1 hgetCommand
1.1 方法说明
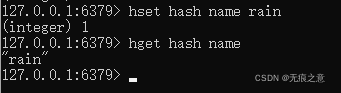
获取hash键的键值
1.2 命令实践
1.3 方法源代码
void hgetCommand(redisClient *c) {
robj *o;
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.nullbulk)) == NULL ||
checkType(c,o,REDIS_HASH)) return;
addHashFieldToReply(c, o, c->argv[2]);
}
1.4 相关源代码
1.4.1 addHashFieldToReply
static void addHashFieldToReply(redisClient *c, robj *o, robj *field) {
int ret;
//如果对象为null,返回null
if (o == NULL) {
addReply(c, shared.nullbulk);
return;
}
//如果数据结构为压缩表
if (o->encoding == REDIS_ENCODING_ZIPLIST) {
unsigned char *vstr = NULL;
unsigned int vlen = UINT_MAX;
long long vll = LLONG_MAX;
ret = hashTypeGetFromZiplist(o, field, &vstr, &vlen, &vll);
if (ret < 0) {
addReply(c, shared.nullbulk);
} else {
if (vstr) {
addReplyBulkCBuffer(c, vstr, vlen);
} else {
addReplyBulkLongLong(c, vll);
}
}
}
//如果数据额结构为哈希表
else if (o->encoding == REDIS_ENCODING_HT) {
robj *value;
ret = hashTypeGetFromHashTable(o, field, &value);
if (ret < 0) {
addReply(c, shared.nullbulk);
} else {
addReplyBulk(c, value);
}
} else {
redisPanic("Unknown hash encoding");
}
}
1.4.2 hashTypeGetFromZiplist
/* Get the value from a ziplist encoded hash, identified by field.
1. Returns -1 when the field cannot be found. */
int hashTypeGetFromZiplist(robj *o, robj *field,
unsigned char **vstr,
unsigned int *vlen,
long long *vll)
{
unsigned char *zl, *fptr = NULL, *vptr = NULL;
int ret;
redisAssert(o->encoding == REDIS_ENCODING_ZIPLIST);
field = getDecodedObject(field);
zl = o->ptr;
//获取压缩表头部的位置
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) {
//先找到键的位置
fptr = ziplistFind(fptr, field->ptr, sdslen(field->ptr), 1);
if (fptr != NULL) {
/* Grab pointer to the value (fptr points to the field) */
//获取下一个位置的指针
vptr = ziplistNext(zl, fptr);
redisAssert(vptr != NULL);
}
}
decrRefCount(field);
if (vptr != NULL) {
//根据值的指针获取值
ret = ziplistGet(vptr, vstr, vlen, vll);
redisAssert(ret);
return 0;
}
return -1;
}
1.4.3 hashTypeGetFromHashTable
/* Get the value from a hash table encoded hash, identified by field.
2. Returns -1 when the field cannot be found. */
int hashTypeGetFromHashTable(robj *o, robj *field, robj **value) {
dictEntry *de;
redisAssert(o->encoding == REDIS_ENCODING_HT);
de = dictFind(o->ptr, field);
if (de == NULL) return -1;
*value = dictGetVal(de);
return 0;
}
1.5 代码理解
1、 先获取键对象,并判断对象类型是否为hash;
2、 调用addHashFieldToReply方法获取某个键的值;
3、 判断数据结构是压缩表还是哈希表;
4、 如果是压缩表,则调用压缩表相关方法获取某个键的值;
5、 如果是哈希表,则调用哈希表相关方法获取某个键的值;
这里面主要方法是 hashTypeGetFromZiplist 和 hashTypeGetFromHashTable,都是根据键来获取值,不同的是两者数据结构不同,所以获取值的逻辑也大不一样。
hashTypeGetFromZiplist 要先获取键的位置,再来根据键的位置通过 ziplistNext 获取下一个位置的指针,在用这个新位置的指针通过 ziplistGet 获取值,从代码大概能看出来压缩表所有的值是紧凑挨在一起的,类似数组一样,具体详细内容等后面学习到压缩表的专门代码文件的时候再仔细研究。
hashTypeGetFromHashTable 相对来说就简单明了一点,直接使用键通过 dictFind 找到指针,在通过dictGetVal找到相应地值就可以。
2 genericHgetallCommand
2.1 方法说明
这个方法是hgetall、hvals、hkeys 的通用方法。
2.2 方法源代码
void genericHgetallCommand(redisClient *c, int flags) {
robj *o;
hashTypeIterator *hi;
int multiplier = 0;
int length, count = 0;
//获取键对象,并判断对象类型是否为hash类型
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.emptymultibulk)) == NULL
|| checkType(c,o,REDIS_HASH)) return;
//如果标记是key,则加一
if (flags & REDIS_HASH_KEY) multiplier++;
//如果标记是value,则加一
if (flags & REDIS_HASH_VALUE) multiplier++;
//计算结果值个数
length = hashTypeLength(o) * multiplier;
addReplyMultiBulkLen(c, length);
//初始化迭代对象
hi = hashTypeInitIterator(o);
//从头部向后面遍历hash元素
while (hashTypeNext(hi) != REDIS_ERR) {
if (flags & REDIS_HASH_KEY) {
addHashIteratorCursorToReply(c, hi, REDIS_HASH_KEY);
count++;
}
if (flags & REDIS_HASH_VALUE) {
addHashIteratorCursorToReply(c, hi, REDIS_HASH_VALUE);
count++;
}
}
//释放迭代器
hashTypeReleaseIterator(hi);
redisAssert(count == length);
}
2.3 相关源代码
2.3.1 hashTypeInitIterator
hashTypeIterator *hashTypeInitIterator(robj *subject) {
hashTypeIterator *hi = zmalloc(sizeof(hashTypeIterator));
hi->subject = subject;
hi->encoding = subject->encoding;
if (hi->encoding == REDIS_ENCODING_ZIPLIST) {
hi->fptr = NULL;
hi->vptr = NULL;
} else if (hi->encoding == REDIS_ENCODING_HT) {
hi->di = dictGetIterator(subject->ptr);
} else {
redisPanic("Unknown hash encoding");
}
return hi;
}
2.3.2 hashTypeNext
/* Move to the next entry in the hash. Return REDIS_OK when the next entry
* could be found and REDIS_ERR when the iterator reaches the end. */
int hashTypeNext(hashTypeIterator *hi) {
if (hi->encoding == REDIS_ENCODING_ZIPLIST) {
unsigned char *zl;
unsigned char *fptr, *vptr;
zl = hi->subject->ptr;
fptr = hi->fptr;
vptr = hi->vptr;
if (fptr == NULL) {
/* Initialize cursor */
redisAssert(vptr == NULL);
fptr = ziplistIndex(zl, 0);
} else {
/* Advance cursor */
redisAssert(vptr != NULL);
fptr = ziplistNext(zl, vptr);
}
if (fptr == NULL) return REDIS_ERR;
/* Grab pointer to the value (fptr points to the field) */
vptr = ziplistNext(zl, fptr);
redisAssert(vptr != NULL);
/* fptr, vptr now point to the first or next pair */
hi->fptr = fptr;
hi->vptr = vptr;
} else if (hi->encoding == REDIS_ENCODING_HT) {
if ((hi->de = dictNext(hi->di)) == NULL) return REDIS_ERR;
} else {
redisPanic("Unknown hash encoding");
}
return REDIS_OK;
}
2.3.3 addHashIteratorCursorToReply
static void addHashIteratorCursorToReply(redisClient *c, hashTypeIterator *hi, int what) {
//如果是压缩表
if (hi->encoding == REDIS_ENCODING_ZIPLIST) {
unsigned char *vstr = NULL;
unsigned int vlen = UINT_MAX;
long long vll = LLONG_MAX;
//从压缩表中获取当前位置值
hashTypeCurrentFromZiplist(hi, what, &vstr, &vlen, &vll);
if (vstr) {
addReplyBulkCBuffer(c, vstr, vlen);
} else {
addReplyBulkLongLong(c, vll);
}
}
//如果是哈希表
else if (hi->encoding == REDIS_ENCODING_HT) {
robj *value;
//从哈希表中获取当前位置的值
hashTypeCurrentFromHashTable(hi, what, &value);
addReplyBulk(c, value);
} else {
redisPanic("Unknown hash encoding");
}
}
2.3.4 hashTypeCurrentFromZiplist
/* Get the field or value at iterator cursor, for an iterator on a hash value
* encoded as a ziplist. Prototype is similar to hashTypeGetFromZiplist. */
void hashTypeCurrentFromZiplist(hashTypeIterator *hi, int what,
unsigned char **vstr,
unsigned int *vlen,
long long *vll)
{
int ret;
redisAssert(hi->encoding == REDIS_ENCODING_ZIPLIST);
if (what & REDIS_HASH_KEY) {
ret = ziplistGet(hi->fptr, vstr, vlen, vll);
redisAssert(ret);
} else {
ret = ziplistGet(hi->vptr, vstr, vlen, vll);
redisAssert(ret);
}
}
2.3.5 hashTypeCurrentFromHashTable
/* Get the field or value at iterator cursor, for an iterator on a hash value
* encoded as a ziplist. Prototype is similar to hashTypeGetFromHashTable. */
void hashTypeCurrentFromHashTable(hashTypeIterator *hi, int what, robj **dst) {
redisAssert(hi->encoding == REDIS_ENCODING_HT);
if (what & REDIS_HASH_KEY) {
*dst = dictGetKey(hi->de);
} else {
*dst = dictGetVal(hi->de);
}
}
2.4 代码理解
1、 获取键对象,并判断对象类型是否为hash类型;
2、 计算要遍历的结果值长度;
3、 初始化迭代对象;
4、 从头部向后面遍历hash元素;
5、 释放迭代器;
这里面的主要获取值的方法是 hashTypeCurrentFromZiplist 和 hashTypeCurrentFromHashTable,通过看代码和上面的注释可以看出来这两个方法和上面我们刚学习的 hashTypeGetFromZiplist 和 hashTypeGetFromHashTable 高度相似,核心不同点是前者是已知指针位置直接通过当前指针获取值就可以,后者要先根据键的位置找到键的指针,再来获取值。
根据这个方法的参数和逻辑可以看出来,这个方法可以根据传入的flag来查找键、值、或者键值,刚好也就对应了hkeys、hvals、hgetall三个方法,发现redis中很多参数之间都是用这种二进制的 与或 来做判断,是一种不错的实践方法。
3 hkeysCommand
3.1 方法说明
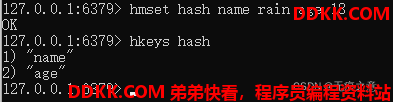
获取一个hash的所有键
3.2 命令实践
3.3 命令源代码
void hkeysCommand(redisClient *c) {
genericHgetallCommand(c,REDIS_HASH_KEY);
}
3.4 代码理解
直接调用了 genericHgetallCommand 方法,并传入了REDIS_HASH_KEY,来表示只获取键。
4 hvalsCommand
4.1 方法说明
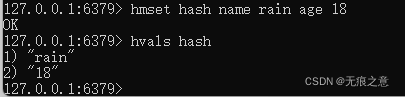
获取一个hash的所有值
4.2 命令实践
4.3 方法源代码
void hvalsCommand(redisClient *c) {
genericHgetallCommand(c,REDIS_HASH_VALUE);
}
直接调用了 genericHgetallCommand 方法,并传入了REDIS_HASH_VALUE,来表示只获取值。
5 hvalsCommand
5.1 方法说明
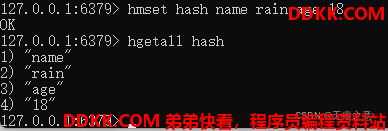
获取一个hash的所有键和值
5.2 命令实践
5.3 方法源代码
void hgetallCommand(redisClient *c) {
genericHgetallCommand(c,REDIS_HASH_KEY|REDIS_HASH_VALUE);
}
直接调用了 genericHgetallCommand 方法,并传入了REDIS_HASH_KEY|REDIS_HASH_VALUE,来表示只获取键和值,这里就可以看到使用二进制运算的便捷性。
6 总结
1、 有hashType前缀的方法,里面都包含了两种数据结构的处理逻辑;
2、 hgetall、hvals、hkeys三个命令都会调用genericHgetallCommand方法;
3、 hashTypeGetFromZiplist和hashTypeGetFromHashTable先根据键找到键的位置,再来获取值;
4、 hashTypeCurrentFromZiplist和hashTypeCurrentFromHashTable直接根据当前位置获取值;
5、 有标记逻辑的时候,都会使用二进制运算来控制,并且这些枚举值都是01248之类;