Redis 简单动态字符串
1.介绍
Redis兼容传统的C语言字符串类型,但没有直接使用C语言的传统的字符串(以’\0’结尾的字符数组) 表示,而是自己构建了一种名为简单动态字符串(simple dynamic string,SDS) 的对象。简单动态字符串在Redis数据库中应用很广泛,例如:键值对在底层就是由SDS实现的。
在redis种,有一种数据类型叫string类型,而string类型简单的说就是SDS实现的(简单理解)
127.0.0.1:6379> SET str1 Redis //设置key:value = str1:Redis
OK
127.0.0.1:6379> GET str1 //获取str1的value
"Redis"
127.0.0.1:6379> TYPE str1 //获取key的存储类型 string类型
string
127.0.0.1:6379> STRLEN str1 //str1的长度为5字节
(integer) 5
2.SDS的定义
SDS定义在redis源码根目录下的sds.h/sdshdr
typedef char *sds;
//sds兼容传统C风格字符串,所以起了个别名叫sds,并且可以存放sdshdr结构buf成员的地址
SDS也有一个表头(header) 用来存放sds的信息。
struct sdshdr {
int len; //buf中已占用空间的长度
int free; //buf中剩余可用空间的长度
char buf[]; //初始化sds分配的数据空间,而且是柔性数组(Flexible array member)
};
关于柔型数组可以看陈皓的一篇文章:C语言结构体里的成员数组和指针
根据这个结构体,我们用图大概表示一下str1,如下图:
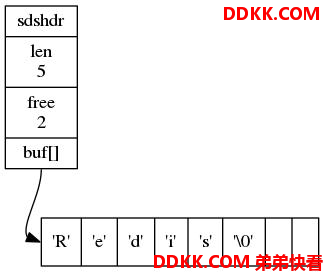
- len为5,表示这个sds长度为5字节。
- free为2,表示这个sds还有2个字节未使用的空间。
- buf是一个char[]的数组,分配了(len+1+free)个字节的长度,前len个字节保存着’R’、’e’、’d’、’i’、’s’这5个字符,接下来的1个字节保存着’\0’,剩下的free个字节未使用。
3. SDS的优点
SDS本质上就是char *,因为有了表头sdshdr结构的存在,所以SDS比传统C字符串在某些方面更加优秀,并且能够兼容传统C字符串。
3.1 兼容C的部分函数
因为SDS兼容传统的C字符串,采用以’\0’作为结尾,所以SDS就能够使用一部分
3.2 二进制安全(Binary Safe)
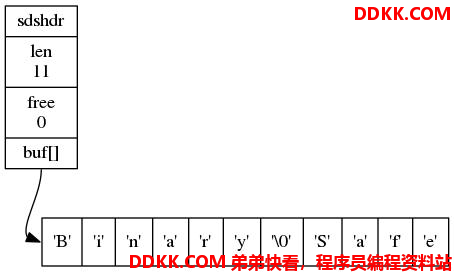
因为传统C字符串符合ASCII编码,这种编码的操作的特点就是:遇零则止 。即,**当读一个字符串时,只要遇到’\0’结尾,就认为到达末尾,就忽略’\0’结尾以后的所有字符。**因此,如果传统字符串保存图片,视频等二进制文件,操作文件时就被截断了。
而SDS表头的buf被定义为字节数组,因为判断是否到达字符串结尾的依据则是表头的len成员,这意味着它可以存放任何二进制的数据和文本数据,包括’\0’,如下图:
3.3 获得字符串长度的操作复杂度为O(1)
传统的C字符串获得长度时的做法:遍历字符串的长度,遇零则止,复杂度为O(n)。
而SDS表头的len成员就保存着字符串长度,所以获得字符串长度的操作复杂度为O(1)。
3.4 杜绝缓冲区溢出
因为SDS表头的free成员记录着buf字符数组中未使用空间的字节数,所以,在进行APPEND命令向字符串后追加字符串时,如果不够用会先进行内存扩展,在进行追加。
总之,正是因为表头的存在,使得redis的字符串有这么多优点。
4. SDS源码剖析
4.1 SDS内存分配策略—空间预分配
空间预分配策略用于优化SDS的字符串增长操作。
- 如果对SDS进行修改后,SDS表头的len成员小于1MB,那么就会分配和len长度相同的未使用空间。free和len成员大小相等。
- 如果对SDS进行修改后,SDS的长度大于等于1MB,那么就会分配1MB的未使用空间。
通过空间预分配策略,Redis可以减少连续执行字符串增长操作所需的内存重分配次数。
源代码如下:
sds sdsMakeRoomFor(sds s, size_t addlen) { //对 sds 中 buf 的长度进行扩展
struct sdshdr *sh, *newsh;
size_t free = sdsavail(s); //获得s的未使用空间长度
size_t len, newlen;
//free的长度够用不用扩展直接返回
if (free >= addlen) return s;
//free长度不够用,需要扩展
len = sdslen(s); //获得s字符串的长度
sh = (void*) (s-(sizeof(struct sdshdr))); //获取表头地址
newlen = (len+addlen); //扩展后的新长度
//空间预分配
//#define SDS_MAX_PREALLOC (1024*1024)
//预先分配内存的最大长度为 1MB
if (newlen < SDS_MAX_PREALLOC) //新长度小于“最大预分配长度”,就直接将扩展的新长度乘2
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC; //新长度大于“最大预分配长度”,就在加上一个“最大预分配长度”
newsh = zrealloc(sh, sizeof(struct sdshdr)+newlen+1); //获得新的扩展空间的地址
if (newsh == NULL) return NULL;
newsh->free = newlen - len; //更新新空间的未使用的空间free
return newsh->buf;
}
4.2 SDS内存释放策略—惰性空间释放
惰性空间释放用于优化SDS的字符串缩短操作。
- 当要缩短SDS保存的字符串时,程序并不立即使用内存充分配来回收缩短后多出来的字节,而是使用表头的free成员将这些字节记录起来,并等待将来使用。
源代码如下:
void sdsclear(sds s) { //重置sds的buf空间,懒惰释放
struct sdshdr *sh = (void*) (s-(sizeof(struct sdshdr)));
sh->free += sh->len; //表头free成员+已使用空间的长度len = 新的free
sh->len = 0; //已使用空间变为0
sh->buf[0] = '\0'; //字符串置空
}
4.3 Redis源码注释
1、 在sds.h文件中,有两个staticinline的函数,分别是sdslen和sdsavail函数,你可以把它认为是一个static的函数,加上了inline的属性而inline关键字仅仅是建议编译器做内联展开处理,而不是强制;
2、 在sds.c中,几乎所有的函数所传的参数都是sds类型,而非表头sdshdr的地址,但是使用了通过sds指针运算从而求得表头的地址的技巧,因为sds是指向sdshdr结构buf成员的通过sds.h/sdslen函数,来分析:;
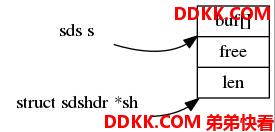
这里的关键就是sds类型是指向sdshdr结构buf成员。
1、 structsdshdr结构共有三个变量,其中sds指向的buf成员是一个柔性数组,它仅仅起到占位符的作用,并不占用该结构体的大小,因此sizeof(sizeof(structsdshdr))大小为8字节;
2、 由于一个SDS类型的内存是通过动态内存分配的,所以它的内存在堆区,堆由下往上增长,因此sds指针减区sizeof(structsdshdr)的大小就得到了表头的地址,然后就可以通过”->”访问表头的成员如下图:;
static inline size_t sdslen(const sds s) { //计算buf中字符串的长度
struct sdshdr *sh = (void*)(s-(sizeof(struct sdshdr))); //s指针地址减去结构体大小就是结构体的地址
return sh->len;
}
通过这种技巧,将表头结构隐藏起来,只对外公开sds类型。
以下源码注释可以访问放在这里:sds.c和sds.h源码注释
- sds.h文件注释
#ifndef __SDS_H
#define __SDS_H
#define SDS_MAX_PREALLOC (1024*1024) //预先分配内存的最大长度为1MB
#include <sys/types.h>
#include <stdarg.h>
typedef char *sds; //sds兼容传统C风格字符串,所以起了个别名叫sds,并且可以存放sdshdr结构buf成员的地址
struct sdshdr {
unsigned int len; //buf中已占用空间的长度
unsigned int free; //buf中剩余可用空间的长度
char buf[]; //初始化sds分配的数据空间,而且是柔性数组(Flexible array member)
};
static inline size_t sdslen(const sds s) { //计算buf中字符串的长度
struct sdshdr *sh = (void*)(s-(sizeof(struct sdshdr)));
return sh->len;
}
static inline size_t sdsavail(const sds s) { //计算buf中的未使用空间的长度
struct sdshdr *sh = (void*)(s-(sizeof(struct sdshdr)));
return sh->free;
}
sds sdsnewlen(const void *init, size_t initlen); //创建一个长度为initlen的字符串,并保存init字符串中的值
sds sdsnew(const char *init); //创建一个默认长度的字符串
sds sdsempty(void); //建立一个只有表头,字符串为空"\0"的sds
size_t sdslen(const sds s); //计算buf中字符串的长度
sds sdsdup(const sds s); //拷贝一份s的副本
void sdsfree(sds s); //释放s字符串和表头
size_t sdsavail(const sds s); //计算buf中的未使用空间的长度
sds sdsgrowzero(sds s, size_t len); //将sds扩展制定长度并赋值为0
sds sdscatlen(sds s, const void *t, size_t len); //将字符串t追加到s表头的buf末尾,追加len个字节
sds sdscat(sds s, const char *t); //将t字符串拼接到s的末尾
sds sdscatsds(sds s, const sds t); //将sds追加到s末尾
sds sdscpylen(sds s, const char *t, size_t len); //将字符串t覆盖到s表头的buf中,拷贝len个字节
sds sdscpy(sds s, const char *t); //将字符串覆盖到s表头的buf中
sds sdscatvprintf(sds s, const char *fmt, va_list ap); //打印函数,被 sdscatprintf 所调用
#ifdef __GNUC__
sds sdscatprintf(sds s, const char *fmt, ...) //打印任意数量个字符串,并将这些字符串追加到给定 sds 的末尾
__attribute__((format(printf, 2, 3)));
#else
sds sdscatprintf(sds s, const char *fmt, ...); //打印任意数量个字符串,并将这些字符串追加到给定 sds 的末尾
#endif
sds sdscatfmt(sds s, char const *fmt, ...); //格式化打印多个字符串,并将这些字符串追加到给定 sds 的末尾
sds sdstrim(sds s, const char *cset); //去除sds中包含有 cset字符串出现字符 的字符
void sdsrange(sds s, int start, int end); //根据start和end区间截取字符串
void sdsupdatelen(sds s); //更新字符串s的长度
void sdsclear(sds s); //将字符串重置保存空间,懒惰释放
int sdscmp(const sds s1, const sds s2); //比较两个sds的大小,相等返回0
sds *sdssplitlen(const char *s, int len, const char *sep, int seplen, int *count); //使用长度为seplen的sep分隔符对长度为len的s进行分割,返回一个sds数组的地址,*count被设置为数组元素数量
void sdsfreesplitres(sds *tokens, int count); //释放tokens中的count个sds元素
void sdstolower(sds s); //将sds字符串所有字符转换为小写
void sdstoupper(sds s); //将sds字符串所有字符转换为大写
sds sdsfromlonglong(long long value); //根据long long value创建一个SDS
sds sdscatrepr(sds s, const char *p, size_t len); //将长度为len的字符串p以带引号""的格式追加到s末尾
sds *sdssplitargs(const char *line, int *argc); //参数拆分,主要用于 config.c 中对配置文件进行分析。
sds sdsmapchars(sds s, const char *from, const char *to, size_t setlen); //将s中所有在 from 中的字符串,替换成 to 中的字符串
sds sdsjoin(char **argv, int argc, char *sep); //以分隔符连接字符串子数组构成新的字符串
/* Low level functions exposed to the user API */
sds sdsMakeRoomFor(sds s, size_t addlen); //对 sds 中 buf 的长度进行扩展
void sdsIncrLen(sds s, int incr); //根据incr的正负,移动字符串末尾的'\0'标志
sds sdsRemoveFreeSpace(sds s); //回收sds中的未使用空间
size_t sdsAllocSize(sds s); //获得sds所有分配的空间
#endif
- sds.c文件注释
/* Create a new sds string with the content specified by the 'init' pointer
* and 'initlen'.
* If NULL is used for 'init' the string is initialized with zero bytes.
*
* The string is always null-termined (all the sds strings are, always) so
* even if you create an sds string with:
*
* mystring = sdsnewlen("abc",3);
*
* You can print the string with printf() as there is an implicit \0 at the
* end of the string. However the string is binary safe and can contain
* \0 characters in the middle, as the length is stored in the sds header. */
sds sdsnewlen(const void *init, size_t initlen) { //创建一个长度为initlen的字符串,并保存init字符串中的值
struct sdshdr *sh;
if (init) {
sh = zmalloc(sizeof(struct sdshdr)+initlen+1); //申请空间:表头+initlen长度+'\0'
} else {
sh = zcalloc(sizeof(struct sdshdr)+initlen+1); //如果init为空,则将申请的空间初始化为0
}
if (sh == NULL) return NULL;
sh->len = initlen; //设置表头的len成员
sh->free = 0; //设置free,新的sds不预留任何空间
if (initlen && init)
memcpy(sh->buf, init, initlen); //将指定的字符串init拷贝到表头的buf中
sh->buf[initlen] = '\0'; //以'\0'结尾
return (char*)sh->buf;
}
/* Create an empty (zero length) sds string. Even in this case the string
* always has an implicit null term. */
sds sdsempty(void) { //建立一个只有表头,字符串为空"\0"的sds
return sdsnewlen("",0);
}
/* Create a new sds string starting from a null terminated C string. */
sds sdsnew(const char *init) { //根据字符串init,创建一个与init一样长度字符串的sds(表头+buf)
size_t initlen = (init == NULL) ? 0 : strlen(init);
return sdsnewlen(init, initlen);
}
/* Duplicate an sds string. */
sds sdsdup(const sds s) { //拷贝一份s的副本
return sdsnewlen(s, sdslen(s));
}
/* Free an sds string. No operation is performed if 's' is NULL. */
void sdsfree(sds s) { //释放s字符串和表头
if (s == NULL) return;
zfree(s-sizeof(struct sdshdr));
}
/* Set the sds string length to the length as obtained with strlen(), so
* considering as content only up to the first null term character.
*
* This function is useful when the sds string is hacked manually in some
* way, like in the following example:
*
* s = sdsnew("foobar");
* s[2] = '\0';
* sdsupdatelen(s);
* printf("%d\n", sdslen(s));
*
* The output will be "2", but if we comment out the call to sdsupdatelen()
* the output will be "6" as the string was modified but the logical length
* remains 6 bytes. */
void sdsupdatelen(sds s) { //更新字符串s的长度
struct sdshdr *sh = (void*) (s-(sizeof(struct sdshdr)));
int reallen = strlen(s);
sh->free += (sh->len-reallen);
sh->len = reallen;
}
/* Modify an sds string in-place to make it empty (zero length).
* However all the existing buffer is not discarded but set as free space
* so that next append operations will not require allocations up to the
* number of bytes previously available. */
void sdsclear(sds s) { //将字符串重置保存空间,懒惰释放
struct sdshdr *sh = (void*) (s-(sizeof(struct sdshdr)));
sh->free += sh->len; //表头free成员+已使用空间的长度len = 新的free
sh->len = 0; //已使用空间变为0
sh->buf[0] = '\0'; //字符串置空
}
/* Enlarge the free space at the end of the sds string so that the caller
* is sure that after calling this function can overwrite up to addlen
* bytes after the end of the string, plus one more byte for nul term.
*
* Note: this does not change the *length* of the sds string as returned
* by sdslen(), but only the free buffer space we have. */
sds sdsMakeRoomFor(sds s, size_t addlen) { //对 sds 中 buf 的长度进行扩展
struct sdshdr *sh, *newsh;
size_t free = sdsavail(s); //获得s的未使用空间长度
size_t len, newlen;
if (free >= addlen) return s; //free的长度够用不用扩展直接返回
//free长度不够用,需要扩展
len = sdslen(s); //获得s字符串的长度
sh = (void*) (s-(sizeof(struct sdshdr)));
newlen = (len+addlen); //扩展后的新长度
if (newlen < SDS_MAX_PREALLOC) //新长度小于“最大预分配长度”,就直接将扩展的新长度乘2
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC; //新长度大于“最大预分配长度”,就在加上一个“最大预分配长度”
newsh = zrealloc(sh, sizeof(struct sdshdr)+newlen+1); //获得新的扩展空间的地址
if (newsh == NULL) return NULL;
newsh->free = newlen - len; //更新新空间的未使用的空间free
return newsh->buf;
}
/* Reallocate the sds string so that it has no free space at the end. The
* contained string remains not altered, but next concatenation operations
* will require a reallocation.
*
* After the call, the passed sds string is no longer valid and all the
* references must be substituted with the new pointer returned by the call. */
sds sdsRemoveFreeSpace(sds s) { //回收sds中的未使用空间
struct sdshdr *sh;
sh = (void*) (s-(sizeof(struct sdshdr))); //获得s表头的地址
sh = zrealloc(sh, sizeof(struct sdshdr)+sh->len+1); //只分配表头len成员大小的空间
sh->free = 0; //更新free成员
return sh->buf;
}
/* Return the total size of the allocation of the specifed sds string,
* including:
* 1) The sds header before the pointer.
* 2) The string.
* 3) The free buffer at the end if any.
* 4) The implicit null term.
*/
size_t sdsAllocSize(sds s) { //获得sds所分配的空间
struct sdshdr *sh = (void*) (s-(sizeof(struct sdshdr)));
return sizeof(*sh)+sh->len+sh->free+1; //表头空间+len+free+'\0'
}
/* Increment the sds length and decrements the left free space at the
* end of the string according to 'incr'. Also set the null term
* in the new end of the string.
*
* This function is used in order to fix the string length after the
* user calls sdsMakeRoomFor(), writes something after the end of
* the current string, and finally needs to set the new length.
*
* Note: it is possible to use a negative increment in order to
* right-trim the string.
*
* Usage example:
*
* Using sdsIncrLen() and sdsMakeRoomFor() it is possible to mount the
* following schema, to cat bytes coming from the kernel to the end of an
* sds string without copying into an intermediate buffer:
*
* oldlen = sdslen(s);
* s = sdsMakeRoomFor(s, BUFFER_SIZE);
* nread = read(fd, s+oldlen, BUFFER_SIZE);
* ... check for nread <= 0 and handle it ...
* sdsIncrLen(s, nread);
*/
void sdsIncrLen(sds s, int incr) { //根据incr的正负,移动字符串末尾的'\0'标志
struct sdshdr *sh = (void*) (s-(sizeof(struct sdshdr)));
if (incr >= 0)
assert(sh->free >= (unsigned int)incr); //保证free的空间大于等于要扩展的空间,否则直接终止程序
else
assert(sh->len >= (unsigned int)(-incr)); //保证len的空间长度大于incr绝对值的长度
sh->len += incr; //更新len、free和'\0'的位置
sh->free -= incr;
s[sh->len] = '\0';
}
/* Grow the sds to have the specified length. Bytes that were not part of
* the original length of the sds will be set to zero.
*
* if the specified length is smaller than the current length, no operation
* is performed. */
sds sdsgrowzero(sds s, size_t len) { //将sds扩展制定长度并赋值为0
struct sdshdr *sh = (void*)(s-(sizeof(struct sdshdr)));
size_t totlen, curlen = sh->len;
if (len <= curlen) return s;
s = sdsMakeRoomFor(s,len-curlen); //扩展字符串sds
if (s == NULL) return NULL;
/* Make sure added region doesn't contain garbage */
sh = (void*)(s-(sizeof(struct sdshdr))); //获得表头地址
memset(s+curlen,0,(len-curlen+1)); /* also set trailing \0 byte */ //用0来填充扩展的空间
//更新表头
totlen = sh->len+sh->free; //总长度
sh->len = len; //使用空间的长度
sh->free = totlen-sh->len; //总长度-使用空间的长度 = 为使用空间的长度
return s;
}
/* Append the specified binary-safe string pointed by 't' of 'len' bytes to the
* end of the specified sds string 's'.
*
* After the call, the passed sds string is no longer valid and all the
* references must be substituted with the new pointer returned by the call. */
sds sdscatlen(sds s, const void *t, size_t len) { //将字符串t追加到s表头的buf末尾,追加len个字节
struct sdshdr *sh;
size_t curlen = sdslen(s); //原有的长度
s = sdsMakeRoomFor(s,len); //扩展空间
if (s == NULL) return NULL;
sh = (void*) (s-(sizeof(struct sdshdr)));
memcpy(s+curlen, t, len); //字符串拼接
//更新属性
sh->len = curlen+len;
sh->free = sh->free-len;
s[curlen+len] = '\0';
return s;
}
/* Append the specified null termianted C string to the sds string 's'.
*
* After the call, the passed sds string is no longer valid and all the
* references must be substituted with the new pointer returned by the call. */
sds sdscat(sds s, const char *t) { //将t字符串拼接到s的末尾
return sdscatlen(s, t, strlen(t));
}
/* Append the specified sds 't' to the existing sds 's'.
*
* After the call, the modified sds string is no longer valid and all the
* references must be substituted with the new pointer returned by the call. */
sds sdscatsds(sds s, const sds t) { //将sds追加到s末尾
return sdscatlen(s, t, sdslen(t));
}
/* Destructively modify the sds string 's' to hold the specified binary
* safe string pointed by 't' of length 'len' bytes. */
sds sdscpylen(sds s, const char *t, size_t len) { //将字符串t覆盖到s表头的buf中,拷贝len个字节
struct sdshdr *sh = (void*) (s-(sizeof(struct sdshdr)));
size_t totlen = sh->free+sh->len; //获得总长度
if (totlen < len) { //总长度小于len
s = sdsMakeRoomFor(s,len-sh->len); //扩展l空间
if (s == NULL) return NULL;
sh = (void*) (s-(sizeof(struct sdshdr)));
totlen = sh->free+sh->len; //更新总长度
}
memcpy(s, t, len); //拷贝字符串t覆盖s原有的字符串
//更新表头
s[len] = '\0';
sh->len = len;
sh->free = totlen-len;
return s;
}
/* Like sdscpylen() but 't' must be a null-termined string so that the length
* of the string is obtained with strlen(). */
sds sdscpy(sds s, const char *t) { //将字符串覆盖到s表头的buf中
return sdscpylen(s, t, strlen(t));
}
/* Helper for sdscatlonglong() doing the actual number -> string
* conversion. 's' must point to a string with room for at least
* SDS_LLSTR_SIZE bytes.
*
* The function returns the length of the null-terminated string
* representation stored at 's'. */
#define SDS_LLSTR_SIZE 21
int sdsll2str(char *s, long long value) { //将一个long long类型的value转化为字符串,返回字符串长度
char *p, aux;
unsigned long long v;
size_t l;
/* Generate the string representation, this method produces
* an reversed string. */
v = (value < 0) ? -value : value;
p = s;
do {
*p++ = '0'+(v%10);
v /= 10;
} while(v);
if (value < 0) *p++ = '-';
/* Compute length and add null term. */
l = p-s;
*p = '\0';
/* Reverse the string. */
p--;
while(s < p) {
aux = *s;
*s = *p;
*p = aux;
s++;
p--;
}
return l;
}
/* Identical sdsll2str(), but for unsigned long long type. */
int sdsull2str(char *s, unsigned long long v) {
//将一个unsigned long long类型的value转化为字符串,返回字符串长度
char *p, aux;
size_t l;
/* Generate the string representation, this method produces
* an reversed string. */
p = s;
do {
*p++ = '0'+(v%10);
v /= 10;
} while(v);
/* Compute length and add null term. */
l = p-s;
*p = '\0';
/* Reverse the string. */
p--;
while(s < p) {
aux = *s;
*s = *p;
*p = aux;
s++;
p--;
}
return l;
}
/* Create an sds string from a long long value. It is much faster than:
*
* sdscatprintf(sdsempty(),"%lld\n", value);
*/
sds sdsfromlonglong(long long value) { //根据long long value创建一个SDS
char buf[SDS_LLSTR_SIZE];
int len = sdsll2str(buf,value); //返回装换成字符串的长度
return sdsnewlen(buf,len); //创建SDS
}
/* Like sdscatprintf() but gets va_list instead of being variadic. */
sds sdscatvprintf(sds s, const char *fmt, va_list ap) { //打印函数,被 sdscatprintf 所调用
va_list cpy;
char staticbuf[1024], *buf = staticbuf, *t;
size_t buflen = strlen(fmt)*2;
/* We try to start using a static buffer for speed.
* If not possible we revert to heap allocation. */
if (buflen > sizeof(staticbuf)) {
buf = zmalloc(buflen);
if (buf == NULL) return NULL;
} else {
buflen = sizeof(staticbuf);
}
/* Try with buffers two times bigger every time we fail to
* fit the string in the current buffer size. */
while(1) {
buf[buflen-2] = '\0';
va_copy(cpy,ap);
vsnprintf(buf, buflen, fmt, cpy);
va_end(cpy);
if (buf[buflen-2] != '\0') {
if (buf != staticbuf) zfree(buf);
buflen *= 2;
buf = zmalloc(buflen);
if (buf == NULL) return NULL;
continue;
}
break;
}
/* Finally concat the obtained string to the SDS string and return it. */
t = sdscat(s, buf);
if (buf != staticbuf) zfree(buf);
return t;
}
/* Append to the sds string 's' a string obtained using printf-alike format
* specifier.
*
* After the call, the modified sds string is no longer valid and all the
* references must be substituted with the new pointer returned by the call.
*
* Example:
*
* s = sdsnew("Sum is: ");
* s = sdscatprintf(s,"%d+%d = %d",a,b,a+b).
*
* Often you need to create a string from scratch with the printf-alike
* format. When this is the need, just use sdsempty() as the target string:
*
* s = sdscatprintf(sdsempty(), "... your format ...", args);
*/
sds sdscatprintf(sds s, const char *fmt, ...) { //打印任意数量个字符串,并将这些字符串追加到给定 sds 的末尾
va_list ap;
char *t;
va_start(ap, fmt);
t = sdscatvprintf(s,fmt,ap);
va_end(ap);
return t;
}
/* This function is similar to sdscatprintf, but much faster as it does
* not rely on sprintf() family functions implemented by the libc that
* are often very slow. Moreover directly handling the sds string as
* new data is concatenated provides a performance improvement.
*
* However this function only handles an incompatible subset of printf-alike
* format specifiers:
*
* %s - C String
* %S - SDS string
* %i - signed int
* %I - 64 bit signed integer (long long, int64_t)
* %u - unsigned int
* %U - 64 bit unsigned integer (unsigned long long, uint64_t)
* %% - Verbatim "%" character.
*/
sds sdscatfmt(sds s, char const *fmt, ...) { //格式化打印多个字符串,并将这些字符串追加到给定 sds 的末尾
struct sdshdr *sh = (void*) (s-(sizeof(struct sdshdr)));
size_t initlen = sdslen(s);
const char *f = fmt;
int i;
va_list ap;
va_start(ap,fmt);
f = fmt; /* Next format specifier byte to process. */
i = initlen; /* Position of the next byte to write to dest str. */
while(*f) {
char next, *str;
unsigned int l;
long long num;
unsigned long long unum;
/* Make sure there is always space for at least 1 char. */
if (sh->free == 0) {
s = sdsMakeRoomFor(s,1);
sh = (void*) (s-(sizeof(struct sdshdr)));
}
switch(*f) {
case '%':
next = *(f+1);
f++;
switch(next) {
case 's':
case 'S':
str = va_arg(ap,char*);
l = (next == 's') ? strlen(str) : sdslen(str);
if (sh->free < l) {
s = sdsMakeRoomFor(s,l);
sh = (void*) (s-(sizeof(struct sdshdr)));
}
memcpy(s+i,str,l);
sh->len += l;
sh->free -= l;
i += l;
break;
case 'i':
case 'I':
if (next == 'i')
num = va_arg(ap,int);
else
num = va_arg(ap,long long);
{
char buf[SDS_LLSTR_SIZE];
l = sdsll2str(buf,num);
if (sh->free < l) {
s = sdsMakeRoomFor(s,l);
sh = (void*) (s-(sizeof(struct sdshdr)));
}
memcpy(s+i,buf,l);
sh->len += l;
sh->free -= l;
i += l;
}
break;
case 'u':
case 'U':
if (next == 'u')
unum = va_arg(ap,unsigned int);
else
unum = va_arg(ap,unsigned long long);
{
char buf[SDS_LLSTR_SIZE];
l = sdsull2str(buf,unum);
if (sh->free < l) {
s = sdsMakeRoomFor(s,l);
sh = (void*) (s-(sizeof(struct sdshdr)));
}
memcpy(s+i,buf,l);
sh->len += l;
sh->free -= l;
i += l;
}
break;
default: /* Handle %% and generally %<unknown>. */
s[i++] = next;
sh->len += 1;
sh->free -= 1;
break;
}
break;
default:
s[i++] = *f;
sh->len += 1;
sh->free -= 1;
break;
}
f++;
}
va_end(ap);
/* Add null-term */
s[i] = '\0';
return s;
}
/* Remove the part of the string from left and from right composed just of
* contiguous characters found in 'cset', that is a null terminted C string.
*
* After the call, the modified sds string is no longer valid and all the
* references must be substituted with the new pointer returned by the call.
*
* Example:
*
* s = sdsnew("AA...AA.a.aa.aHelloWorld :::");
* s = sdstrim(s,"Aa. :");
* printf("%s\n", s);
*
* Output will be just "Hello World".
*/
sds sdstrim(sds s, const char *cset) { //去除sds中包含有 cset字符串出现字符 的字符
struct sdshdr *sh = (void*) (s-(sizeof(struct sdshdr)));
char *start, *end, *sp, *ep;
size_t len;
//设置和备份指针位置
sp = start = s;
ep = end = s+sdslen(s)-1;
//strchr()函数功能:查找cset中首次出现*sp字符的位置,成功返回第一次出现的位置
while(sp <= end && strchr(cset, *sp)) sp++; //从左开始修剪,sp为目标串的左边界
while(ep > start && strchr(cset, *ep)) ep--; //从右开始修剪,ep为目标串的右边界
len = (sp > ep) ? 0 : ((ep-sp)+1); //目标串的长度
if (sh->buf != sp) memmove(sh->buf, sp, len); //将字符串的位置前移到buf开头
//更新表头
sh->buf[len] = '\0';
sh->free = sh->free+(sh->len-len);
sh->len = len;
return s;
}
/* Turn the string into a smaller (or equal) string containing only the
* substring specified by the 'start' and 'end' indexes.
*
* start and end can be negative, where -1 means the last character of the
* string, -2 the penultimate character, and so forth.
*
* The interval is inclusive, so the start and end characters will be part
* of the resulting string.
*
* The string is modified in-place.
*
* Example:
*
* s = sdsnew("Hello World");
* sdsrange(s,1,-1); => "ello World"
*/
void sdsrange(sds s, int start, int end) { //根据start和end区间截取字符串
struct sdshdr *sh = (void*) (s-(sizeof(struct sdshdr)));
size_t newlen, len = sdslen(s); //获得源串的长度
//1,start或end为负数的情况,转化为非负数
if (len == 0) return;
if (start < 0) { //如果start小于0,则从字符串尾部往前开始算起始位置
start = len+start;
if (start < 0) start = 0;
}
if (end < 0) { //如果start小于0,则从字符串尾部往前开始算结束位置
end = len+end;
if (end < 0) end = 0;
}
//2,start和end为非负数的情况
newlen = (start > end) ? 0 : (end-start)+1; //截取后字符串的长度
if (newlen != 0) {
if (start >= (signed)len) { //起始位置大于字符串的长度,被截取的字符串长度为0
newlen = 0;
} else if (end >= (signed)len) { //结束位置大于字符串的长度,只截取到字符串的末尾
end = len-1;
newlen = (start > end) ? 0 : (end-start)+1; //更新截取后字符串的长度
}
} else {
start = 0;
}
//通过以上两种情况计算出start和end位置,用memmove函数截取
if (start && newlen) memmove(sh->buf, sh->buf+start, newlen); //截取后,移动到buf的前面
//更新表头
sh->buf[newlen] = 0;
sh->free = sh->free+(sh->len-newlen);
sh->len = newlen;
}
/* Apply tolower() to every character of the sds string 's'. */
void sdstolower(sds s) { //将sds字符串所有字符转换为小写
int len = sdslen(s), j;
for (j = 0; j < len; j++) s[j] = tolower(s[j]); //tolower()函数将大写字符转换成小写
}
/* Apply toupper() to every character of the sds string 's'. */
void sdstoupper(sds s) { //将sds字符串所有字符转换为大写
int len = sdslen(s), j;
for (j = 0; j < len; j++) s[j] = toupper(s[j]); //toupper()函数将小字符转换成大写
}
/* Compare two sds strings s1 and s2 with memcmp().
*
* Return value:
*
* positive if s1 > s2.
* negative if s1 < s2.
* 0 if s1 and s2 are exactly the same binary string.
*
* If two strings share exactly the same prefix, but one of the two has
* additional characters, the longer string is considered to be greater than
* the smaller one. */
int sdscmp(const sds s1, const sds s2) { //比较两个sds的大小,相等返回0
size_t l1, l2, minlen;
int cmp;
l1 = sdslen(s1);
l2 = sdslen(s2);
minlen = (l1 < l2) ? l1 : l2; //
cmp = memcmp(s1,s2,minlen); //memcmp()函数比较s1和s2内存地址的前len个字节,返回s1减s2的差值
if (cmp == 0) return l1-l2; //s1长度大于s2返回正差值,否则返回负差值
return cmp;
}
/* Split 's' with separator in 'sep'. An array
* of sds strings is returned. *count will be set
* by reference to the number of tokens returned.
*
* On out of memory, zero length string, zero length
* separator, NULL is returned.
*
* Note that 'sep' is able to split a string using
* a multi-character separator. For example
* sdssplit("foo_-_bar","_-_"); will return two
* elements "foo" and "bar".
*
* This version of the function is binary-safe but
* requires length arguments. sdssplit() is just the
* same function but for zero-terminated strings.
*/
sds *sdssplitlen(const char *s, int len, const char *sep, int seplen, int *count) { //使用长度为seplen的sep分隔符对长度为len的s进行分割,返回一个sds数组的地址,*count被设置为数组元素数量
int elements = 0, slots = 5, start = 0, j;
sds *tokens;
if (seplen < 1 || len < 0) return NULL;
tokens = zmalloc(sizeof(sds)*slots); //默认sds长度为5个
if (tokens == NULL) return NULL;
if (len == 0) { //len为0,count设为0,不分割
*count = 0;
return tokens;
}
for (j = 0; j < (len-(seplen-1)); j++) { //sep和s对比(len-(seplen-1))次,
/* make sure there is room for the next element and the final one */
//如果当前字符串数组数量少于当前已存在数组+2个的时候,动态添加
if (slots < elements+2) {
sds *newtokens;
slots *= 2;
newtokens = zrealloc(tokens,sizeof(sds)*slots);
//扩展内存失败,goto语句释放内存
if (newtokens == NULL) goto cleanup;
tokens = newtokens;
}
/* search the separator */
//分成单字符比较或字符串比较匹配
if ((seplen == 1 && *(s+j) == sep[0]) || (memcmp(s+j,sep,seplen) == 0)) {
tokens[elements] = sdsnewlen(s+start,j-start); //将s分割的一段生成为SDS然后放到预先的tokens数组里
if (tokens[elements] == NULL) goto cleanup; //创建SDS失败要释放tokens数组
elements++;
start = j+seplen;
j = j+seplen-1; /* skip the separator */
}
}
/* Add the final element. We are sure there is room in the tokens array. */
//最后一个字符串添加
tokens[elements] = sdsnewlen(s+start,len-start);
if (tokens[elements] == NULL) goto cleanup; //创建SDS失败要释放tokens数组
elements++;
*count = elements;
return tokens;
cleanup: //释放内存
{
int i;
for (i = 0; i < elements; i++) sdsfree(tokens[i]);
zfree(tokens);
*count = 0;
return NULL;
}
}
/* Free the result returned by sdssplitlen(), or do nothing if 'tokens' is NULL. */
void sdsfreesplitres(sds *tokens, int count) { //释放tokens中的count个sds元素
if (!tokens) return;
while(count--)
sdsfree(tokens[count]);
zfree(tokens);
}
/* Append to the sds string "s" an escaped string representation where
* all the non-printable characters (tested with isprint()) are turned into
* escapes in the form "\n\r\a...." or "\x<hex-number>".
*
* After the call, the modified sds string is no longer valid and all the
* references must be substituted with the new pointer returned by the call. */
sds sdscatrepr(sds s, const char *p, size_t len) { //将长度为len的字符串p以带引号""的格式追加到s末尾
s = sdscatlen(s,"\"",1); //追加左引号,\是转义字符
while(len--) {
switch(*p) {
case '\\':
case '"':
s = sdscatprintf(s,"\\%c",*p);
break;
case '\n': s = sdscatlen(s,"\\n",2); break; // "\\n"是两个字符"\n"
case '\r': s = sdscatlen(s,"\\r",2); break;
case '\t': s = sdscatlen(s,"\\t",2); break;
case '\a': s = sdscatlen(s,"\\a",2); break;
case '\b': s = sdscatlen(s,"\\b",2); break;
default:
if (isprint(*p))
s = sdscatprintf(s,"%c",*p);
else
s = sdscatprintf(s,"\\x%02x",(unsigned char)*p);
break;
}
p++;
}
return sdscatlen(s,"\"",1); //追加右引号
}
/* Helper function for sdssplitargs() that returns non zero if 'c'
* is a valid hex digit. */
int is_hex_digit(char c) { //如果c是十六进制符号中的一个返回正数
return (c >= '0' && c <= '9') || (c >= 'a' && c <= 'f') ||
(c >= 'A' && c <= 'F');
}
/* Helper function for sdssplitargs() that converts a hex digit into an
* integer from 0 to 15 */
int hex_digit_to_int(char c) { //16进制字符转换为10进制整数
switch(c) {
case '0': return 0;
case '1': return 1;
case '2': return 2;
case '3': return 3;
case '4': return 4;
case '5': return 5;
case '6': return 6;
case '7': return 7;
case '8': return 8;
case '9': return 9;
case 'a': case 'A': return 10;
case 'b': case 'B': return 11;
case 'c': case 'C': return 12;
case 'd': case 'D': return 13;
case 'e': case 'E': return 14;
case 'f': case 'F': return 15;
default: return 0;
}
}
/* Split a line into arguments, where every argument can be in the
* following programming-language REPL-alike form:
*
* foo bar "newline are supported\n" and "\xff\x00otherstuff"
*
* The number of arguments is stored into *argc, and an array
* of sds is returned.
*
* The caller should free the resulting array of sds strings with
* sdsfreesplitres().
*
* Note that sdscatrepr() is able to convert back a string into
* a quoted string in the same format sdssplitargs() is able to parse.
*
* The function returns the allocated tokens on success, even when the
* input string is empty, or NULL if the input contains unbalanced
* quotes or closed quotes followed by non space characters
* as in: "foo"bar or "foo'
* 这个函数主要用于 config.c 中对配置文件进行分析。
* 例子:
* sds *arr = sdssplitargs("timeout 10086\r\nport 123321\r\n");
* 会得出
* arr[0] = "timeout"
* arr[1] = "10086"
* arr[2] = "port"
* arr[3] = "123321"
*/
sds *sdssplitargs(const char *line, int *argc) { //参数拆分,主要用于 config.c 中对配置文件进行分析。
const char *p = line;
char *current = NULL;
char **vector = NULL;
*argc = 0;
while(1) {
/* skip blanks */
while(*p && isspace(*p)) p++;
if (*p) {
/* get a token */
int inq=0; /* set to 1 if we are in "quotes" */
int insq=0; /* set to 1 if we are in 'single quotes' */
int done=0;
if (current == NULL) current = sdsempty();
while(!done) {
if (inq) {
if (*p == '\\' && *(p+1) == 'x' &&
is_hex_digit(*(p+2)) &&
is_hex_digit(*(p+3)))
{
unsigned char byte;
byte = (hex_digit_to_int(*(p+2))*16)+
hex_digit_to_int(*(p+3));
current = sdscatlen(current,(char*)&byte,1);
p += 3;
} else if (*p == '\\' && *(p+1)) {
char c;
p++;
switch(*p) {
case 'n': c = '\n'; break;
case 'r': c = '\r'; break;
case 't': c = '\t'; break;
case 'b': c = '\b'; break;
case 'a': c = '\a'; break;
default: c = *p; break;
}
current = sdscatlen(current,&c,1);
} else if (*p == '"') {
/* closing quote must be followed by a space or
* nothing at all. */
if (*(p+1) && !isspace(*(p+1))) goto err;
done=1;
} else if (!*p) {
/* unterminated quotes */
goto err;
} else {
current = sdscatlen(current,p,1);
}
} else if (insq) {
if (*p == '\\' && *(p+1) == '\'') {
p++;
current = sdscatlen(current,"'",1);
} else if (*p == '\'') {
/* closing quote must be followed by a space or
* nothing at all. */
if (*(p+1) && !isspace(*(p+1))) goto err;
done=1;
} else if (!*p) {
/* unterminated quotes */
goto err;
} else {
current = sdscatlen(current,p,1);
}
} else {
switch(*p) {
case ' ':
case '\n':
case '\r':
case '\t':
case '\0':
done=1;
break;
case '"':
inq=1;
break;
case '\'':
insq=1;
break;
default:
current = sdscatlen(current,p,1);
break;
}
}
if (*p) p++;
}
/* add the token to the vector */
vector = zrealloc(vector,((*argc)+1)*sizeof(char*));
vector[*argc] = current;
(*argc)++;
current = NULL;
} else {
/* Even on empty input string return something not NULL. */
if (vector == NULL) vector = zmalloc(sizeof(void*));
return vector;
}
}
err:
while((*argc)--)
sdsfree(vector[*argc]);
zfree(vector);
if (current) sdsfree(current);
*argc = 0;
return NULL;
}
/* Modify the string substituting all the occurrences of the set of
* characters specified in the 'from' string to the corresponding character
* in the 'to' array.
*
* For instance: sdsmapchars(mystring, "ho", "01", 2)
* will have the effect of turning the string "hello" into "0ell1".
*
* The function returns the sds string pointer, that is always the same
* as the input pointer since no resize is needed. */
sds sdsmapchars(sds s, const char *from, const char *to, size_t setlen) { //将s中所有在 from 中的字符串,替换成 to 中的字符串
size_t j, i, l = sdslen(s);
for (j = 0; j < l; j++) { //遍历s
for (i = 0; i < setlen; i++) { //遍历映射
if (s[j] == from[i]) { //替换字符串
s[j] = to[i];
break;
}
}
}
return s;
}
/* Join an array of C strings using the specified separator (also a C string).
* Returns the result as an sds string. */
sds sdsjoin(char **argv, int argc, char *sep) { //以分隔符连接字符串子数组构成新的字符串
sds join = sdsempty(); //创建一个空sds
int j;
for (j = 0; j < argc; j++) {
join = sdscat(join, argv[j]);
if (j != argc-1) join = sdscat(join,sep); //以*sep链接
}
return join;
}
参考书籍:《Redis设计与实现》——黄健翔