1、分页搜索
语法
#搜索第1000页的10条数据
GET /test_index/test_type/_search?from=10000&size=10
2、什么是deep paging?
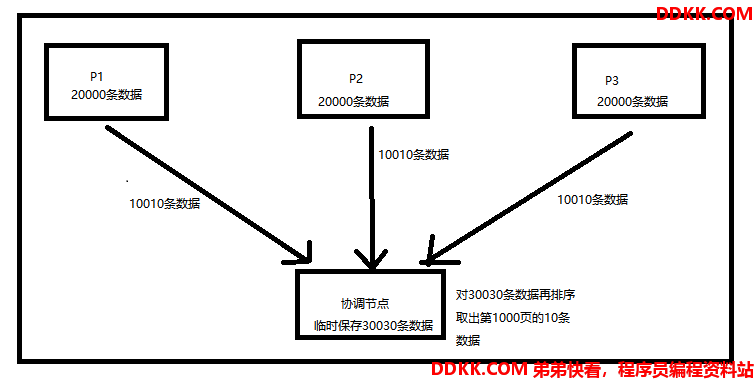
简单来说,就是分页搜索的特别深。比如有个index有3个primary shard,共60000条数据,每个shard上分了20000条数据。现在要进行分页查询取第1000页的10条数据。整个过程是这样的
(1)分页查询请求打到协调节点,协调节点将搜索请求转发到index的3个shard所在的node上去
(2)取出每个node上的第1~10010条数据返回给协调节点,协调节点一共拿到30030条数据
(3)协调节点对这30030条数据进行排序,根据_score(相关度分数)取到排名最前的10条数据,就是我们要的最终的的第1000页的10条数据
3、deep paging性能问题
从上图可以看到,搜索的过深的时候,就需要在协调节点上保存大量的数据,还要进行大量数据的排序,排序之后,再取出对应的那一页。所以这个过程,即耗费网络带宽,耗费内存,还耗费cpu。所以deep paging会出现性能问题。我们应该尽量避免出现这种deep paging操作。