前言:如果RabbitMQ集群中只有一个Broker节点,那么该节点的失效将导致整体服务的临时性不可用,并且也可能会导致消息的丢失,虽然可以将所有消息都设置为持久化,并且对应队列的durable属性也设置为true,这样可以保证消息不丢失,但是这样仍然无法避免由于缓存导致的问题:因为消息在发送之后和被写入磁盘井执行刷盘动作之间存在一个短暂却会产生问题的时间窗。通过 publisherconfirm机制能够确保客户端知道哪些消息己经存入磁盘,尽管如此,一般不希望遇到因单点故障导致的服务不可用,而通过引入镜像队列(Mirror Queue)的机制,可以将队列镜像到集群中的其他Broker节点之上,如果集群中的一个节点失效了,队列能自动地切换到镜像中的另一个节点上以保证服务的可用性。
验证过程如下(没开启消息持久化,有兴趣的同学可以看看):
我这里准备了3台虚拟机来跑RabbitMQ服务分别为
node1:192.168.194.128
node2:192.168.194.129
node3:192.168.194.130
(1)执行以下代码,在node1节点里生成队列
package com.ken;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.MessageProperties;
/**
* 生产者
*/
public class Producer {
//队列名称(用于指定往哪个队列发送消息)
public static final String QUEUE_NAME = "my_queue";
//进行发送操作
public static void main(String[] args) throws Exception{
//创建一个连接工厂
ConnectionFactory factory = new ConnectionFactory();
//设置工厂IP,用于连接RabbitMQ的队列
factory.setHost("192.168.194.128");
//设置连接RabbitMQ的用户名
factory.setUsername("admin");
//设置连接RabbitMQ的密码
factory.setPassword("123456");
//创建连接
Connection connection = factory.newConnection();
//获取信道
Channel channel = connection.createChannel();
/**
* 创建队列
* 第一个参数:队列名称
* 第二个参数:服务器重启后队列是否还存在,即队列是否持久化,true为是,false为否,默认false,即消息存储在内存中而不是硬盘中
* 第三个参数:该队列是否只供一个消费者进行消费,是否进行消息共享,true为只允许一个消费者进行消费,false为允许多个消费者对队列进行消费,默认false
* 第四个参数:是否自动删除,最后一个消费者断开连接后该队列是否自动删除,true自动删除,false不自动删除
* 第五个参数:其他参数
*/
channel.queueDeclare(QUEUE_NAME,false ,false,false,null);
//发消息
String message = "Hello World";
/**
* 用信道对消息进行发布(消息持久化)
* 第一个参数:发送到哪个交换机
* 第二个参数:路由的Key值是哪个,本次是队列名
* 第三个参数:其他参数信息
* 第四个参数:发送消息的消息体
*/
channel.basicPublish("",QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes());
System.out.println("消息发送成功!");
}
}
效果图:

(2)进页面查看效果,可以得知my_queue这个队列只在node1节点创建了,没在其他节点同步创建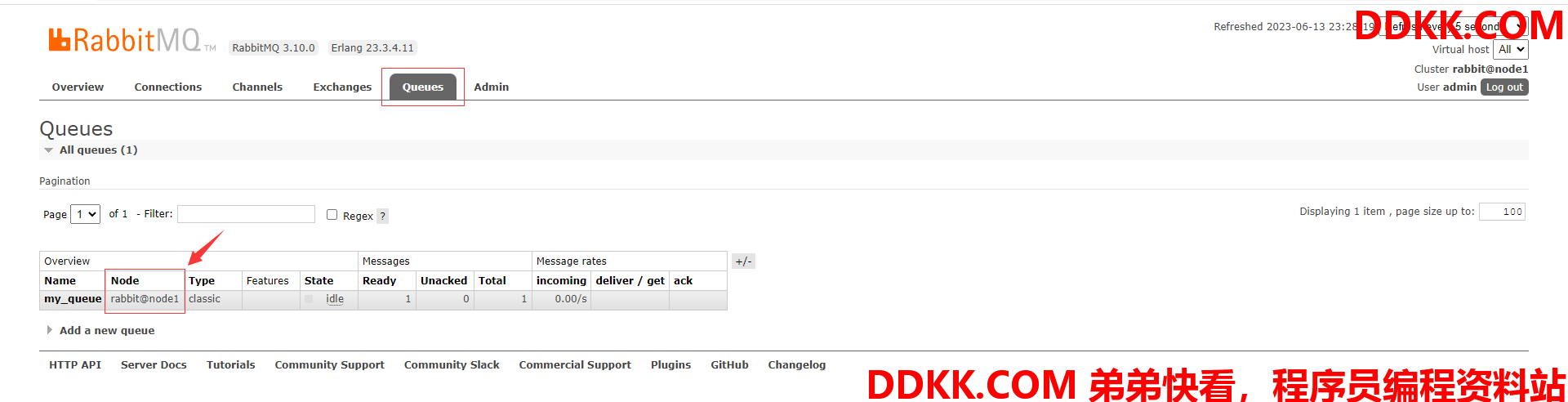
(3)在node1节点执行关闭RabbitMQ服务的命令来模拟节点宕机
rabbitmqctl stop_app
效果图:

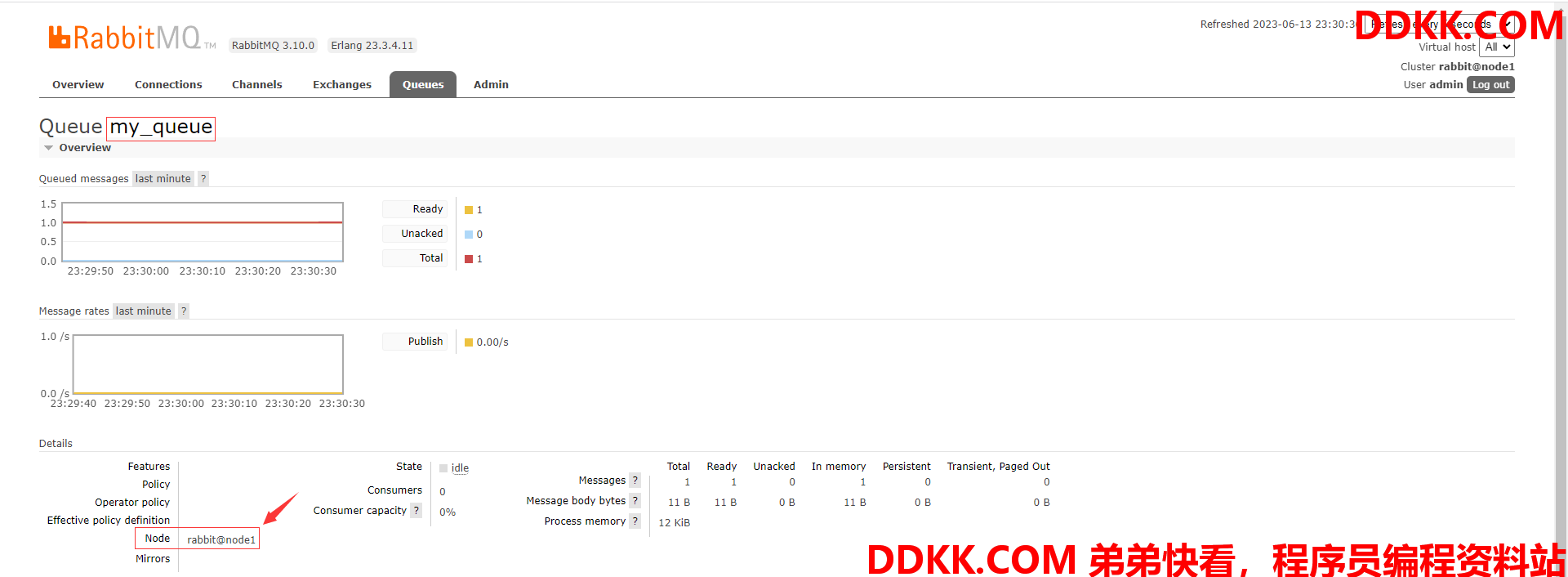
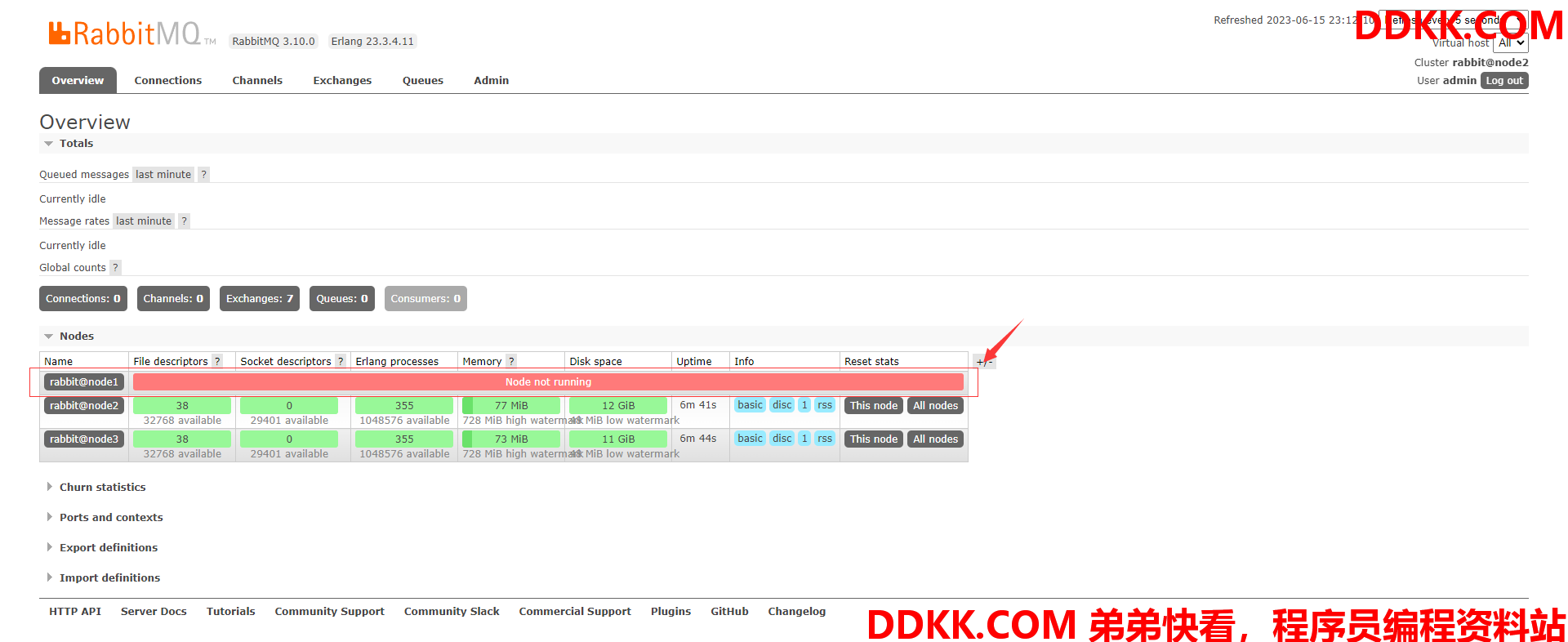
(4)用其他节点的可视化页面来查看集群信息,由图可知node1节点没在运行
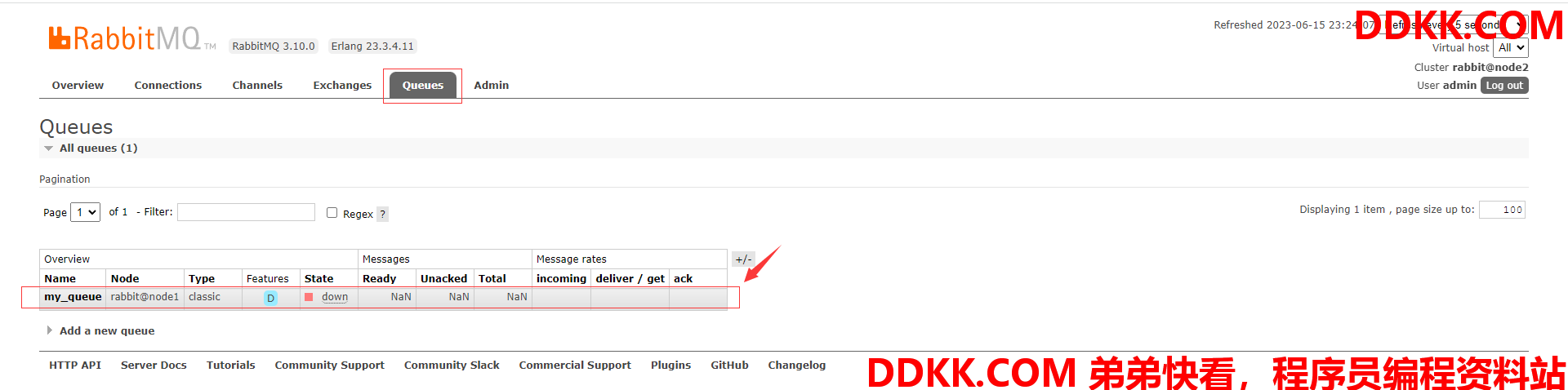
(5)查看队列,可以看到my_queue队列的状态为停止
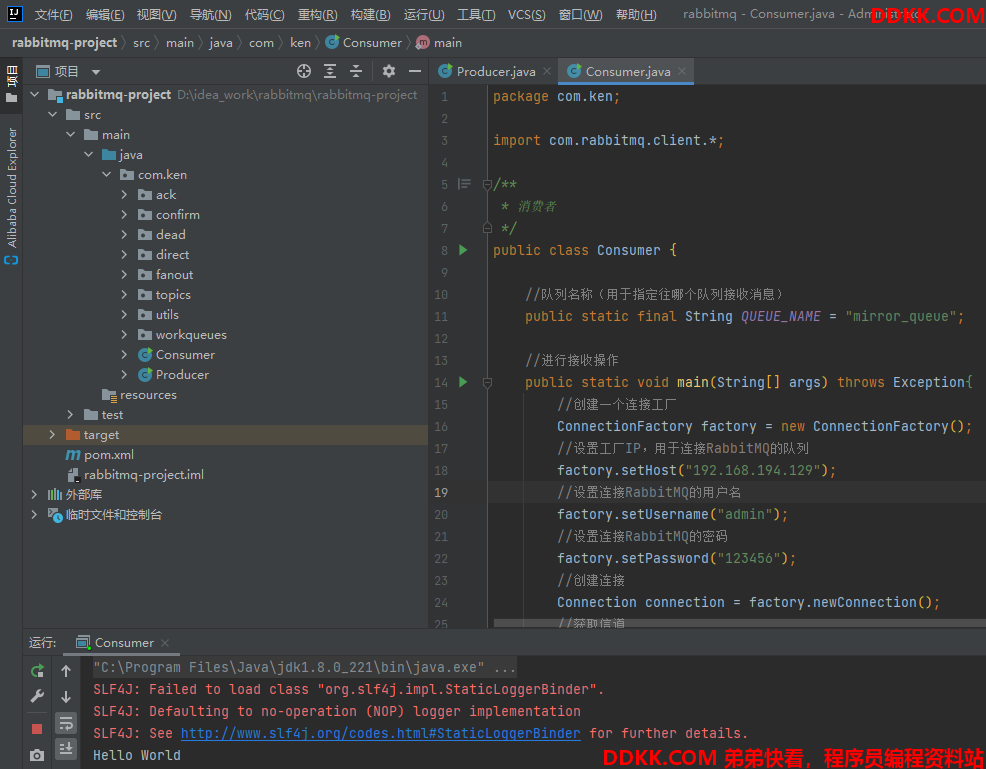
(6)执行以下代码,在node2节点里生成消费者,尝试消费消息
package com.ken;
import com.rabbitmq.client.*;
/**
* 消费者
*/
public class Consumer {
//队列名称(用于指定往哪个队列接收消息)
public static final String QUEUE_NAME = "my_queue";
//进行接收操作
public static void main(String[] args) throws Exception{
//创建一个连接工厂
ConnectionFactory factory = new ConnectionFactory();
//设置工厂IP,用于连接RabbitMQ的队列
factory.setHost("192.168.194.129");
//设置连接RabbitMQ的用户名
factory.setUsername("admin");
//设置连接RabbitMQ的密码
factory.setPassword("123456");
//创建连接
Connection connection = factory.newConnection();
//获取信道
Channel channel = connection.createChannel();
/**
* 声明消费者接收消息后的回调方法(由于回调方法DeliverCallback是函数式接口,所以需要给DeliverCallback赋值一个函数,为了方便我们这里使用Lambda表达式进行赋值)
* 为什么要这样写呢,是因为basicConsume方法里的参数deliverCallback的类型DeliverCallback用 @FunctionalInterface注解规定DeliverCallback是一个函数式接口,所以要往deliverCallback参数传的值要是一个函数
*
* 以下是DeliverCallback接口的源代码
* @FunctionalInterface
* public interface DeliverCallback {
* void handle (String consumerTag, Delivery message) throws IOException;
* }
*/
DeliverCallback deliverCallback = (consumerTag,message) -> {
System.out.println(new String(message.getBody()));
};
/**
* 声明消费者取消接收消息后的回调方法(由于回调方法CancelCallback是函数式接口,所以需要给CancelCallback赋值一个函数,为了方便我们这里使用Lambda表达式进行赋值)
* 为什么要这样写呢,是因为basicConsume方法里的参数cancelCallback的类型CancelCallback用 @FunctionalInterface注解规定CancelCallback是一个函数式接口,所以要往cancelCallback参数传的值要是一个函数
*
* @FunctionalInterface
* public interface CancelCallback {
* void handle (String consumerTag) throws IOException;
* }
*
*/
CancelCallback cancelCallback = consumerTag -> {
System.out.println("取消消费消息");
};
/**
* 用信道对消息进行接收
* 第一个参数:消费的是哪一个队列的消息
* 第二个参数:消费成功后是否要自动应答,true代表自动应当,false代表手动应答
* 第三个参数:消费者接收消息后的回调方法
* 第四个参数:消费者取消接收消息后的回调方法(正常接收不调用)
*/
channel.basicConsume(QUEUE_NAME,true,deliverCallback,cancelCallback);
}
}
效果图:(报错信息提示node1节点上的my_queue队列已经关闭了)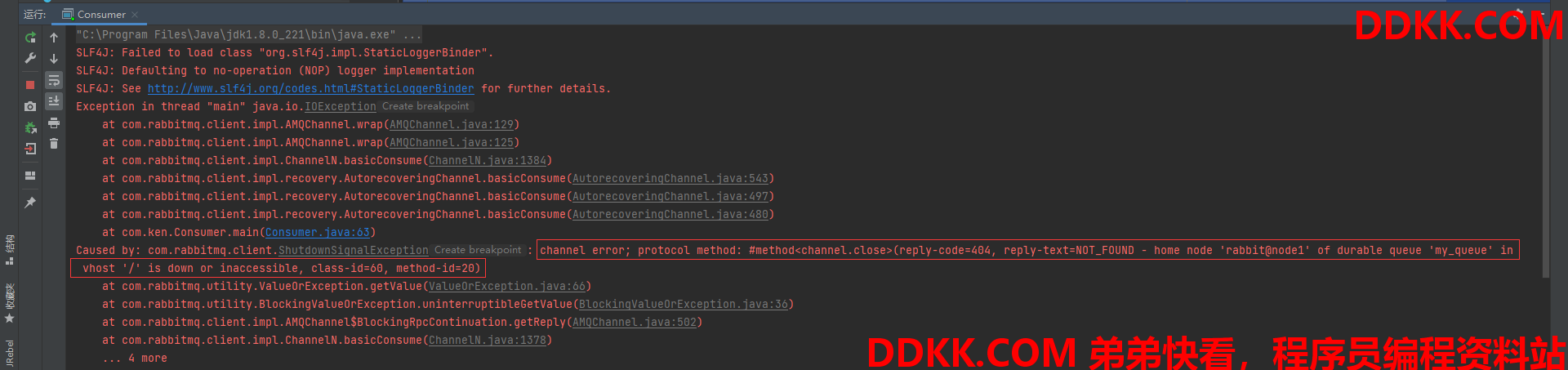
(7)把node1节点上的RabbitMQ服务重新启动起来
rabbitctl start_app
效果图:

(8)查看消费者的日志,可以发现消费者并没有消费消息

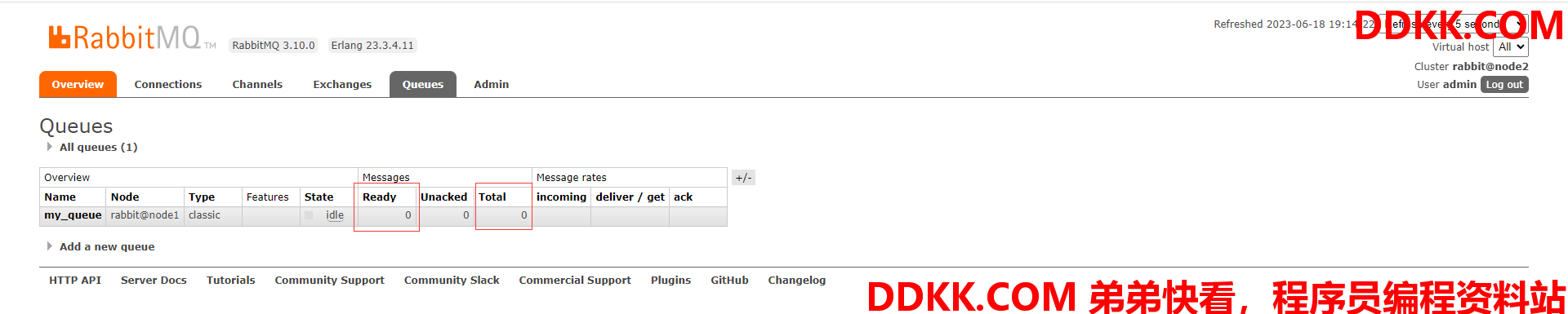
(9)查看队列里消息的情况,可以看到消息丢失了(在未设置消息持久化的情况下)
搭建镜像队列
1、 启动node1、node2、node3三台集群节点;
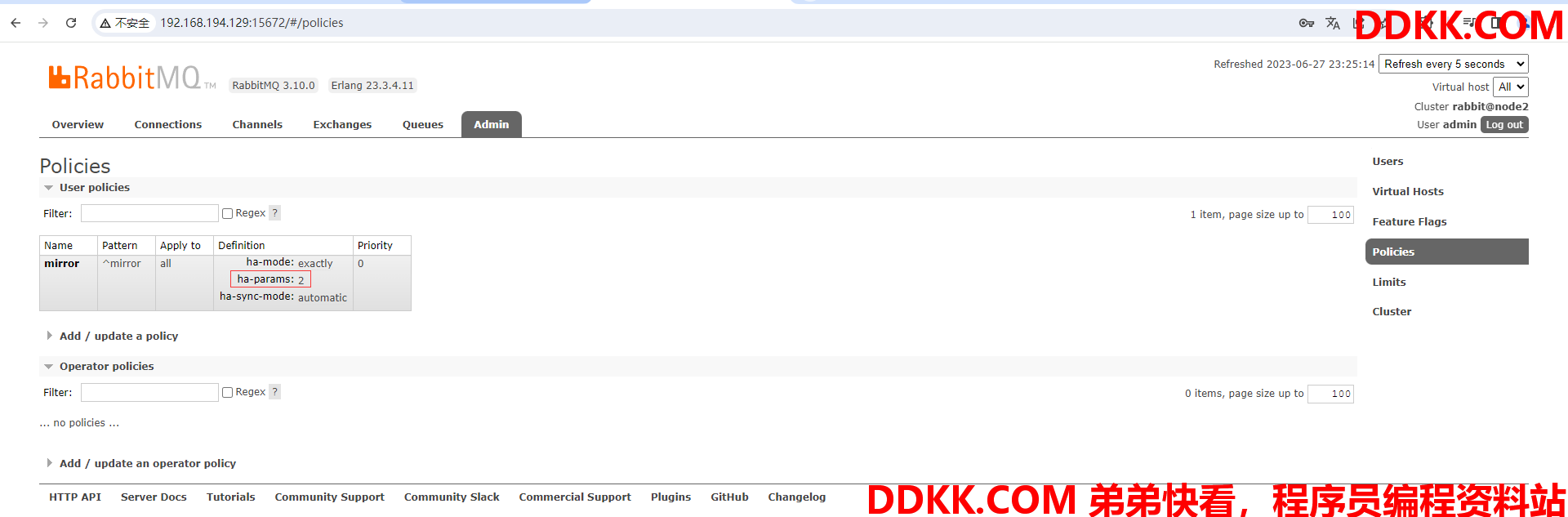
2、 随便找一个节点添加policy(策略);
(1)进入node1节点的可视化界面
(2)进入添加策略的界面
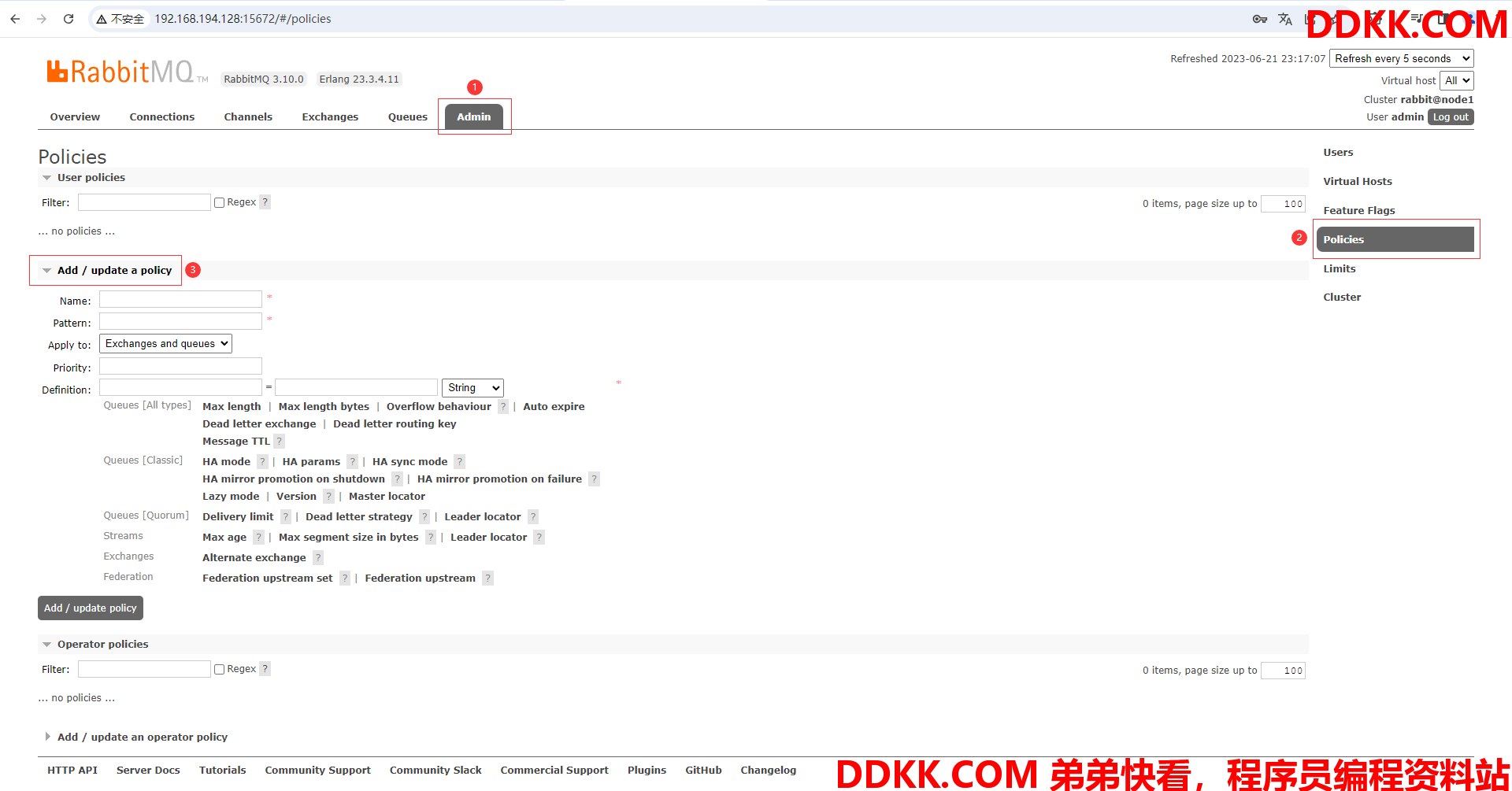
(3)给策略取一个名字 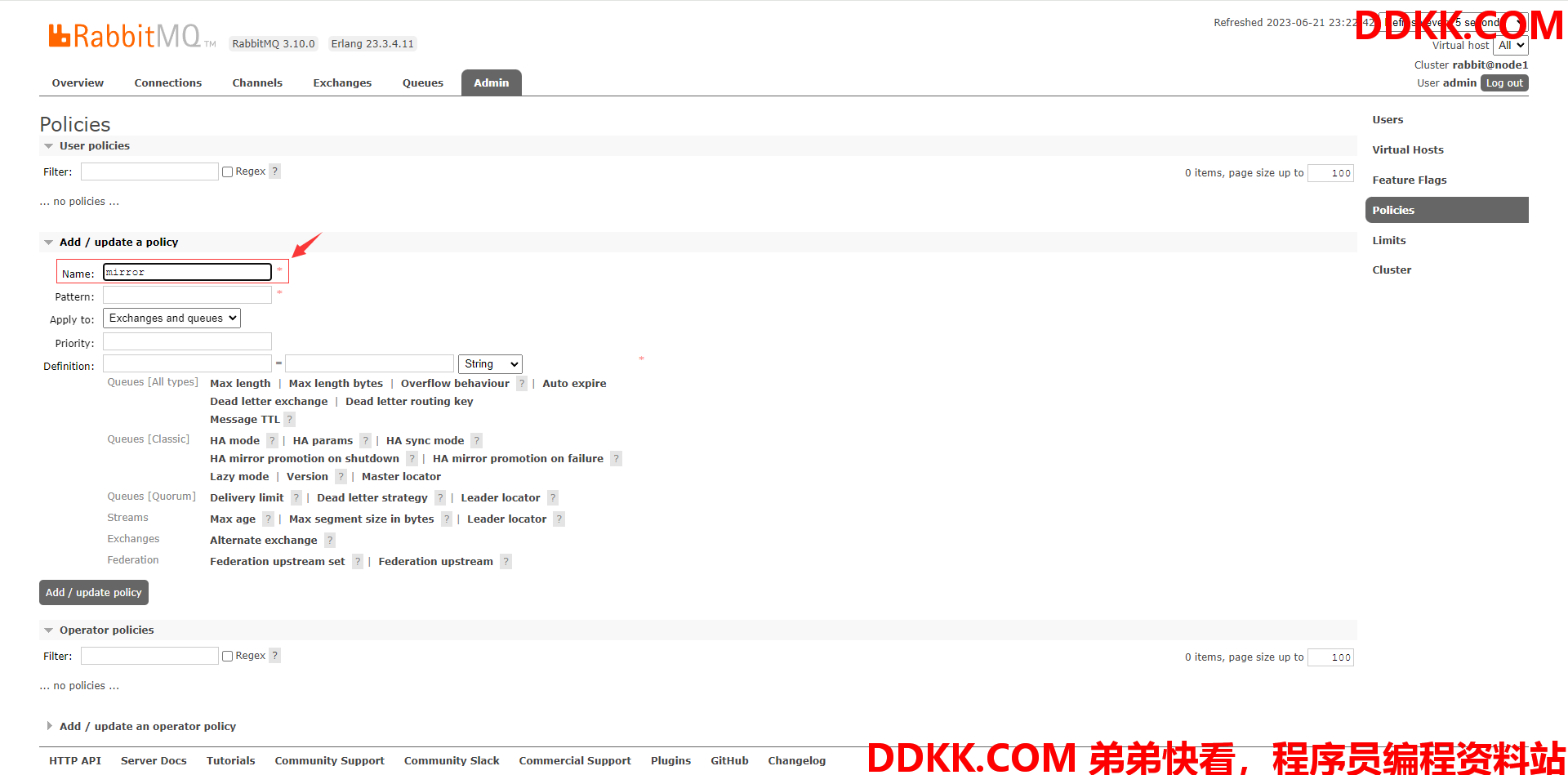
(4)给策略加上匹配规则,通过正则表达式匹配队列,若交换机或者队列的名字满足以mirror开头这个条件,则那条队列使用该策略
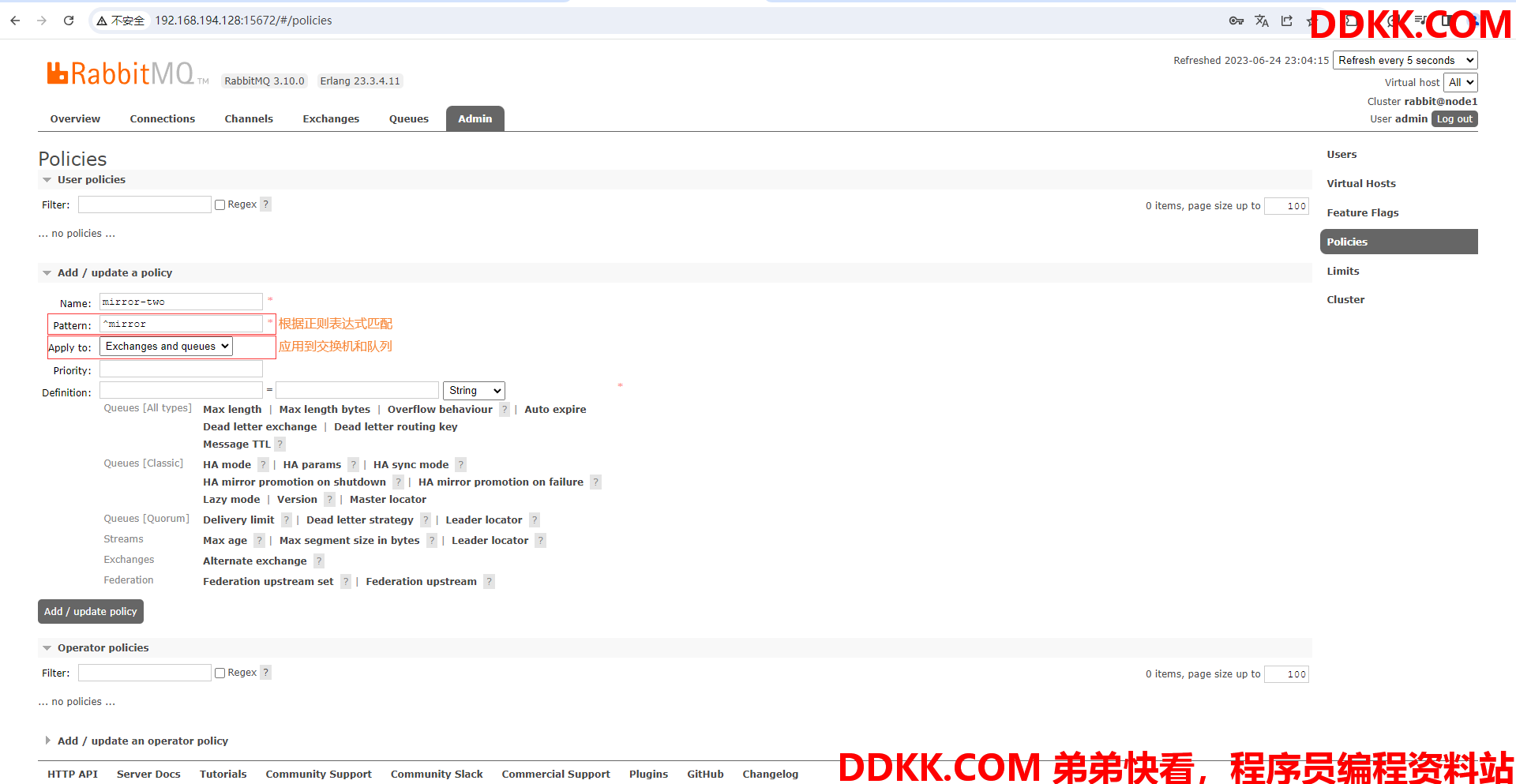
例:

(5)为策略选择模式为ha-mode(ha-mode表示是备机模式)点击HA mode即可
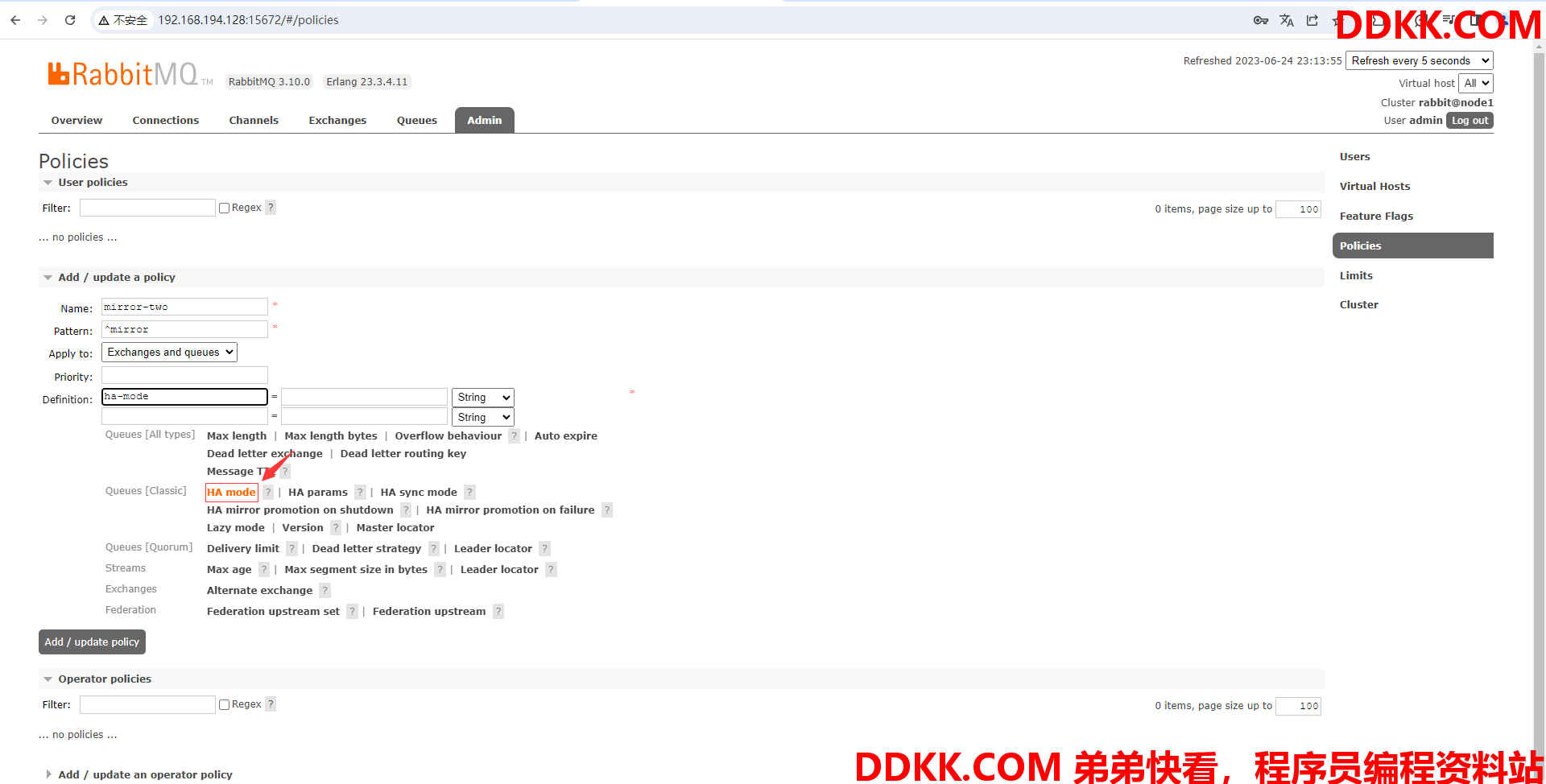
(6)为ha-mode指定获取参数方式为exactly(exactly表示指定参数)
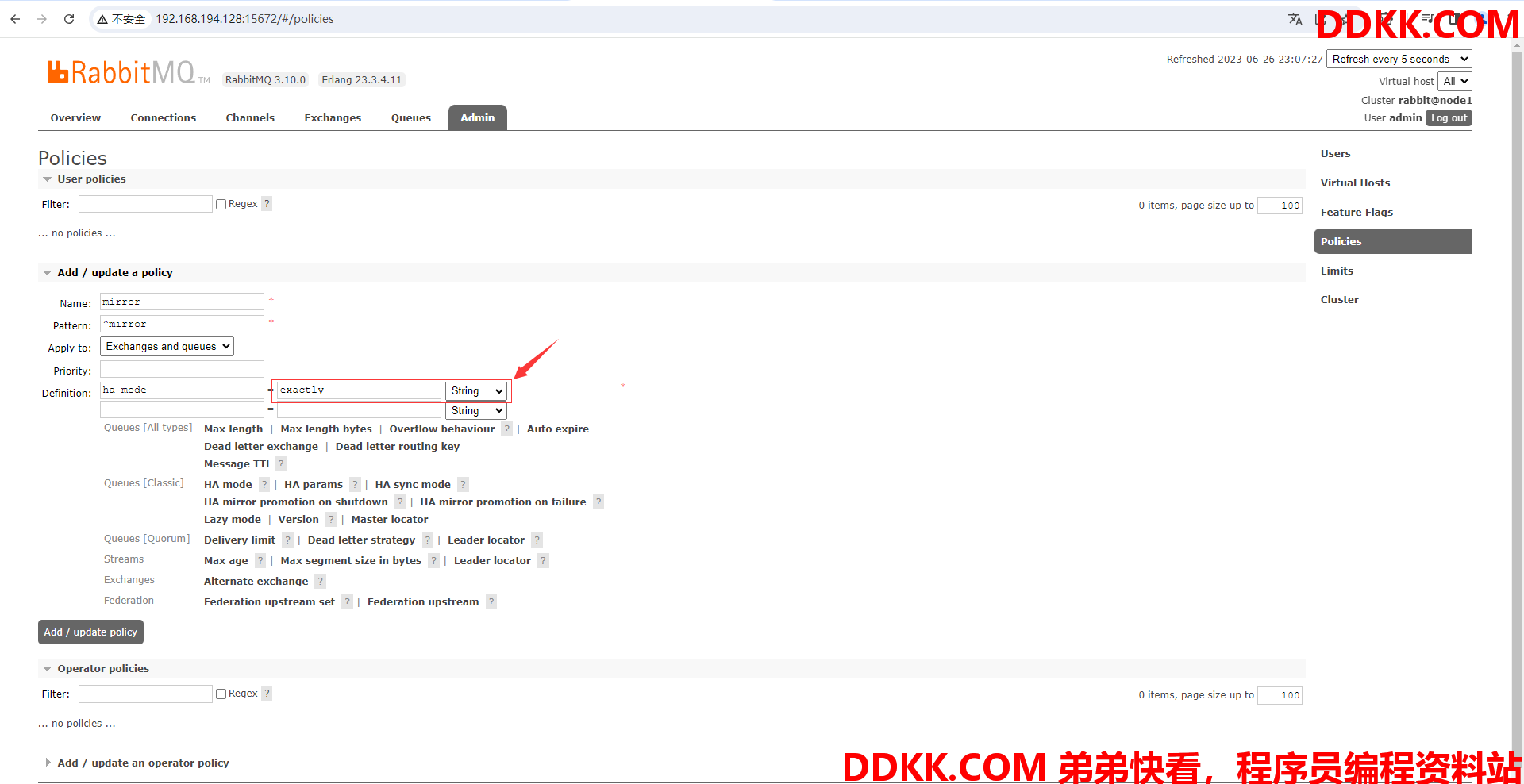
(7)点击HA params,就会往自定义参数里填入ha-params,这里用于指定策略作用的节点的数量
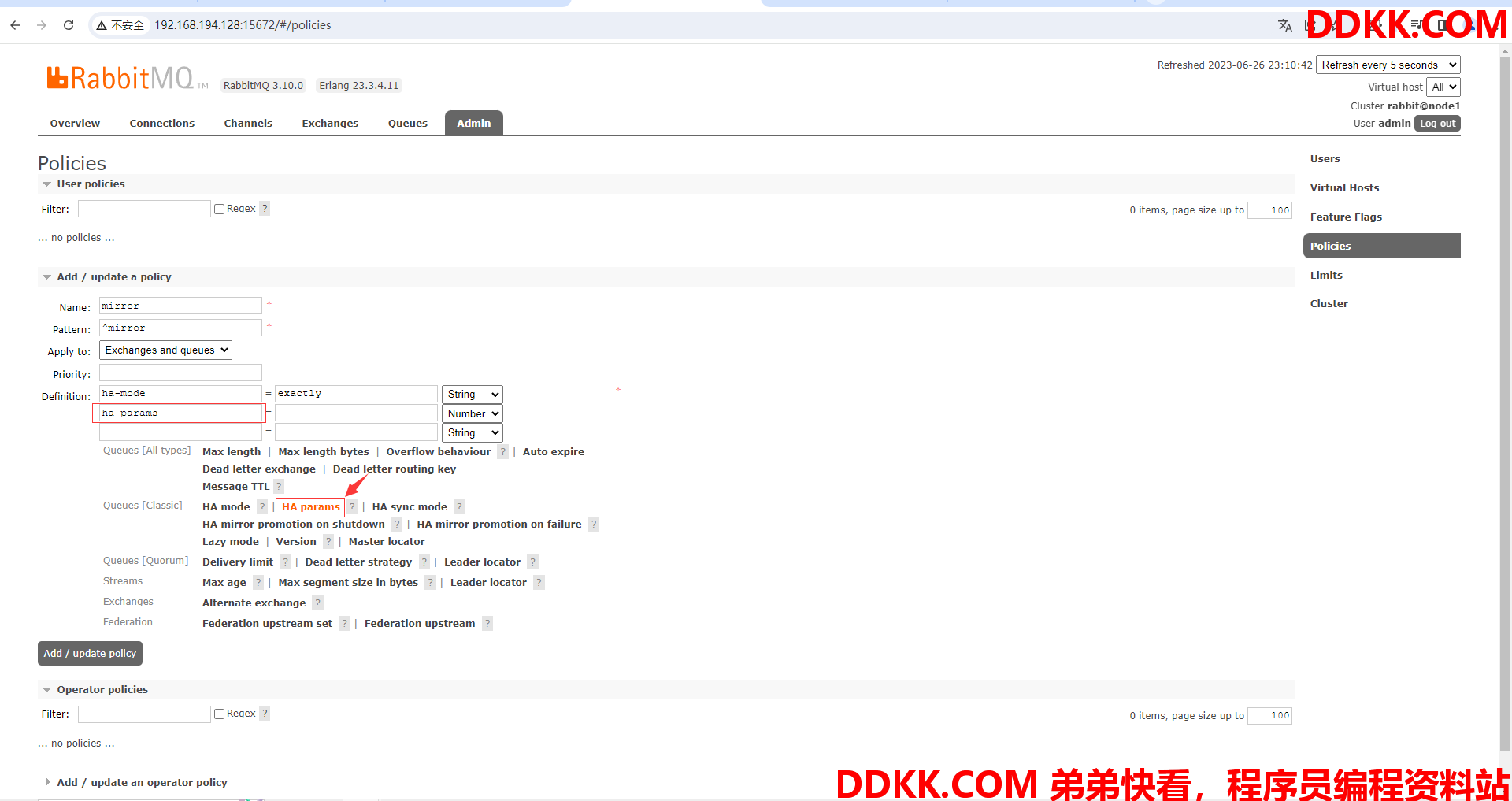
(8)为ha-params指定策略作用的节点的数量为2(包含被镜像的队列,镜像和被镜像的队列数总共为2)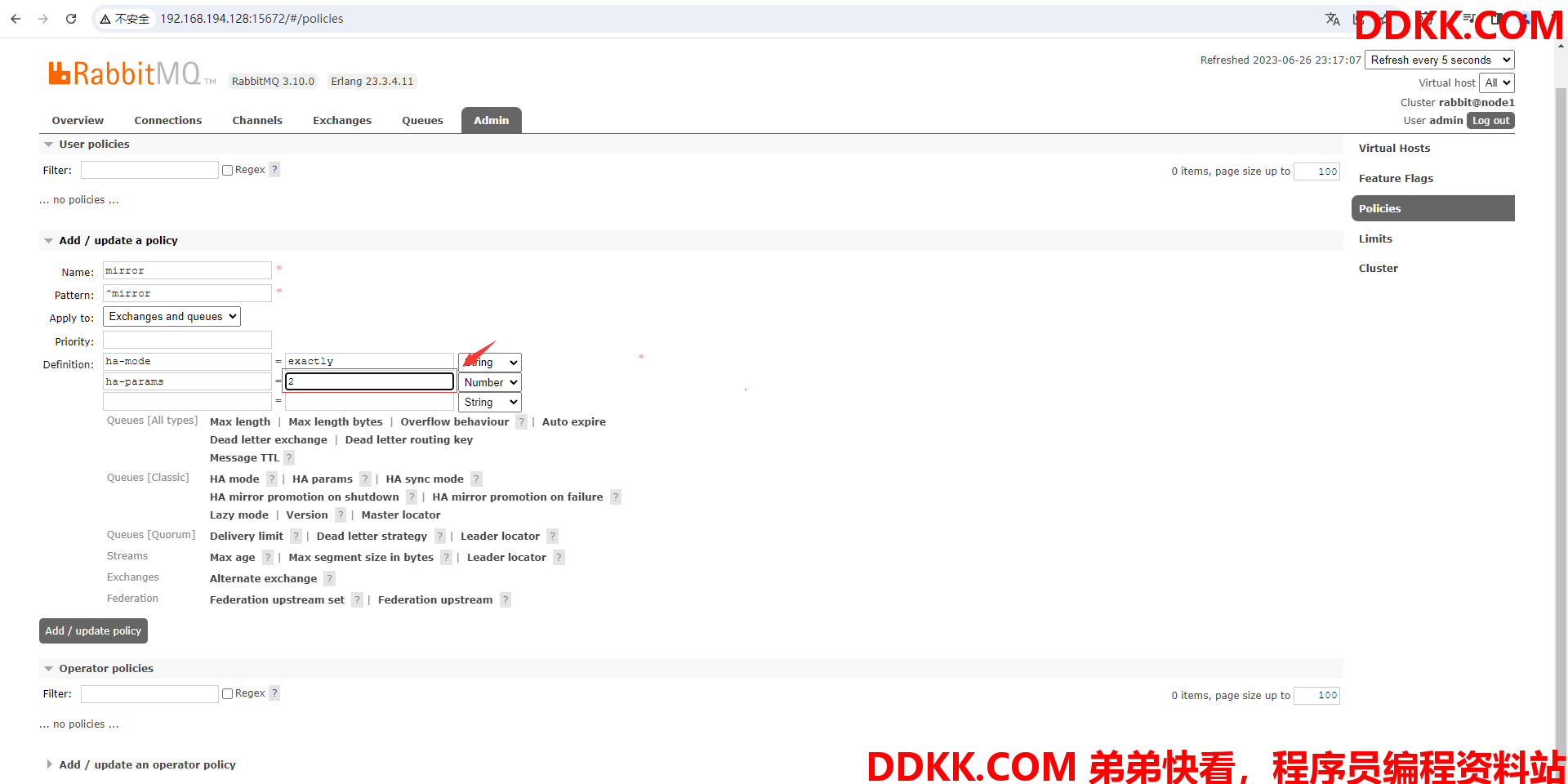
(9)点击HA sync mode,就会往自定义参数里填入ha-sync-mode,这里用于指定同步的模式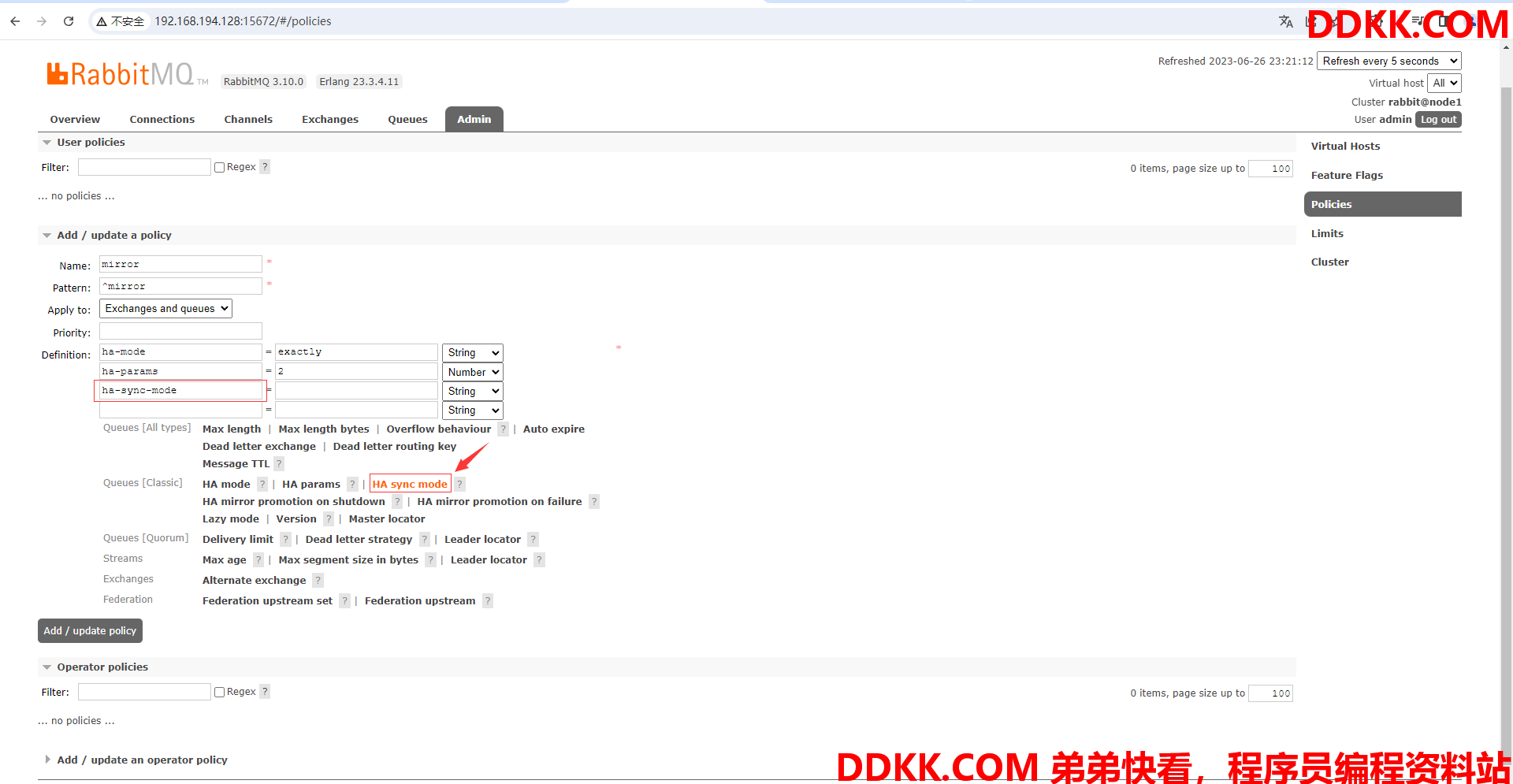
(10)为ha-sync-mode指定同步模式为自动同步模式
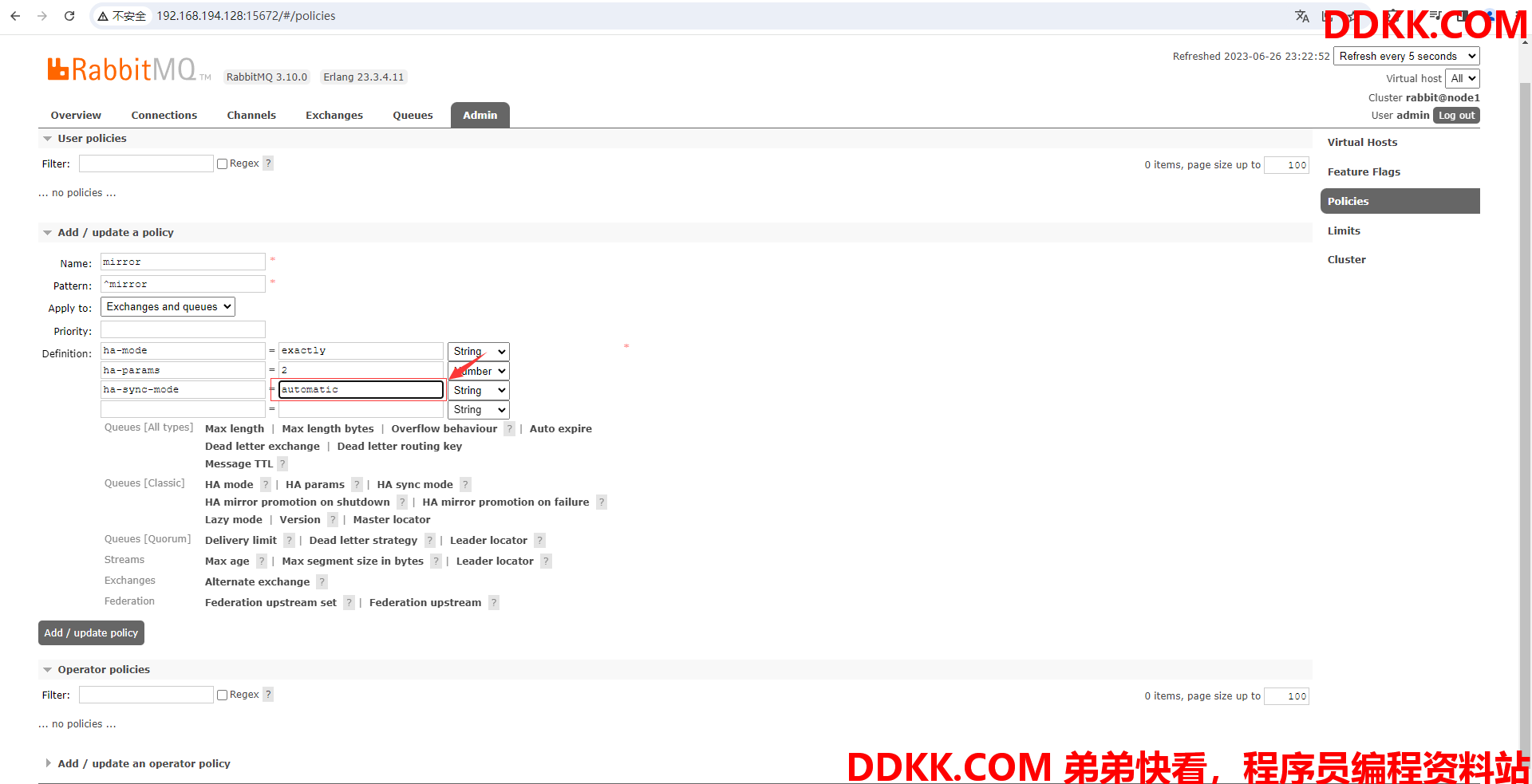
(11)最后点击Add/update policy添加策略即可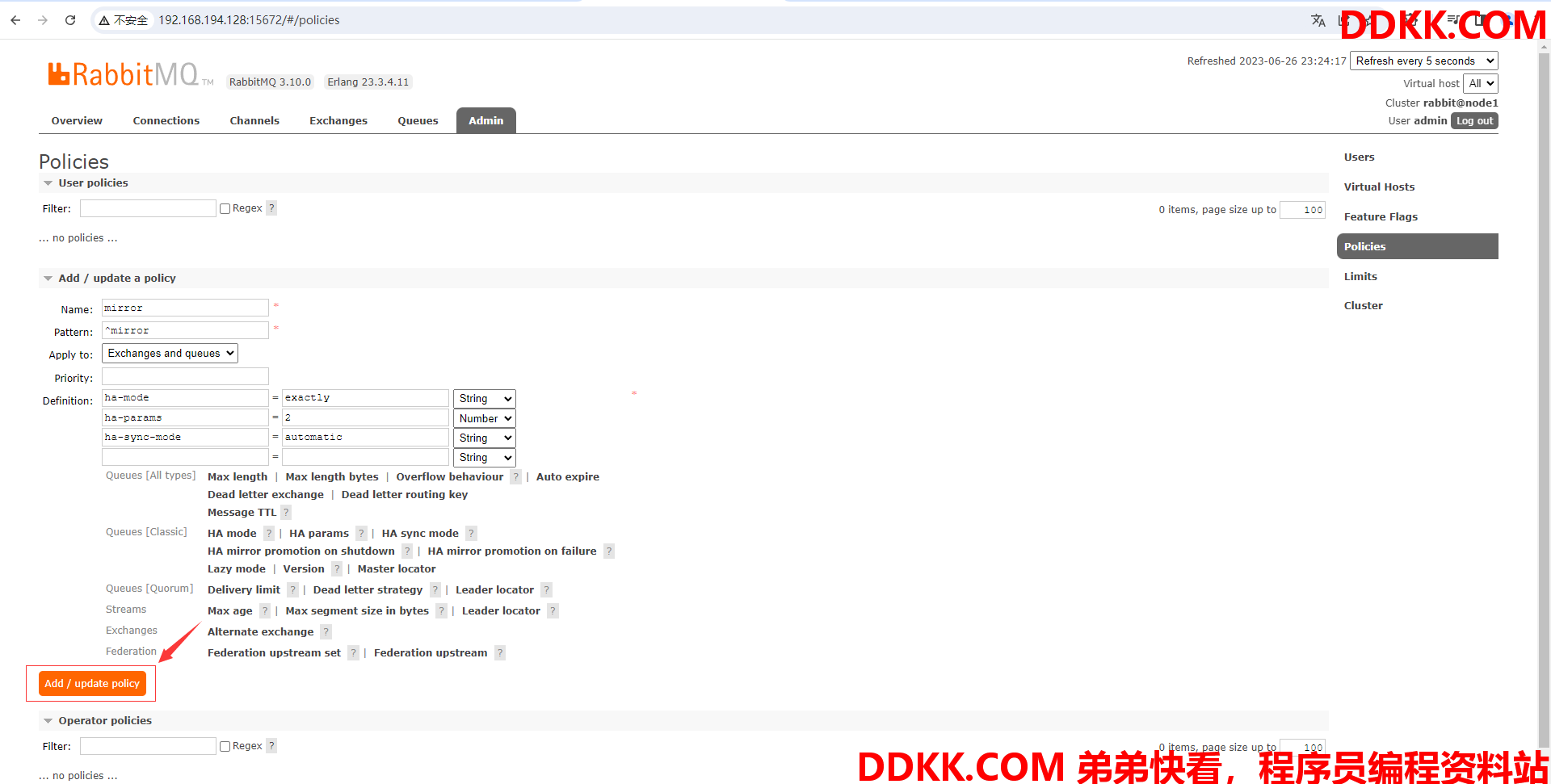
(12)往上滑动查看策略添加情况
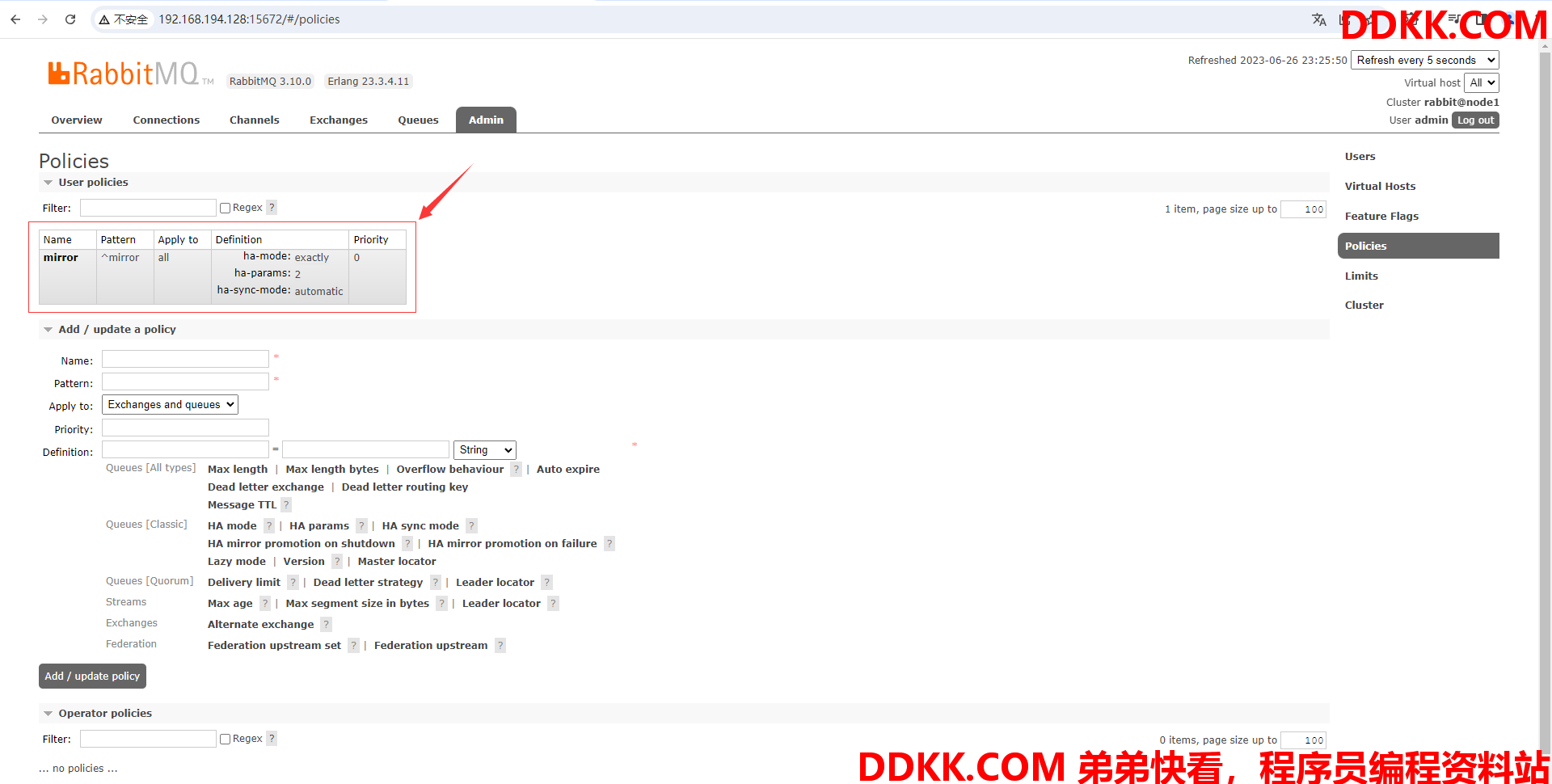
(13)执行代码在node1节点上创建名字以mirror开头的队列
代码如下
package com.ken;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.MessageProperties;
/**
* 生产者
*/
public class Producer {
//队列名称(用于指定往哪个队列发送消息)
public static final String QUEUE_NAME = "mirror_queue";
//进行发送操作
public static void main(String[] args) throws Exception{
//创建一个连接工厂
ConnectionFactory factory = new ConnectionFactory();
//设置工厂IP,用于连接RabbitMQ的队列
factory.setHost("192.168.194.128");
//设置连接RabbitMQ的用户名
factory.setUsername("admin");
//设置连接RabbitMQ的密码
factory.setPassword("123456");
//创建连接
Connection connection = factory.newConnection();
//获取信道
Channel channel = connection.createChannel();
/**
* 创建队列
* 第一个参数:队列名称
* 第二个参数:服务器重启后队列是否还存在,即队列是否持久化,true为是,false为否,默认false,即消息存储在内存中而不是硬盘中
* 第三个参数:该队列是否只供一个消费者进行消费,是否进行消息共享,true为只允许一个消费者进行消费,false为允许多个消费者对队列进行消费,默认false
* 第四个参数:是否自动删除,最后一个消费者断开连接后该队列是否自动删除,true自动删除,false不自动删除
* 第五个参数:其他参数
*/
channel.queueDeclare(QUEUE_NAME,false ,false,false,null);
//发消息
String message = "Hello World";
/**
* 用信道对消息进行发布(消息持久化)
* 第一个参数:发送到哪个交换机
* 第二个参数:路由的Key值是哪个,本次是队列名
* 第三个参数:其他参数信息
* 第四个参数:发送消息的消息体
*/
channel.basicPublish("",QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes());
System.out.println("消息发送成功!");
}
}
效果图:
(14)进入Queues查看队列的情况,可以发现刚刚创建的mirror_queue队列上有+1,这证明镜像队列创建成功
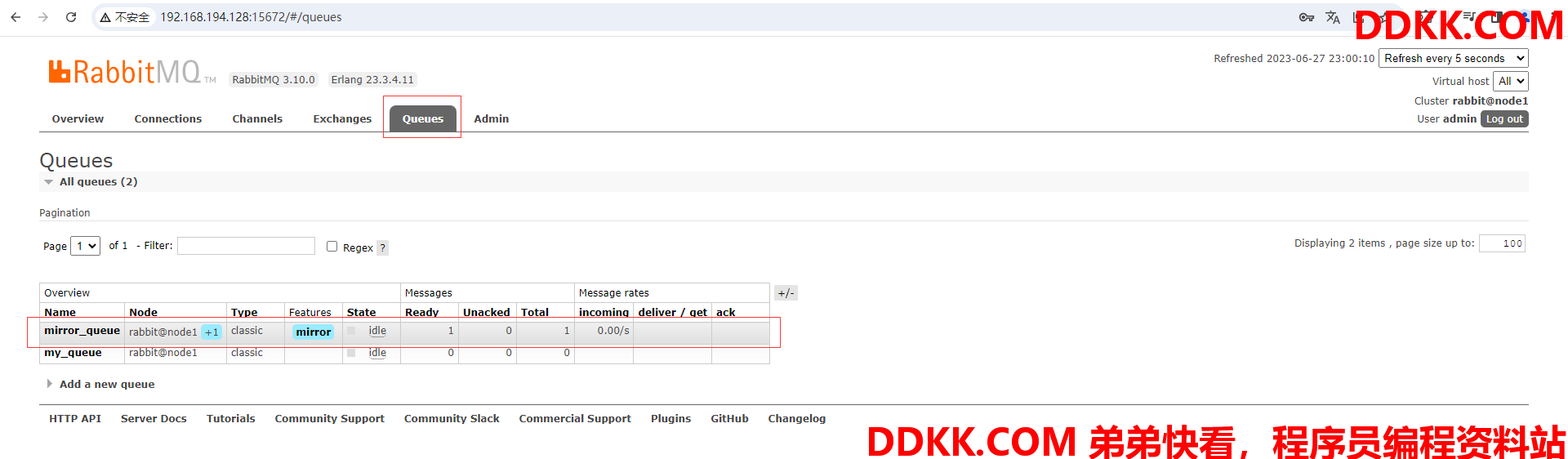
(15)进入mirror_queue队列查看详情,可以发现镜像队列在node2节点上
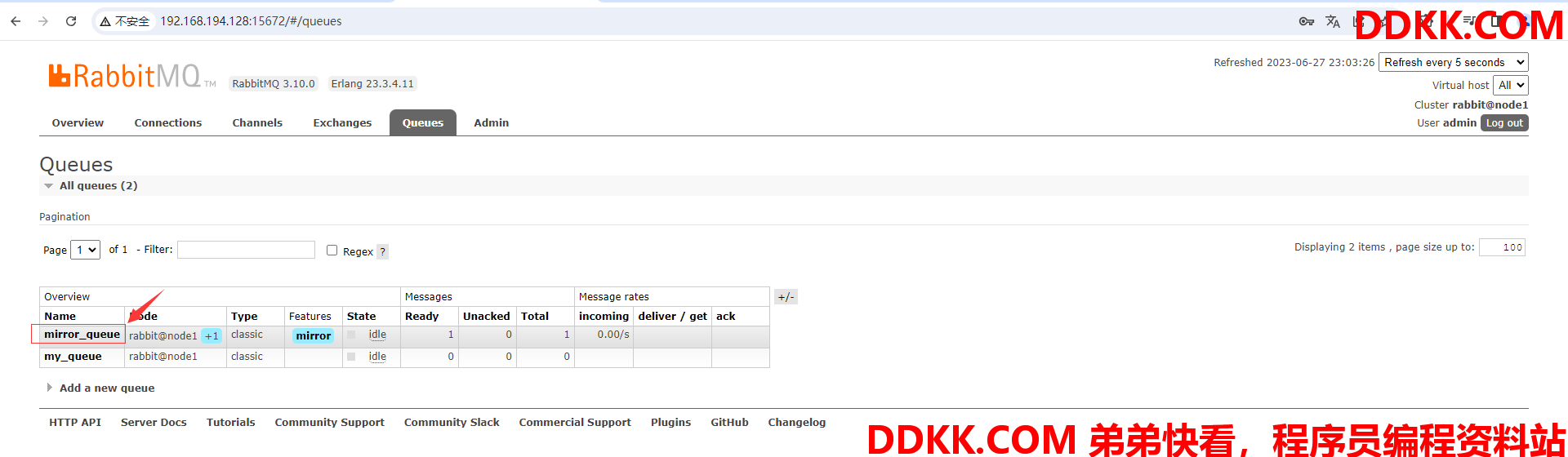
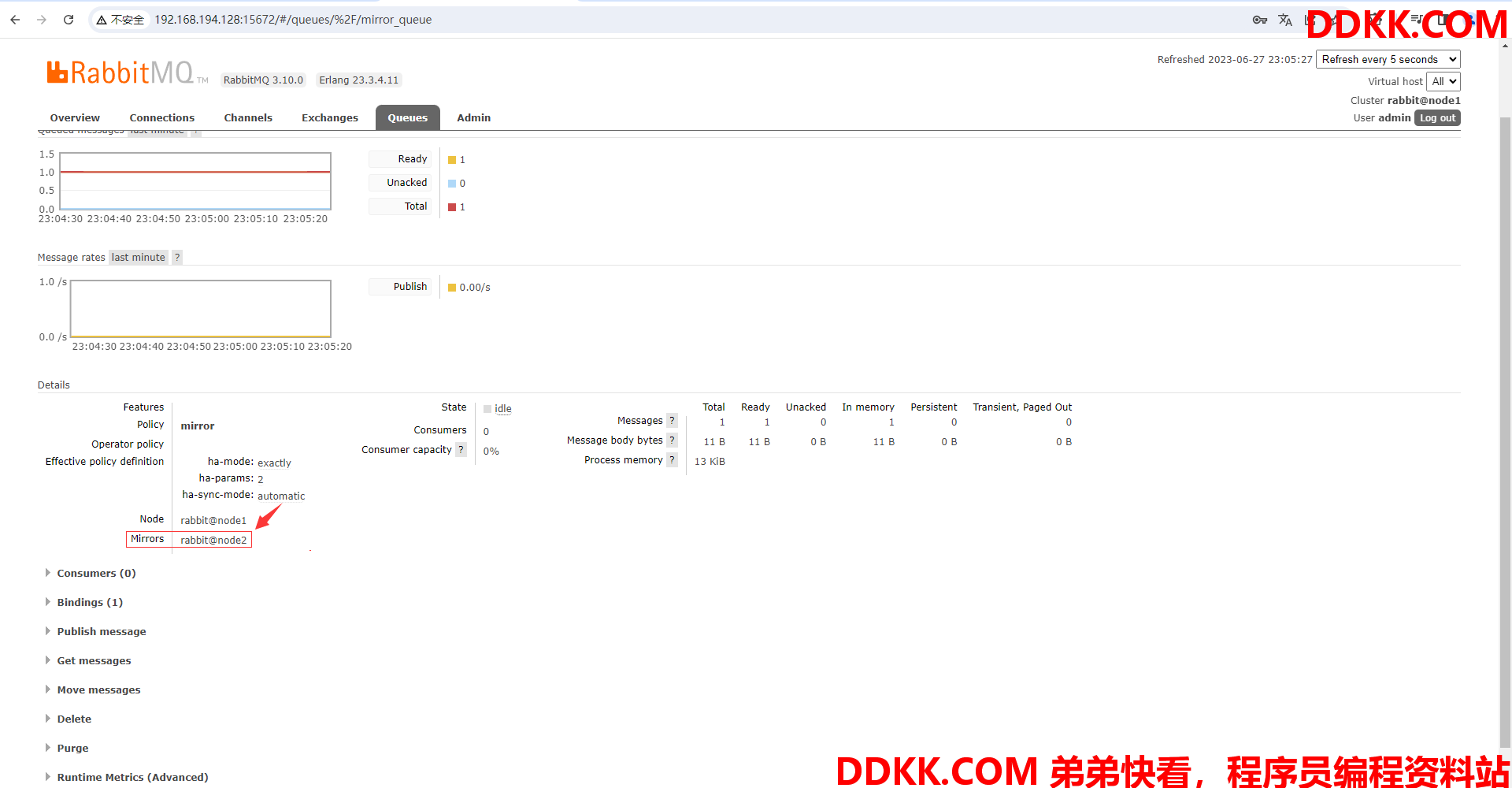
3、 测试镜像队列是否正常运行;
(1)关闭node1节点,模拟node1节点宕机
rabbitmqctl stop_app
效果图:

从node2的可视化页面可以看到node1节点停机了
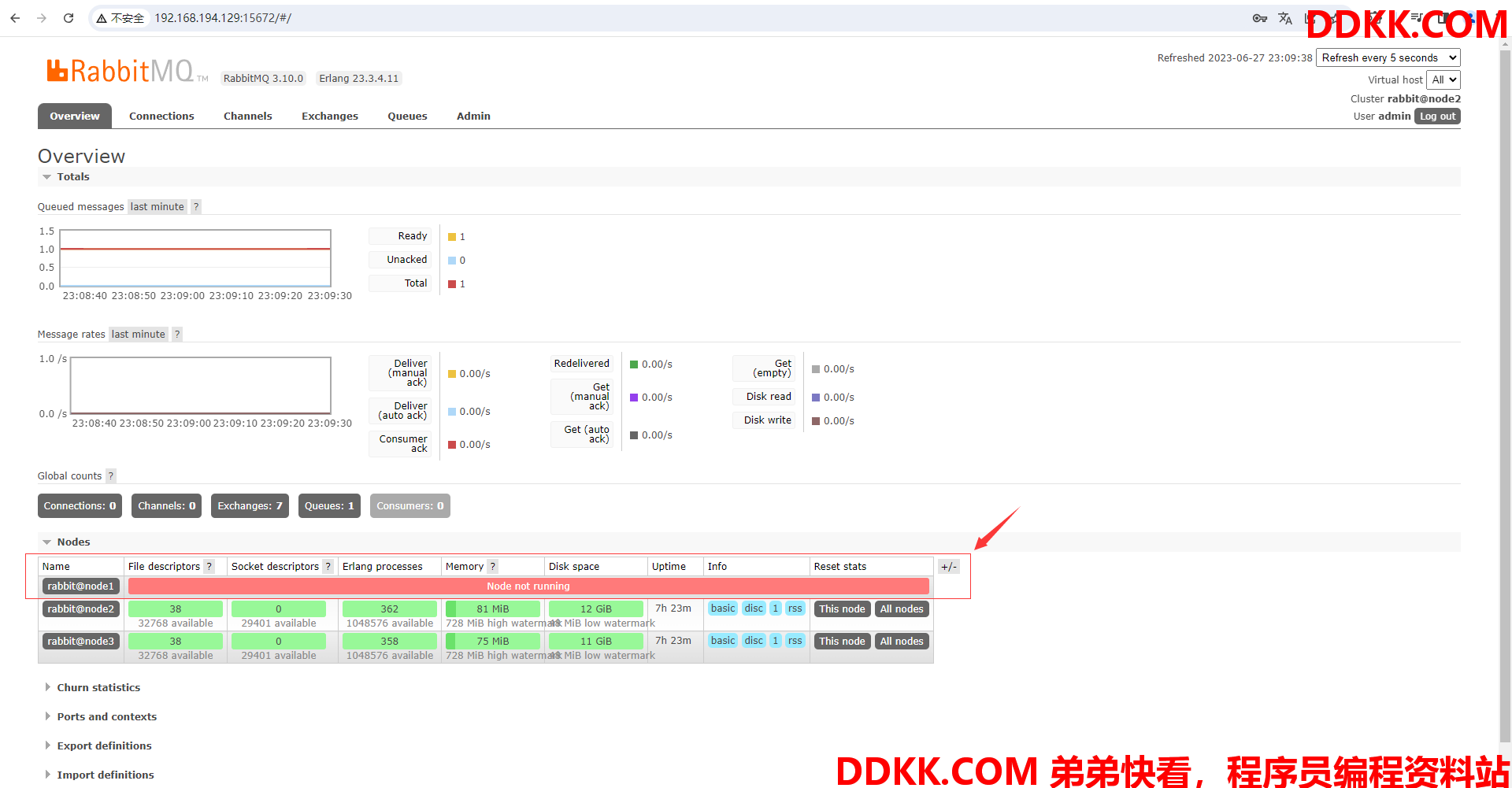
注意:
从Queues进入mirror_queue队列查看详情,可以发现当node1节点停掉后node2自动替代了node1节点的位置,node3作为镜像队列的节点,由此可见我们策略里写的ha-params:2这一参数是生效的,使得节点的个数总是保持2个,这样就算我们整个集群只剩下一台机器,在节点不断替代的情况下,消费者始终能消费队列里面的消息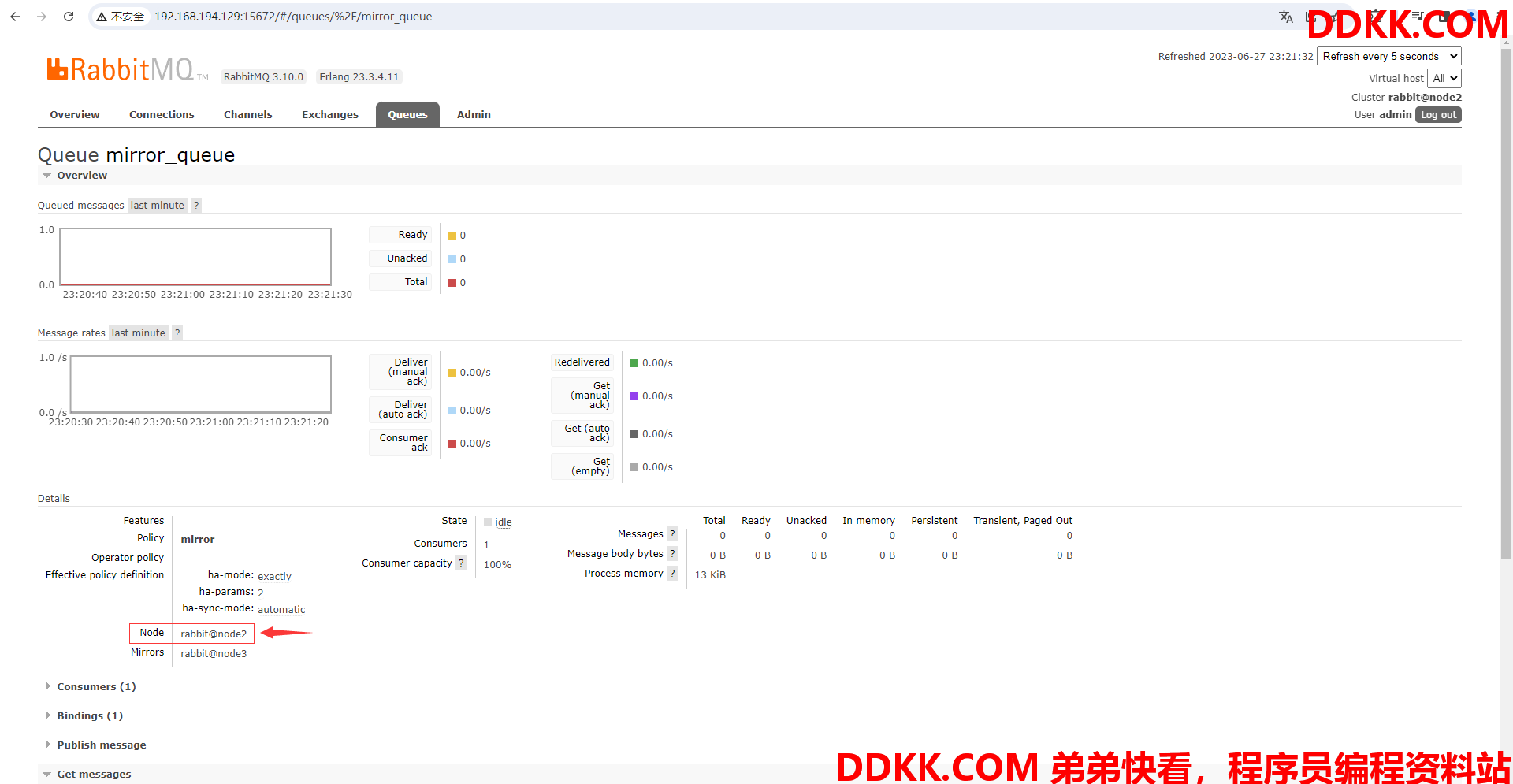
(2)执行以下代码,在node2节点里生成消费者,尝试消费mirror_queue队列的消息,发现node2可以消费mirror_queue队列的消息并且消费成功,这证明mirror_queue队列成功镜像到node2节点上
package com.ken;
import com.rabbitmq.client.*;
/**
* 消费者
*/
public class Consumer {
//队列名称(用于指定往哪个队列接收消息)
public static final String QUEUE_NAME = "mirror_queue";
//进行接收操作
public static void main(String[] args) throws Exception{
//创建一个连接工厂
ConnectionFactory factory = new ConnectionFactory();
//设置工厂IP,用于连接RabbitMQ的队列
factory.setHost("192.168.194.129");
//设置连接RabbitMQ的用户名
factory.setUsername("admin");
//设置连接RabbitMQ的密码
factory.setPassword("123456");
//创建连接
Connection connection = factory.newConnection();
//获取信道
Channel channel = connection.createChannel();
/**
* 声明消费者接收消息后的回调方法(由于回调方法DeliverCallback是函数式接口,所以需要给DeliverCallback赋值一个函数,为了方便我们这里使用Lambda表达式进行赋值)
* 为什么要这样写呢,是因为basicConsume方法里的参数deliverCallback的类型DeliverCallback用 @FunctionalInterface注解规定DeliverCallback是一个函数式接口,所以要往deliverCallback参数传的值要是一个函数
*
* 以下是DeliverCallback接口的源代码
* @FunctionalInterface
* public interface DeliverCallback {
* void handle (String consumerTag, Delivery message) throws IOException;
* }
*/
DeliverCallback deliverCallback = (consumerTag,message) -> {
System.out.println(new String(message.getBody()));
};
/**
* 声明消费者取消接收消息后的回调方法(由于回调方法CancelCallback是函数式接口,所以需要给CancelCallback赋值一个函数,为了方便我们这里使用Lambda表达式进行赋值)
* 为什么要这样写呢,是因为basicConsume方法里的参数cancelCallback的类型CancelCallback用 @FunctionalInterface注解规定CancelCallback是一个函数式接口,所以要往cancelCallback参数传的值要是一个函数
*
* @FunctionalInterface
* public interface CancelCallback {
* void handle (String consumerTag) throws IOException;
* }
*
*/
CancelCallback cancelCallback = consumerTag -> {
System.out.println("取消消费消息");
};
/**
* 用信道对消息进行接收
* 第一个参数:消费的是哪一个队列的消息
* 第二个参数:消费成功后是否要自动应答,true代表自动应当,false代表手动应答
* 第三个参数:消费者接收消息后的回调方法
* 第四个参数:消费者取消接收消息后的回调方法(正常接收不调用)
*/
channel.basicConsume(QUEUE_NAME,true,deliverCallback,cancelCallback);
}
}
效果图: