一、SQL 优化
1.1 常用基础 SQL 语句优化
1.1.1 减少使用“SELECT * ”
SELECT语句中可以用“*”来列出某个表的所有列名,但是这样的写法对Oracle系统来说存在解析的动态问题。Oracle系统会通过查询数据字典来将“*”转换成表的所有列名,这自然会消耗系统时间。建议用户在写SELECT语句时,采用与访问表有关的实际列名。
示例
这里已经创建好了一个USERS表,里面有ID、NAME、AGE、SEX、PHONE字段,并有20853条数据。下面使用SELECT *,和不使用*作比较。
SELECT * FROM USERS;
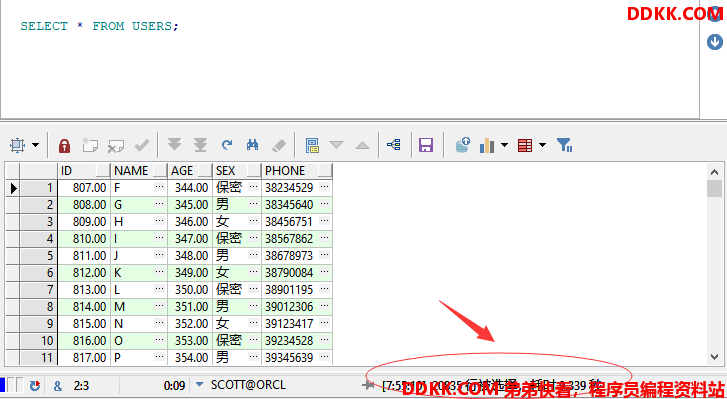
SELECT ID, NAME, AGE, SEX, PHONE FROM USERS;
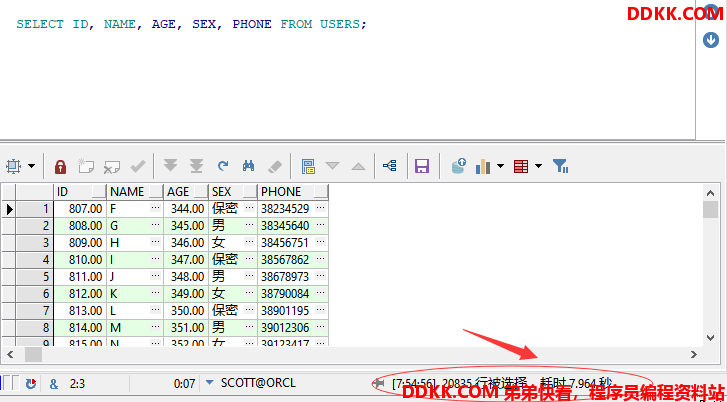
可以发现,使用SELECT * FROM USERS所消耗的事件为9.339秒,而将*转换成对应的字段时,使用SELECT ID, NAME, AGE, SEX, PHONE FROM USERS,消耗的时间则是7.964秒。
虽然这里看着只相差2秒左右的时间,但是在实际使用总,可能会有很多个表一起查询,而且每个表的字段也可能会很多,这样就会严重耗费时间,所以建议在查询时尽量使用对应的字段而不是使用*来查询所有,只取需要的字段,节省资源、减少网络开销。。
1.1.2 用TRUNCATE代替DELETE
当使用DELETE删除表中的数据行时,Oracle会使用撤销表空间(UNDO TABLESPACE)来存放恢复的信息。在这期间,如果用户没有发出COMMIT命令,而是发出ROLLBACK命令,Oracle系统会将数据恢复到删除之前的状态。
当用户使用TRUNCATE语句对表的数据进行删除时,系统不会将被删除的数据写到回滚段(或撤销表空间)中,速度当然要快得多。所以当希望对表或者簇中的所有行全部删除时,采用TRUNCATE命令更加有效。
TRUNCATE命令语法格式如下:
Truncate [table | cluster] schema.[table_name] [cluster_name] [drop | reuse storage]
- table_name:要清空的表名。
- cluster_name:要清空的簇名。
- drop | reuse storage:表示保留被删除的空间以供该表的新数据使用或回收空间,默认为drop storage,即收回被删除的空间系统。
示例
DELETE FROM USERS;
TRUNCATE TABLE USERS;
1.1.3 确保完整情况下多使用COMMIT语句
在PL/SQL块中,经常将几个相互联系的DML语句写在一个BEGIN…END块中,建议在每个块的END前面使用COMMIT语句,这样就可以实现对象DML语句的及时提交,同时也释放事务所占用的资源。
COMMIT语句所释放的资源如下。
- 回滚段上用于恢复数据的信息,撤销表空间也只做短暂的保留。
- 被程序语句获得的锁。
- redo log buffer中的空间。
- Oracle为管理上述资源的内部花费。
1.1.4 尽量减少表的查询次数
在含有子查询的SQL语句中,要特别注意减少对表的查询。
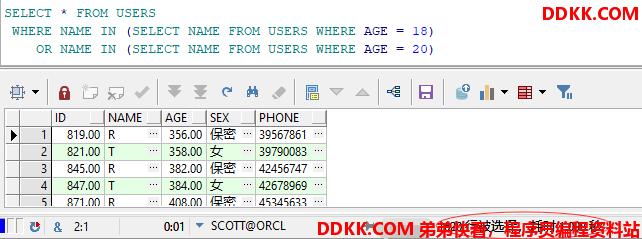
示例: 第一种:低效率的SQL查询语句。
SELECT * FROM USERS
WHERE NAME IN (SELECT NAME FROM USERS WHERE AGE = 18)
OR NAME IN (SELECT NAME FROM USERS WHERE AGE = 20)
查询结果和时间消耗如下
第二种:对上面的代码进行适当修改,高效率的SQL查询语句如下。
SELECT * FROM USERS WHERE NAME IN (
SELECT NAME FROM USERS WHERE AGE = 18 OR AGE = 20)
查询结果和时间消耗如下
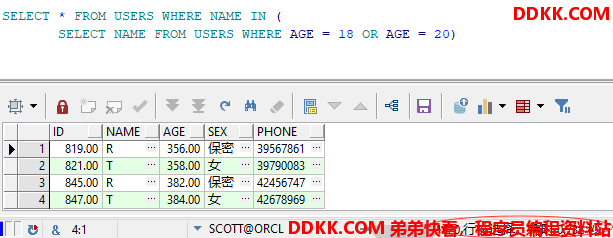
从上面的对比结果可以发现,在第一种查询语句中,要对USERS表执行两遍的查询,而在第二种查询中,仅对USERS表执行一遍查询。在大量数据的情况下,显然第二种查询要比第一种查询快得多。
1.1.5 用[NOT] EXISTS代替[NOT] IN
在子查询中,[NOT] IN子句将执行一个内部的排序与合并,无论在哪种情况下,[NOT] IN语句都是最低效的,因为它对子查询中的表执行了一个全表遍历。
为了避免使用[NOT] IN,用户可以把它改写成外连接(OUTER JOINS)、NOT EXISTS或者EXISTS子句,如下面的两段代码。
示例 第一种:低效率的NOT IN子句。
SELECT EMPNO, ENAME FROM EMP
WHERE EMPNO NOT IN(SELECT DEPTNO FROM DEPT WHERE LOC= 'BEIJING');
第二种:高效率的EXISTS子句。
SELECT EMPNO, ENAME FROM EMP
WHERE EXISTS (SELECT DEPTNO FROM DEPT WHERE LOC != 'BEIJING');
在SQL语句中,许多资料都建议最好不用[NOT] IN。那么,[NOT] IN在何处可以用呢?这里要一分为二地看[NOT] IN:
- 当[NOT] IN后面跟子查询,并且查询的结果集较多时,不宜使用[NOT] IN;
- 当[NOT] IN后面的括号内是列表(可枚举的几个)或子查询所满足的结果集很小时,也是可以使用的。
1.1.6 LIMIT的使用
在编写SQL时,如果已经知道查询的结果只有一条或者几条,可以使用limit进行限制。示例如下
(1)示例1
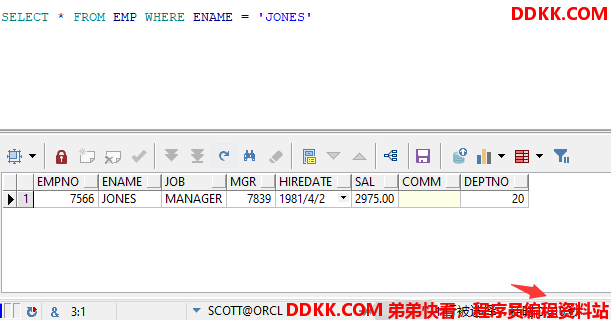
不使用LIMIT
SELECT * FROM EMP WHERE ENAME = 'JONES'
查询结果及耗时
使用LIMIT
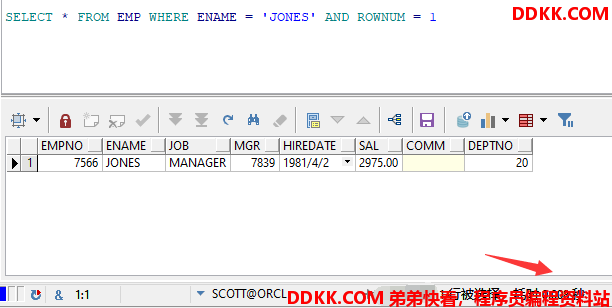
SELECT * FROM EMP WHERE ENAME = 'JONES' AND ROWNUM = 1
查询结果及耗时
(2)示例2
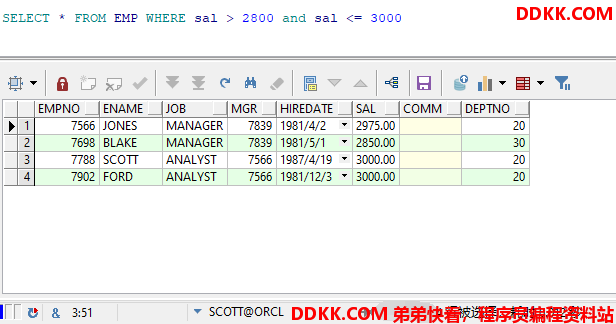
不使用LIMIT
SELECT * FROM EMP WHERE sal > 2800 and sal <= 3000
使用LIMIT
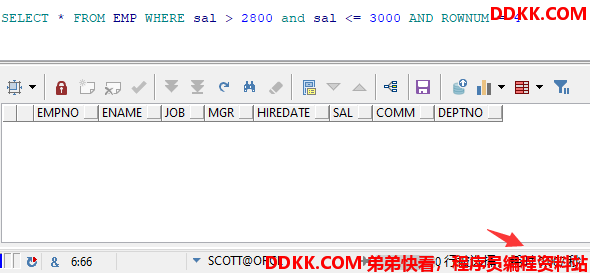
加上limit后,当SQL执行到找到了对应的记录时,就不会继续向下执行和扫描了,效率将会大大提高。
当然,如果条件字段(NAME和SAL)是唯一索引的话,是不必要加上limit了,因为limit的存在主要就是为了防止全表扫描,从而提高性能,如果编写的SQL实现就知道不会全表扫描的化,添加LIMIT的意义就不大了。
1.1.7 WHERE 条件后减少 OR 关键字的使用
使用OR关键字可能会使索引失效,从而全表扫描。
示例 使用OR关键字
SELECT * FROM USERS WHERE AGE = 18 OR AGE = 25
查询结果及耗时
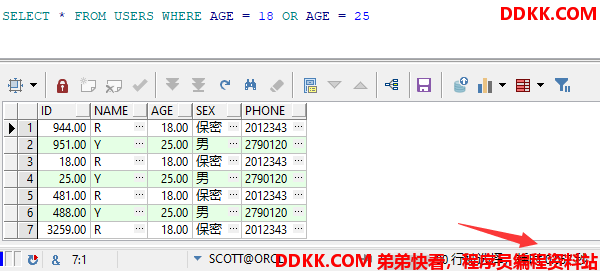
不使用OR关键字
SELECT * FROM USERS WHERE AGE = 18
UNION ALL
SELECT * FROM USERS WHERE AGE = 25
查询结果及耗时
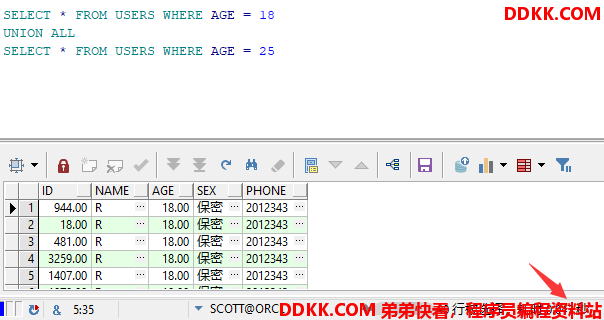
对于AGE字段没有索引的情况下,使用OR关键字,假设SQL执行时走了ID的索引,但是走到AGE查询条件时,它还得全表扫描,也就是需要三步过程:全表扫描+索引扫描+合并。如果它一开始就执行全表扫描来查询,直接一遍扫描就结束了。
1.1.8 LIKE 关键字的使用优化
LIKE关键字在实际工作种常被用来进行模糊查询,但是LIKE关键字很有可能会使索引失效。
SELECT * FROM USERS WHERE ID LIKE '%123%'
这种SQL在执行的时候就不会引用索引,但是下面这种就会引用索引
SELECT * FROM USERS WHERE ID LIKE '123%'
1.1.9 UNION 和 UNION ALL 关键字
UNION在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。实际大部分应用中是不会产生重复的记录。如:
SELECT ID, NAME, AGE, SEX FROM USERS
UNION
SELECT ID, NAME, AGE, SEX FROM STUDENTS
这个SQL在运行时先取出两个表的结果,再用排序空间进行排序删除重复的记录,最后返回结果集,如果表数据量大的话可能会导致用磁盘进行排序。
这时可以采用UNION ALL操作符替代UNION,因为UNION ALL操作只是简单的将两个结果合并后就返回。
SELECT ID, NAME, AGE, SEX FROM USERS
UNION ALL
SELECT ID, NAME, AGE, SEX FROM STUDENTS
1.1.10 > 及 < 操作符(大于或小于操作符)
大于或小于操作符一般情况下是不用调整的,因为它有索引就会采用索引查找,但有的情况下可以对它进行优化。
例如:一个表MONEY有100万记录,表中有一个数值型字段NUM,其中NUM=0的记录有30万条,NUM=1的记录有30万条,NUM=2的记录有39万条,NUM=3的记录有30万条,现在要查询表NUM>=3的记录,有如下两种写法
写法1:
SELECT * FROM MONEY WHERE NUM > 2;
写法2:
SELECT * FROM MONEY WHERE NUM >= 3;
SQL在执行NUM > 2与NUM >= 3时就会有很大的区别,写法1在执行时ORACLE会先找出为NUM=2的记录索引再进行比较,而写法2在执行时ORACLE则直接找到NUM=3的记录索引。
1.2 表连接查询 SQL 语句优化
1.2.1 驱动表的选择
驱动表(Driving Table)是指被最先访问的表(通常以全表扫描的方式被访问)。Oracle 11g优化器会检查SQL语句中的每个表的物理大小、索引状态,然后选用花费最低的执行路径。
示例
SELECT * FROM STUDENTS A, USERS B WHERE A.NAME = B.NAME
在上面的代码中,假设在USERS 表的NAME列创建了索引,而在STUDENTS 表的NAME列没有索引。由于STUDENTS 最先被访问(紧随FROM其后),这样STUDENTS 表将被作为查询中的驱动表,由此可见,只有两个表都建立有索引,优化器才能按照紧随FROM关键字后面的为驱动表的规则来对待。
1.2.2 WHERE 字句的连接顺序
Oracle采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前。那些可以过滤掉最大数据记录的条件必须写在WHERE子句的末尾,也就是在表进行连接操作以前,过滤掉的记录越多越好。
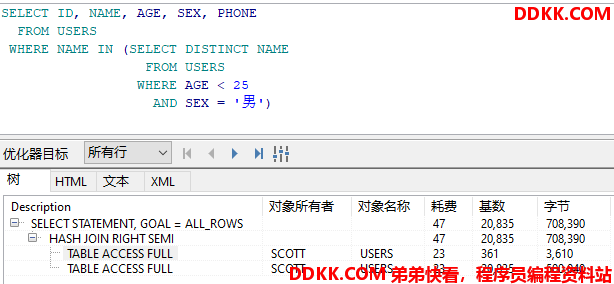
示例 第一种:先连接表,然后再过滤记录
SELECT *
FROM USERS A, USERS B
WHERE A.NAME = B.NAME
AND A.SEX = '男'
AND A.AGE < 25
AND B.AGE < 25
AND A.NAME = 'S'
查询结果及耗时如下
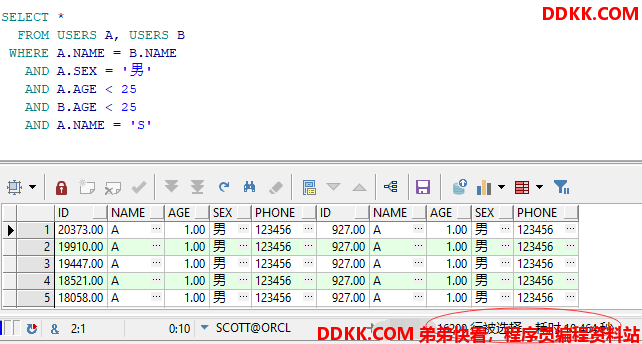
第二种:在表连接之前过滤记录
SELECT *
FROM USERS A, USERS B
WHERE A.AGE < 25
AND B.AGE < 25
AND A.SEX = '男'
AND A.NAME = B.NAME
查询结果及耗时如下
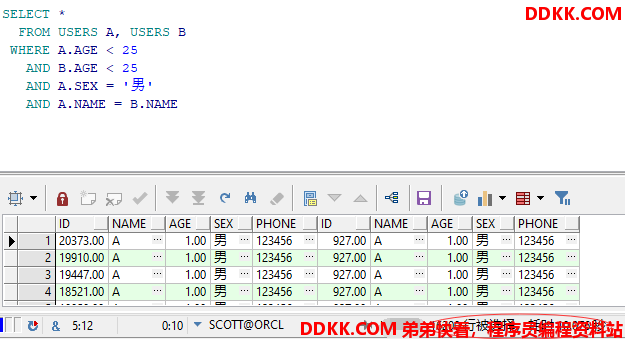
二、使用索引进行优化
创建主键和唯一索引的主要目的除了数据的完整性和一致性之外,还具有提高查询速度的作用。此外,创建一般索引的目的就是为了提高查询速度。
2.1 索引介绍
在利用索引的情况下,由于只从表中选择部分行,所以能够提高查询速度。对于只从总行数中查询2%~4%的表,可以考虑创建索引。
创建索引的基本原则:
- 以查询关键字为基础,表中的行随机排序。
- 包含的列数相对比较少的表。
- 表中的大多数查询都包含相对简单的WHERE从句。
- 经常以查询关键字为基础的表,并且该表中的行遵从均匀分布。
- 缓存命中率低,并且不需要操作系统权限。
2.2 索引列和表达式的选择
在创建索引时,选择列和表达式是非常重要的,如下是创建索引时选择索引列的原则:
- WHERE从句频繁使用的字段列。
- SQL语句中频繁使用进行表连接的字段列。
- 可选择性高(重复性少的)字段列。
- 对于取值较少的字段列或表达式,不要采用标准的B树索引,可以考虑建立位图索引。
- 不要将那些频繁修改的列作为索引列。
- 不要使用包含操作符或函数的WHERE从句中的字段列作为索引列,如果需要的话,可以考虑建立函数索引。
- 如果大量并发的INSERT、UPDATE、DELETE语句访问了父表或者子表,则考虑使用完整性约束的外部键作为索引。
- 在选择索引列时,还要考虑该索引所引起的INSERT、UPDATE、DELETE操作是否值得。
2.3 选择复合索引主列
多列索引也叫做复合索引,复合索引有时比单列索引有更好的性能。如果在建立索引时采用了几个列作为索引,则在使用时也要按照建立时的顺序来描述,也就是说,主列是最先被选择的列。
示例 在USERS表的AGE字段创建索引
//创建单列索引
CREATE INDEX INDEX_AGE ON USERS(AGE)
SELECT * FROM USERS WHERE AGE < 50
//创建复合索引
CREATE INDEX INDEX_COMPLEX ON USERS(AGE, SEX)
SELECT * FROM USERS1 WHERE AGE < 50 AND SEX = '男'
当索引被建立成复合型,在查询语句中要带有WHERE…AND从句才能使用该复合索引。
在选择复合索引的关键字时,要遵循下列的原则:
- 如果某些关键字在WHERE从句中的使用频率较高,则考虑创建索引。
- 如果某些关键字在WHERE从句中的使用频率相当,则创建索引时考虑按照从高到低的顺序来说明关键字。
- 如果几个查询都选择相同的关键字集合,则考虑创建组合索引。
- 创建索引以后使得WHERE从句所使用的关键字能够组成前导部分。
- 应该选择在WHERE从句条件中频繁使用的关键字,并且这些关键字由AND操作符连接。
2.4 避免全表扫描大表
在应用程序设计中,除了一些必要的情况,如月报数据的统计,打印所有清单等任务可以允许使用全表扫描外,一般都应尽量避免对大表进行全表扫描,全表扫描就是指不加任何条件或没有使用索引的查询语句。
以下情况Oracle就可以使用全表扫描。
- 所查询的表没有索引。
- 需要返回所有的行。
- 带LIKE并使用‘%’这样的语句就是全表扫描。
- 对索引主列有条件限制,但使用了函数,则Oracle使用全表扫描
SELECT * FROM USERS WHERE SUBSTR(PHONE,1,4) = '1234'
带有is null、is not null或!=等字句也导致全表扫描,比如下面的代码:
SELECT * FROM USERS WHERE AGE != 20
2.5 监视索引是否被使用
除了主键是完整性约束而自动变为索引外,创建普通索引的目的就是为了提高查询速度。如果我们创建了索引而索引没有被使用,那么这些不被使用的索引将起到阻碍性能的作用。
为了辨别索引是否被使用,从Oracle 9i版本开始,用户可以对索引进行监视,通常使用ALTER INDEX…MONITORING USAGE语句,示例如下:
设置监视索引INDEX_SEX :
ALTER INDEX INDEX_SEX MONITORING USAGE;
检查索引使用情况,代码如下:
ALTER INDEX INDEX_SEX MONITORING USAGE;
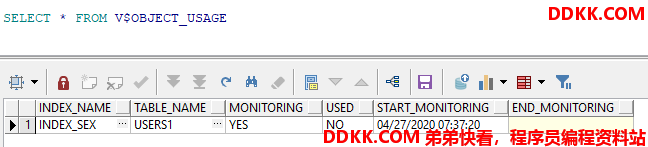
在检查索引使用情况种,如果发现索引INDEX_SEX 在限定的时间内得不到使用(即USE列的值为NO),则建议使用DROP INDEX语句删除掉,代码如下:
DROP INDEX INDEX_SEX;
索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
三、其他优化方法
3.1 Oracle 优化器的使用
3.1.1 优化器的概述
尽管现在计算机的CPU速度达到GB级,但在处理数据库时还是显得不够。在大型应用系统中,存在许多消耗CPU大量时间的SQL语句,但是却很少被程序员本人发现。 实际上,Oracle优化器在处理每一个SQL语句准备执行之前,都需要进行许多步骤才能使SQL语句成为可执行的语句。
(1)语法检查:检查SQL语句的拼写是否正确。
(2)语义分析:核实所有与数据字典不一致的表和列的名字。
(3)概要存储检查:检查数据字典,以确定该SQL语句的概要是否已经存在。
(4)生成执行计划:使用基于成本的优化规则和数据字典的统计表来决定最佳执行计划。
(5)建立二进制代码:基于执行计划,Oracle生成了二进制执行代码。
为了使每条SQL语句的性能达到优化,建议用户对所有的SQL语句执行EXPLAIN PLAN命令,并查看输出结果,然后对性能低下的SQL语句进行调整。 通过设置执行计划(即EXPLAIN PLAN命令),可以了解Oracle在执行SELECT、DELETE、INSERT、UPDATE语句时的情况。
所谓SQL语句执行计划就是Oracle优化器在执行每个SQL语句时所采用的执行顺序。执行计划包括以下的几个方面:
- 语句所引用的表的顺序。
- 语句所涉及的表的访问方法。
- 语句中连接操作所影响到的各表的连接方法。
Oracle 11g数据库在执行SQL语句时,都是使用基于代价(或者成本)的优化器—这个代价(或者成本)就是指占用一定的系统资源。
3.1.2 运行EXPLAIN
PLAN 执行计划是Oracle系统在执行SQL语句时的一种执行策略。那么,用户如何看到这些执行计划的内容呢? 为了得到Oracle产生的执行计划的报告,必须创建一个表来存放系统检查SQL语句执行计划时所产生的结果,建议在用户的账户下执行UTLXPLAN脚本来完成PLAN_TABLE表的创建,该表存放执行计划的信息。
当运行了UTLXPLAN.SQL这个脚本后,Oracle在用户的账户下创建了TABLE_NAME表。该表用于存放用户希望产生的SQL语句的执行计划。
EXPLAIN PLAN命令的语法如下:
EXPLAIN PLAN [SET STATEMENT_ID [=] <STRING LITERAL>]
[INTO <TABLE_NAME>]
FOR <SQL_STATMENT>
3.1.3 Oracle 11g中SQL执行计划的管理
Oracle在执行一个SQL之前,首先要分析一下语句的执行计划,然后再按执行计划去执行。分析语句执行计划的工作是由优化器(Optimizer)来完成的。不同的情况下,一条SQL可能有多种执行计划,但在某一时刻,一定只有一种计划是最优的,花费时间是最少的。
Oracle 11g使用基于代价的优化方式(Cost_Based Optimization,简称为CBO),这里的代价主要指CPU和内存,优化器主要参照的是表及索引的统计信息。统计信息给出表的大小、有多少行、每行的长度等信息。这些统计信息起初在数据库内是没有的,是用户在做ANALYZE(统计分析)后才出现的。很多时候,过期统计信息会令优化器做出一个错误的执行计划,因此用户应及时更新这些信息。
3.2 Oracle 数据库和 SQL 重演
3.2.1 数据库重演
数据库重演(Database Replay)是指在产品环境的数据库上捕获所有负载,并可以将之传送至备份的(Standby)数据库或有备份恢复的测试库上,在测试环境中重演主库的环境,这使得升级或软件更新可以进行预先的“真实”测试,或者可以通过测试环境完全再现真实环境的负载及运行情况。
这是Oracle向后追溯能力的又一增强,在Oracle 10g中,Oracle通过V$SESSION_WAIT_HISTORY视图、ASH特性等,实现将数据库的等待时间向后追溯。现在通过Database Replay特性,Oracle可以将整个数据库的负载捕获、记录并实现Replay,也就是增强了整个数据库的向后追溯能力。
这一特性提供了再现现场能力,极大地丰富了用户发现并解决数据库问题的手段,将为数据库管理带来更多的方便。 当然使用这一特性会带来一定的性能负担,Oracle说这一负担在5%左右。
3.2.2 SQL 重演
数据库重演的简化版本就是SQL 重演(SQL Replay),即只捕获SQL负载,通过SQL负载,应用程序可以再现SQL影响。
Oracle已经有了一系列的Flashback技术(即闪回技术),现在又有了Replay技术。Flashback可以向后闪回,Replay可以向前推演,Oracle给用户提供的手段越来越多了。
3.3 Oracle 的性能顾问
3.3.1 Oracle 的性能顾问介绍
Oracle数据库中有一位自动数据库诊断监控程序(ADDM)形式的助理DBA,这种机器人式的DBA会不知疲倦地反复搜索数据库性能统计,以标识瓶颈、分析SQL语句,并据此提供多种改进性能的建议。
Oracle自动SQL调整解决方案包括SQL调优顾问(SQL Tuning Advisor)和SQL访问顾问(SQL Access Advisor),可以为应用程序提供综合、自动、具有成本效益的解决方案,减少SQL的调整时间和管理成本。
3.3.2 SQL调优顾问
SQL调优顾问(SQL Tuning Advisor)是Oracle 10g中引入的,设计它的目的就是为了替代传统的手工SQL调整。
SQL调优顾问处理的对象包括那些响应时间很慢或者是占用CPU/DISK很高的SQL,SQL调优顾问收集这些SQL,并且给出自己的建议,它包括下面的部分:
- 怎样调整SQL的执行计划。
- 优化后效率的提升幅度。
- 做出这条建议的理论原理。
- 直接给出推荐使用的命令。
用户可以有选择性地接收这些建议,然后去调优SQL。随着SQL调优顾问的引入,用户现在就可以让Oracle优化器来自动地调整SQL。
3.3.3 SQL访问顾问
SQL访问顾问(SQL Access Advisor)的设计目的是获得有关基于实际频率和使用类型(而非数据类型)进行分区、索引和创建物化视图以改进模式设计的建议。
SQL访问顾问与SQL调优顾问提供有关查询、调整及在流程中延长整个优化过程的建议有所不同,它的特点如下:
- 分析整个负载而不仅仅是单独的SQL语句。
- 使访问结构设计更加清晰,以优化应用程序性能。
- 建议创建和删除某些索引、物化视图和物化视图日志以提高性能。
Oracle 11g的SQL访问顾问除了可以像在Oracle 10g中一样分析索引、物化视图等,还可以分析表和查询以识别可能的分区策略,这在进行最佳模式设计时可以提供很大的帮助。在Oracle 11g中,SQL访问顾问可以提供与整个负载相关的建议,包括考虑创建成本和维护访问结构等。
3.4 其他方面的优化
(1)尽量减少在 where 关键字后面的筛选条件语句的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引,如:
select id from t where substr(name,1,3) = 'abc'
应改为:
select id from t where name like 'abc%'
(2)尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
(3)应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
(4)尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
(5)尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
(6)尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。
(7)避免频繁创建和删除临时表,以减少系统表资源的消耗。
(8)临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。
(9)尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
(10)在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。