1. 不合理设置内存的反面示例
比如,支付系统因为没有经过合理的内存预估,所以选用了 1台2核4G的虚拟机来部署了线上系统,而且就只用了一台机器。
然后线上JVM给的堆内存大小,仅仅就只有1G,扣除老年代之后,新生代其实就几百MB的内存空间,如下图。
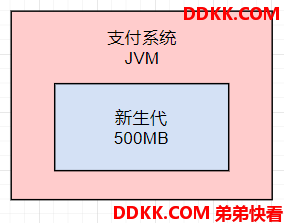
按照每天100万交易,高峰值为每秒大概100笔支付交易,对应核心的支付订单对象有100个创建出来,每个支付订单对象占据500左右的字节大小,总共就是50kb大小。
然后一笔交易要1秒来处理,所以这100个对象在新生代中存在1秒的期间会被引用,是无法被回收的。
从全局预估,核心的支付订单对象扩展开来到系统里其他对象中去,起码要把内存占用扩大10倍~20倍。
比如扩大了20倍,那么说明1秒之内,总共会创建出来大概1MB左右的对象,无法被回收。
2. 大促期间,瞬时访问量增加十倍
新生代在系统正常运行的情况下,每秒新增1MB对象,几百秒过后,新生代就会满了,然后出发Minor GC,回收掉里面99%的垃圾对象。
而内存那么小,平时可能就只是发现系统每隔几分钟略微卡顿一下,因为这个时候在进行垃圾回收,会影响系统性能。
但是,如果这个时间段在搞大促活动,很可能会导致压力瞬间增大10倍。那么这时候,每秒钟你的支付系统就不是100笔订单了,可能是每秒钟上千笔订单。
这时候,系统压力本身就会很大,不光是内存,尤其是线程资源、CPU资源,都会几乎打满。内存更是岌岌可危。
3.少数请求需要几十秒处理,导致老年代内存占用变大
假设每秒1000笔交易,那么每秒系统对内存的占用增加到10MB以上。甚至再高点,每秒对内存占用达到几十MB,上百MB也有可能。
那么,此时每秒过来的1000笔交易,就不是1秒钟就可以处理完毕了,因为压力骤增,会导致系统性能下降,可能会出现某个请求处理完毕需要几秒钟,甚至几十秒的时间。
此时可能出现的问题是,如果新生代已经积压满了很多数据,而此时有几十MB的对象都被人引用着。但因为压力太大,导致系统性能太差,从而导致这几十MB对象的引用请求突然处理的很慢。

问题来了,如果这时候,需要再次在新生代里分配对象,就会触发一次 Minor GC去回收新生代。
但是虽然回收掉大量的对象,但因为少数请求特别慢,所以那少数几十MB的对象还在。然后新生代会再次很快被填满,再次触发Minor GC,然后少数几十MB的对象还在,如此反复多次GC之后,就会被转移到老年代去,如下图:
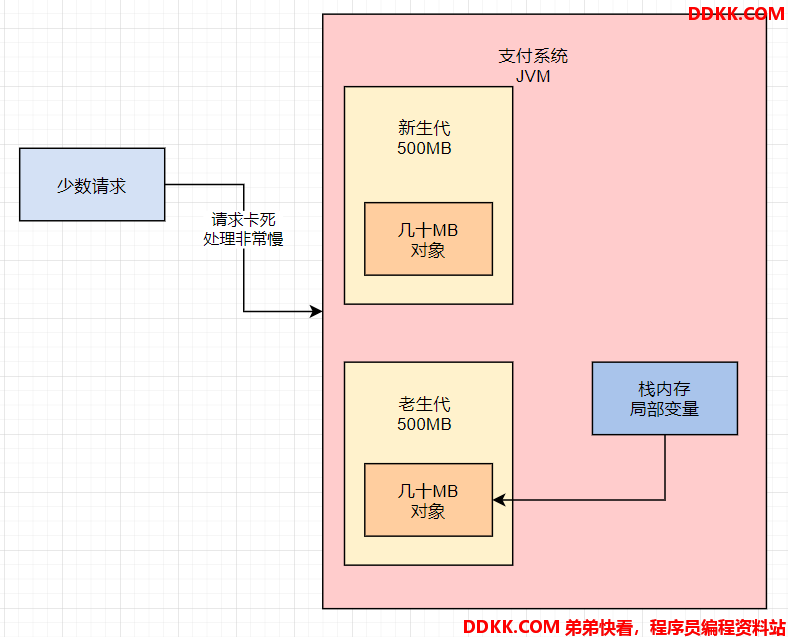
4. 老年代对象越来越多导致频繁垃圾回收
当上述流程反复多次后,新生代的对象反复多次无法被回收,然后被弄到老年代去。当后续处理完之后,老年代的对象就没人引用了,成为了垃圾对象。
反复多次后,老年代的垃圾对象就会越来越多。最终被拉满,然后就会触发老年代的垃圾回收。而老年代被拉满是很快的,所以也会频繁的垃圾回收。
重点来了,老年代的垃圾回收速度是很慢的,而这将反向影响新生代GC的速度,当老年代没有完成当次垃圾回收来空出内存空间时,新生代是无法继续将对象弄过来的。那此时新生代就要一直等待不能进行GC,而新的对象也就不能产生。支付订单流程就会卡在这里。
5. 反面案例总结
支付系统内存设置过小,在突发巨大的流量压力下,发生性能抖动,最终导致很多对象长期在新生代被引用,因无法回收,最后持续进入老年代,最后触发老年代内存频繁占满,然后老年代也频繁垃圾回收。
6. 如何合理设置永久代大小?
刚开始上线一个系统,没太多可参考的规范,设置几百MB,基本就够用了。
7. 如何合理设置栈内存大小
栈内存大小设置,默认在 512kb到1MB之间。基本就够用了。该内存空间用来存放线程执行方法期间的各种布局变量。
8.总结
1、 高并请求下,处理性能会直线下降,导致大量对象积压在新生代时间过久,动态年龄判断转移到老年代,老年代堆满, full gc(young + old) 系统处理性能又进一步下降,同时对象也无法存放,最后OOM。(ps:因为处理时间过长,占用资源过久,容易造成各种池,比如db连接池爆掉)
2、 高并发下考虑的是tps,正常请求多少。
3、 新生代和老年代没有绝对比例,比如网上新生代和老年代比率一比二。得基于不同系统的运行模型来分析,你每个系统的jvm参数应该是不同的。
4、 一般 minor gc 几秒到几十秒一次是一个合理的范围。