备注:测试数据库版本为MySQL 8.0
一.选择操作系统
GNU/Linux如今是高性能MySQL最常用的操作系统,但是MySQL本身可以运行在很多操作系统上。
MySQL官网 8.0和 5.7 支持的操作系统(https://www.mysql.com/support/supportedplatforms/database.html):
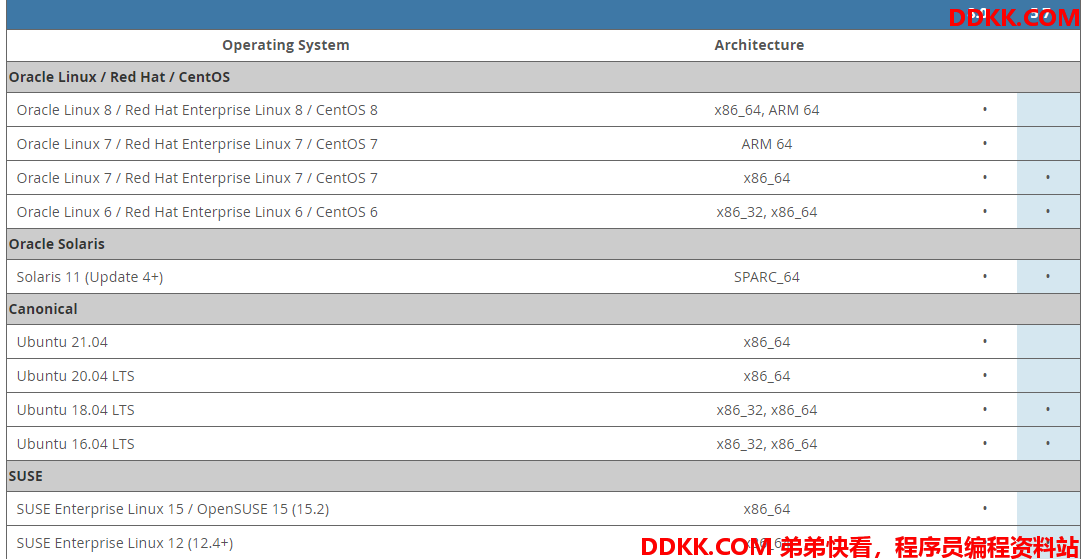

生产的MySQL尽量不要图方便安装在Windows下,尽可能的选择GNU/Linux,红帽子企业版Linux是一个高品质、稳定的发行版;CentOS是一个受欢迎的二进制兼容替代品(免费),但已经因为延后时间较长获得了一些批评;还有Oracle发行的Oracle Enterprise Linux;
二.选择文件系统
文件系统的选择非常依赖于操作系统。在许多系统中,如Windows就只有一到两个选择,而且只有一个(NTFS)真的是能用的。比较而言,GNU/Linux则支持多种文件系统。
许多人想知道哪个文件系统在GNU/Linux上能提供最好的MySQL性能,或者更具体一些,哪个对InnoDB和MyISAM而言是最好的选择。实际的基准测试表明,大多数文件系统在很多方面都非常接近,但测试文件系统的性能确实是一件烦心事。文件系统的性能是与工作负载相关的,没有哪个文件系统是“银弹”。大部分情况下,给定的文件系统不会明显地表现得与其他文件系统不一样。除非遇到了文件系统的限制,例如,它怎么支持并发、怎么在多文件下工作、怎么对文件切片,等等。
建议使用XFS文件系统。ext3文件系统有太多严重的限制,例如inode只有一个互斥变量,并且fsync()时会刷新所有脏块,而不只是单个文件。ext4对ext3有诸多的改进,也可以考虑使用。
三.选择磁盘队列调度策略
在GNU/Linux上,队列调度决定了到块设备的请求实际上发送到底层设备的顺序。默认情况下使用cfq(Completely Fair Queueing,完全公平排队)策略。随意使用的笔记本和台式机使用这个调度策略没有问题,并且有助于防止I/O饥饿,但是用于服务器则是有问题的。在MySQL的工作负载类型下,cfq会导致很差的响应时间,因为会在队列中延迟一些不必要的请求。
可以用下面的命令来查看系统所有支持的以及当前在用的调度策略:
-- 这里sda需要替换成想查看的磁盘的盘符
cat /sys/block/vda/queue/scheduler
[root@mydb]# cat /sys/block/vda/queue/scheduler
[mq-deadline] kyber none
内核中实现的IO调度器主要有四种–Noop,Deadline,CFG, Anticipatory。
一般建议将IO调度调整为Deadline
3.1 Noop算法
Noop调度算法是内核中最简单的IO调度算法。Noop调度算法也叫作电梯调度算法,它将IO请求放入到一个FIFO队列中,然后逐个执行这些IO请求,当然对于一些在磁盘上连续的IO请求,Noop算法会适当做一些合并。这个调度算法特别适合那些不希望调度器重新组织IO请求顺序的应用。
这种调度算法在以下场景中优势比较明显:
1)在IO调度器下方有更加智能的IO调度设备。如果您的Block Device Drivers是Raid,或者SAN,NAS等存储设备,这些设备会更好地组织IO请求,不用IO调度器去做额外的调度工作;
2)上层的应用程序比IO调度器更懂底层设备。或者说上层应用程序到达IO调度器的IO请求已经是它经过精心优化的,那么IO调度器就不需要画蛇添足,只需要按序执行上层传达下来的IO请求即可。
3)对于一些非旋转磁头氏的存储设备,使用Noop的效果更好。因为对于旋转磁头式的磁盘来说,IO调度器的请求重组要花费一定的CPU时间,但是对于SSD磁盘来说,这些重组IO请求的CPU时间可以节省下来,因为SSD提供了更智能的请求调度算法,不需要内核去画蛇添足。这篇文章提及了SSD中使用Noop效果会更好。
3.2 Deadline算法
Deadline算法的核心在于保证每个IO请求在一定的时间内一定要被服务到,以此来避免某个请求饥饿。
Deadline算法中引入了四个队列,这四个队列可以分为两类,每一类都由读和写两类队列组成,一类队列用来对请求按起始扇区序号进行排序,通过红黑树来组织,称为sort_list;另一类对请求按它们的生成时间进行排序,由链表来组织,称为fifo_list。每当确定了一个传输方向(读或写),那么将会从相应的sort_list中将一批连续请求dispatch到requst_queue的请求队列里,具体的数目由fifo_batch来确定。只有下面三种情况才会导致一次批量传输的结束:
1)对应的sort_list中已经没有请求了
2)下一个请求的扇区不满足递增的要求
3)上一个请求已经是批量传输的最后一个请求了。
所有的请求在生成时都会被赋上一个期限值(根据jiffies),并按期限值排序在fifo_list中,读请求的期限时长默认为为500ms,写请求的期限时长默认为5s,可以看出内核对读请求是十分偏心的,其实不仅如此,在deadline调度器中,还定义了一个starved和writes_starved,writes_starved默认为2,可以理解为写请求的饥饿线,内核总是优先处理读请求,starved表明当前处理的读请求批数,只有starved超过了writes_starved后,才会去考虑写请求。因此,假如一个写请求的期限已经超过,该请求也不一定会被立刻响应,因为读请求的batch还没处理完,即使处理完,也必须等到starved超过writes_starved才有机会被响应。为什么内核会偏袒读请求?这是从整体性能上进行考虑的。读请求和应用程序的关系是同步的,因为应用程序要等待读取的内容完毕,才能进行下一步工作,因此读请求会阻塞进程,而写请求则不一样,应用程序发出写请求后,内存的内容何时写入块设备对程序的影响并不大,所以调度器会优先处理读请求。
默认情况下,读请求的超时时间是500ms,写请求的超时时间是5s。
这篇文章说在一些多线程应用下,Deadline算法比CFQ算法好。这篇文章说在一些数据库应用下,Deadline算法比CFQ算法好。
3.3 Anticipatory算法
Anticipatory算法的核心是局部性原理,它期望一个进程做完一次IO请求后还会继续在此处做IO请求。在IO操作中,有一种现象叫“假空闲”(Deceptive idleness),它的意思是一个进程在刚刚做完一波读操作后,看似是空闲了,不读了,但是实际上它是在处理这些数据,处理完这些数据之后,它还会接着读,这个时候如果IO调度器去处理另外一个进程的请求,那么当原来的假空闲进程的下一个请求来的时候,磁头又得seek到刚才的位置,这样大大增加了寻道时间和磁头旋转时间。所以,Anticipatory算法会在一个读请求做完后,再等待一定时间t(通常是6ms),如果6ms内,这个进程上还有读请求过来,那么我继续服务,否则,处理下一个进程的读写请求。
在一些场景下,Antocipatory算法会有非常有效的性能提升。这篇文章有说,这篇文章也有一份评测。
值得一提的是,Anticipatory算法从Linux 2.6.33版本后,就被移除了,因为CFQ通过配置也能达到Anticipatory算法的效果。
4.4 CFQ算法
CFQ(Completely Fair Queuing)算法,顾名思义,绝对公平算法。它试图为竞争块设备使用权的所有进程分配一个请求队列和一个时间片,在调度器分配给进程的时间片内,进程可以将其读写请求发送给底层块设备,当进程的时间片消耗完,进程的请求队列将被挂起,等待调度。 每个进程的时间片和每个进程的队列长度取决于进程的IO优先级,每个进程都会有一个IO优先级,CFQ调度器将会将其作为考虑的因素之一,来确定该进程的请求队列何时可以获取块设备的使用权。IO优先级从高到低可以分为三大类:RT(real time),BE(best try),IDLE(idle),其中RT和BE又可以再划分为8个子优先级。实际上,我们已经知道CFQ调度器的公平是针对于进程而言的,而只有同步请求(read或syn write)才是针对进程而存在的,他们会放入进程自身的请求队列,而所有同优先级的异步请求,无论来自于哪个进程,都会被放入公共的队列,异步请求的队列总共有8(RT)+8(BE)+1(IDLE)=17个。
从Linux 2.6.18起,CFQ作为默认的IO调度算法。
对于通用的服务器来说,CFQ是较好的选择。
五.线程
MySQL每个连接使用一个线程,另外还有内部处理线程、特殊用途的线程,以及所有存储引擎创建的线程。
无论哪种方式,MySQL都需要大量的线程才能有效地工作。MySQL确实需要内核级线程的支持,而不只是用户级线程,这样才能更有效地使用多个CPU。另外也需要有效的同步原子,例如互斥变量。操作系统的线程库必须提供所有的这些功能。
GNU/Linux提供两个线程库:LinuxThreads和新的原生POSIX线程库(NPTL)。LinuxThreads在某些情况下仍然使用,但现在的发行版已经切换到NPTL,并且大部分应用已经不再加载LinuxThreads。NPTL更轻量,更高效,也不会有那些LinuxThreads遇到的问题。
进程很线程的关系:
1、 一个进程可包含多个线程;
2、 每一个程序都至少有一个线程,若程序只有一个线程,那就是程序本身;
3、 地址空间和其它资源(如打开文件):进程间相互独立,同一进程的各线程间共享某进程内的线程在其它进程不可见;
4、 通信:进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信——需要进程同步和互斥手段的辅助,以保证数据的一致性;
5、 调度和切换:线程上下文切换比进程上下文切换要快得多;
6、 在多线程OS中,进程不是一个可执行的实体;
六.内存交换区
当操作系统因为没有足够的内存而将一些虚拟内存写到磁盘就会发生内存交换。内存交换对操作系统中运行的进程是透明的。只有操作系统知道特定的虚拟内存地址是在物理内存还是硬盘。
内存交换对MySQL性能影响是很糟糕的。它破坏了缓存在内存的目的,并且相对于使用很小的内存做缓存,使用交换区的性能更差。MySQL和存储引擎有很多算法来区别对待内存中的数据和硬盘上的数据,因为一般都假设内存数据访问代价更低。
因为内存交换对用户进程不可见,MySQL(或存储引擎)并不知道数据实际上已经移动到磁盘,还会以为在内存中。
结果会导致很差的性能。例如,若存储引擎认为数据依然在内存,可能觉得为“短暂”的内存操作锁定一个全局互斥变量(例如InnoDB缓冲池Mutex)是OK的。如果这个操作实际上引起了硬盘I/O,直到I/O操作完成前任何操作都会被挂起。这意味着内存交换比直接做硬盘I/O操作还要糟糕。
在GNU/Linux上,可以用vmstat来监控内存交换。最好查看si和so列报告的内存交换I/O活动,这比看swpd列报告的交换区利用率更重要。swpd列可以展示那些被载入了但是没有被使用的进程,它们并不是真的会成为问题。我们喜欢si和so列的值为0,并且一定要保证它们低于每秒10个块。
极端的场景下,太多的内存交换可能导致操作系统交换空间溢出。如果发生了这种情况,缺乏虚拟内存可能让MySQL崩溃。但是即使交换空间没有溢出,非常活跃的内存交换也会导致整个操作系统变得无法响应,到这种时候甚至不能登录系统去杀掉MySQL进程。有时当交换空间溢出时,甚至Linux内核都会完全hang住。
绝不要让系统的虚拟内存溢出!对交换空间利用率做好监控和报警。如果不知道需要多少交换空间,就在硬盘上尽可能多地分配空间,这不会对性能造成冲击,只是消耗了硬盘空间。有些大的组织清楚地知道内存消耗将有多大,并且内存交换被非常严格地控制,但是对于只有少量多用途的MySQL实例,并且工作负载也多种多样的环境,通常不切实际。如果后者的描述更符合实际情况,确认给服务器一些“呼吸”的空间,分配足够的交换空间。
在特别大的内存压力下经常发生的另一件事是内存不足(OOM),这会导致踢掉和杀掉一些进程。在MySQL进程这很常见。在另外的进程上也挺常见,比如SSH,甚至会让系统不能从网络访问。可以通过设置SSH进程的oom_adj或oom_score_adj值来避免这种情况。
可以通过正确地配置MySQL缓冲来解决大部分内存交换问题,但是有时操作系统的虚拟内存系统还是会决定交换MySQL的内存。这通常发生在操作系统看到MySQL发出了大量I/O,因此尝试增加文件缓存来保存更多数据时。如果没有足够的内存,有些东西就必须被交换出去,有些可能就是MySQL本身。有些老的Linux内核版本也有一些适得其反的优先级,导致本不应该被交换的被交换出去,但是在最近的内核都被缓解了。
有些人主张完全禁用交换文件。尽管这样做有时在某些内核拒绝工作的极端场景下是可行的,但这降低了操作系统的性能(在理论上不会,但是实际上会的)。同时这样做也是很危险的,因为禁用内存交换就相当于给虚拟内存设置了一个不可动摇的限制。如果MySQL需要临时使用很大一块内存,或者有很耗内存的进程运行在同一台机器(如夜间批量任务),MySQL可能会内存溢出、崩溃,或者被操作系统杀死。
如下是发生了内存交换的机器
