在0.10 版本之前,Kafka 仅仅只是一个消息系统,主要处理 解耦、异步消息、流量削峰 等问题。
在0.10 版本之后,Kafka 提供了连接器和流处理的能力,从分布式的消息系统逐渐成为一个流式的数据平台。
分区模型
- Kafka 由多个 broker server (消息代理服务器) 组成,每条消息的类别用 topic (主题) 来表示
- Kafka 为每个 topic 维护了分布式的 partition (分区) 日志文件
- 每个 partition 都是有序、不可变的记录序列,新消息不断追加到 commit log (提交日志)
- partition 中的每条消息都会按照时间顺序分配到一个单调递增的 offset (偏移量),offset 是唯一能定位消息在当前 partition 中的位置
消费模型
-
Kafka 采用的是拉取模型作为消费模型,由消费者自己记录消费状态,消费者拉取的最大上限通过 watermark 控制,生产者最新消息没达到备份数量,对消费者是不可见的
-
好处是消费者可以按照任意顺序消费消息,可以重复消费,可以跳过消费
-
生产者发布的消息会一直保存在 Kafka 中,不管有没有消费,到达设置的保留时间会清理过期的数据
分布式模型
- Kafka 采用分布式的方式存储每个 topic 的多个 partition 日志,为了故障容错,每个分区会以副本的方式复制到多个 broker 上
- Leader replica 负责客户端的读写操作,Follower replica 负责从 Leader replica 中同步数据,Leader replica 出现故障,Follower replica 会接替成为 Leader replica
- 生产者发布消息的时候会根据是否有键来选择分区策略,有键总是会分到相同分区,没有键会采用轮询的方式进行负载均衡
- 消费者按照 队列模型、发布-订阅模型 来消费数据
Kafka 如何保证消息的有序性
Kafka 以 partition 为最小的粒度,将每个 partition 分配给消费组中不同且唯一的消费者,这个消费者是这个分区唯一的读取线程,只要 partition 消息是有序的,处理的消息顺序就是有序的
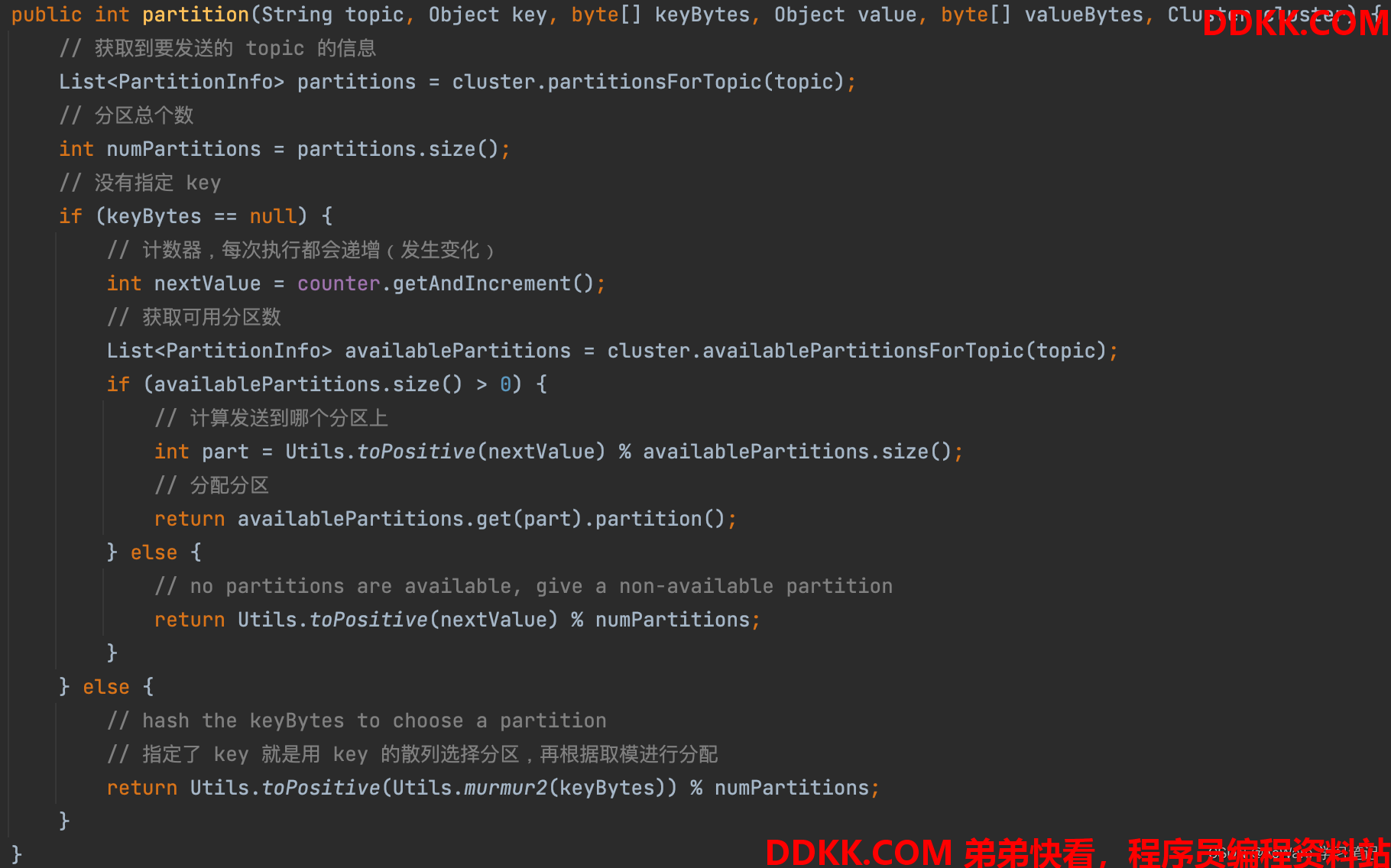
Kafka 的生产者如何确定消息发往哪个分区的
在 Kafka 生产者 send 消息之后会执行 doSend() 方法,在 doSend() 方法里面会执行 partition() 方法进行 partition 计算,如果这条消息已经分配了分区号,会直接返回该分区号,如果没有,就会进入分区器进行选择,默认使用 DefaultPartitioner 这个分区器,如果有 key 的话会根据 key 的散列值取模得到分区号,如果没有 key,会有一个计数器递增记录,然后根据可用分区数进行计算,得到最后的分区号
[0.10.1.0 版本] org.apache.kafka.clients.producer.internals.DefaultPartitioner#partition