0.01 sec)
mysql> select * from te;
+-----------+-----------+
| c1 | c2 |
+-----------+-----------+
| 131072.31 | 131072.32 |
+-----------+-----------+
1 row in set (0.00 sec)
这就告诉我们在精度要求较高的时候尽量使用定点数来防止这种情况的发生,另外,浮点数的比较也会因精度问题产生意料之外的错误,比如7.22 == 7.22结果不一定成立,7.22-7.0的结果不是想象中的0.22等等,这些都是需要避免的。
四、日期类型的选择
MySQL里面日期类型有DATE、TIME、DATETIME、DATESTAMP等,选用的原则基本如下:
- 选择能够满足应用的最小存储日期类型;比如只要年份那1个字节的YEAR就够了,没必要用4个字节的DATE;
- 如果记录的年份比较久远,那么最好使用DATETIME而不是DATESTAMP,因为DATESTAMP表示的日期范围要短很多;
- 如果记录的日期需要让不同时区的用户使用,那么要选TIMESTAMP,因为日期类型中只有它能和时区对应。