主要对于运行相关内容的介绍,又多了很多新的概念,还没有着手去尝试,感觉很多内容确实有用,等我把这一章结束时候,实际跑一跑代码感受一下。
运行
KieBase
KieBase是所有应用的知识定义仓库。它包含规则,过程,定义和模型类型,KieBase本身不包含数据;相反,会话是被KieBase创建的,会话可以插入数据并启动实例流程。KieBase从包含定义了KieBase的KieModule的KieContainer处获得。
示例16. 从KieContainer获取KieBase
KieBase kBase = kContainer.getKieBase();
KieSession
KieSession存储和执行运行时数据,KieSession由KieBase创建。

图示15. KieSession
示例17. 通过KieBase创建KieSession
KieSession ksession = kbase.newKieSession();
KieRuntime
KieRuntime
KieRuntime提供了既适用于规则又适用于过程的方法,就像设置全局变量和注册通道。(“出口点”是“通道”的过时同义词。)
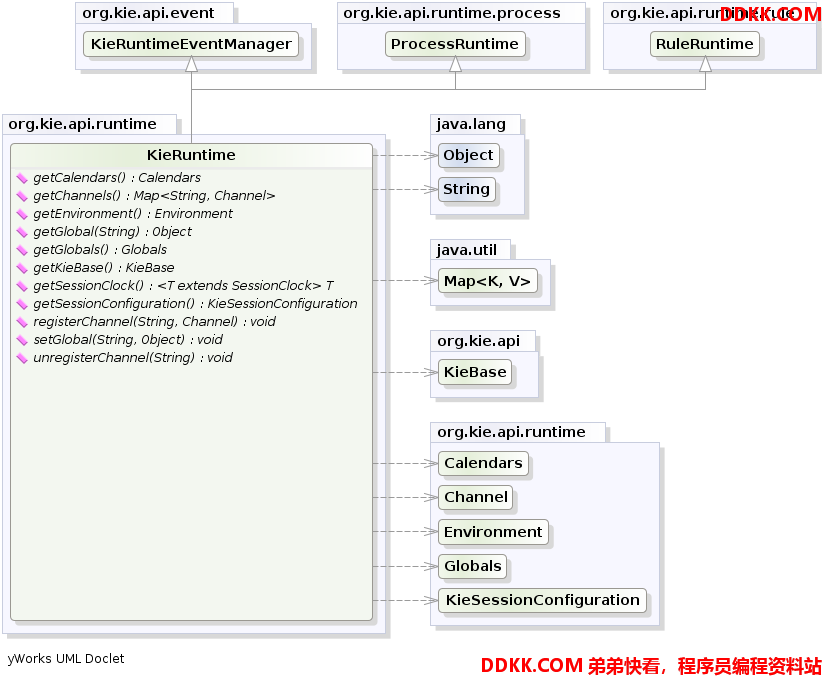
图示16. KieRuntime
全局变量#
Globals是对Drools规则引擎可视对象的命名,但是使用这种方式与fact截然不同:全局对象的更改不会触发规则的重新运行。但是,全局变量对于提供静态信息还是非常有帮助的,比如作为一个用于规则的右边提供服务的对象,或者作为Drools规则引擎的返回值。如果你在一个规则的左手边对象使用全局变量时,请确保其是不变的,或者,至少意想不到的改变不会对你的规则的行为产生任何影响。
全局变量不许在规则文件中声明,并且该全局变量需要有java对象的支持。
global java.util.List list
由于Kie base已经知道了全局变量的标识和类型,现在可以通过调用ksession.setGlobal()方法,通过传入全局变量的变量名和对象给全局变量赋值,对于任何session,都可以通过对象与全局变量关联。DRL代码中如果全局变量的类型和标识声明失败,则会导致调用时抛出异常。
List<String> list = new ArrayList<>();
ksession.setGlobal("list", list);
在运行规则之前,请确保设置了全局变量。否则会导致空指针异常。
事件模型
事件包提供了Drools规则引擎事件的通知方式,包括规则启动,对象装配等。这样就允许将日志,审核与你程序的主要部分分离。
KieRuntimeEventManager接口被KieRuntime类实现,KieRuntimeEventManager提供了两个接口,RuleRuntimeEventManager和ProcessEventManager。我们这里只介绍RuleRuntimeEventManager。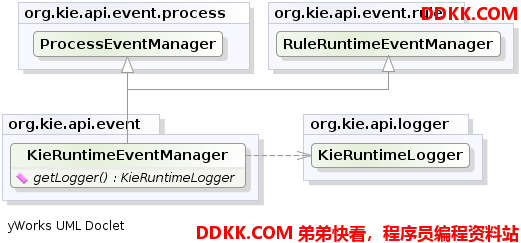
图示17. KieRuntimeEventManager
RuleRuntimeEventManager允许添加和移除监听器,以便可以监听工作内存和日程。

图示18 RuleRuntimeEventManager
下面的代码片段展示了,如何把一个简单的日程监听器声明并将其加入到session中去。当他启动后,会打印出匹配的事件。
示例18.添加一个日程监听器
ksession.addEventListener( new DefaultAgendaEventListener() {
public void afterMatchFired(AfterMatchFiredEvent event) {
super.afterMatchFired( event );
System.out.println( event );
}
});
Drools也提供了DebugRuleRuntimeEventListener 和DebugAgendaEventListener,使用调试打印语句实现了每一个方法。打印所有工作内存事件,添加一个监听器像下面这样:
示例19. 添加一个DebugRuleRuntimeEventListener
ksession.addEventListener( new DebugRuleRuntimeEventListener() );
所有发出的事件都要实现KieRuntimeEvent接口,这个接口用于检索实际的KnowkegeRuntime的事件源。
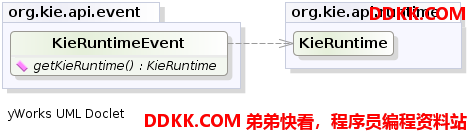
图示19. KieRuntimenEvent
当前支持的事件有:
- MatchCreatedEvent
- MatchCancelledEvent
- BeforeMatchFiredEvent
- AfterMatchFiredEvent
- AgendaGroupPushedEvent
- AgendaGroupPoppedEvent
- ObjectInsertEvent
- ObjectDeletedEvent
- ObjectUpdatedEvent
- ProcessCompletedEvent
- ProcessNodeLeftEvent
- ProcessNodeTriggeredEvent
- ProcessStartEvent
KieRuntimeLogger
KieRuntimeLogger使用了Drools中的综合事件系统创造一个审计日志,该日志可以用于记录应用的执行情况,然后可以使用类似于Eclipse的审计器对其进行查看。
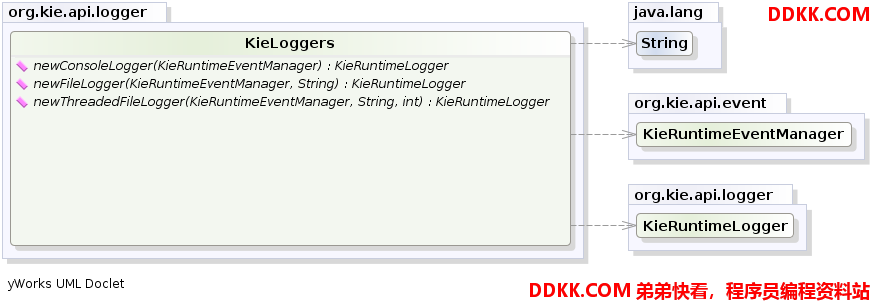
图示20.KieLoggers
示例20.FileLogger
KieRuntimeLogger logger =
KieServices.Factory.get().getLoggers().newFileLogger(ksession, "logdir/mylogfile");
...
logger.close();
命令和命令执行器
KIE有有状态会话和无状态会话的概念。已经介绍了使用标准KieRuntime的有状态会话,会随着时间推移进行迭代处理。无状态会话是对提供的数据集进行KieRuntime的一次性执行。
图示21 CommandExecutor
图示22 ExecutionResults
CommandExecutor允许命令在会话中执行,唯一不同的是无状态会话会在会话销毁结束之前,执行fireAllRules方法。命令可以使用CommandExecutor创建。java手册提供了允许使用CommandExecutor的命令的完整列表。
setGlobal和getGlobal是两条跟Drools与jBPM都有关的命令。
SetGlobal调用下面的setGlobal。可选的布尔表示是否命令应该返回作为ExecutionResults一部分的全局值。如果是true,则使用与全局名称相同的名称。如果需要替代名称,则可以使用字符串而不是布尔值。
示例21. 设置Set Global命令
StatelessKieSession ksession = kbase.newStatelessKieSession();
ExecutionResults bresults =
ksession.execute( CommandFactory.newSetGlobal( "stilton", new Cheese( "stilton" ), true);
Cheese stilton = bresults.getValue( "stilton" );
允许已存在的全局变量返回,第二个可选字符串参数是返回值的名称
示例22. Get Global命令
StatelessKieSession ksession = kbase.newStatelessKieSession();
ExecutionResults bresults =
ksession.execute( CommandFactory.getGlobal( "stilton" );
Cheese stilton = bresults.getValue( "stilton" );
前面所有的例子执行都是单条命令。BatchExecution表示一条复杂命令,有一系列的命令组成创建。执行时遍历命令列表并按顺序执行。这就意味着你可以插入对象,开启程序,调用fireAllRules并且执行查询,所有都是在execute方法中调用,相当强大。
无状态会话会在结束的时候自动执行fireAllRules()。然而目光敏锐的读者可能已经注意到fireAllRules命令,并且想知道他是如何与无状态会话一起工作的。这个FireAllRules命令允许设置不在会话结束时自动执行,可以将它看做是一个手动操作的函数。
批处理中任何设置了out标识符的命令都会将其结果添加到返回的ExecutionResults实例中。让我们看一个简单的例子去了解一下如何工作的。为了说明方便,例子中的命令包括了Drools和jBPM。例子的详细介绍在Drools和jBPM相关章节中。
StatelessKieSession ksession = kbase.newStatelessKieSession();
List cmds = new ArrayList();
cmds.add( CommandFactory.newInsertObject( new Cheese( "stilton", 1), "stilton") );
cmds.add( CommandFactory.newStartProcess( "process cheeses" ) );
cmds.add( CommandFactory.newQuery( "cheeses" ) );
ExecutionResults bresults = ksession.execute( CommandFactory.newBatchExecution( cmds ) );
Cheese stilton = ( Cheese ) bresults.getValue( "stilton" );
QueryResults qresults = ( QueryResults ) bresults.getValue( "cheeses" );
在前面的例子中,执行了多条命令,其中有两个使用了ExecutionResults。查询命令默认使用与查询名称相同的标识符。但是也可以映射到不同的标识上。
StatelessKieSession
StatelessKieSession封装了KieSession,而不是继承。他的主要关注点是决策服务的场景类型。他避免调用了dispose()方法。无状态会话不支持迭代插入和从java代码里调用fireAllRules方法;调用execute是一个单次行为,该行为会在内部实例化一个KieSession,添加所有的用户数据, 执行用户命令,调用fireAllRule方法,并且最后调用dispose方法。虽然使用StatelessKieSession类的主要方式是通过实现了CommandExecutor接口的BatchExecutor(Command的子类),但是当只是简单对象插入时,会提供两种方法使用。CommandExecutor和BatchExecution会在其各自的章节进行详细讨论。
图示23. StatelessKieSession
我们的简单示例展示了,无状态会话使用方便的API执行给定的java对象集合。会话会遍历该集合,按顺序插入每一个元素。
示例24. 使用集合执行简单的StatelessKieSession
StatelessKieSession ksession = kbase.newStatelessKieSession();
ksession.execute( collection );
如果这种情况是单条命令,应该按照下面的例子来做:
示例25. 使用插入元素命令执行简单的StatelessKieSession
如果你想要插入集合本身和集合的每一条元素,CommandFactory.newInsert(collection)会帮你完成这个工作。
CommandFactory的方法创建支持的命令,所有的命令可以使用XStream和BatchExecutionHelper进行编组。BatchExecutionHelper。BatchExecutionHelper提供了有关XML的详细信息,以及如何使用Drools Pipeline自动对BatchExecution和ExecutionResults进行编组。
StatelessKieSession支持全局变量,其作用域有很多种。我们首先介绍非命令方式,因为命令的作用域是特定的执行调用。全局变量的实现可以有三种方式。
- StatelessKieSessoin的方法getGlobal返回一个全局变量的实例,该实例提供了访问会话的全局变量。这些全局变量用于所有执行调用。对于可变全局变量要格外小心,因为执行调用可以同时在不同的线程中调用。
实例26. 会话范围的全局变量
StatelessKieSession ksession = kbase.newStatelessKieSession();
// Set a global hbnSession, that can be used for DB interactions in the rules.
ksession.setGlobal( "hbnSession", hibernateSession );
// Execute while being able to resolve the "hbnSession" identifier.
ksession.execute( collection );
- 使用委托是全局量的另一种解决方式。给全局变量赋值(使用setGlobal(String,Object)方法)会导致全局变量被保存在内部集合中,将标识符映射到值。在内部集合中的标识符会比其他委托的全局变量拥有优先级。只有当内部集合没有该标识符的时候,委托全局变量(如果有的话)才会被使用。
- 第三种方式是拥有一个执行范围的全局变量。一个被设置了全局变量的命令传递给CommandExecutor。
CommandExecutor接口通过输出参数,也提供了到处数据的能力。插入的事实,全局变量,查询结果全部都可以被返回。
示例27. 输出标识符
// Set up a list of commands
List cmds = new ArrayList();
cmds.add( CommandFactory.newSetGlobal( "list1", new ArrayList(), true ) );
cmds.add( CommandFactory.newInsert( new Person( "jon", 102 ), "person" ) );
cmds.add( CommandFactory.newQuery( "Get People", "getPeople" ) );
// Execute the list
ExecutionResults results =
ksession.execute( CommandFactory.newBatchExecution( cmds ) );
// Retrieve the ArrayList
results.getValue( "list1" );
// Retrieve the inserted Person fact
results.getValue( "person" );
// Retrieve the query as a QueryResults instance.
results.getValue( "Get People" );
编组
KieMarshallers用于编组和解组KieSession。
图示24. KieMarshallers
KieMarshallers的实例可以通KieService中检索。最简单的方式如下:
示例28. 简单的Marshall例子
// ksession is the KieSession// kbase is the KieBase
ByteArrayOutputStream baos = new ByteArrayOutputStream();
Marshaller marshaller = KieServices.Factory.get().getMarshallers().newMarshaller( kbase );
marshaller.marshall( baos, ksession );
baos.close();
但是,使用marshalling,当处理用户数据时,你需要更灵活。使用ObjectMarshallingStrategy接口来到达这个灵活的目的。包里提供了两种实现方式,但是用户也可以自己去实现。两种提供的方式是IdentityMarshallingStrategy和SerializeMarshallingStrategy。SerializeMarshallingStrategy是默认的,就像上面例子展示的那样,在用户实例上调用Serializable或者Externalizable方法。
IdentityMarshallingStrategy为每一个用户对象建立了一个整数id,并保存在一个Map里,同时将id写入流中。当解组时,这个id用来访问IdentityMarshallingStrategy的map,检索实例。这就意味着,如果你使用IdentityMarshallingStrategy,编组实例的生命周期是有状态的,并且创建id,为所有尝试编组的对象保留引用。下面就是使用标识编组策略的代码。
示例29. IdentityMarshallingStrategy
ByteArrayOutputStream baos = new ByteArrayOutputStream();
KieMarshallers kMarshallers = KieServices.Factory.get().getMarshallers()
ObjectMarshallingStrategy oms = kMarshallers.newIdentityMarshallingStrategy()
Marshaller marshaller =
kMarshallers.newMarshaller( kbase, new ObjectMarshallingStrategy[]{ oms } );
marshaller.marshall( baos, ksession );
baos.close();
在大部分情况下,单条策略是不够的,为了添加灵活,可以使用ObjectMarshallingStrategyAcceptor 接口。编组有一个策略链,当读或写一个用户对象时,这个策略链会遍历策略,询问是否他们接受对用户对象编组的责任。提供的实现之一是ClassFilterAcceptor。这个类允许使用字符串和通配符来匹配类名。默认是“.”所以在前一个例子的标识符编组策略用的就是默认的“.”。
假设我们要序列化除了给定外的所有类,我们可以通过标识查找,操作如下所示:
示例30. 带接收者的IdentityMarshallingStrategy
ByteArrayOutputStream baos = new ByteArrayOutputStream();
KieMarshallers kMarshallers = KieServices.Factory.get().getMarshallers()
ObjectMarshallingStrategyAcceptor identityAcceptor =
kMarshallers.newClassFilterAcceptor( new String[] { "org.domain.pkg1.*" } );
ObjectMarshallingStrategy identityStrategy =
kMarshallers.newIdentityMarshallingStrategy( identityAcceptor );
ObjectMarshallingStrategy sms = kMarshallers.newSerializeMarshallingStrategy();
Marshaller marshaller =
kMarshallers.newMarshaller( kbase,
new ObjectMarshallingStrategy[]{ identityStrategy, sms } );
marshaller.marshall( baos, ksession );
baos.close();
注意,接收检查的顺序就是提供元素时的自然顺序。
持久化和事物
使用Drools可以使用JPA实现开箱即用的长期持久化。需要安装JTA的一些实现。用于开发目的时,可以使用Bitronix的事务管理器,因为它的设置和嵌入式工作很简单,但是对于生产使用来说,推荐使用JBoss Transactions。
示例31. 使用事务的简单例子
KieServices kieServices = KieServices.Factory.get();
Environment env = kieServices.newEnvironment();
env.set( EnvironmentName.ENTITY_MANAGER_FACTORY,
Persistence.createEntityManagerFactory( "emf-name" ) );
env.set( EnvironmentName.TRANSACTION_MANAGER,
TransactionManagerServices.getTransactionManager() );
// KieSessionConfiguration may be null, and a default will be used
KieSession ksession =
kieServices.getStoreServices().newKieSession( kbase, null, env );
int sessionId = ksession.getId();
UserTransaction ut =
(UserTransaction) new InitialContext().lookup( "java:comp/UserTransaction" );
ut.begin();
ksession.insert( data1 );
ksession.insert( data2 );
ksession.startProcess( "process1" );
ut.commit();
使用JPA,必须使用EntityManagerFactory和TransactionManager设置环境。如果发生回滚,ksession的状态也需要回滚,所以ksession才能在回滚之后继续使用。为了加载一个之前持久化了的KieSession,你需要那个KieSession的id, 像下面展示的那样:
示例32.加载KieSession
KieSession ksession =
kieServices.getStoreServices().loadKieSession( sessionId, kbase, null, env );
为了能够启用多个类的持久化需要添加一个persistence.xml,像下面例子这样:
示例33. 配置 JPA
<persistence-unit name="org.drools.persistence.jpa" transaction-type="JTA"><provider>org.hibernate.ejb.HibernatePersistence</provider><jta-data-source>jdbc/BitronixJTADataSource</jta-data-source><class>org.drools.persistence.info.SessionInfo</class><class>org.drools.persistence.info.WorkItemInfo</class><properties><property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/><property name="hibernate.max_fetch_depth" value="3"/><property name="hibernate.hbm2ddl.auto" value="update" /><property name="hibernate.show_sql" value="true" /><property name="hibernate.transaction.manager_lookup_class"value="org.hibernate.transaction.BTMTransactionManagerLookup" /></properties></persistence-unit>
首先jdbc JTA数据源必须配置,Bitronix提供了很多种配置方式,请查询其文档了解详情。为了快速开始,这里有一个程序化的方法:
示例34. 配置 JTA 数据源
PoolingDataSource fs = new PoolingDataSource();
fs.setUniqueName( "jdbc/BitronixJTADataSource" );
fs.setClassName( "org.h2.jdbcx.JdbcDataSource" );
fs.setMaxPoolSize( 3 );
fs.setAllowLocalTransactions( true );
fs.getDriverProperties().put( "user", "sa" );
fs.getDriverProperties().put( "password", "sasa" );
fs.getDriverProperties().put( "URL", "jdbc:h2:mem:mydb" );
fs.init();
Bitronix也提供了简单的JNDI嵌入服务,非常适合测试。使用该服务,需要添加一个jndi配置文件到META-INF文件夹中,并且在配置文件中添加下面这一行:
示例35. JNDI配置文件
java.naming.factory.initial=bitronix.tm.jndi.BitronixInitialContextFactory