ShardingSphere最重要的功能模块是数据分片,从规则到实现都比较复杂。其他功能相对来说比较简单,本篇介绍ShardingSphere的读写分离功能。
一、功能详解
1. 背景
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。使用多主多从的方式,不但能够提升系统吞吐量,还能够提升系统可用性,可以达到在任何一个数据库宕机,甚至磁盘物理损坏的情况下仍然不影响系统的正常运行。
与将数据根据分片键打散至各个数据节点的水平分片不同,读写分离则是根据对SQL语义的分析,将读操作和写操作分别路由至主库与从库,如下图所示。
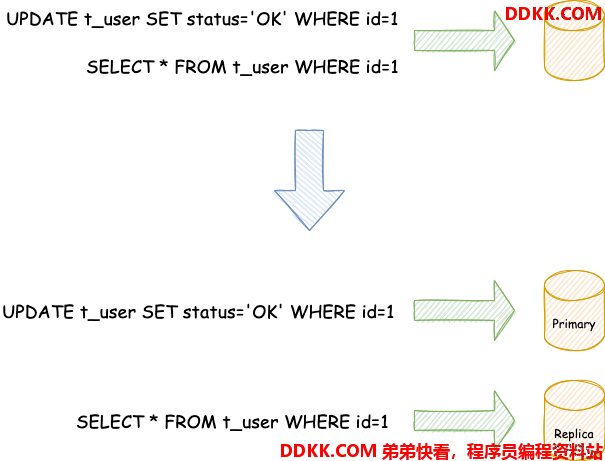
读写分离数据节点中的数据内容是一致的,而水平分片的每个数据节点的数据内容却并不相同。将水平分片和读写分离联合使用,能够更加有效的提升系统性能。
读写分离虽然可以提升系统的吞吐量和可用性,但同时也带来了数据不一致的问题。这包括多个主库之间的数据一致性,以及主库与从库之间的数据一致性的问题。并且,读写分离也带来了与数据分片同样的问题,它同样会使得应用开发和运维人员对数据库的操作和运维变得更加复杂。下图展现了将数据分片与读写分离一同使用时,应用程序与数据库集群之间的复杂拓扑关系。
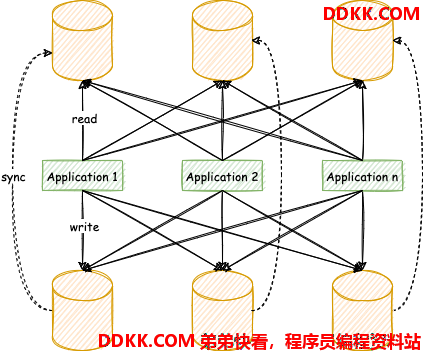
透明化读写分离所带来的影响,让使用方尽量像使用一个数据库一样使用主从数据库集群,是ShardingSphere读写分离模块的主要设计目标。
2. 核心概念
- 主库
添加、更新以及删除数据操作所使用的数据库,目前仅支持单主库。
- 从库
查询数据操作所使用的数据库,可支持多从库。
- 主从同步
将主库的数据异步同步到从库的操作。由于主从同步的异步性,从库与主库的数据会短时间内不一致。
- 负载均衡策略
将查询请求疏导至不同从库以均衡负载的策略。
3. 使用规范
- 支持项:提供一主多从的读写分离配置,可独立使用,也可配合数据分片使用;事务中的数据读写均用主库;基于 Hint 的强制主库路由。
- 不支持项:主库和从库的数据同步;主库和从库的数据同步延迟导致的数据不一致;主库多写;主从库间的事务一致性。主从模型中,事务中的数据读写均用主库。
二、用例测试
测试环境已经配置好MySQL一主两从异步复制如下:
- 主库:172.18.26.198:3306
- 从库:172.18.10.66:3306;172.18.18.102:3306
MySQL异步复制配置过程参见“四、配置异步复制”。为了便于分析,将两个从库设置为只读:
set global read_only = on;
set global super_read_only = on;
跟使用数据分片功能一样,资源、规则、逻辑表等对象都隶属于一个逻辑数据库。因此我们先要在ShardingSphere中创建一个新的逻辑数据库,之后所有测试均在此逻辑数据库之中进行。
-- 创建逻辑库
create database splitting_db;
-- 切换当前数据库
use splitting_db;
1. 读写分离
需求:主库实例中有两个物理数据库用于写,从库1中对应的两个物理数据库用于读。
(1)添加资源
add resource
write_ds1 (host=172.18.26.198, port=3306, db=db3, user=wxy, password=mypass),
write_ds2 (host=172.18.26.198, port=3306, db=db4, user=wxy, password=mypass),
read_ds1 (host=172.18.10.66, port=3306, db=db3, user=wxy, password=mypass),
read_ds2 (host=172.18.10.66, port=3306, db=db4, user=wxy, password=mypass),
read_ds3 (host=172.18.18.102, port=3306, db=db3, user=wxy, password=mypass),
read_ds4 (host=172.18.18.102, port=3306, db=db4, user=wxy, password=mypass);
(2)创建表
create default single table rule resource = write_ds1;
create table t_order (
order_id bigint auto_increment primary key,
user_id bigint not null,
order_quantity int not null default 0,
order_amount decimal(10 , 2 ) not null default 0,
remark varchar(100),
key idx_user_id (user_id));
alter default single table rule resource = write_ds2;
create table t_order2 (
order_id bigint auto_increment primary key,
user_id bigint not null,
order_quantity int not null default 0,
order_amount decimal(10 , 2 ) not null default 0,
remark varchar(100),
key idx_user_id (user_id));
上篇已经讲过,对于没有对应规则的表,创建的是单表,而如果没有缺省单表规则,建表前并不能确定表被建在哪个数据源中。上面的建表语句可能被路由到一个只读从库中,因此报错。
mysql> create table t_order (
-> order_id bigint auto_increment primary key,
-> user_id bigint not null,
-> order_quantity int not null default 0,
-> order_amount decimal(10 , 2 ) not null default 0,
-> remark varchar(100),
-> key idx_user_id (user_id));
ERROR 1290 (HY000): The MySQL server is running with the --super-read-only option so it cannot execute this statement
所以在建表前,我们通过定义缺省单表规则来指定单表数据源。
再创建第二张表时,注意因为是逻辑表,即使实际在不同物理数据库中建表,这里也不能重名,否则会报Table 't_order' already exists错误。这是与单实例MySQL的区别之一。
现在可以查询两个实际从库确认表所属库是否正确,同时也能表示复制是否成功。
[mysql@vvgg-z2-music-mysqld~]$mysql -uwxy -h172.18.10.66 -P3306 -pmypass -Ddb3 -e "show tables;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+---------------+
| Tables_in_db3 |
+---------------+
| t_order |
+---------------+
[mysql@vvgg-z2-music-mysqld~]$mysql -uwxy -h172.18.10.66 -P3306 -pmypass -Ddb4 -e "show tables;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+---------------+
| Tables_in_db4 |
+---------------+
| t_order2 |
+---------------+
[mysql@vvgg-z2-music-mysqld~]$mysql -uwxy -h172.18.18.102 -P3306 -pmypass -Ddb3 -e "show tables;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+---------------+
| Tables_in_db3 |
+---------------+
| t_order |
+---------------+
[mysql@vvgg-z2-music-mysqld~]$mysql -uwxy -h172.18.18.102 -P3306 -pmypass -Ddb4 -e "show tables;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+---------------+
| Tables_in_db4 |
+---------------+
| t_order2 |
+---------------+
(3)创建读写分离规则
create readwrite_splitting rule ms_group_1 (
write_resource=write_ds1,
read_resources(read_ds1));
create readwrite_splitting rule ms_group_2 (
write_resource=write_ds2,
read_resources(read_ds2));
以上语句创建了两个读写分离规则。根据需求,第一个规则将写操作路由到write_ds1数据源,读操作路由到read_ds1数据源。第二个规则将写操作路由到write_ds2数据源,读操作路由到read_ds2数据源。
查看规则:
mysql> show readwrite_splitting rules\G
*************************** 1. row ***************************
name: ms_group_1
auto_aware_data_source_name:
write_data_source_name: write_ds1
read_data_source_names: read_ds1
load_balancer_type:
load_balancer_props:
*************************** 2. row ***************************
name: ms_group_2
auto_aware_data_source_name:
write_data_source_name: write_ds2
read_data_source_names: read_ds2
load_balancer_type:
load_balancer_props:
2 rows in set (0.01 sec)
ShardingSphere支持创建静态读写分离规则和动态读写分离规则,动态读写分离规则依赖于数据库发现规则,而数据库发现目前只支持MySQL组复制。从我个人的观点来看,MySQL组复制以性能角度衡量并不是一个理想的解决方案。为了满足多主写强一致性,组复制比简单的异步复制性能衰减严重,量化对比结果参见“8. 主从、半同步、组复制性能对比测试”。出于这个原因,本篇不做动态读写分离的演示。
(4)读写数据
预览实际执行的SQL,确认路由符合预期。
mysql> preview select * from t_order;
+------------------+-----------------------+
| data_source_name | actual_sql |
+------------------+-----------------------+
| read_ds1 | select * from t_order |
+------------------+-----------------------+
1 row in set (0.01 sec)
mysql> preview select * from t_order2;
+------------------+------------------------+
| data_source_name | actual_sql |
+------------------+------------------------+
| read_ds2 | select * from t_order2 |
+------------------+------------------------+
1 row in set (0.00 sec)
mysql> preview
-> insert into t_order (user_id,order_quantity,order_amount) values (1,10,100),(99,10,100),(100,10,100),(199,10,100),(200,10,100),(299,10,100),(300,10,100),(399,10,100)\G
*************************** 1. row ***************************
data_source_name: write_ds1
actual_sql: insert into t_order (user_id,order_quantity,order_amount) values (1,10,100),(99,10,100),(100,10,100),(199,10,100),(200,10,100),(299,10,100),(300,10,100),(399,10,100)
1 row in set (0.00 sec)
mysql> preview
-> insert into t_order2 (user_id,order_quantity,order_amount) values (1,10,100),(99,10,100),(100,10,100),(199,10,100),(200,10,100),(299,10,100),(300,10,100),(399,10,100)\G
*************************** 1. row ***************************
data_source_name: write_ds2
actual_sql: insert into t_order2 (user_id,order_quantity,order_amount) values (1,10,100),(99,10,100),(100,10,100),(199,10,100),(200,10,100),(299,10,100),(300,10,100),(399,10,100)
1 row in set (0.01 sec)
可以看到,对t_order、t_order2表的查询分别路由到read_ds1、read_ds2执行,对两表的写操作分别路由到write_ds1、write_ds2执行,实现了读写分离需求。 实际执行结果如下:
mysql> insert into t_order (user_id,order_quantity,order_amount) values (1,10,100),(99,10,100),(100,10,100),(199,10,100),(200,10,100),(299,10,100),(300,10,100),(399,10,100);
Query OK, 8 rows affected (0.02 sec)
mysql> insert into t_order2 (user_id,order_quantity,order_amount) values (1,10,100),(99,10,100),(100,10,1100),(199,10,100),(200,10,100),(299,10,100),(300,10,100),(399,10,100);
Query OK, 8 rows affected (0.02 sec)
mysql> select * from t_order;
+----------+---------+----------------+--------------+--------+
| order_id | user_id | order_quantity | order_amount | remark |
+----------+---------+----------------+--------------+--------+
| 1 | 1 | 10 | 100.00 | NULL |
| 2 | 99 | 10 | 100.00 | NULL |
| 3 | 100 | 10 | 100.00 | NULL |
| 4 | 199 | 10 | 100.00 | NULL |
| 5 | 200 | 10 | 100.00 | NULL |
| 6 | 299 | 10 | 100.00 | NULL |
| 7 | 300 | 10 | 100.00 | NULL |
| 8 | 399 | 10 | 100.00 | NULL |
+----------+---------+----------------+--------------+--------+
8 rows in set (0.02 sec)
mysql> select * from t_order2;
+----------+---------+----------------+--------------+--------+
| order_id | user_id | order_quantity | order_amount | remark |
+----------+---------+----------------+--------------+--------+
| 1 | 1 | 10 | 100.00 | NULL |
| 2 | 99 | 10 | 100.00 | NULL |
| 3 | 100 | 10 | 100.00 | NULL |
| 4 | 199 | 10 | 100.00 | NULL |
| 5 | 200 | 10 | 100.00 | NULL |
| 6 | 299 | 10 | 100.00 | NULL |
| 7 | 300 | 10 | 100.00 | NULL |
| 8 | 399 | 10 | 100.00 | NULL |
+----------+---------+----------------+--------------+--------+
8 rows in set (0.01 sec)
2. 读负载均衡
(1)轮询算法
修改ms_group_1规则添加一个读库,并指定负载均衡算法为轮询。
alter readwrite_splitting rule ms_group_1 (
write_resource=write_ds1,
read_resources(read_ds1, read_ds3),
type(name=round_robin));
预览实际执行的SQL,确认读操作在两个数据源间轮询。
mysql> preview select * from t_order;
+------------------+-----------------------+
| data_source_name | actual_sql |
+------------------+-----------------------+
| read_ds3 | select * from t_order |
+------------------+-----------------------+
1 row in set (0.00 sec)
mysql> preview select * from t_order;
+------------------+-----------------------+
| data_source_name | actual_sql |
+------------------+-----------------------+
| read_ds1 | select * from t_order |
+------------------+-----------------------+
1 row in set (0.00 sec)
mysql> preview select * from t_order;
+------------------+-----------------------+
| data_source_name | actual_sql |
+------------------+-----------------------+
| read_ds3 | select * from t_order |
+------------------+-----------------------+
1 row in set (0.00 sec)
(2)随机访问算法
修改ms_group_2规则添加一个读库,并指定负载均衡算法为随机。
alter readwrite_splitting rule ms_group_2 (
write_resource=write_ds2,
read_resources(read_ds2, read_ds4),
type(name=random));
预览实际执行的SQL,确认读操作在两个数据源间随机选择。
[mysql@vvgg-z2-music-mysqld~]$mysql -u root -h 172.18.18.102 -P 3307 -p123456 -Dsplitting_db -e "preview select * from t_order2;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+------------------+------------------------+
| data_source_name | actual_sql |
+------------------+------------------------+
| read_ds2 | select * from t_order2 |
+------------------+------------------------+
[mysql@vvgg-z2-music-mysqld~]$mysql -u root -h 172.18.18.102 -P 3307 -p123456 -Dsplitting_db -e "preview select * from t_order2;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+------------------+------------------------+
| data_source_name | actual_sql |
+------------------+------------------------+
| read_ds4 | select * from t_order2 |
+------------------+------------------------+
[mysql@vvgg-z2-music-mysqld~]$mysql -u root -h 172.18.18.102 -P 3307 -p123456 -Dsplitting_db -e "preview select * from t_order2;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+------------------+------------------------+
| data_source_name | actual_sql |
+------------------+------------------------+
| read_ds4 | select * from t_order2 |
+------------------+------------------------+
[mysql@vvgg-z2-music-mysqld~]$mysql -u root -h 172.18.18.102 -P 3307 -p123456 -Dsplitting_db -e "preview select * from t_order2;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+------------------+------------------------+
| data_source_name | actual_sql |
+------------------+------------------------+
| read_ds2 | select * from t_order2 |
+------------------+------------------------+
[mysql@vvgg-z2-music-mysqld~]$mysql -u root -h 172.18.18.102 -P 3307 -p123456 -Dsplitting_db -e "preview select * from t_order2;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+------------------+------------------------+
| data_source_name | actual_sql |
+------------------+------------------------+
| read_ds4 | select * from t_order2 |
+------------------+------------------------+
(3)权重访问算法
修改ms_group_1规则添加一个读库,并指定两个读库的权重为2:1。
alter readwrite_splitting rule ms_group_1 (
write_resource=write_ds1,
read_resources(read_ds1, read_ds3),
type(name=weight, properties(read_ds1=2,read_ds3=1)));
预览实际执行的SQL,确认读操作在两个数据源的访问比例为2比1。由于只有两个读库,加了权重的随机不太明显,但还是能看到read_ds1的路由比例大于read_ds3。连续12次执行preview select * from t_order,路由到read_ds1为7次,read_ds3为5次。
修改ms_group_2规则添加一个读库,并指定两个读库的权重为1:0。
alter readwrite_splitting rule ms_group_2 (
write_resource=write_ds2,
read_resources(read_ds2, read_ds4),
type(name=weight, properties(read_ds2=1,read_ds4=0)));
预览实际执行的SQL,因为read_ds4的权重指定为0,所以每次查询都路由到read_ds2。
3. 客户端连接透传问题
原来在使用MySQL-Router时遇到了一个问题,应用通过Router连接到底层数据库实例后,show processlist输出中的Host列,始终为运行Router的主机地址。这给监控和排查问题都带来了不便,因为无法得知是哪个应用程序连接的数据库。换句话说,就是Router无法将连接数据库的客户端地址透传给MySQL服务器。
ShardingSphere-Proxy会不会有同样的问题呢?先说结论,ShardingSphere-Proxy也无法透传客户端连接地址,但这并不是问题,相反如果透传了才会造成混淆。
ShardingSphere-Proxy与MySQL-Router实现机制完全不同。前者实现了MySQL客户端服务器连接协议,并且提供了完整的MySQL控制台。对于用户来说,就拿Proxy当MySQL服务器使用,从Proxy的控制台就可以执行show processlist命令监控客户端连接,而从底层物理数据库实例中看到的则是ShardingSphere-Proxy的主机地址。在这种用法上,只需监控应用到Proxy的连接即可。
如果Proxy将客户端连接地址透传给底层MySQL服务器,而同时又有应用直连底层MySQL服务器,那么从MySQL中就无法区分那些连接是通过ShardingSphere-Proxy,哪些连接是直连,反而不好查问题。
ShardingSphere-Proxy缺省关闭show processlist功能,但可以通过将show-process-list-enabled属性设置为true开启。在server.yaml配置文件中添加:
props:
show-process-list-enabled: true
然会重启ShardingSphere-Proxy使配置生效:
/root/apache-shardingsphere-5.1.1-shardingsphere-proxy-bin/bin/stop.sh
/root/apache-shardingsphere-5.1.1-shardingsphere-proxy-bin/bin/start.sh
从一个客户端连接ShardingSphere-Proxy执行查询:
mysql -u root -h 172.18.18.102 -P 3307 -p123456 -e "select sleep(1000);"
从一个客户端连接ShardingSphere-Proxy控制台查看连接:
mysql> show processlist;
+--------------------------------------+------+---------------+--------------+---------+-------+----------------+------------------------------------------------------------------------------------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+--------------------------------------+------+---------------+--------------+---------+-------+----------------+------------------------------------------------------------------------------------------------------+
| f70c3521-2cb1-69a3-9884-d4fe890755dc | root | 172.18.16.156 | sharding_db | Execute | 37 | Executing 0/1 | select sleep(1000) |
+--------------------------------------+------+---------------+--------------+---------+-------+----------------+------------------------------------------------------------------------------------------------------+
1 rows in set (0.02 sec)
可以看到客户端地址为172.18.16.156,而通常运维人员或DBA只要监控ShardingSphere-Proxy就能发现问题所在,下一步可以再找到底层物理数据库继续排查。