Oracle提供了一个强大的SQL引擎,使得用户可以通过SQL语言来管理和操作数据库。
1. 基本查询
以CAP(顾客-代理-产品)数据库为例,表结构如下:
CUSTOMERS(顾客信息表)
-
cid 顾客ID
-
cname 顾客姓名
-
city 顾客所在城市
-
discnt 顾客可能会有的折扣
-
AGENTS 代理商信息表
-
aid 代理商ID
-
aname 代理商名称
-
city 代理商所在城市
-
percent 代理商每笔交易所能获得佣金的百分比
-
PRODUCTS( 商品信息表 )
-
pid 商品ID
-
pname 商品名称
-
city 商品库存所在城市
-
quantity 商品库存数量
-
price 商品批发价
-
ORDERS( 订单信息表)
-
ordno 订单ID
-
Month 订单月份
-
cid 顾客ID
-
aid 代理商ID
-
pid 商品ID
-
qty 数量
-
dollars 商品总价
(1)All
找出佣金百分率最小的代理商aid
select aid from agents where percent <=all (select percent from agents);
(2)in/exists 子查询
EXISTS用于检查subquery是否至少会返回一行数据,subquery 是一个受限的 SELECT 语句 (不允许有 COMPUTE 子句和 INTO 关键字) 返回一个结果集,EXISTS子句根据其内查询语句的结果集空或者非空,返回一个布尔值True或False。一种通俗的可以理解为:将外查询表的每一行,代入内查询作为检验,如果内查询返回的结果取非空值,则EXISTS子句返回TRUE,这一行行可作为外查询的结果行,否则不能作为结果。
NOT EXISTS 的作用与 EXISTS 正好相反。如果子查询没有返回行,则满足了 NOT EXISTS 中的 WHERE 子句。
找出既订购了产品p01有订购了产品p07的顾客cid
关系代数 π c i d ( σ p i d = ’ p 01 ’ ( O ) ) ∩ π c i d ( σ p i d = ’ p 07 ’ ( O ) ) π_{cid}(σ_{pid=’p01’}(O))∩ π_{cid}(σ{pid=’p07’}(O)) πcid(σpid=’p01’(O))∩πcid(σpid=’p07’(O))SQL语句
select distinct cid from orders x where x.pid=‘p01’ and exists (select * from orders y where x.cid=y.cid and y.pid=‘p07’);
或
select distinct x.cid from orders x,orders y where x.pid=‘p01’ and x.cid=y.cid and y.cid=‘p07’ ;
找出没有通过代理商a03订货的顾客cid
关系代数: π c i d ( O ) — π c i d ( σ a i d = ’ a 03 ’ ( O ) ) π_{cid}(O)—π_{cid}(σ_{aid=’a03’}(O)) πcid(O)—πcid(σaid=’a03’(O))SQL语句
select distinct cid from orders x where not exists (select * from orders where cid=x.cid and aid=‘a03’);
EXISTS的查询一般能找到等价的其他查询形式,如
select distinct t.xk from bm_zyml t where not exists (select * from bm_xk s where s.mc= t.xk);
等价于
select distinct t.xk from bm_zyml t where t.xk not in (select s.mc from bm_xk s)
通常情况下采用exists要比in效率高,因为in不走索引,但一般in适合于外表大而内表小的情况,exists适合于外表小而内表大的情况。
(3)union/except/intersect
union
包含了顾客所在的或代理商所在或两者皆在的城市名单:
select city from customers union select city from agents;#不含重复行
select city from customers union all select city from agents;# 含有重复行
- except:返回在 TABLE1 中但不在 TABLE2 中的行并消除所有重复行。
- intersect:返回 TABLE1 和 TABLE2 中都有的行并消除所有重复行。
(4)group by
每个代理商为顾客c002和c003订购产品及产品总数量:
select a.aid,aname,p.pid,pname,sum(qty)
from orders x,products p,agents a
where x.pid=p.pid and x.aid=a.aid
and x.cid in (‘c002’,’c003’)
group by a.aid,a.aname,p.pid,p.pname;
group by 后可跟多个字段
(5)having
至少两个顾客订购的产品pid:
select pid from orders
group by pid having count(distinct cid) >=2
(6)聚集函数:avg, max, min, sum, count
聚焦函数不能作为条件用在where子句中,需要与having,group一起使用
所有代理商的最大销售额的平均值:
select avg(select max(dollars) from orders group by aid);
删除总订货金额小于600的代理商:
delete from agents where aid in (select aid from orders group by aid having sum(dollars)<600);
2. 连接查询
例如图书馆借阅系统,表book与student结构如下:
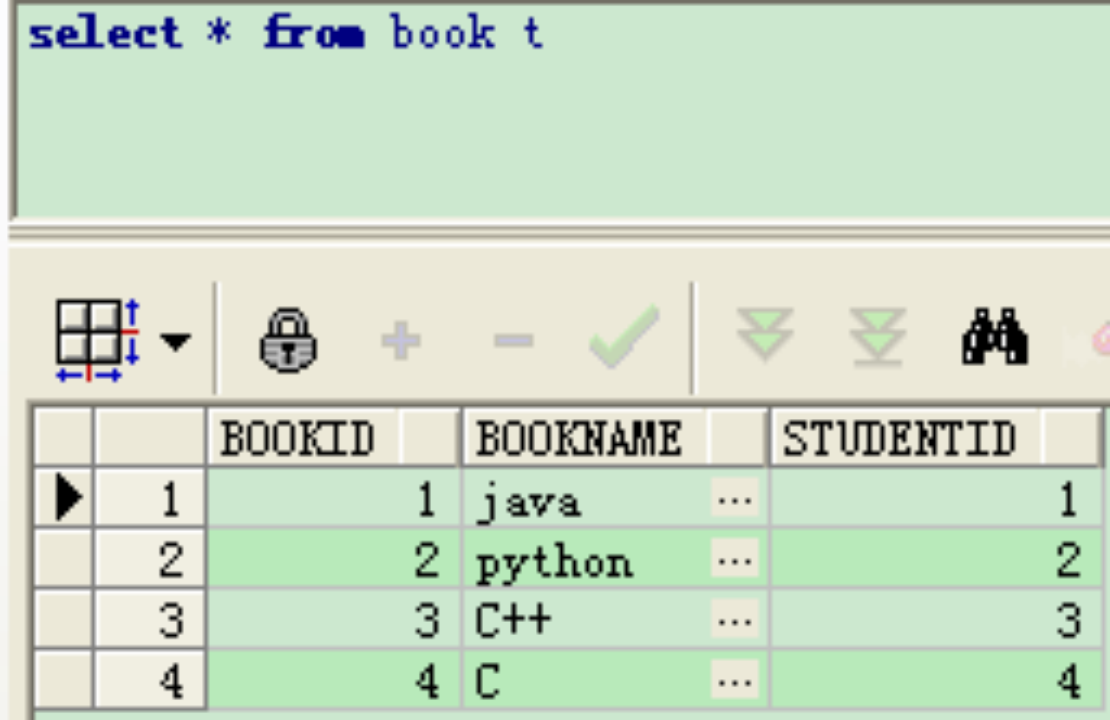
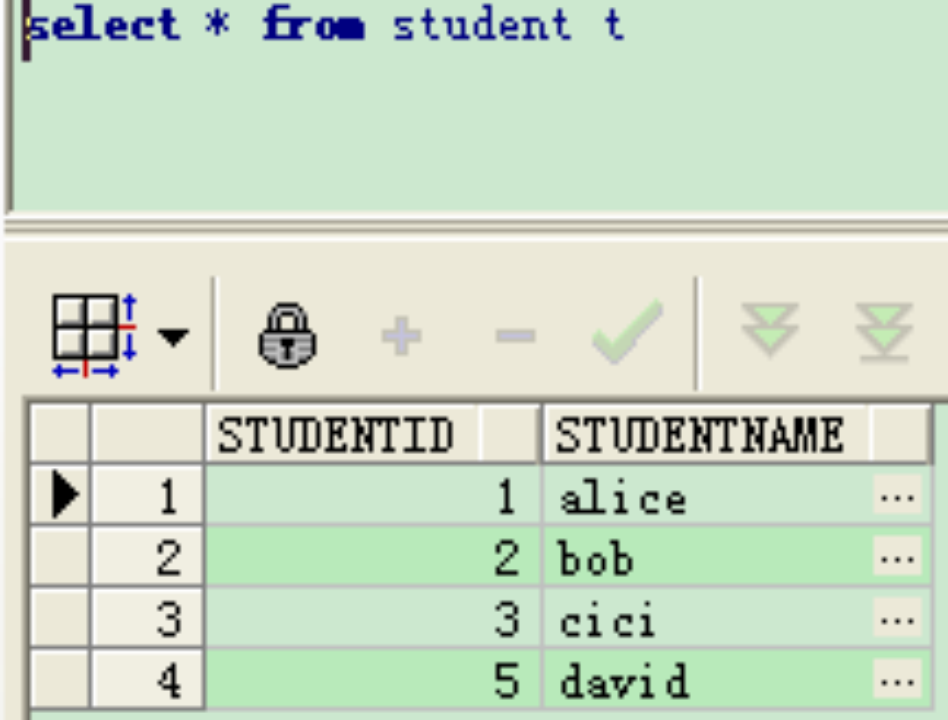
(1)内连接
内连接查询操作列出与连接条件匹配的数据行,它使用比较运算符比较被连接列的列值。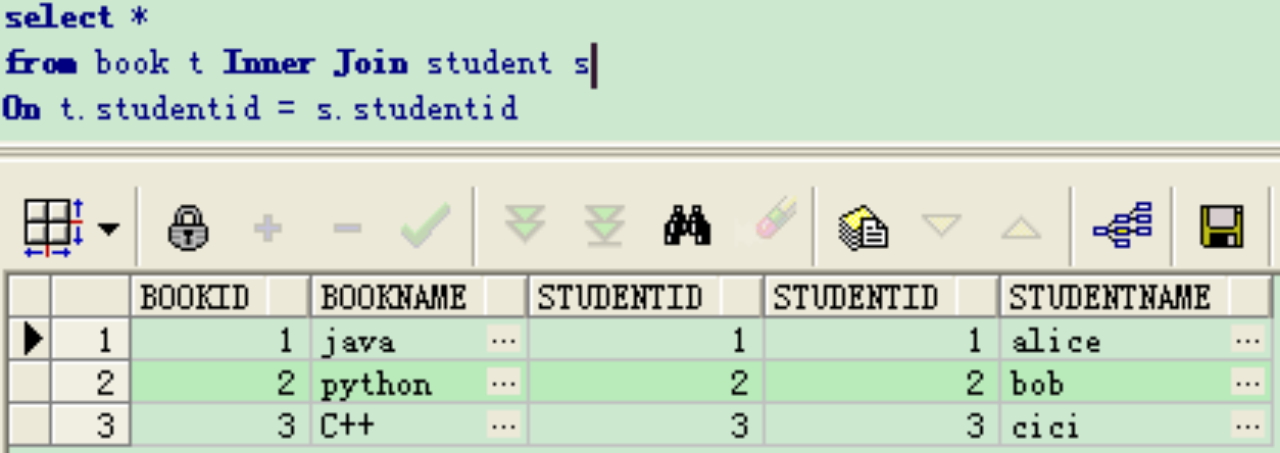
上述SQL等价于
select * from book t, student s where t.studentid=s.studentid
(2)外连接
外连接返回到查询结果集合中的不仅包含符合连接条件的行,而且还包括左表(左外连接时)、右表(右外连接时)或两个边接表(全外连接)中的所有数据行,无匹配的显示空值。
左外连接(left join)
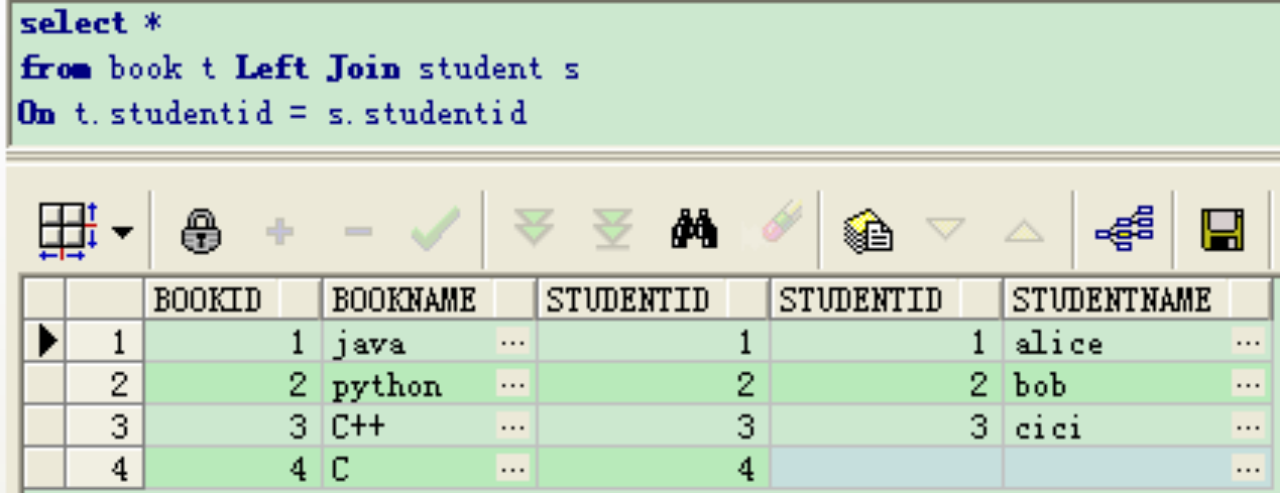
上述SQL等价于
select * from book t, student s where t.studentid(+) = s.studentid
右外连接(right join)
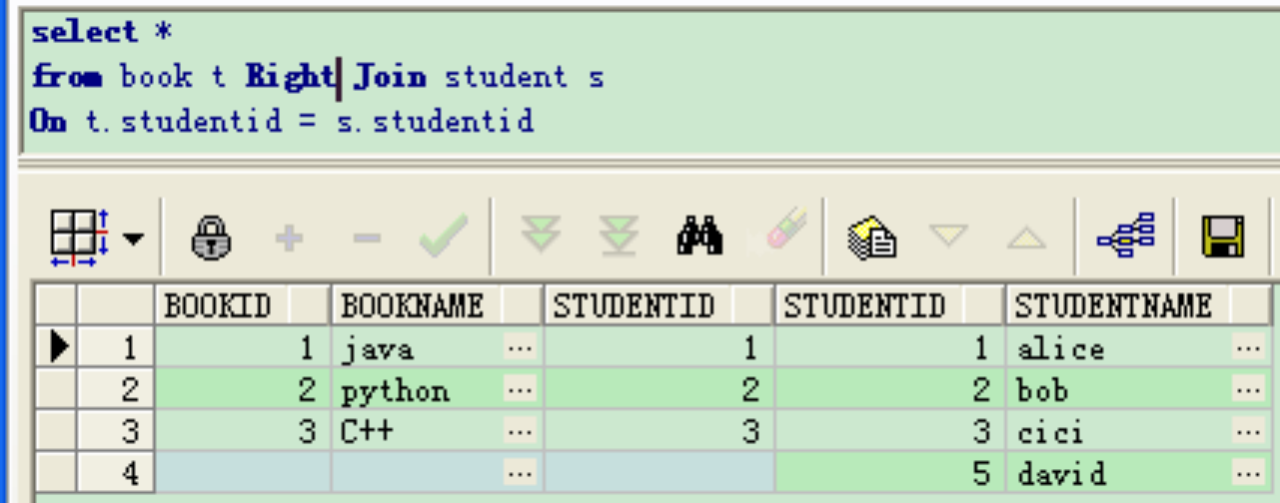
上述SQL等价于
select * from book t, student s where t.studentid = s.studentid(+)
全外连接(full join)
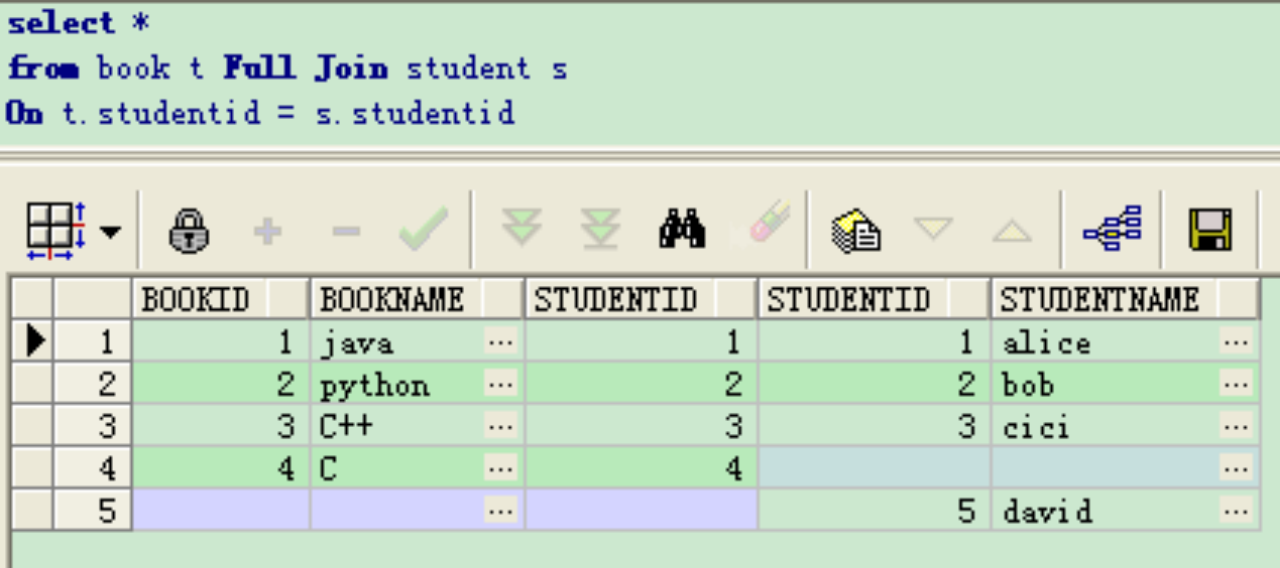
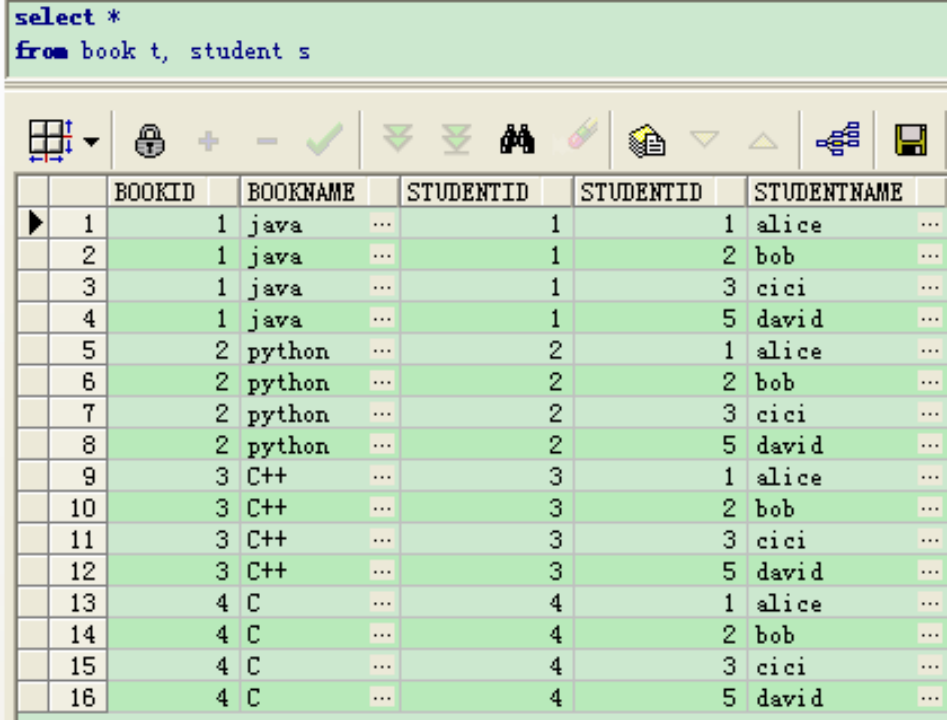
(3)交叉连接交叉连接不带WHERE子句,它返回被连接的两个表所有数据行的笛卡尔积,返回到结果集合中的数据行数等于第一个表中符合查询条件的数据行数乘以第二个表中符合查询条件的数据行数。
3. SQL语句解析
SQL解析指的是Oracle数据库将用户提交的SQL语句转换成可以执行的代码的过程,主要包括三个阶段:分析、优化和执行。
(1)分析
符号检查和词法分析:Oracle会检查SQL语句中的每个字符,确保都是有效的标识符,并且符合数据库中定义的规则。如果Oracle发现了任何错误或不合法的字符,它将抛出一个错误,并停止解析过程。
语法分析:Oracle根据SQL语句的语法规则,将其分解为多个操作和表达式。例如,SQL语句中的SELECT语句可以被分解为列名、FROM子句、WHERE子句等部分。如果Oracle发现了任何语法错误,它也会抛出一个错误并停止解析过程。
语义分析:Oracle将确定SQL语句中每个表、列名和函数是否存在、是否被正确引用,并且它们的数据类型是否兼容。如果Oracle发现了任何不兼容的类型或其他不一致的引用,它也会抛出一个错误并停止解析过程。
(2)优化
优化器处理:Oracle将执行一系列的优化规则,以便找到SQL语句的最佳执行计划。这些规则包括索引选择、连接顺序和扫描类型等。由于优化器处理需要大量的计算和IO操作,所以在这个步骤中可能会花费大量的时间。
(3)执行
执行计划生成:Oracle将使用优化器处理过的最佳执行计划,生成一个具体的执行计划。执行计划通常是一个树形结构,它描述了SQL语句将使用哪些操作、连接和过滤器,以及它们的执行顺序。
执行:Oracle将执行执行计划,并返回查询结果。根据SQL语句的类型,可能会涉及到许多不同的操作,包括表扫描、索引扫描、连接和聚合等。如果有任何错误,它们将在执行过程中被捕获,并且数据库将返回错误代码。
SQL语句解析的过程是非常复杂和计算密集的,每个步骤都需要大量的处理和IO操作。因此,如果SQL语句不正确或不规范,它会导致解析速度缓慢甚至失败。另外,一个错误的执行计划也会导致查询效率低下或查询结果不正确。为了确保最佳的数据库性能,必须深入了解SQL语句解析的过程,并可以优化查询语句以提高查询效率。
e.g. 标准的SQL 解析顺序:
- (1)FROM 子句, 组装来自不同数据源的数据
- (2)WHERE 子句, 基于指定的条件对记录进行筛选
- (3)GROUP BY 子句, 将数据划分为多个分组
- (4)使用聚合函数进行计算
- (5)使用 HAVING 子句筛选分组
- (6)计算所有的表达式
- (7)使用 ORDER BY 对结果集进行排序
例如:在学生成绩表中 (暂记为 tb_Grade), 把 "考生姓名"内容不为空的记录按照 “考生姓名” 分组, 并且筛选分组结果, 选出 “总成绩” 大于 600 分的。
SQL语句为:
select 考生姓名, max(总成绩) as max总成绩
from tb_Grade
where 考生姓名 is not null
group by 考生姓名
having max(总成绩) > 600
order by max总成绩
执行顺序如下:
- (1) 首先执行 FROM 子句, 从 tb_Grade 表组装数据源的数据
- (2) 执行 WHERE 子句, 筛选 tb_Grade 表中所有数据不为 NULL 的数据
- (3) 执行 GROUP BY 子句, 把 tb_Grade 表按 “学生姓名” 列进行分组
- (4) 计算 max() 聚集函数, 按 “总成绩” 求出总成绩中最大的一些数值
- (5) 执行 HAVING 子句, 筛选课程的总成绩大于 600 分的.
- (6) 执行 ORDER BY 子句, 把最后的结果按 “Max 成绩” 进行排序
4. Oracle Hint
Oracle hint是一种在SQL语句中使用的特殊注释,它可以告诉Oracle数据库如何执行SQL语句,从而达到最优的执行效果。
Oracle hint主要用于优化复杂的SQL查询语句,特别是当优化器无法选择最优的执行计划时。例如,当使用复杂的连接查询、子查询、聚合函数或大数据量的表时,Oracle hint通过给出提示指导优化器选择最优的执行计划,从而提高SQL语句的执行效率和性能。
Oracle hint必须写在SQL语句的SELECT、INSERT、UPDATE或DELETE语句之后,但在WHERE子句之前。
注意:如果表中指定了别名,那么Hint中也必须使用别名,否则Hint会忽略:
Select /+full(a)/ * from t a; – 使用hint
Select /*+full(t) */ * from t a; --不使用hint
(1)优化器模式提示
对语句块选择基于开销的优化方法,并获得最佳吞吐量,使资源消耗最小化。
select /*+ALL_ROWS(t)*/* from student t Where name='WASEEM HAIDER'
select /*+FIRST_ROWS(t)*/* from student t Where name ='WASEEM HAIDER'
select /*+FIRST_ROWS(t,20)*/* from student t Where name ='WASEEM HAIDER'
ALL_ROWS时,Oracle 会用最快的速度将SQL执行完毕,将所有结果集全部返回,在OLAP 系统中使用得比较多;ALL_ROWS 强调SQL整体的执行效率,而FIRST_ROWS(n)强调用最快的速度返回前N行,而不管所有的结果返回的时长,可能最后一条要很长时间才能获得。
对语句块选择基于规则的优化方法
select /*+RULE(t)*/* from student t Where name ='WASEEM HAIDER'
(2)访问路径提示
对表选择全局扫描的方法
select /*+FULL(t)*/* from student t Where name='WASEEM HAIDER'
对表选择索引的扫描方法
select /*+INDEX(T_JBXX X)*/* from student Where name='WASEEM HAIDER'
(3)并行执行提示
select /*+PARALLEL(t,16)*/* from student t Where t.name ='WASEEM HAIDER'
这个值会覆盖表自身设定的并行度,如果这个值为default,CBO使用系统参数值。
(4)其他
Insert /*+append */ into t as select * from all_objects
提示数据库以直接加载的方式(direct load)将数据加载入库,尤其在插入大量的数据,一般都会用此hint。
此外还有表连接顺序/表关联方式提示、查询转换提示等。