前面学习过@MappedSuperclass,可以把一些公共的属性提取到添加该注解的类里,如id,creteTime,updateTime等。该类不会生成表,该类中相应的字段都会生成在子类中。该类没有被@Entity注释,不是一个实体。
@Inheritance
JPA为我们提供了@Inheritance注解来控制实体时间有继承关系时,在数据库中如何生成对应的表。该注解需要添加在根实体上,如果没有添加@Inheritance注解,或添加了没有指定InheritanceType那么将使用SINGLE_TABLE(单表)映射策略。
下面我们通过例子来看一下三个继承策略有什么不同,如书籍(Book)下有两个子类,纸质书(PrintBook)、电子书(EBook)。
SINGLE_TABLE(单表映射策略)
不添加@Inheritance或InheritanceType.SINGLE_TABLE(默认的策略)都会使用该策略。
Book实体
/**
* 书籍实体
* @author DDKK.COM 弟弟快看,程序员编程资料站
*/
@Data
@Entity
@Builder
@Table(name = "jpa_book")
//@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@NoArgsConstructor
@AllArgsConstructor
@NamedEntityGraphs({
@NamedEntityGraph(name = "Book.fetch.category",attributeNodes = {@NamedAttributeNode("category")})
})
public class Book {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String bookName;
private LocalDate publishDate;
/**
* 书和门类是多对一的关系
*/
@JsonIgnore
@ManyToOne
@JoinColumn(name = "category_id",referencedColumnName = "id")
private Category category;
/**
* 书和作者是多对多的关系,我们让book为关联拥有放,添加@JoinTable注解。
*/
@JsonIgnore
@ManyToMany
@JoinTable(name = "jpa_book_author",
joinColumns = @JoinColumn(name="book_id", referencedColumnName="id"),
inverseJoinColumns= @JoinColumn(name="author_id", referencedColumnName="id"))
private List<Author> authors;
}
PrintBook实体
/**
* 纸质书籍
* @author DDKK.COM 弟弟快看,程序员编程资料站
*/
@Data
@Entity
@Table(name = "jpa_print_book")
public class PrintBook extends Book{
/**
* 印刷时间
*/
private LocalDate printDate;
}
EBook实体
/**
*电子书籍
* @author DDKK.COM 弟弟快看,程序员编程资料站
*/
@Data
@Entity
@Table(name = "jpa_ebook")
public class EBook extends Book{
/**
* 格式
*/
private String format;
}
测试用例1:
@Test
void testExtends1(){
Book book = new Book();
book.setBookName("书籍001");
bookRepository.save(book);
PrintBook printBook = new PrintBook();
printBook.setBookName("纸质书籍001");
printBook.setPrintDate(LocalDate.of(2019,12,20));
bookRepository.save(printBook);
EBook eBook = new EBook();
eBook.setBookName("电子书001");
eBook.setFormat("txt");
bookRepository.save(eBook);
}
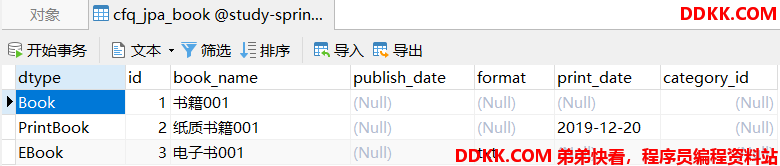
查看生成的表结构和打印的SQL语句如下:

测试用例2:
@Test
void testExtends2(){
List<Book> books = bookRepository.findAll();
books.forEach(b -> System.out.println(b.getClass().getSimpleName()));
}
运行结果:
Hibernate: select book0_.id as id2_8_, book0_.book_name as book_nam3_8_, book0_.category_id as category7_8_, book0_.publish_date as publish_4_8_, book0_.format as format5_8_, book0_.print_date as print_da6_8_, book0_.dtype as dtype1_8_ from cfq_jpa_book book0_
Book
PrintBook
EBook
为PrintBook建立单独的Repository:
/**
* @author DDKK.COM 弟弟快看,程序员编程资料站
*/
public interface PrintBookRepository extends JpaRepositoryImplementation<PrintBook,Long> {
}
测试用例3:
@Test
void testExtends3(){
List<EBook> books = eBookRepository.findAll();
books.forEach(b -> System.out.println(b.getClass().getSimpleName()));
EBook eBook = books.get(0);
eBook.setBookName("EBook001");
eBook.setFormat("pdf");
}
运行结果:
Hibernate: select ebook0_.id as id2_8_, ebook0_.book_name as book_nam3_8_, ebook0_.category_id as category7_8_, ebook0_.publish_date as publish_4_8_, ebook0_.format as format5_8_ from cfq_jpa_book ebook0_ where ebook0_.dtype='EBook'
EBook
Hibernate: update cfq_jpa_book set book_name=?, category_id=?, publish_date=?, format=? where id=?
得出结论:
1、使用SINGLE_TABLE策略时,子类不会生成对应的表,所以子类中的@Table注解多余了。而父类的表中会多出一个dtype字段,由JPA来维护,字段的值是类的简单名称,用来标识是属于哪一类的。
2、父类和子类之间差异不大,父类维护了大量的相同字段,子类只有少量字段不同,且子类字段可以为空的情况下,才能使用。
3、可以为每个子类单独创建Repository,进行持久层操作。
JOINED(关联映射策略)
特定于子类的字段被映射到一个单独的表,而不是父类的公共字段,并执行联接来实例化子类。
我们将之前生成的book表删除,并修改Book类@Inheritance的策略为InheritanceType.JOINED。
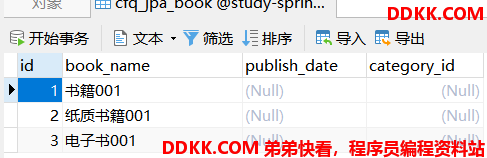
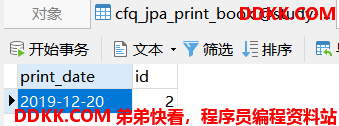
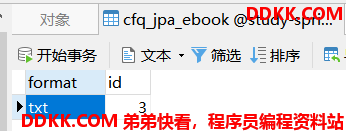
运行测试用例1生成的表结构和打印的SQL如下:


运行测试用例2,SQL打印及结果如下:
Hibernate: select book0_.id as id1_8_, book0_.book_name as book_nam2_8_, book0_.category_id as category4_8_, book0_.publish_date as publish_3_8_, book0_1_.format as format1_11_, book0_2_.print_date as print_da1_14_, case when book0_1_.id is not null then 1 when book0_2_.id is not null then 2 when book0_.id is not null then 0 end as clazz_ from cfq_jpa_book book0_ left outer join cfq_jpa_ebook book0_1_ on book0_.id=book0_1_.id left outer join cfq_jpa_print_book book0_2_ on book0_.id=book0_2_.id
EBook
PrintBook
Book
运行测试用例3,SQL打印及结果如下:
Hibernate: select ebook0_.id as id1_8_, ebook0_1_.book_name as book_nam2_8_, ebook0_1_.category_id as category4_8_, ebook0_1_.publish_date as publish_3_8_, ebook0_.format as format1_11_ from cfq_jpa_ebook ebook0_ inner join cfq_jpa_book ebook0_1_ on ebook0_.id=ebook0_1_.id
EBook
Hibernate: update cfq_jpa_book set book_name=?, category_id=?, publish_date=? where id=?
Hibernate: update cfq_jpa_ebook set format=? where id=?
得出结论:
1、会生成多张表,在父类对应的表中存放了公共的字段,在子类对应的表中,存放了子类特有的字段,还有一个指向父类id的外键。
2、在执行新增操作时,如果是子类新增,会执行两条insert语句,分别插入到父类对应的表和自己对应的表中。
3、在使用父类的Repository进行findAll查询时,父类对应的表会左外连接所有子类所对应的表进行查询,数据量大,且子类多时,发杂的SQL,会有性能问题。
4、在使用子类自己的Repository进行findAll查询时,子类对应的表会内连接类对对应的表。
TABLE_PER_CLASS(每个实体对应一个表)
我们把之前生成的book、printbook、ebook表删除,并修改Book类@Inheritance的策略为InheritanceType.TABLE_PER_CLASS。
直接运行测试用例1会报如下错误:
org.hibernate.MappingException: Cannot use identity column key generation with <union-subclass> mapping for: cn.caofanqi.study.studyspringdatajpa.pojo.domain.PrintBook
意思是使用TABLE_PER_CLASS策略时,不能使用主键自增策略。因为每一个类都会生成一张表,当使用父类的Repository进行查询时,会把这些表的数据都抓出来,然后每一个表里面都会有各自的主键,如果用自增策略的话,两张表中的主键可能会一样,比如说book表中有id为1的记录,ebook表中也有id为1的记录。这样把他们聚合到一块的时候,就会有两个id为1的book对象。所以不能使用主键自增策略。
修改Book实体如下:
/**
* 书籍实体
* @author DDKK.COM 弟弟快看,程序员编程资料站
*/
@Data
@Entity
@Builder
@Table(name = "jpa_book")
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
@NoArgsConstructor
@AllArgsConstructor
@NamedEntityGraphs({
@NamedEntityGraph(name = "Book.fetch.category",attributeNodes = {@NamedAttributeNode("category")})
})
public class Book {
@Id
@GeneratedValue(generator = "sequenceGenerator") //指定生成器
@GenericGenerator(name = "sequenceGenerator", strategy = "org.hibernate.id.enhanced.SequenceStyleGenerator",//为生成器指定策略(hibernate默认提供的)
parameters = {
@org.hibernate.annotations.Parameter(name = SequenceStyleGenerator.SEQUENCE_PARAM, value = "id_sequence"),//指定要用的序列或表的名称
@org.hibernate.annotations.Parameter(name = SequenceStyleGenerator.INITIAL_PARAM, value = "1000"),//sequence从几开始
@org.hibernate.annotations.Parameter(name = SequenceStyleGenerator.INCREMENT_PARAM, value = "1"),//增量步长
@org.hibernate.annotations.Parameter(name = SequenceStyleGenerator.OPT_PARAM, value = "pooled"),//指定优化器,用于提高性能
}
)
private Long id;
private String bookName;
private LocalDate publishDate;
/**
* 书和门类是多对一的关系
*/
@JsonIgnore
@ManyToOne
@JoinColumn(name = "category_id",referencedColumnName = "id")
private Category category;
/**
* 书和作者是多对多的关系,我们让book为关联拥有放,添加@JoinTable注解。
*/
@JsonIgnore
@ManyToMany
@JoinTable(name = "jpa_book_author",
joinColumns = @JoinColumn(name="book_id", referencedColumnName="id"),
inverseJoinColumns= @JoinColumn(name="author_id", referencedColumnName="id"))
private List<Author> authors;
}
运行测试用例1生成的表结构和打印的SQL如下:
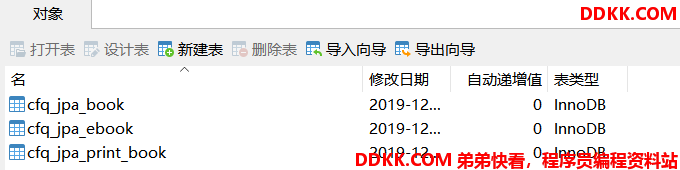
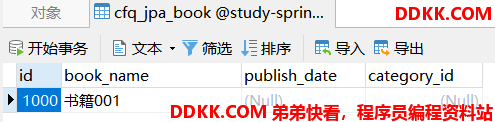
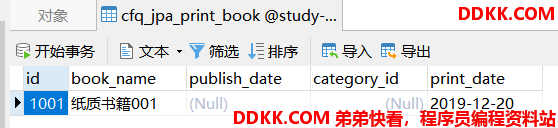
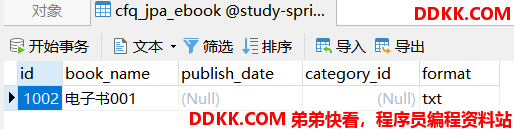
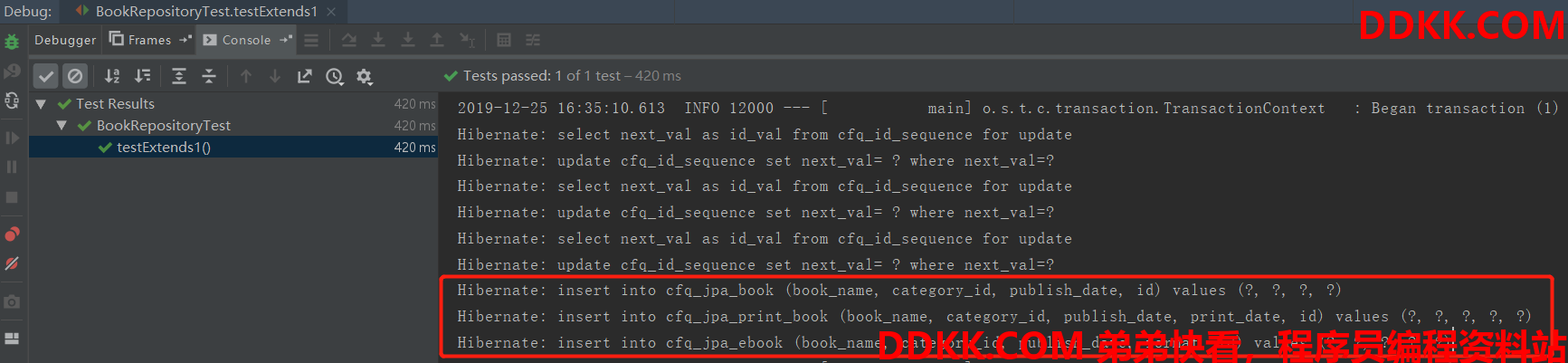
运行测试用例2,SQL打印及结果如下:
Hibernate: select book0_.id as id1_8_, book0_.book_name as book_nam2_8_, book0_.category_id as category4_8_, book0_.publish_date as publish_3_8_, book0_.format as format1_11_, book0_.print_date as print_da1_14_, book0_.clazz_ as clazz_ from ( select id, book_name, publish_date, category_id, null as format, null as print_date, 0 as clazz_ from cfq_jpa_book union all select id, book_name, publish_date, category_id, format, null as print_date, 1 as clazz_ from cfq_jpa_ebook union all select id, book_name, publish_date, category_id, null as format, print_date, 2 as clazz_ from cfq_jpa_print_book ) book0_
Book
EBook
PrintBook
运行测试用例3,SQL打印及结果如下:
Hibernate: select ebook0_.id as id1_8_, ebook0_.book_name as book_nam2_8_, ebook0_.category_id as category4_8_, ebook0_.publish_date as publish_3_8_, ebook0_.format as format1_11_ from cfq_jpa_ebook ebook0_
EBook
Hibernate: update cfq_jpa_ebook set book_name=?, category_id=?, publish_date=?, format=? where id=?
得出结论:
1、会生成多张表,父类对应的表中中有自己的字段。子类对应的表中当中除了有自己特有的字段外,也有父类所有的字段。
2、执行新增操作时,执行一次insert到自己对应的表。
3、在使用父类的Repository进行findAll查询时,会将所有的表进行UNION ALL操作。
4、在使用子类自己的Repository进行findAll查询时,单表SELECT。
5、适用于父类和子类差以比较大的时候,如果继承体系比较小时。
源码地址:https://github.com/caofanqi/study-spring-data-jpa