1. JVM性能优化的是什么
不管是在面试题还是平常的技术交流中,大家都在说 JVM调优、JVM优化什么的;那你有没有想过,JVM优化到底在优化什么东西?
1.1 Java系统运行流程梳理
一个Java系统运行起来之后,也就是JVM运行起来之后,最核心的区域就是堆内存,在堆内存区域会 存放系统运行时生成的各种对象。
堆内存会被划分为新生代和老年代两个区域,对于新创建的对象来说,首先都是被放入新生代的;
1.1.1 新生代
随着系统不停的运行,会创建越来越多的对象,也就会有越来越多的对象进入新生代;由于Java堆内存大小是有限制的,所以这个新生代区域也会被逐渐放满,在快要放满的时候,就需要对里面的“垃圾对象”进行清理了。
这些垃圾对象,也就是 没有被 GC Roots 直接或间接引用的对象;GC Roots一般就是 静态变量、局部变量、活着的线程 等。
在一个系统中最经常创建对象的地方是在各个方法里面,当一个方法运行完毕之后,这个方法中创建的对象就没有局部变量这个GC Roots引用了,也就是成为了垃圾对象。
所以在新生代中,可能95%以上的对象都是这种没有被引用的垃圾对象。
新生代中按照默认比例分配的话,会有一块占比80%的 Eden区域 和两块分别占比10%的 Survivor区域;
在新生代快要满了的时候,就会触发新生代GC(Minor GC),使用 复制算法 对新生代的垃圾对象进行清理:
首先停止系统程序的运行,也就是进入“Stop the World”状态;
然后对所有的 GC Roots进行追踪,标记出被引用了的存活对象:
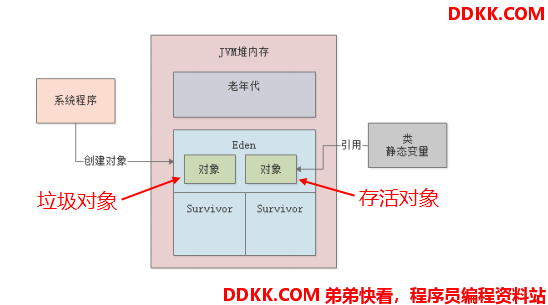
然后把 Eden区(和Survivor区)所有的存活对象都复制到另一块 Survivor区域中去:
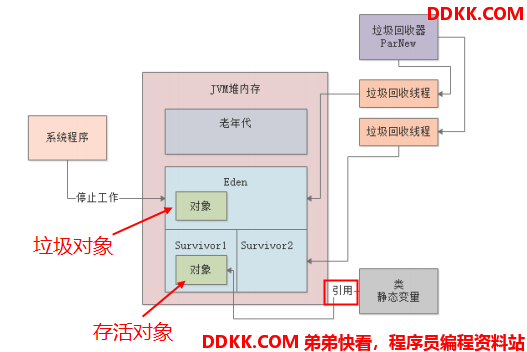
最后把 Eden区(和Survivor区)中的剩余的垃圾对象全部回收掉,释放内存空间;并恢复系统程序运行;
这就是从系统生成对象到进入新生代,再到新生代GC的全部过程了。
这里面有一个重点:新生代GC的时候,会进入“Stop the World”状态,也就是会停止系统运行。
Q:那这种新生代GC对系统的性能影响到底大不大呢?
A:其实影响是不大的,因为新生代中存活的对象很少,所以JVM能够迅速地标记出被GC Roots引用的存活对象,然后使用效率很高的复制算法移到Survivor区,再对垃圾对象进行回收就好了,整个过程速度很快(大概就几毫秒、几十毫秒);所以对系统的性能影响是很小的。
Q:那什么时候新生代GC对系统的性能影响会很大呢?
A:如果你的系统是类似Kafka、ES之类的大数据处理相关的系统,它们每秒可能会有上万的请求量,就需要很大的JVM堆内存进行处理;
所以如果系统是部署在很大的机器上(比如64G的机器),此时分配给新生代Eden区的内存可能就会有20G以上;
这个时候由于请求量非常大生成对象也就会很快,导致频繁回收新生代;每次回收的时候由于Eden区太大,“Stop the World”的时间也就是系统停顿的时间就会比较长(可能达到几秒),也就可能导致系统请求阻塞、超时等情况;
1.1.2 老年代
除了新生代,系统运行时还会有不少对象会进入老年代,那有哪些对象在什么情况下会进入老年代呢?
- 分配担保规则:新生代GC过后,存活对象太多,Survivor区放不下了,这个时候就需要通过分配担保进入老年代;
- 达到年龄阈值:对象在新生代熬过了15次(-XX:MaxTenuringThreshold)GC,达到了年龄阈值,会晋升到老年代;(这种对象一般很少,只有在系统中的确需要长期存在的核心组件等,它们一般不能被回收)
- 动态年龄判断:在新生代Survivor区的对象,如果:年龄1 + 年龄2 + 年龄3 + 年龄N 的对象大小占比大于了Survivor区的50%以上,那年龄N及以上的对象就会晋升到老年代;
- 大对象直接进入老年代;(-XX:PretenureSizeThreshold)
默认值为0,当不主动设置值时,不管多大的对象都会先在新生代分配内存;
当手动设置了这个值时,如果生成一个大于这个大小的对象(比如一个超大的数组或者其他对象),就会直接在老年代中为这个对象分配内存;
G1收集器中有专门的大对象Region,大对象不存在老年代;
上面的几种情况中,分配担保和动态年龄判断都是很关键的;通常如果新生代的Survivor区内存设置过小,就可能导致这两种情况频繁发生,然后导致大量对象快速进入老年代,在老年代对象过多的时候,就会触发 Full GC。
1.1.2.1 Full GC
Full GC发生的时候一般会跟着一次Young GC,也会跟着触发元数据空间的GC。
那什么条件会触发 Full GC呢?
- 老年代占用比例参数(-XX:CMSInitiatingOccupancyFaction 默认92%),老年代使用内存达到这个阈值会触发 Full GC;
- 执行 Young GC之前,如果 老年代可用内存大小 < 历次 YGC后升入老年代对象的平均大小,先执行 Full GC;
- 执行 Young GC之后,如果 存活对象大小 > 老年代可用内存大小,执行 Full GC;
Full GC 一般来说都很耗时,无论是CMS垃圾回收器还是G1垃圾回收器;因为它们都要经过 “Stop the World”的初始标记、追踪所有GC Roots关联对象的并发标记、再次“Stop the World”的重新标记 三个阶段,过程非常复杂也非常耗时。
Full GC 一般来说会比新生代GC慢10倍以上,比如新生代GC每次耗时50ms,其实对用户系统影响不大;但是老年代GC每次耗时1000ms,可能就会导致在GC的时候用户界面上卡顿1s左右的时间,这个影响就很大了。
所以如果JVM内存分配不合理,导致频繁地进行老年代GC,每次Full GC都让用户系统停顿1s左右的时间,这对大部分应用简直是致命的打击。
1.2 JVM优化的是什么
到这里我们应该知道了,Java系统的最大问题就是:因为内存分配和参数设置的不合理,导致对象频繁进入老年代,然后频繁触发Full GC,进而导致应用卡顿,还可能引发OOM等严重问题。
所以,JVM的优化,说到底就是 尽量保证你的系统只发生Young GC,减少甚至不发生Full GC。
那优化有没有一个可以量化的标准呢?
-
其实很难给定一个量化的标准,因为各个系统的内存条件和负载量这些都不一样,所以没法给出一个具体的标准;
-
但是一般来说,正常运行情况下的系统,因为你不可能无限的分配堆内存,所以随着系统的运行,一定会发生Young GC的;
-
负载不高的系统,一般几十分钟几个小时发生一次Young GC,每次耗时在几毫秒左右;
-
负载很高的系统,一般几分钟这些发生一次Young GC,每次耗时几毫秒左右,这些都是合理的;
-
Full GC的话,大多数系统多控制在几十分钟或者几个小时发生一次,也就比较合理了;
2. 怎么做JVM性能优化
工欲善其事,必先利其器;想要真正去做JVM性能优化,除了JVM本身的基础知识(JVM运行区域、运行原理、垃圾回收器及回收流程),我们还需要具备几项基本技能:
- 熟悉基本的JVM参数;
- 会分析JVM的GC日志;
- 会使用jstat、jmap、jhat等命令行工具分析程序运行情况;
- 会使用jvisualvm、mat等可视化工具分析程序堆栈日志;
- 熟悉OOM发生在不同位置的常见原因;
2.1 JVM参数
2.1.1 JVM参数示例
在系统运行时,新生成的对象,通常来说都是优先分配在新生代中的Eden区域,然后随着垃圾回收,交替使用两个Survivor区域进行存活对象的复制;默认Eden区和两个Survivor区的比值为:8:1:1;例如使用如下JVM参数来运行系统:
-Xms4G -Xmx4G -Xmn2G -Xss1M -XX:SurvivorRatio=8 -XX:PretenureSizeThreshold=10M
-XX:+PrintGCDetils -XX:+PrintGCTimeStamps -Xloggc:gc.log -XX:+UseParNewGC -XX:+UseConcMarkSweepGC
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/oom
这些参数都是基于 JDK1.8设置的,不同JDK版本对应的参数名称可能不太一样。
-
“-Xms4G”和 “-Xmx4G”:虚拟机堆内存的初始大小和最大大小,它们两个被建议设置为相等的;
-
原因:如果初始堆大小设置过小,在应用内存分配不够时,JVM会先频繁地触发GC操作,当GC操作无法释放更多内存时,才会进行内存的扩充,直到最大堆大小;所以设置为相等可以避免频繁GC和扩容造成的系统开销。
-
“-Xmn2G”:新生代的大小;
-
“-Xss1M”:每个线程的栈内存大小;
-
“-XX:SurvivorRatio=8”:Eden:Survivor:Survivor区的比值,默认即为8,可以不设置;
-
“-XX:PretenureSizeThreshold=10M”:指定大对象阈值为10MB;
-
“XX:+PrintGCDetils”:打印详细的GC日志;
-
“-XX:+PrintGCTimeStamps”:打印每次GC发生的时间;
-
“-Xloggc:gc.log”:将GC日志写入指定文件;
-
“-XX:+UseParNewGC”:新生代使用ParNew垃圾回收器;
-
“-XX:+UseConcMarkSweepGC”:老年代使用CMS垃圾回收器;
-
“-XX:+HeapDumpOnOutOfMemoryError”:发生OOM的时候自动dump堆内存快照出来;
-
“-XX:HeapDumpPath=/usr/local/oom”:把dump出来的内存快照文件存放到指定目录;
2.1.2 JVM参数汇总
| 参数 | 示例 | 说明 |
|---|---|---|
| -Xms | -Xms1G | 初始堆大小;默认空闲堆内存小于40%(XX:MinHeapFreeRatio),JVM就会增大堆到-Xmx的最大限制 |
| -Xmx | -Xmx1G | 最大堆大小;默认空闲堆内存大于70%时,JVM会减少堆到 -Xms的最小限制 |
| -Xmn | -Xmn512M | 新生代大小;(eden+ 2 survivor space)的大小;SUN官方推荐配置为整个堆的3/8 |
| -XX:NewRatio | -XX:NewRatio=2 | 新生代与老年代比值;-XX:NewRatio=2表示新生代与老年代所占比例为1:2,新生代占整个堆空间的1/3 |
| -XX:SurvivorRatio | -XX:SurvivorRatio=8 | Eden:Survivor:Survivor;默认为8,Eden区占新生代的8/10,Survivor区分别占新生代的1/10 |
| -Xss | -Xss1M | 线程的栈内存大小;JDK5.0以后每个线程栈内存大小为1M |
| -XX:MetaspaceSize | -XX:MetaspaceSize=512M | 元数据空间初始大小 |
| -XX:MaxMetaspaceSize | -XX:MaxMetaspaceSize=512M | 元数据空间最大大小 |
| -XX:+UseSerialGC | 虚拟机运行在Client模式下的默认值,设置后使用 Serial + Serial Old 组合进行垃圾回收 | |
| -XX:+UseParNewGC | 使用 ParNew + Serial Old 组合进行垃圾回收 | |
| -XX:+UseConcMarkSweepGC | 使用 ParNew + CMS + Serial Old 组合进行垃圾回收,Serial Old作为CMS收集器失败后的后备收集器使用 | |
| -XX:CMSInitiatingOccupanyFraction | 使用CMS时,在老年代空间被使用多少后出发垃圾回收;默认值 68% | |
| -XX:+UseCMSCompactAtFullCollection | 使用CMS时,开启对老年代的压缩 | |
| -XX:CMSFullGCsBeforeCompaction=0 | 使用CMS时,多少次Full GC后,对老年代进行压缩 | |
| -XX:+UseParallelGC | 虚拟机运行在Server模式下的默认值,设置后使用 Parallel Scavenge + Serial Old 组合进行垃圾回收 | |
| -XX:+UseParallelOldGC | 使用 Parallel Scavenge + Parallel Old 组合进行垃圾回收 | |
| -XX:+UseG1GC | 使用 G1 进行垃圾回收 | |
| -XX:+PrintGC | 打印GC简单信息 | |
| -XX:+PrintGCDetails | 打印GC详细信息 | |
| -XX:+PrintGCTimeStamps | 打印每次GC发生的时间 | |
| -Xloggc:gc.log | 将GC日志写入指定文件 | |
| -XX:+HeapDumpOnOutOfMemoryError | 发生OOM的时候自动dump堆内存快照出来 | |
| -XX:HeapDumpPath=/usr/local/oom | 把dump出来的内存快照文件存放到指定目录 |
2.2 GC 日志
JVM运行参数:
-Xmx10m -Xms10m -Xmn5m -XX:SurvivorRatio=8 -XX:PretenureSizeThreshold=10m -XX:+UseParNewGC -XX:+UseConcMarkSweepGC
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:log/demo1.log
示例代码:
public class Demo1 {
public static void main(String[] args) {
byte[] array1 = new byte[1024 * 1024];
array1 = new byte[1024 * 1024];
array1 = new byte[1024 * 1024];
array1 = null;
byte[] array2 = new byte[2 * 1024 * 1024];
}
}
2.2.1 Java代码在JVM中的运行流程
-
public static void main(String[] args)在main线程的虚拟机栈中压入一个main()方法的栈帧;
-
byte[] array1 = new byte[1024 * 1024];在新生代Eden区中创建一个1MB的byte数组对象;
-
在main()方法的栈帧中创建一个 array1 的局部变量,并指向Eden区中那个1MB的byte数组对象;
-
array1 = new byte[1024 * 1024];继续在Eden区中创建第二个byte数组对象,并让 array1这个局部变量指向这第二个对象;那这个时候第一个byte数组对象就没有引用了,也就变成了“垃圾对象”;
-
array1 = new byte[1024 * 1024];同样,创建第三个byte数组对象,第二个byte数组对象变成“垃圾对象”;
-
array1 = null;让array1这个变量指向了null,意思就是第三个byte数组对象也变成了“垃圾对象”;也就是说这里三个对象都变成了“垃圾对象”;(但是不会马上被回收)
-
byte[] array2 = new byte[2 * 1024 * 1024];继续在Eden区中创建2MB的byte数组对象;
-
那这个时候还能正常创建吗?不行的;
-
来看JVM参数:
-Xmn5m -XX:SurvivorRatio=8,意思是新生代只分配了5MB的内存空间,按比例,Eden区只有4M的内存空间; -
而在前面的代码执行中,已经往Eden区放入了3MB的对象了,剩余空间只有1MB不到了(因为还会有一些元数据),所以此时要想再放入2MB的新对象,是放不进去的;如图:
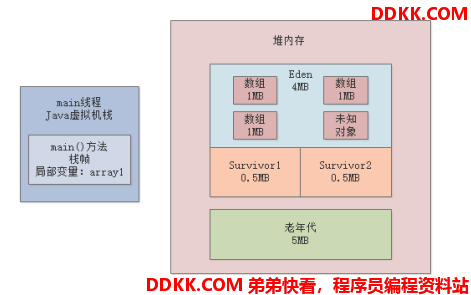
所以这个时候就会发生新生代GC(Young GC);如图:
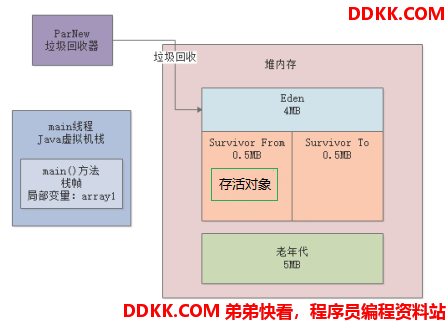
在新生代GC发生之后,由于前面三个对象都已经是“垃圾对象”了,所以都能被回收,在被回收之后,Eden区又空出来接近4MB的内存空间,这个时候就能放入新的array2对象了;
那怎么知道到底是不是这样执行的呢?我们又能怎么进行验证?来看看GC日志就知道了。
2.2.2 GC日志分析
使用上面的JVM参数运行这段代码,就会在log目录下的demo1.log文件中,看到这段代码执行的GC日志。
Java HotSpot(TM) 64-Bit Server VM (25.181-b13) for linux-amd64 JRE (1.8.0_181-b13), built on Jul 7 2018 00:56:38 by "java_re" with gcc 4.3.0 20080428 (Red Hat 4.3.0-8)
Memory: 4k page, physical 1863076k(369904k free), swap 2097148k(2097148k free)
CommandLine flags: -XX:InitialHeapSize=10485760 -XX:MaxHeapSize=10485760 -XX:MaxNewSize=5242880 -XX:NewSize=5242880 -XX:OldPLABSize=16 -XX:PretenureSizeThreshold=10485760 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:SurvivorRatio=8 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
0.048: [GC (Allocation Failure) 0.048: [ParNew: 3498K->264K(4608K), 0.0005606 secs] 3498K->264K(9728K), 0.0006166 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
Heap
par new generation total 4608K, used 2395K [0x00000000ff600000, 0x00000000ffb00000, 0x00000000ffb00000)
eden space 4096K, 52% used [0x00000000ff600000, 0x00000000ff814930, 0x00000000ffa00000)
from space 512K, 51% used [0x00000000ffa80000, 0x00000000ffac22d0, 0x00000000ffb00000)
to space 512K, 0% used [0x00000000ffa00000, 0x00000000ffa00000, 0x00000000ffa80000)
concurrent mark-sweep generation total 5120K, used 0K [0x00000000ffb00000, 0x0000000100000000, 0x0000000100000000)
Metaspace used 2477K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 267K, capacity 386K, committed 512K, reserved 1048576K
-
CommandLine flags:基本都是我们设置的JVM参数,和没有设置时,系统默认给的JVM参数;
-
0.048:说明这次GC是在系统运行了 40ms左右发生的;
-
GC (Allocation Failure):发生了一次GC;Allocation Failure:对象分配失败;
为什么会发生?看参数,Eden区只有 4M;再看代码,我们先分配了3M,再需要分配2M的时候,Eden区不够了,所以此时需要触发一次 Young GC; -
[ParNew: 3498K->264K(4608K), 0.0005606 secs]:因为这里我们使用的是 ParNew + CMS,所以 Young GC使用 ParNew收集;
-
3498K->264K:新生代执行了一次 Young GC, 执行之前使用了 3498K,GC 之后还有 264K的对象存活下来;
(这里可能会有疑惑,我们生成的对象是3M的数组,应该是3072KB,那GC执行前应该是使用了3072KB内存吧,但是这里为什么是3498K呢?
这是因为JVM为了存储数组,还会附带一些其他的内置信息(元数据),所以每个数组实际占用的内存是要大于1MB的) -
4608K:新生代可用空间大小为4608K,也就是4.5M,为什么是4.5M? Eden区4M + 一个Survivor区0.5M = 4.5M;
-
0.0005606 secs:本次 GC 消耗的时间,大概消耗了1ms,因为就仅仅是回收 3M的对象;
-
3498K->264K(9728K), 0.0006166 secs:指整个堆内存的回收情况;
9728K:整个Java堆可用空间为9728K,新生代4.5M + 老年代5M;
[Times: user=0.00 sys=0.00, real=0.00 secs]:本次GC消耗的时间;因为只消耗了几毫秒,而这里单位是秒,只保留到小数点后两位的话,就全是0;
Heap后面的是 在JVM退出的时候打印出来的当前堆的内存情况。
- par new generation total 4608K, used 2395K:ParNew 垃圾回收器负责的新生代总共有4608K(4.5MB)可用内存,目前是使用了 2395K;
上次回收剩下的 264K + 2048K(新生成的2M)= 2294K,这里为什么是 2395K呢?
这里多出来的,也就是上面说到的,每个数组会额外占据一些内存来存放自己这个对象的元数据; - eden space 4096K, 52% used:Eden区此时 4M内存被使用了52%,也就是我们后面创建的 2M的数组;
- from space 512K, 51% used:Survivor From区此时的 512K内存被使用了 51%,也就是上面 Young GC 存活下来的 264K的未知对象
- concurrent mark-sweep generation total 5120K, used 0K :老年代的CMS垃圾回收器 管理的老年代内存一共是我们指定的 5M,此时没有使用,因为我们没有对象进入老年代;
- Metaspace used 2477K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 267K, capacity 386K, committed 512K, reserved 1048576K
Metaspace元数据空间和Class空间,存放一些类信息、常量池之类的东西,此时他们的总容量,使用内存,等等
所以经过GC日志的分析,我们不仅能够验证上面的代码执行流程,还能知道各种对象在JVM中的分配情况。