原子变量-AtomicIntegerArray/AtomicLongArray/AtomicReferenceArray
JUC针对数组元素的原子封装,先看AtomicIntegerArray。
private static final Unsafe unsafe = Unsafe.getUnsafe();
//arrayBaseOffset获取数组首个元素地址偏移
private static final int base = unsafe.arrayBaseOffset(int[].class);
//shift就是数组元素的偏移量
private static final int shift;
private final int[] array;
static {
//scale数组元素的增量偏移
int scale = unsafe.arrayIndexScale(int[].class);
//对于int型数组,scale是4,用二进制&操作判断是否是2的倍数,这个判断nb
if ((scale & (scale - 1)) != 0)
throw new Error("data type scale not a power of two");
//这里是处理int型的偏移量,shift是2
shift = 31 - Integer.numberOfLeadingZeros(scale);
}
/**
计算数组中元素的地址
*/
private long checkedByteOffset(int i) {
if (i < 0 || i >= array.length)
throw new IndexOutOfBoundsException("index " + i);
return byteOffset(i);
}
/**
计算数组中元素的地址,首地址偏移+每个元素的偏移,采用了移位操作,没想过还可以用,佩服
*/
private static long byteOffset(int i) {
return ((long) i << shift) + base;
}
为了说明unsafe对数组的操作,举个栗子:
public class UnsafeTest {
public static void main(String[] args) throws NoSuchFieldException, SecurityException, IllegalArgumentException, IllegalAccessException {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
Unsafe unsafe = (Unsafe) field.get(null);
int[] a = new int[]{1,2,5};
//int[]首个元素的偏移
int arrayBaseOffset = unsafe.arrayBaseOffset(a.getClass());
//数组中元素的增量偏移
int arrayIndexScale = unsafe.arrayIndexScale(a.getClass());
System.out.println(arrayBaseOffset);
System.out.println(arrayIndexScale);
//通过首地址的偏移+增量偏移,获取数组元素值
System.out.println(unsafe.getIntVolatile(a, arrayBaseOffset+arrayIndexScale));
}
}
源码里面对于增量偏移使用了移位操作,这步处理没看源码前还真是没想到
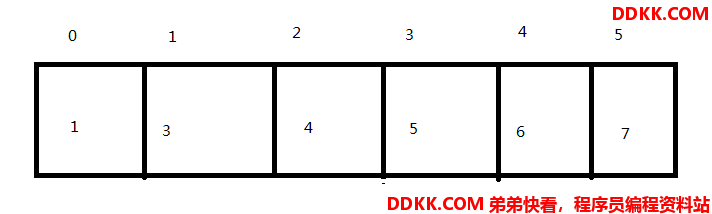
假设数组首地址14,int型,每个4个字节,所以取第0个元素地址就是,14+(0*4),第2个元素14+(1*4),第i个地址为14+(i*4),采用移位的话就是(4的2进制是2)14+(i<<2),对于AtomicLongArray取数组元素就是首地址+(i<<3)。对于AtomicInteger取元素地址就是base+(index<<scale)。
看下AtomicIntegerArray的构造函数
public AtomicIntegerArray(int[] array) {
// Visibility guaranteed by final field guarantees
this.array = array.clone();
}
这里有个说明,采用final来保证数组的可见性,看到这里的时候,郁闷,以前final的使用,重来没想过什么可见性问题,直接用就是了,只好百度,http://www.infoq.com/cn/articles/java-memory-model-6/这里对于final的可见性有详细说明,也是通过加内存屏障来实现。最重要一句: JSR-133专家组增强了final的语义。通过为final域增加写和读重排序规则,可以为java程序员提供初始化安全保证:只要对象是正确构造的(被构造对象的引用在构造函数中没有“逸出”),那么不需要使用同步(指lock和volatile的使用),就可以保证任意线程都能看到这个final域在构造函数中被初始化之后的值。
看下AtomicIntegerArray的一些方法:
public final int get(int i) {
return getRaw(checkedByteOffset(i));
}
/**
通过unsafe.getIntVolatile这个保证volatile语义,
感觉意思应该是可以当场volatile变量使用
*/
private int getRaw(long offset) {
return unsafe.getIntVolatile(array, offset);
}
/**
unsafe.putIntVolatile保证volatile语义
*/
public final void set(int i, int newValue) {
unsafe.putIntVolatile(array, checkedByteOffset(i), newValue);
}
/**
unsafe.putOrderedInt这个前面一文提过,
去掉了storeLoad内存屏障,只有storestore屏障,只保证修W改成功,不保证修改后其他处理器立即就可以看到
*/
public final void lazySet(int i, int newValue) {
unsafe.putOrderedInt(array, checkedByteOffset(i), newValue);
}
/**
这里是通过while循环来实现最终设置成功
*/
public final int getAndSet(int i, int newValue) {
long offset = checkedByteOffset(i);
while (true) {
int current = getRaw(offset);
if (compareAndSetRaw(offset, current, newValue))
return current;
}
}
/**
对于数组的cas,只是多了个先取地址的操作,其他还是底层的unsafe
*/
public final boolean compareAndSet(int i, int expect, int update) {
return compareAndSetRaw(checkedByteOffset(i), expect, update);
}
private boolean compareAndSetRaw(long offset, int expect, int update) {
return unsafe.compareAndSwapInt(array, offset, expect, update);
}
跟之前的AtomicInteger没太多区别,只是需要对于传入的i需要先判断在数组length范围内,再转换成内存地址。类中其他方法类同。
AtomicLongArray跟AtomicIntegerArray类同。
AtomicReferenceArray多了个arrayFieldOffset,用来在从stream读数组设置到array内存偏移地址。