5月13日突然有用户反应订单很久都没结算掉,立刻去看定时器状态,没想到定时器直接挂了,因为是很老旧的单体项目,没有健康检查,所以k8s没有及时通知到开发。pod监控显示几个定时器的实例内存都超过了3GB,cpu也几乎打满。
流程
登录devops工具,打出内存快照,导入mat
分享一套 181G视频的Java架构师课程,累计更新时长1000+个小时
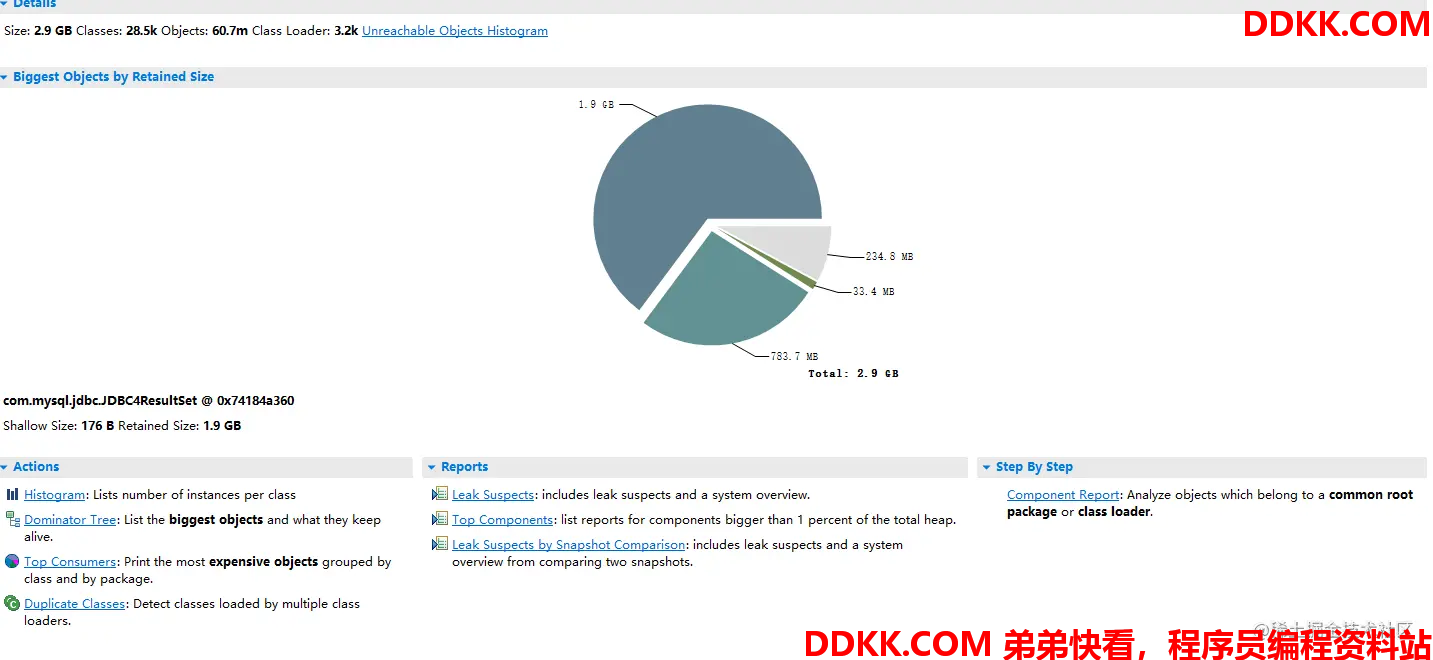
从概览看确实很不正常,这个JDBC4ResultSet的对象居然占据了1.9GB的内存,这个对象对应一次查询的结果,从概览我们大概就能得出是一次错误的sql查询导致查询出了很多不应该查询出来的数据,接下来我们找具体哪个线程生成了这么大的内存
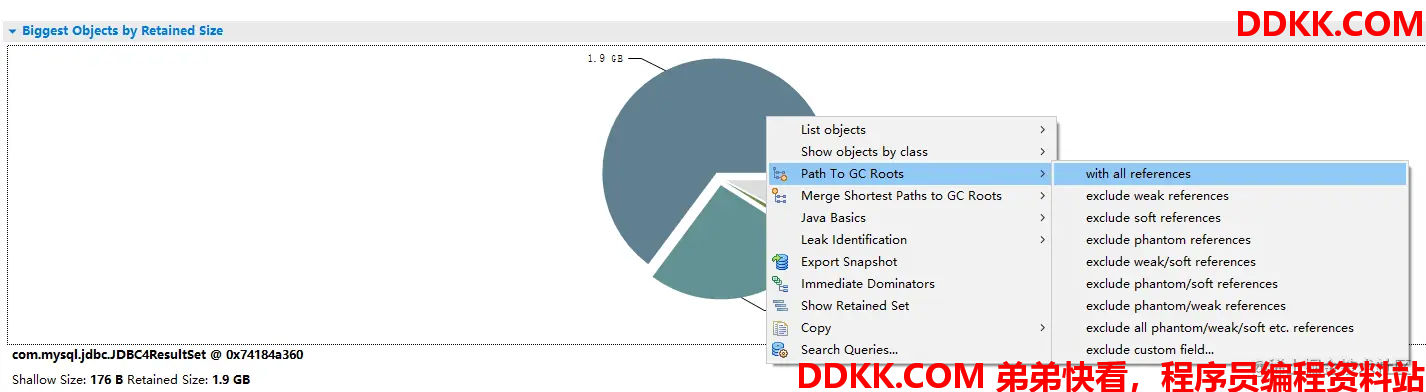
单击最大的区域点击Merge Shortest Paths to GC Roots->with all reference,mat会根据占用内存大小排序所有持有这个对象的线程
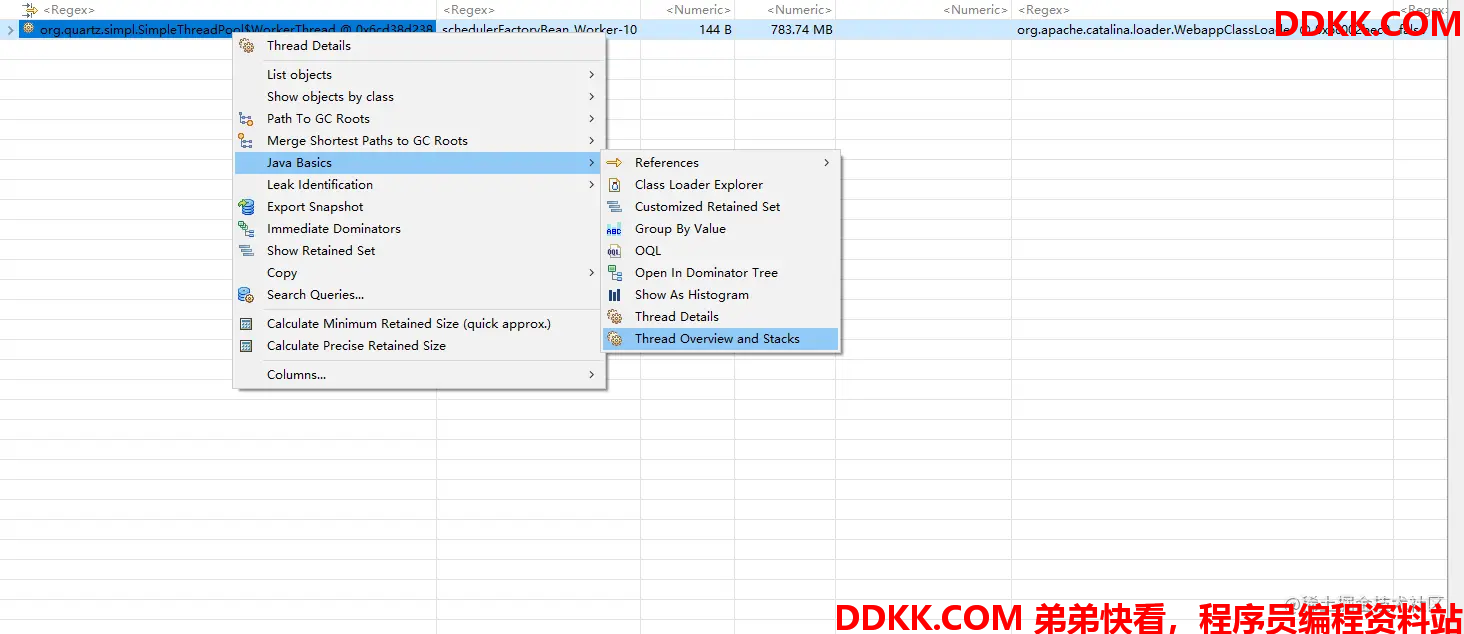
得到一条引用的线程,直接右键java basics->Thread Overview and Stacks,查询当前线程的堆栈
线程的堆栈是这样的,我们尽量从下往上找,从自己熟悉的包名入手。能找到入口,然后一步步排查是哪条sql造的孽
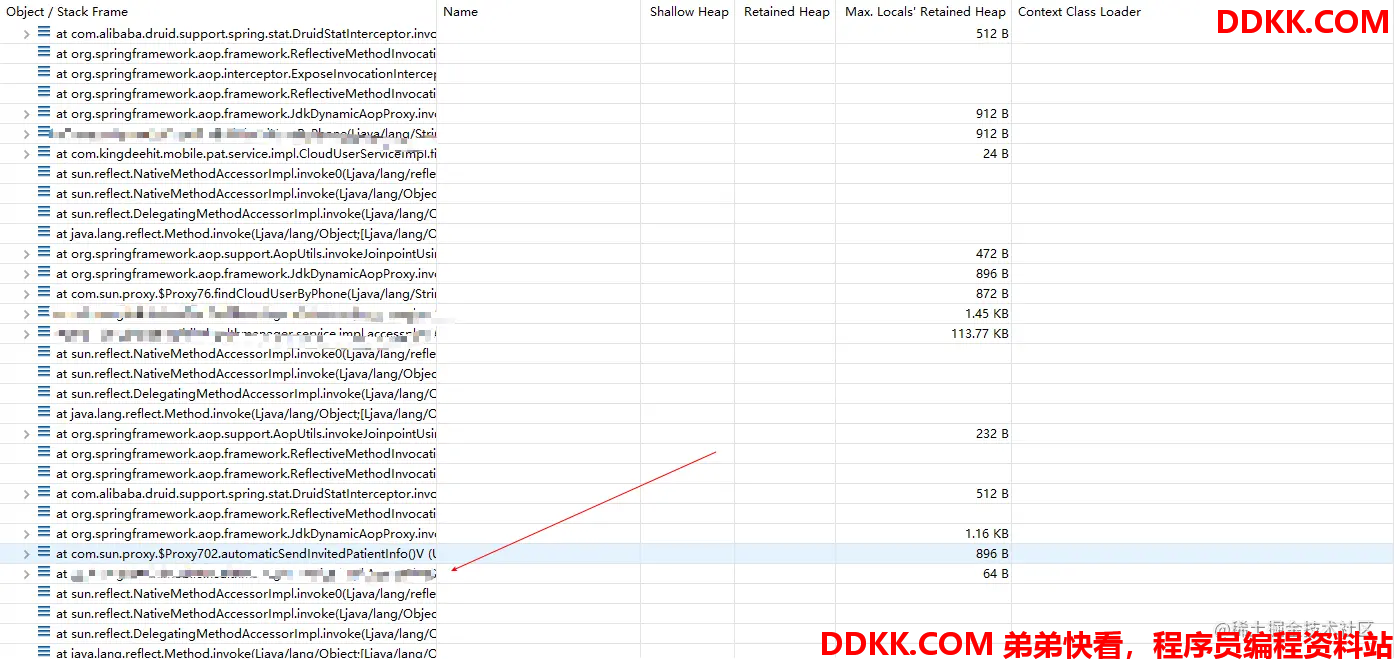
发现最后是这行代码导致了

展开这部分的代码的堆栈

可以看到这个入参是一个空字符串
这行代码的逻辑本来是这样的,通过电话号码去匹配我们的用户然后获取一个用户列表,一般来说这个用户列表是不会超过五个的,但是这个传入的电话号码因为第三方入参了一个空字符串的原因导致把全表的用户都查出来了,表里有好几千万的数据,所以导致了oom宕机
总结及后续措施
- 对第三方入参做限制,如果为空直接拒绝这个请求
06/17 用户端cpu和内存飙升
背景
6月17号晚上突然运维告警,用户端所有实例cpu和内存占用都在稳步上升,重启实例也不可以,虽然尚未宕机,但是已经到了宕机的边缘,cpu几乎跑满。用户端服务是直接面向用户的服务,非常重要,所以立刻登录develops平台查看实例。
流程
首先还是在develops平台随机挑一个幸运实例打出实例内存快照,打快照这段时间,顺便登录了下skywalking查看gc情况,发现几乎没有ygc,都是fgc,基本一秒两到三次。猜测是错误sql查询大量对象塞满堆,又因为请求没结束这些对象被线程对象持有,所以触发fgc回收整堆,但是回收不掉。这些只是猜测,具体问题具体分析。
拿到内存快照,导入mat,首先查看概览:
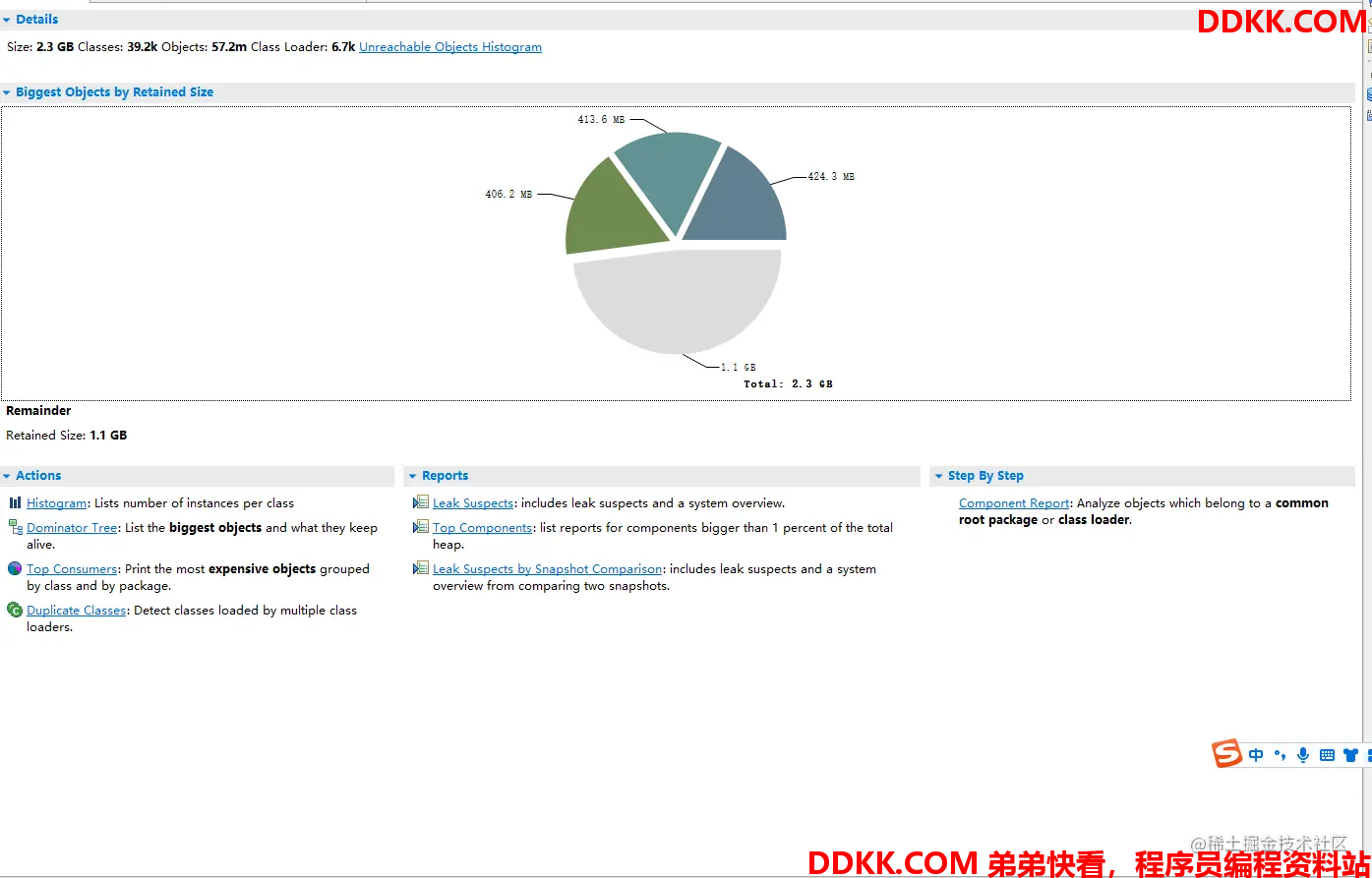
看这个概览感觉问题不是一点点,我们直接看直方图:
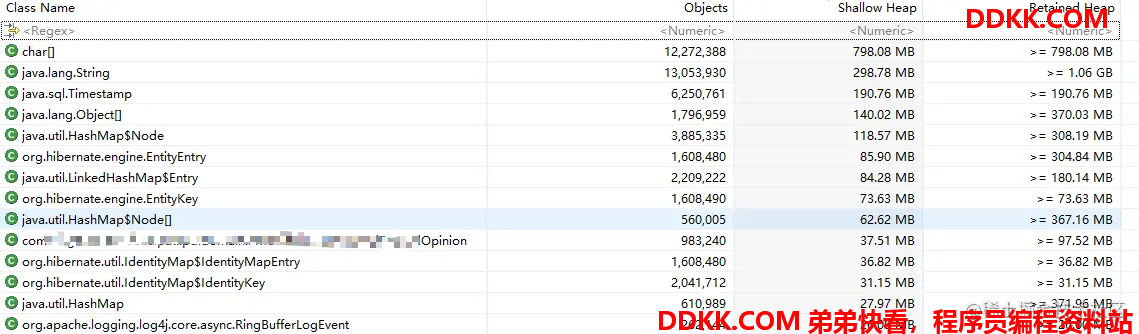
直方图提供了对象数量,浅堆大小(自身对象不包括引用对象的大小)和深堆(包括引用对象的大小)大小三个维度的堆解读
可以看到这里不合理的地方有几个:
1、 TimeStamp这个对象有六百多万个;
2、 打码的Opinion对象有98万个,这个对象是我们的一个业务类,不应该出现这么多个实例;
我们来追踪下Timstamp这个对象,被什么对象引用,右键点击List Objects with incoming references

追踪结果如下:
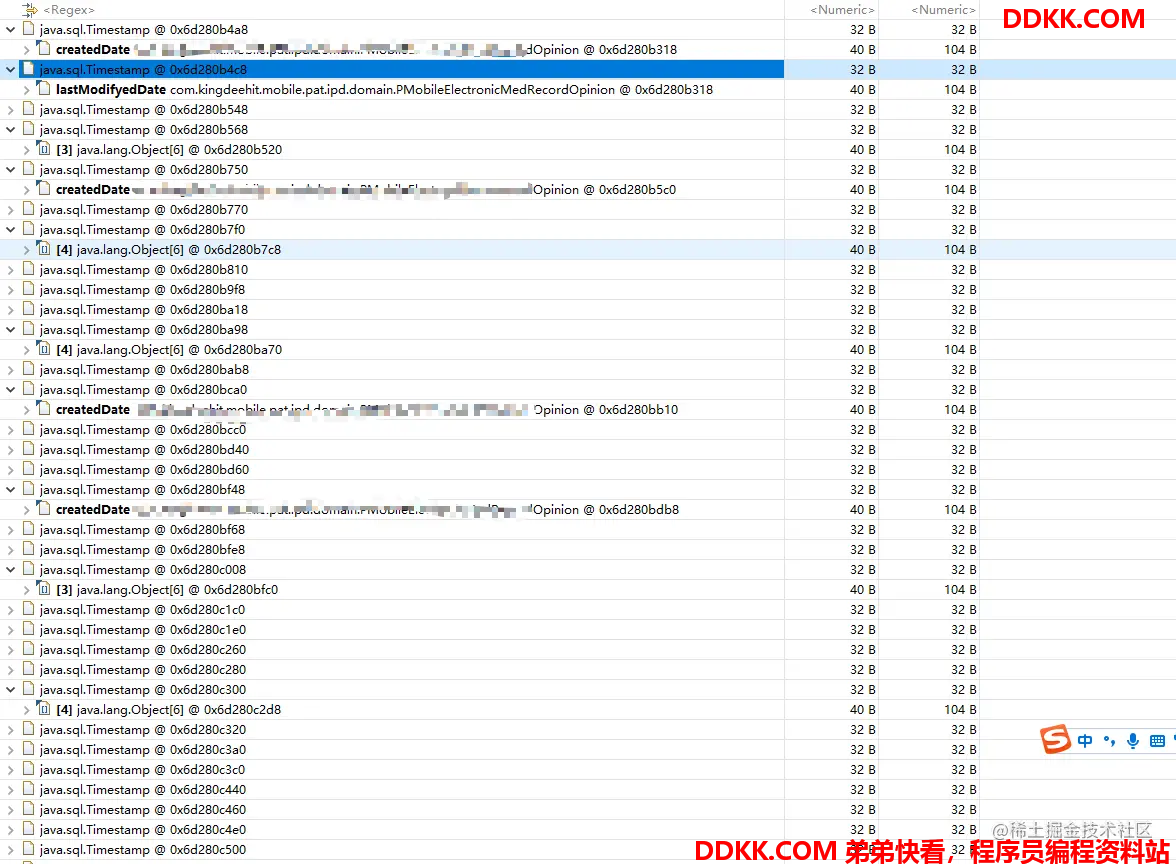
发现TimeStatmp对象被很多的Opinion对象持有,也就是说是大量的Opinion导致了大量的TimeStamp对象,所以罪魁祸首是Opinion对象!
我们追踪下Opinion对象被什么对象引用:

从上图结果看出来,Opinion是被一个容量196647的数组引用的,并且是直接new出来的,就在tomcat线程内new出来的,我们直接对这条线程查看线程的堆栈信息:
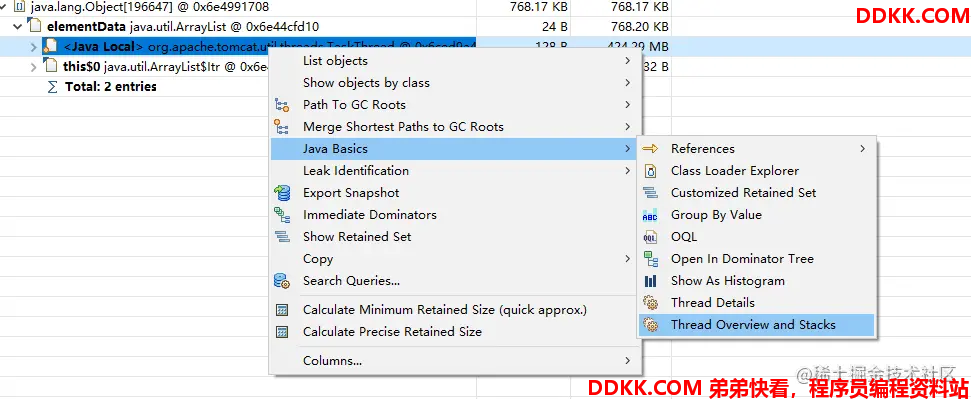
搜索关键字,跟踪堆栈
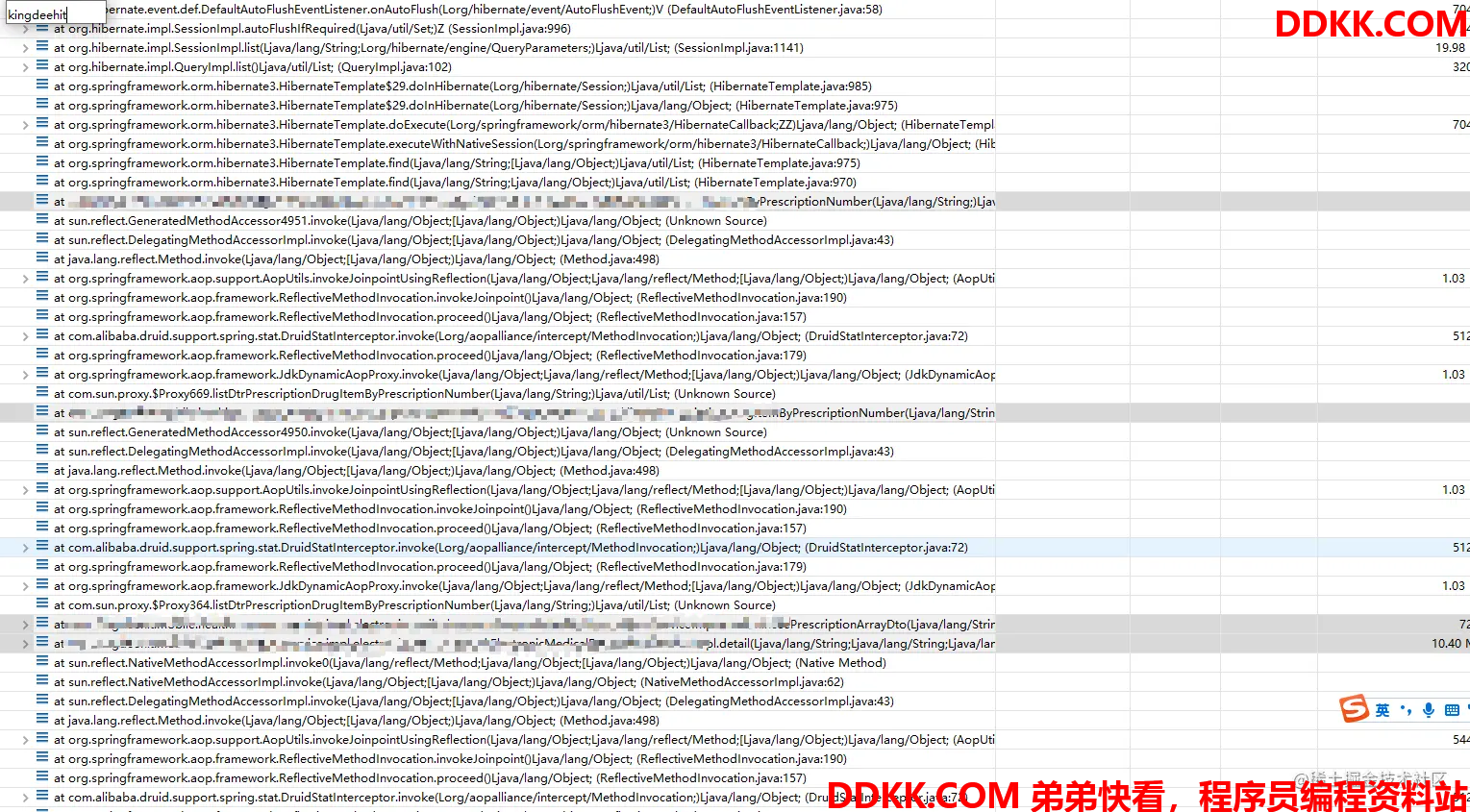
同时在代码根据堆栈发现是这样的
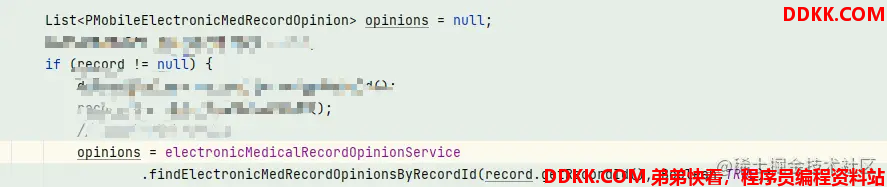
整个堆栈里面也就这里初始化了一个opinion的对象数组,可以基本判断就是这个数组导致的内存飙高,那么接下来定位是哪条数据导致的大数组。在堆栈上找到具体函数,展开函数,查看入参:
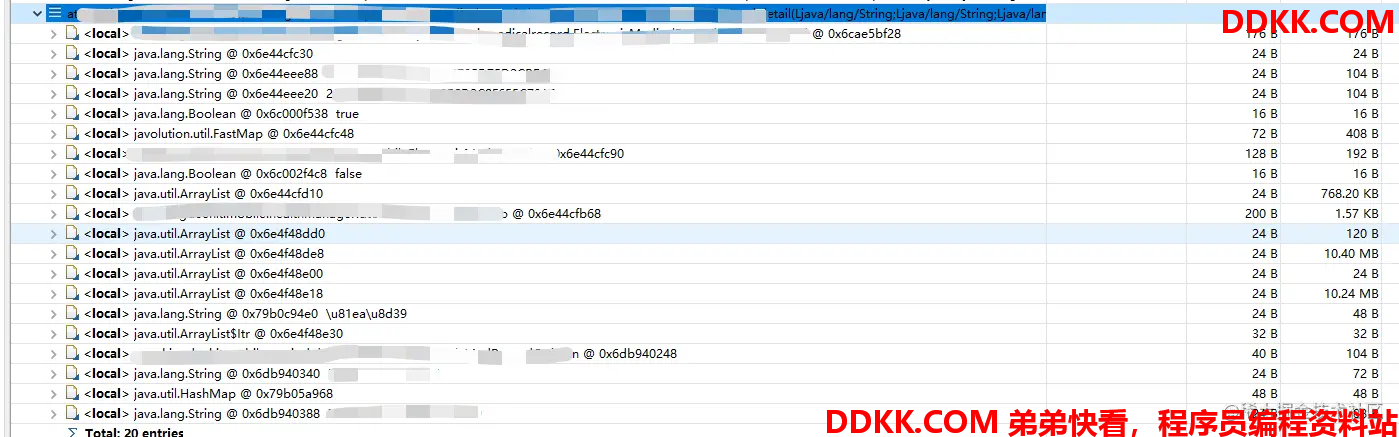
对照代码找到入参,复原sql后发现该条记录存在19w+的关联记录,属于不当操作产生的脏数据,在这个请求被一口气查了出来,并且用户因为系统反应缓慢多次重复请求,导致多条线程都引用这个数组,系统内存几乎用光。
当场措施
删除脏数据后重启实例,系统恢复正常
后续措施
堵住产生脏数据来源,避免下次再次产生大量的脏数据