下面是solr7的官网API介绍:
网页翻译的不是很准确,只能了解个大概,基本能获取如下信息:
1、构建和运行SolrJ应用程序
对于用Maven构建的项目, pom.xml配置:
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>7.1.0</version>
</dependency>
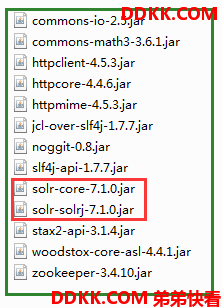
如果不用maven构建项目,只需要将solr-solrj-7.1.0.jar 和 在dist/solrj-lib目录中的依赖包放入到工程中。
2、solr7 API
在solr5系之后跟solr4最大的区别是被发布成了一个独立的应用。而不再需要tomcat等容器。在其内部集成了jetty服务器,他可以通过bin目录的脚本直接运行启动。solr5有两种运行模式,独立模式和云模式,独立模式是以core来管理,云模式是以collection来管理。
SolrClient是一个抽象类,下边有很多被实现的子类,HttpSolrClient是通用客户端。 可以与一个Solr节点直接通信。),
LBHttpSolrClient,CloudSolrClient,ConcurrentUpdateSolrClient
HttpSolrClient的创建需要用户指定一个或多个Solr基础URL,然后客户端使用Solr发送HTTP请求。
1、 一个URL的路径指向一个特定的核心或集合(例如,http://hostname:8983/solr/core1)当核心或集合中指定基础的URL,后续请求由客户机不需要测量影响集合然而,客户端是有限的核心/集合、发送请求,不能发送请求到任何其他实例;
2、 一个URL指向根Solr路径(例如,http://hostname:8983/solr)当没有指定核心或集合的基URL,可以请求任何核心/收集,但受影响的核心/必须指定集合的所有请求;
一般来说,如果你的 SolrClient只会被用在一个核心/收集,包括实体的路径是最方便的。 需要更多的灵活性,收集/核心应该被排除在外。
1、solrJ客户端实例创建并设置连接超时时间:
final String solrUrl = "http://127.0.0.1:8080/solr";
//创建solrClient同时指定超时时间,不指定走默认配置
HttpSolrClient build = new HttpSolrClient.Builder(solrUrl)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build();
不同solr版本solrj 的创建方式有所不同
//solr4创建方式
//SolrServer solrServer = new HttpSolrServer("http://127.0.0.1:8080/solr"); //solr5创建方式,在url中指定core名称:core1 //HttpSolrClient solrServer=new HttpSolrClient("http://127.0.0.1:8080/solr/core1"); //solr7创建方式,在url中指定core名称:core1 HttpSolrClient solrServer= new HttpSolrClient.Builder("http://127.0.0.1:8080/solr/core1").build();
注意:solr5以后URL指向自定义核心的名称,如实例名称是core1,那么URL为http://127.0.0.1:8080/solr/core1
2、solrJ之查询
SolrClient有很多quary() 查询方法用于从solr中获取结果,这些方法都需要一个SolrParams 类型的参数,该对象可以封装任意的查询参数。和每个方法输出 QueryResponse 一个包装器,可以用来访问结果文档和其他相关的元数据。
/**
* 查询
* @throws Exception
*/
@Test
public void querySolr() throws Exception{
//[1]获取连接
// HttpSolrClient client= new HttpSolrClient.Builder("http://127.0.0.1:8080/solr/core1").build();
String solrUrl = "http://127.0.0.1:8080/solr/core1";
//创建solrClient同时指定超时时间,不指定走默认配置
HttpSolrClient client = new HttpSolrClient.Builder(solrUrl)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build();
//[2]封装查询参数
Map<String, String> queryParamMap = new HashMap<String, String>();
queryParamMap.put("q", "*:*");
//[3]添加到SolrParams对象
MapSolrParams queryParams = new MapSolrParams(queryParamMap);
//[4]执行查询返回QueryResponse
QueryResponse response = client.query(queryParams);
//[5]获取doc文档
SolrDocumentList documents = response.getResults();
//[6]内容遍历
for(SolrDocument doc : documents) {
System.out.println("id:"+doc.get("id")
+"\tproduct_name:"+doc.get("product_name")
+"\tproduct_catalog_name:"+doc.get("product_catalog_name")
+"\tproduct_number:"+doc.get("product_number")
+"\tproduct_price:"+doc.get("product_price")
+"\tproduct_picture:"+doc.get("product_picture"));
}
client.close();
}
SolrParams有一个 SolrQuery子类,它提供了一些方法极大地简化了查询操作。下面是SolrQuery示例代码:
/**
* 2、使用 SolrParams 的子类 SolrQuery,它提供了一些方便的方法,极大地简化了查询操作。
* @throws Exception
*/
@Test
public void querySolr2() throws Exception{
//[1]获取连接
// HttpSolrClient client= new HttpSolrClient.Builder("http://127.0.0.1:8080/solr/core1").build();
String solrUrl = "http://127.0.0.1:8080/solr/core1";
//创建solrClient同时指定超时时间,不指定走默认配置
HttpSolrClient client = new HttpSolrClient.Builder(solrUrl)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build();
//[2]封装查询参数
SolrQuery query = new SolrQuery("*:*");
//[3]添加需要回显得内容
query.addField("id");
query.addField("product_name");
query.setRows(20);//设置每页显示多少条
//[4]执行查询返回QueryResponse
QueryResponse response = client.query(query);
//[5]获取doc文档
SolrDocumentList documents = response.getResults();
//[6]内容遍历
for(SolrDocument doc : documents) {
System.out.println("id:"+doc.get("id")
+"\tproduct_name:"+doc.get("product_name")
+"\tname:"+doc.get("name")
+"\tproduct_catalog_name:"+doc.get("product_catalog_name")
+"\tproduct_number:"+doc.get("product_number")
+"\tproduct_price:"+doc.get("product_price")
+"\tproduct_picture:"+doc.get("product_picture"));
}
client.close();
}
3、用solrJ创建索引
添加索引使用SolrClient的add()方法
/**
* 添加
* @throws SolrServerException
* @throws IOException
*/
@Test
public void solrAdd() throws Exception{
//[1]获取连接
// HttpSolrClient client= new HttpSolrClient.Builder("http://127.0.0.1:8080/solr/core1").build();
String solrUrl = "http://127.0.0.1:8080/solr/core1";
//创建solrClient同时指定超时时间,不指定走默认配置
HttpSolrClient client = new HttpSolrClient.Builder(solrUrl)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build();
//[2]创建文档doc
SolrInputDocument doc = new SolrInputDocument();
//[3]添加内容
String str = UUID.randomUUID().toString();
System.out.println(str);
doc.addField("id", str);
doc.addField("name", "Amazon Kindle Paperwhite");
//[4]添加到client
UpdateResponse updateResponse = client.add(doc);
System.out.println(updateResponse.getElapsedTime());
//[5] 索引文档必须commit
client.commit();
}
在正常情况下,文档应该在更大的批次,索引,而不是一次一个的进行索引。 它也建议使用Solra Solr管理员提交文档时设置为autocommit自动提交,而不是使用显式的 commit()调用。
4、solrJ之单个id 的删除索引
/**
* 4、单个id 的删除索引
*/
@Test
public void solrDelete() throws Exception{
//[1]获取连接
HttpSolrClient client = Constant.getSolrClient();
//[2]通过id删除
client.deleteById("30000");
//[3]提交
client.commit();
//[4]关闭资源
client.close();
}
5、solrJ之多个id 的list集合 删除索引
/**
* 5、多个id 的list集合 删除索引
*/
@Test
public void solrDeleteList() throws Exception{
//[1]获取连接
HttpSolrClient client = Constant.getSolrClient();
//[2]通过id删除
ArrayList<String> ids = new ArrayList<String>();
ids.add("30000");
ids.add("1");
client.deleteById(ids);
//[3]提交
client.commit();
//[4]关闭资源
client.close();
}
6、Java对象绑定
SolrJ提供两个有用的接口,UpdateResponse和 QueryResponse,它们可以很方便的处理特定域的对象,可以使您的应用程序更容易被理解。SolrJ支持通过@Field注解隐式转换文档与任何类。每个实例变量在Java对象可以映射到一个相应的Solr字段中,使用 field注解。
先查看一下配置:
solrconfig.xml配置
<requestHandler name="/dataimport" class="solr.DataImportHandler"> <lst name="defaults"> <!--数据源配置文件所在路径--> <str name="config">./data-config.xml</str> </lst> </requestHandler>
data-config.xml配置
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/solrdata"
user="root"
password="root"/>
<document>
<entity name="product" query="select pid,name,catalog,catalog_name,price,number,description,picture from products">
<field column="pid" name="id"/>
<field column="name" name="p_name"/>
<field column="catalog_name" name="p_catalog_name"/>
<field column="price" name="p_price"/>
<field column="number" name="p_number"/>
<field column="description" name="p_description"/>
<field column="picture" name="p_picture"/>
</entity>
</document>
</dataConfig>
managed-schema文件配置
<!--配置ik分词器-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<!--配置ik分词器-->
<field name="name_ik" type="text_ik" indexed="true" stored="true"/>
<!--项目中的字段-->
<field name="p_name" type="text_ik" indexed="true" stored="true"/>
<field name="p_catalog_name" type="string" indexed="true" stored="true"/>
<field name="p_price" type="pfloat" indexed="true" stored="true"/>
<field name="p_number" type="plong" indexed="true" stored="true"/>
<field name="p_description" type="text_ik" indexed="true" stored="true"/>
<field name="p_picture" type="string" indexed="false" stored="true"/>
<!--关键词 定义复制域字段,将商品名称和商品描述都复制到 product_keywords这一个字段上-->
<field name="p_keywords" type="text_ik" indexed="true" stored="false" multiValued="true" />
<copyField source="p_name" dest="p_keywords" />
<copyField source="p_description" dest="p_keywords" />
其中indexed="true" 表示开启索引(当字段不需要被检索时,最好不要开启索引,) stored="true"表示存储原来数据(当字段不被检索,而只是需要通过其他字段检索而获得时,要设为true) multiValued="true" 表示返回多值,如一个返回多个content,此时要在java代码中把 content设置 集合或数组类型如
private String[] content;//多值,对应 multiValued="true"
注意:solr4版本的field的type属性的基本数据类型到solr7的变化
详细内容参照solr-7.1.0\example\example-DIH\solr\db\conf\目录下的managed-schema
| string | string |
| boolean | boolean |
| int | pint |
| double | pdouble |
| long | plong |
| float | pfloat |
| date | pdate |
首先需要创建对象Product,字段必须与schema.xml或managed-schema配置文件的field的一致,该配置文件中必需有这个field,不然会报错。
①字段写错:查询时不报错,查不出来想要的数据,添加时创建的索引字段也不是自己想要的field。
②字段type类型不一致:Caused by: java.long.IllegalArgementException:Can not set java.lang.Integer field junit.Product.id to java.long.String
| solr的fieldtype属性 | javaBean 属性类型 |
| string | String |
| boolean | Boolean |
| pint | Integer |
| pdouble | Double |
| plong | Long |
| pfloat | Float |
| pdate | Date |
product实体对象:
package junit;
import org.apache.solr.client.solrj.beans.Field;
public class Product {
/** * 商品编号 */ @Field private String id; /** * 商品名称 */ @Field private String p_name; /** * 商品分类名称 */ @Field private String p_catalog_name; /** * 价格 */ @Field private Float p_price; /** * 数量 */ @Field private Long p_number; /** * 图片名称 */ @Field private String p_picture; /** * 商品描述 */ @Field private String p_description; public String getId() { return id; } public void setId(String id) { this.id = id; } public String getP_name() { return p_name; } public void setP_name(String p_name) { this.p_name = p_name; } public String getP_catalog_name() { return p_catalog_name; } public void setP_catalog_name(String p_catalog_name) { this.p_catalog_name = p_catalog_name; } public Float getP_price() { return p_price; } public void setP_price(Float p_price) { this.p_price = p_price; } public Long getP_number() { return p_number; } public void setP_number(Long p_number) { this.p_number = p_number; } public String getP_picture() { return p_picture; } public void setP_picture(String p_picture) { this.p_picture = p_picture; } public String getP_description() { return p_description; } public void setP_description(String p_description) { this.p_description = p_description; } //空参数构造 public Product() {} //满参数构造 public Product(String id, String p_name, String p_catalog_name, Float p_price, Long p_number, String p_picture, String p_description) { super(); this.id = id; this.p_name = p_name; this.p_catalog_name = p_catalog_name; this.p_price = p_price; this.p_number = p_number; this.p_picture = p_picture; this.p_description = p_description; } }
4.1、在应用中使用:
(1)Java对象绑定,通过对象创建索引
/**
* 6、Java对象绑定,通过对象创建索引
*/
@Test
public void addBean() throws Exception{
//[1]获取连接
// HttpSolrClient client= new HttpSolrClient.Builder("http://127.0.0.1:8080/solr/core1").build();
String solrUrl = "http://127.0.0.1:8080/solr/core1";
//创建solrClient同时指定超时时间,不指定走默认配置
HttpSolrClient client = new HttpSolrClient.Builder(solrUrl)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build();
//[3]创建对象
Product product = new Product();
product.setId("30000");
product.setP_name("测试商品名称");
product.setP_catalog_name("测试商品分类名称");
product.setP_price(399F);
product.setP_number(30000L);
product.setP_description("测试商品描述");
product.setP_picture("测试商品图片.jpg");
//[4]添加对象
UpdateResponse response = client.addBean(product);
//[5]提交操作
client.commit();
//[6]关闭资源
client.close();
}
查看添加的内容如下:
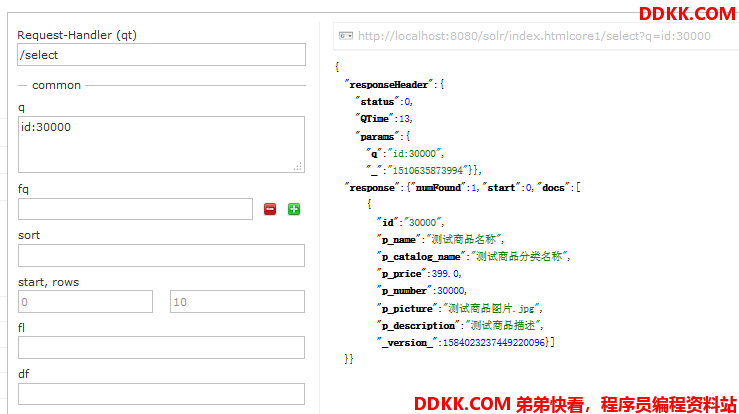
(2)Java对象绑定,通过对象索引查询
搜索时可以通过QueryResponse的getbean()方法将结果直接转换成bean对象:``
/**
* 7、Java对象绑定,通过对象查询索引
*/
@Test
public void queryBean() throws Exception{
//[1]获取连接
// HttpSolrClient client= new HttpSolrClient.Builder("http://127.0.0.1:8080/solr/core1").build();
String solrUrl = "http://127.0.0.1:8080/solr/core1";
//创建solrClient同时指定超时时间,不指定走默认配置
HttpSolrClient client = new HttpSolrClient.Builder(solrUrl)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build();
//[2]创建SolrQuery对象
SolrQuery query = new SolrQuery("*:*");
//添加回显的内容
query.addField("id");
query.addField("p_name");
query.addField("p_price");
query.addField("p_catalog_name");
query.addField("p_number");
query.addField("p_picture");
query.setRows(200);//设置每页显示多少条
//[3]执行查询返回QueryResponse
QueryResponse response = client.query(query);
//[4]获取doc文档
List<Product> products = response.getBeans(Product.class);
//[5]遍历
for (Product product : products) {
System.out.println("id:"+product.getId()
+"\tp_name:"+product.getP_name()
+"\tp_price:"+product.getP_price()
+"\tp_catalog_name:"+product.getP_catalog_name()
+"\tp_number:"+product.getP_number()
+"\tp_picture:"+product.getP_picture()
);
}
//[6]关闭资源
client.close();
}
查询结果:
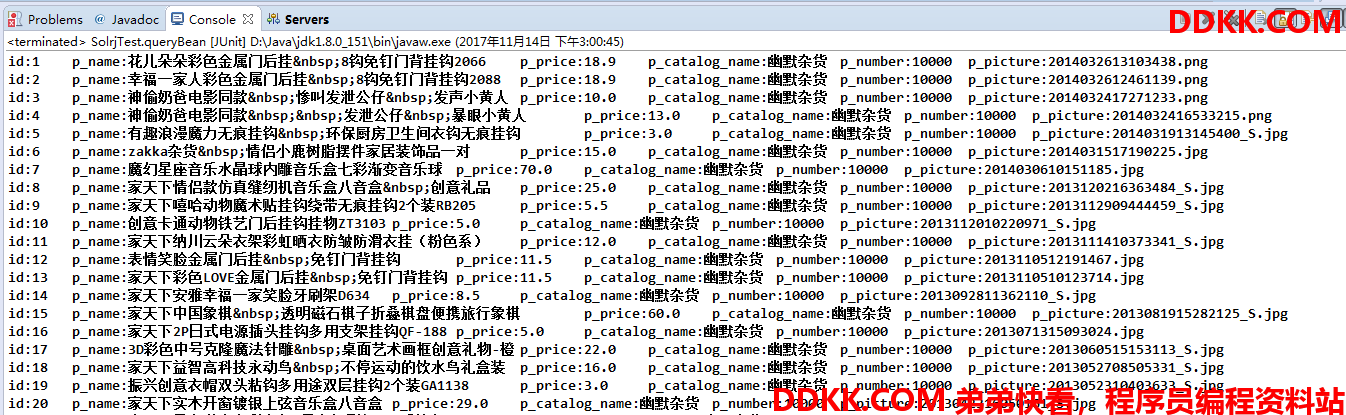
(3)solrJ之通过deleteByQuery删除索引
/**
* 8、通过deleteByQuery删除索引
*/
@Test
public void deleteBean() throws Exception{
//[1]获取连接
// HttpSolrClient client= new HttpSolrClient.Builder("http://127.0.0.1:8080/solr/core1").build();
String solrUrl = "http://127.0.0.1:8080/solr/core1";
//创建solrClient同时指定超时时间,不指定走默认配置
HttpSolrClient client = new HttpSolrClient.Builder(solrUrl)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build();
//[2]执行删除
client.deleteByQuery("id:100");
//[3]提交操作
client.commit();
//[4]关闭资源
client.close();
}
下面是官网API的对字段类型定义的说法
字段类型定义和属性
在managed-schema文件中的字段类型定义

①上面的示例中的第一行包含字段类型名称name="text_general",实现类的名称class="solr.TextField"
②其余的定义是关于对field分析、描述 理解分析、分词器和过滤器。
实现类负责确保字段是正确的被处理。 在managed-schema中的类名,```字符串solr是org.apache.solr.schema或org.apache.solr.analysis的缩写。如:solr.TextField真的是org.apache.solr.schema.TextField`。
字段类型属性
field type的class属性决定了大多数字段类型的行为,但可选属性也可以被定义。例如,下面的日期字段类型定义两个属性的定义,sortMissingLast和omitNorms。
<fieldType name="date" class="solr.DatePointField" sortMissingLast="true" omitNorms="true"/>
可以为一个给定的指定的属性字段类型分为三大类:
- 特定的字段类型的class属性。
- Solr支持任何字段类型。
- 可以指定的字段类型所继承的字段,使用这个类型而不是默认的行为。
一般属性
这些都是一般的属性字段
name
fieldType的name。 这个值被用于field定义的“type”属性。 强烈建议名称只包含字母数字或下划线字符,而不是从一个数字开始。 这不是目前严格执行。
class
class的name,用于存储和索引的数据类型。 请注意,您可能包括类名前面加上“solr。 ”,Solr搜索会自动找出哪些包类,所以 solr.TextField将工作。
如果您使用的是第三方的类,你可能需要一个完全限定的类名。完全限定的等效 solr.TextField是 org.apache.solr.schema.TextField。
positionIncrementGap
对于多值字段,指定多个值之间的距离,防止虚假的短语匹配。
autoGeneratePhraseQueries
对于文本字段。 如果 true,Solr自动生成短语查询相邻。 如果`false```、terms 必须括在双引号被视为短语。
enableGraphQueries
对于text fields,查询时适用 sow = false(这是默认的 sow参数)。 使用 true、默认字段类型的查询分析器包括graph-aware过滤器,例如, Synonym Graph Filter 和 Word Delimiter Graph Filter。
使用false字段类型的查询分析器可以匹配文档包括过滤器,当一些令牌丢失,例如, Shingle Filter。
docValuesFormat
定义了一个定制的 DocValuesFormat用于这种类型的字段。 这就要求一个感知的编解码器,如 SchemaCodecFactory已经配置在 xml。
postingsFormat
定义了一个定制的 PostingsFormat用于这种类型的字段。 这就要求一个感知的编解码器,如 SchemaCodecFactory已经配置在 xml。
字段默认属性
这些属性可以指定字段类型,或对个人领域覆盖提供的字段类型的值。
每个属性的默认值取决于底层 FieldType类,进而可能取决于 版本的属性<schema/>。 下表包含了大部分的默认值 FieldTypeSolr提供了实现,假设 schema.xml声明 version = " 1.6 "。
| 属性 | 描述 | 值 | 默认值 |
| indexed | 如果true,字段的值可用于查询来检索匹配的文档。 |
true or false
|
true |
| stored | 如果true,field的实际值可以通过查询检索。 | true or false | true |
| docValues | 如果true,字段的值将用于 DocValues 结构。 | true or false | false |
| sortMissingFirst sortMissingLast | 控制文档的位置,当分类字段不存在时。 | true or false | false |
|
multiValued
|
如果是true,表明一个文档可能包含多个值的字段类型。 | true or false | false |
| omitNorms | 如果是true,省略了与这个领域相关的规范(这个禁用长度归一化的领域,并节省一些内存)。 所有原始默认值为true(non-analyzed)字段类型,如整数、浮点数、数据、布尔值和字符串。 只有全文字段或字段需要规范。 | true or false | * |
| omitTermFreqAndPositions | 如果是true,省略了词频率、位置和有效载荷从检索条数的field。 这是一个性能提升不需要这些信息的field。 它还可以减少所需的存储空间索引。 依赖于位置的查询字段上发布这个选项将默默地找不到文件。 该属性默认为适用于所有字段类型非 text fields。 | true or false | * |
| omitPositions | 类似于 omitTermFreqAndPositions 但保留词频率信息。 |
true or false | * |
| termVectors termPositions termOffsets termPayloads | 这些选项指示Solr保持完整任期为每个文档向量,可选地包括位置、抵消和负载信息为每个术语出现在这些向量。 这些可以用来加速高亮显示和其他辅助功能,但对大量成本指数的大小。 他们不是典型的使用Solr的必要条件。 | true or false | false |
| required | 没有这个字段的值,命令Solr拒绝任何试图添加一个文档。 该属性默认值为false。 | true or false | false |
| useDocValuesAsStored | 如果字段有 docValues 启用时,设置为true将允许返回字段,就好像它是一个存储字段(即使它stored=false)当匹配 * 一个在一个 fl参数 。 |
true or false | true |
|
large
|
多数的field总是懒加载和当文档中占用空间缓存的实际值 < 512 kb。 这个选项需要 stored="true"和 multiValued="false"。它是用于field有非常大的价值,这样他们不会在内存中缓存。 | true or false | false |
包含在Solr中字段类型
下表列出了在Solr可用字段类型。 的 org.apache.solr.schema包包括所有表中列出的类。
由于工作原因,下边的描述还有待查证。
| class | 描述 |
| BinaryField | |
| BoolField | |
| CollationField | |
| CurrencyField | |
| CurrencyFieldType | |
| DateRangeField | |
| DatePointField | |
| DoublePointField | |
| ExternalFileField | |
| EnumField | |
| EnumFieldType | |
| FloatPointField | |
| ICUCollationField | |
| IntPointField | |
| LatLonPointSpatialField | |
| LatLonType | |
| LongPointField | |
| PointType | |
| PreAnalyzedField | |
| RandomSortField | |
| SpatialRecursivePrefixTreeFieldType | |
| StrField | |
| TextField | |
| TrieDateField | 弃用 。 使用DatePointField代替。 |
| TrieDoubleField | 弃用 。 使用DoublePointField代替。 |
| TrieFloatField | 弃用 。 使用FloatPointField代替。 |
| TrieIntField | 弃用 。 使用IntPointField代替。 |
| TrieLongField | 弃用 。 使用LongPointField代替。 |
| TrieField | 弃用 。 这个field需要 |
| UUIDField |