Redis 哈希键命令实现(t_hash)
1. 哈希命令介绍
| 序号 | 命令及描述 |
|---|---|
| 1 | HDEL key field2 [field2]:删除一个或多个哈希表字段 |
| 2 | HEXISTS key field:查看哈希表 key 中,指定的字段是否存在。 |
| 3 | HGET key field:获取存储在哈希表中指定字段的值。 |
| 4 | HGETALL key:获取在哈希表中指定 key 的所有字段和值 |
| 5 | HINCRBY key field increment:为哈希表 key 中的指定字段的整数值加上增量 increment 。 |
| 6 | HINCRBYFLOAT key field increment:为哈希表 key 中的指定字段的浮点数值加上增量 increment 。 |
| 7 | HKEYS key:获取所有哈希表中的字段 |
| 8 | HLEN key:获取哈希表中字段的数量 |
| 9 | HMGET key field1 [field2]:获取所有给定字段的值 |
| 10 | HMSET key field1 value1 [field2 value2 ]:同时将多个 field-value (域-值)对设置到哈希表 key 中。 |
| 11 | HSET key field value:将哈希表 key 中的字段 field 的值设为 value 。 |
| 12 | HSETNX key field value:只有在字段 field 不存在时,设置哈希表字段的值。 |
| 13 | HVALS key:获取哈希表中所有值 |
| 14 | HSCAN key cursor [MATCH pattern][COUNT count]: 迭代哈希表中的键值对。 |
2. 哈希类型的实现
之前在redis对象系统源码剖析和注释中提到,一个哈希类型的对象的编码有两种,分别是OBJ_ENCODING_ZIPLIST和OBJ_ENCODING_HT。
| 编码—encoding | 对象—ptr |
|---|---|
| OBJ_ENCODING_ZIPLIST | 压缩列表实现的哈希对象 |
| OBJ_ENCODING_HT | 字典实现的哈希对象 |
但是默认创建的哈希类型的对象编码为OBJ_ENCODING_ZIPLIST,OBJ_ENCODING_HT类型编码是通过达到配置的阈值条件后,进行转换得到的。
阈值条件为:
/* redis.conf文件中的阈值 */
hash-max-ziplist-value 64 // ziplist中最大能存放的值长度
hash-max-ziplist-entries 512 // ziplist中最多能存放的entry节点数量
一个哈希对象的结构定义如下:
typedef struct redisObject {
//对象的数据类型,字符串对象应该为 OBJ_HASH
unsigned type:4;
//对象的编码类型,分别为 OBJ_ENCODING_ZIPLIST 或 OBJ_ENCODING_HT
unsigned encoding:4;
//暂且不关心该成员
unsigned lru:LRU_BITS; /* lru time (relative to server.lruclock) */
//引用计数
int refcount;
//指向底层数据实现的指针,指向一个dict的字典结构
void *ptr;
} robj;
例如,我们创建一个 user:info 哈希键,有三个字段,分别是name,sex,passwd。
127.0.0.1:6379> HMSET user:info name Mike sex male passwd 123456
OK
127.0.0.1:6379> HGETALL user:info
1) "name"
2) "Mike"
3) "sex"
4) "male"
5) "passwd"
6) "123456"
我们以此为例,查看redis的哈希对象的空间结构。
根据这些信息的大小,redis应该为其创建一个编码为OBJ_ENCODING_ZIPLIST的哈希对象。如下图所示:
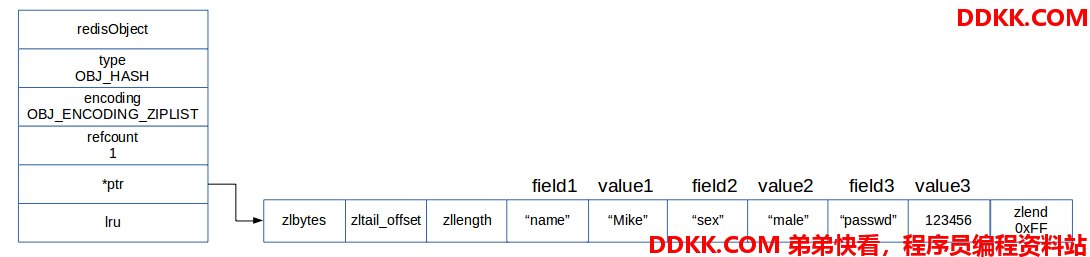
压缩列表中的entry节点,两两组成一个键值对。
如果这个哈希对象所存储的键值对或者ziplist的长度超过配置的限制,则会转换为字典结构,这写阈值条件上面已经列出,而为了说明编码为 OBJ_ENCODING_HT 类型的哈希对象,我们仍用上面的 user:info 对象来表示一个字典结构的哈希对象,哈希对象中的键值对都是字符串类型的对象。如下图:
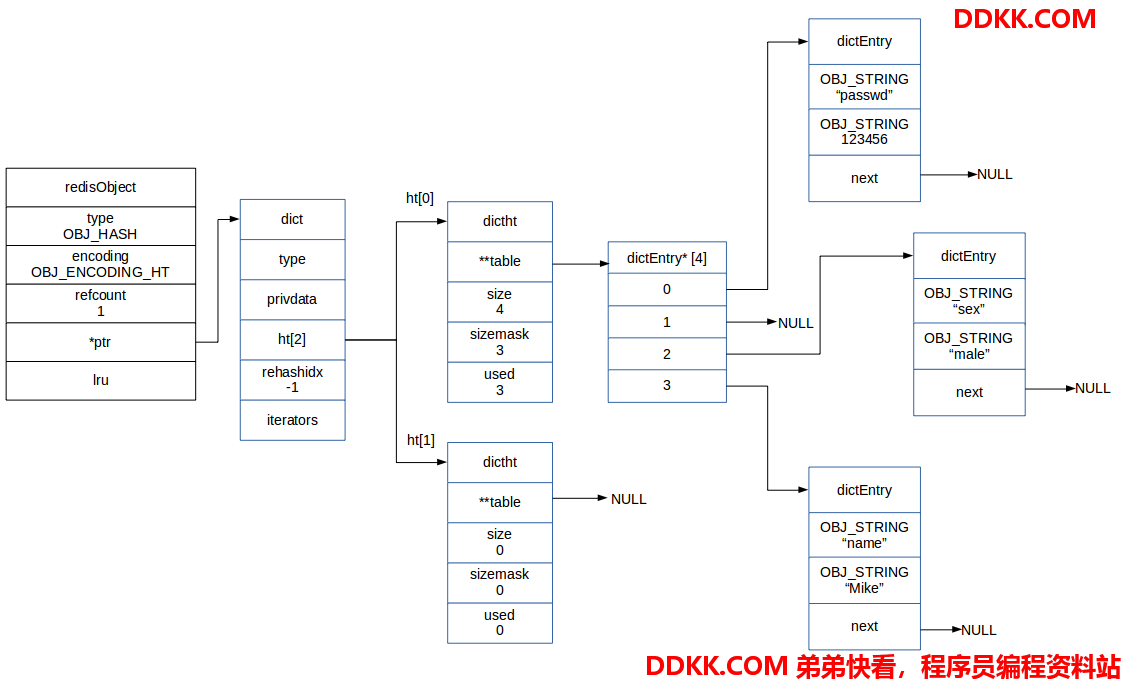
和列表数据类型一样,哈希数据类型基于ziplist和hash table进行封装,实现了哈希数据类型的接口:
/* Hash data type */
// 转换一个哈希对象的编码类型,enc指定新的编码类型
void hashTypeConvert(robj *o, int enc);
// 检查一个数字对象的长度判断是否需要进行类型的转换,从ziplist转换到ht类型
void hashTypeTryConversion(robj *subject, robj **argv, int start, int end);
// 对键和值的对象尝试进行优化编码以节约内存
void hashTypeTryObjectEncoding(robj *subject, robj **o1, robj **o2);
// 从一个哈希对象中返回field对应的值对象
robj *hashTypeGetObject(robj *o, robj *key);
// 判断field对象是否存在在o对象中
int hashTypeExists(robj *o, robj *key);
// 将field-value添加到哈希对象中,返回1,如果field存在更新新的值,返回0
int hashTypeSet(robj *o, robj *key, robj *value);
// 从一个哈希对象中删除field,成功返回1,没找到field返回0
int hashTypeDelete(robj *o, robj *key);
// 返回哈希对象中的键值对个数
unsigned long hashTypeLength(robj *o);
// 返回一个初始化的哈希类型的迭代器
hashTypeIterator *hashTypeInitIterator(robj *subject);
// 释放哈希类型迭代器空间
void hashTypeReleaseIterator(hashTypeIterator *hi);
// 讲哈希类型迭代器指向哈希对象中的下一个节点
int hashTypeNext(hashTypeIterator *hi);
// 从ziplist类型的哈希类型迭代器中获取对应的field或value,保存在参数中
void hashTypeCurrentFromZiplist(hashTypeIterator *hi, int what, unsigned char **vstr, unsigned int *vlen, long long *vll);
// 从ziplist类型的哈希类型迭代器中获取对应的field或value,保存在参数中
void hashTypeCurrentFromHashTable(hashTypeIterator *hi, int what, robj **dst);
// 从哈希类型的迭代器中获取键或值
robj *hashTypeCurrentObject(hashTypeIterator *hi, int what);
// 以写操作在数据库中查找对应key的哈希对象,如果不存在则创建
robj *hashTypeLookupWriteOrCreate(client *c, robj *key);
这些函数接口的注释请上github查看:哈希类型函数接口的注释
3. 哈希类型的迭代器
和列表类型一样,哈希数据类型也实现自己的迭代器,而且也是基于ziplist和字典结构的迭代器封装而成。
typedef struct {
robj *subject; // 哈希类型迭代器所属的哈希对象
int encoding; // 哈希对象的编码类型
// 用ziplist编码
unsigned char *fptr, *vptr; // 指向当前的key和value节点的地址,ziplist类型编码时使用
// 用于字典编码
dictIterator *di; // 迭代HT类型的哈希对象时的字典迭代器
dictEntry *de; // 指向当前的哈希表节点
} hashTypeIterator;
#define OBJ_HASH_KEY 1 // 哈希键
#define OBJ_HASH_VALUE 2 // 哈希值
- 创建一个迭代器
// 返回一个初始化的哈希类型的迭代器
hashTypeIterator *hashTypeInitIterator(robj *subject) {
// 分配空间初始化成员
hashTypeIterator *hi = zmalloc(sizeof(hashTypeIterator));
hi->subject = subject;
hi->encoding = subject->encoding;
// 根据不同的编码设置不同的成员
if (hi->encoding == OBJ_ENCODING_ZIPLIST) {
hi->fptr = NULL;
hi->vptr = NULL;
} else if (hi->encoding == OBJ_ENCODING_HT) {
// 初始化一个字典迭代器返回给di成员
hi->di = dictGetIterator(subject->ptr);
} else {
serverPanic("Unknown hash encoding");
}
return hi;
}
- 释放迭代器
// 释放哈希类型迭代器空间
void hashTypeReleaseIterator(hashTypeIterator *hi) {
// 如果是字典,则需要先释放字典迭代器的空间
if (hi->encoding == OBJ_ENCODING_HT) {
dictReleaseIterator(hi->di);
}
zfree(hi);
}
- 迭代
/* Move to the next entry in the hash. Return C_OK when the next entry
* could be found and C_ERR when the iterator reaches the end. */
//讲哈希类型迭代器指向哈希对象中的下一个节点
int hashTypeNext(hashTypeIterator *hi) {
// 迭代ziplist
if (hi->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *zl;
unsigned char *fptr, *vptr;
// 备份迭代器的成员信息
zl = hi->subject->ptr;
fptr = hi->fptr;
vptr = hi->vptr;
// field的指针为空,则指向第一个entry,只在第一次执行时,初始化指针
if (fptr == NULL) {
/* Initialize cursor */
serverAssert(vptr == NULL);
fptr = ziplistIndex(zl, 0);
} else {
/* Advance cursor */
// 获取value节点的下一个entry地址,即为下一个field的地址
serverAssert(vptr != NULL);
fptr = ziplistNext(zl, vptr);
}
// 迭代完毕或返回C_ERR
if (fptr == NULL) return C_ERR;
/* Grab pointer to the value (fptr points to the field) */
// 保存下一个value的地址
vptr = ziplistNext(zl, fptr);
serverAssert(vptr != NULL);
/* fptr, vptr now point to the first or next pair */
// 更新迭代器的成员信息
hi->fptr = fptr;
hi->vptr = vptr;
// 如果是迭代字典
} else if (hi->encoding == OBJ_ENCODING_HT) {
// 得到下一个字典节点的地址
if ((hi->de = dictNext(hi->di)) == NULL) return C_ERR;
} else {
serverPanic("Unknown hash encoding");
}
return C_OK;
}
4. 哈希命令的实现
上面都给出了哈希类型的接口,所以哈希类型命令实现很容易看懂,而且哈希类型命令没有阻塞版的。
具体所有注释请看:哈希类型命令的注释
- Hgetall一类命令的底层实现
HKEYS、HVALS、HGETALL
void genericHgetallCommand(client *c, int flags) {
robj *o;
hashTypeIterator *hi;
int multiplier = 0;
int length, count = 0;
// 以写操作取出哈希对象,若失败,或取出的对象不是哈希类型的对象,则发送0后直接返回
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.emptymultibulk)) == NULL
|| checkType(c,o,OBJ_HASH)) return;
// 计算一对键值对要返回的个数
if (flags & OBJ_HASH_KEY) multiplier++;
if (flags & OBJ_HASH_VALUE) multiplier++;
// 计算整个哈希对象中的所有键值对要返回的个数
length = hashTypeLength(o) * multiplier;
addReplyMultiBulkLen(c, length); //发get到的个数给client
// 创建一个哈希类型的迭代器并初始化
hi = hashTypeInitIterator(o);
// 迭代所有的entry节点
while (hashTypeNext(hi) != C_ERR) {
// 如果取哈希键
if (flags & OBJ_HASH_KEY) {
// 保存当前迭代器指向的键
addHashIteratorCursorToReply(c, hi, OBJ_HASH_KEY);
count++; //更新计数器
}
// 如果取哈希值
if (flags & OBJ_HASH_VALUE) {
// 保存当前迭代器指向的值
addHashIteratorCursorToReply(c, hi, OBJ_HASH_VALUE);
count++; //更新计数器
}
}
//释放迭代器
hashTypeReleaseIterator(hi);
serverAssert(count == length);
}
- HSTRLEN 命令实现
Redis 3.2版本以上新加入的
void hstrlenCommand(client *c) {
robj *o;
// 以写操作取出哈希对象,若失败,或取出的对象不是哈希类型的对象,则发送0后直接返回
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.czero)) == NULL ||
checkType(c,o,OBJ_HASH)) return;
// 发送field对象的值的长度给client
addReplyLongLong(c,hashTypeGetValueLength(o,c->argv[2]));
}
- HDEL命令实现
void hdelCommand(client *c) {
robj *o;
int j, deleted = 0, keyremoved = 0;
// 以写操作取出哈希对象,若失败,或取出的对象不是哈希类型的对象,则发送0后直接返回
if ((o = lookupKeyWriteOrReply(c,c->argv[1],shared.czero)) == NULL ||
checkType(c,o,OBJ_HASH)) return;
// 遍历所有的字段field
for (j = 2; j < c->argc; j++) {
// 从哈希对象中删除当前字段
if (hashTypeDelete(o,c->argv[j])) {
deleted++; //更新删除的个数
// 如果哈希对象为空,则删除该对象
if (hashTypeLength(o) == 0) {
dbDelete(c->db,c->argv[1]);
keyremoved = 1; //设置删除标志
break;
}
}
}
// 只要删除了字段
if (deleted) {
// 发送信号表示键被改变
signalModifiedKey(c->db,c->argv[1]);
// 发送"hdel"事件通知
notifyKeyspaceEvent(NOTIFY_HASH,"hdel",c->argv[1],c->db->id);
// 如果哈希对象被删除
if (keyremoved)
// 发送"hdel"事件通知
notifyKeyspaceEvent(NOTIFY_GENERIC,"del",c->argv[1],
c->db->id);
server.dirty += deleted; // 更新脏键
}
addReplyLongLong(c,deleted); //发送删除的个数给client
}
- HINCRBYFLOAT 命令的实现
void hincrbyfloatCommand(client *c) {
double long value, incr;
robj *o, *current, *new, *aux;
// 得到一个long double类型的增量increment
if (getLongDoubleFromObjectOrReply(c,c->argv[3],&incr,NULL) != C_OK) return;
// 以写方式取出哈希对象,失败则直接返回
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;
// 返回field在哈希对象o中的值对象
if ((current = hashTypeGetObject(o,c->argv[2])) != NULL) {
//从值对象中得到一个long double类型的value,如果不是浮点数的值,则发送"hash value is not a valid float"信息给client
if (getLongDoubleFromObjectOrReply(c,current,&value,
"hash value is not a valid float") != C_OK) {
decrRefCount(current); //取值成功,释放临时的value对象空间,直接返回
return;
}
decrRefCount(current); //取值失败也要释放空间
} else {
value = 0; //如果没有值,则设置为默认的0
}
value += incr; //备份原先的值
// 将value转换为字符串类型的对象
new = createStringObjectFromLongDouble(value,1);
//将键和值对象的编码进行优化,以节省空间,是以embstr或raw或整型存储
hashTypeTryObjectEncoding(o,&c->argv[2],NULL);
// 设置原来的key为新的值对象
hashTypeSet(o,c->argv[2],new);
// 讲新的值对象发送给client
addReplyBulk(c,new);
// 修改数据库的键则发送信号,发送"hincrbyfloat"事件通知,更新脏键
signalModifiedKey(c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_HASH,"hincrbyfloat",c->argv[1],c->db->id);
server.dirty++;
/* Always replicate HINCRBYFLOAT as an HSET command with the final value
* in order to make sure that differences in float pricision or formatting
* will not create differences in replicas or after an AOF restart. */
// 用HSET命令代替HINCRBYFLOAT,以防不同的浮点精度造成的误差
// 创建HSET字符串对象
aux = createStringObject("HSET",4);
// 修改HINCRBYFLOAT命令为HSET对象
rewriteClientCommandArgument(c,0,aux);
// 释放空间
decrRefCount(aux);
// 修改increment为新的值对象new
rewriteClientCommandArgument(c,3,new);
// 释放空间
decrRefCount(new);
}
- HSCAN 命令实现
// HSCAN key cursor [MATCH pattern] [COUNT count]
// HSCAN 命令实现
void hscanCommand(client *c) {
robj *o;
unsigned long cursor;
// 获取scan命令的游标cursor
if (parseScanCursorOrReply(c,c->argv[2],&cursor) == C_ERR) return;
// 以写操作取出哈希对象,若失败,或取出的对象不是哈希类型的对象,则发送0后直接返回
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.emptyscan)) == NULL ||
checkType(c,o,OBJ_HASH)) return;
// 调用底层实现
scanGenericCommand(c,o,cursor);
}