学习完 t_string.c、t_list.c、t_hash.c、t_set.c 源代码之后,终于来到了五种数据类型最后的环节有序集合,对应的源代码是 t_zset.c,,我估略看了下这个文件的代码,不仅代码量比之前的几个文件多,而且复杂程度也比之前高,不过我们一路走过来相当不容易,马上就到成功的终点,不能在这最后一步就退缩了,兄弟们加油,一鼓作气冲过去。
1 前言
1.1 原文注释
这回不同以往直接上来就看代码,先看一段作者的注释说明,在 t_zset.c中作者的注释是比较多的,可见晦涩程度比较高。
/*-----------------------------------------------------------------------------
* Sorted set API
*----------------------------------------------------------------------------*/
/* ZSETs are ordered sets using two data structures to hold the same elements
* in order to get O(log(N)) INSERT and REMOVE operations into a sorted
* data structure.
*
* The elements are added to a hash table mapping Redis objects to scores.
* At the same time the elements are added to a skip list mapping scores
* to Redis objects (so objects are sorted by scores in this "view"). */
/* This skiplist implementation is almost a C translation of the original
* algorithm described by William Pugh in "Skip Lists: A Probabilistic
* Alternative to Balanced Trees", modified in three ways:
* a) this implementation allows for repeated scores.
* b) the comparison is not just by key (our 'score') but by satellite data.
* c) there is a back pointer, so it's a doubly linked list with the back
* pointers being only at "level 1". This allows to traverse the list
* from tail to head, useful for ZREVRANGE. */
1.2 大致翻译
zset是使用两个数据结构来保存相同元素的有序集为了得到O(log(N))的INSERT和REMOVE操作到一个排序数据结构。
1、 元素被添加到一个映射Redis对象到分数的哈希表中;
2、 同时元素被添加到一个跳跃列表映射分数;
3、 到Redis对象(所以对象在这个“视图”中按分数排序);
这个skiplist实现几乎是原始版本的C翻译William Pugh在《跳跃列表:A probability》中描述的算法平衡树的替代品”,修改了三种方式:
1、 该实现允许重复分数;
2、 比较不仅仅是通过关键(我们的“分数”),而是通过卫星数据;
3、 有一个反向指针,所以它是一个具有反向的双向链表,指针仅在“级别1”这允许遍历列表从尾到头,适用于ZREVRANGE;
1.3 注释理解
看完上面作者写的注释,我个人理解是有序集合为了达到一个好的查询和遍历的效率,同时使用了两种数据结构来存储有序集合,这里是同时使用两种,不同以往那些数据类型是用两种实现。下面一大段是说作者引用原版的跳跃表的代码,并为了支持一些扩展做了些许修改。
2 zaddCommand
2.1 方法说明
向一个有序集合中增加或修改元素和分值。
之前我一直以为这个命令就这么简单的使用方法,不料今天看了源代码怎么发现一大堆逻辑,才发现这个命令还可以在key后面使用可选参数,以此来达到更多的功能,也不知道作者煞费苦心实现这个功能用的人多不多。
- xx:如果元素存在,则进行添加或修改成员
- nx:如果元素不存在,则进行添加或修改成员
- ch:将返回值变为修改的数量,之前是返回添加成员的数量
- incr:对一个成员进行加法操作
2.2 命令实践
2.2.1 简单用法
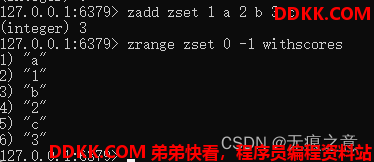
添加成员成功会返回添加成员的数量,这里需要注意的是分值在元素前面,否则会报错。
2.2.2 带nx参数
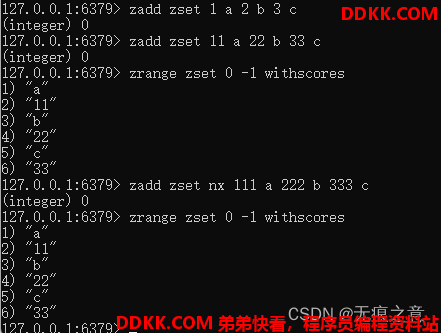
- 可以看到第一次直接再次加入相同的元素和分值,返回0,因为没有新增元素。
- 第二次修改了分值,但返回的还是0,说明返回的事新增成员的数量,使用zrange命令可以看到分值确实被修改了。
- 第三次加上了nx参数,发现分值并没有被修改,代表如果值如果不存在才能进行修改和新增操作。
2.2.3 带xx参数
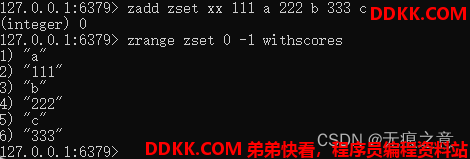
既然nx修改不了,我们就试试xx参数,可以看到换了xx之后,分值被修改了,表示使用xx参数的时候,只有成员存在才能进行修改,这样其实说明带了这个参数就无法新增成员了。
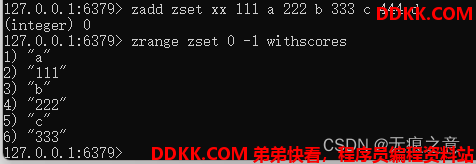
可以看到使用了xx参数之后,无法新增成员。
2.2.4 带ch参数

1、 方便测试,先把原有的有序集合删除了,重新来一遍;
2、 先加入3个成员,返回的是3,代表新增3个成员;
3、 再用相同的命令,返回的是0,表示没有新增成员;
4、 这回带上ch参数,因为没有发生变化,所以返回的是0;
5、 最后一次,将所有成员的分值修改,可以看到这次返回的是3,代表有3个成员被修改;
2.2.5 带incr参数

- 新增3个成员,并查看成员和分值。
- 使用incr参数修改a成员的分值,可以看到返回结果为修改后a成员的分值。
- 查看修改后的成员和分值,可以看到a的分值确实增加了10。
2.3 方法源代码
//zadd命令,直接调用 zaddGenericCommand
void zaddCommand(redisClient *c) {
zaddGenericCommand(c,ZADD_NONE);
}
//zincrby命令,直接调用 zaddGenericCommand
void zincrbyCommand(redisClient *c) {
zaddGenericCommand(c,ZADD_INCR);
}
//几个可选参数的宏定义
/* This generic command implements both ZADD and ZINCRBY. */
#define ZADD_NONE 0
#define ZADD_INCR (1<<0) /* Increment the score instead of setting it. */
#define ZADD_NX (1<<1) /* Don't touch elements not already existing. */
#define ZADD_XX (1<<2) /* Only touch elements already exisitng. */
#define ZADD_CH (1<<3) /* Return num of elements added or updated. */
void zaddGenericCommand(redisClient *c, int flags) {
//错误提示,分值不是一个数字
static char *nanerr = "resulting score is not a number (NaN)";
//获取键值
robj *key = c->argv[1];
robj *ele;
robj *zobj;
robj *curobj;
double score = 0, *scores = NULL, curscore = 0.0;
int j, elements;
int scoreidx = 0;
/* The following vars are used in order to track what the command actually
* did during the execution, to reply to the client and to trigger the
* notification of keyspace change. */
int added = 0; /* Number of new elements added. */
int updated = 0; /* Number of elements with updated score. */
int processed = 0; /* Number of elements processed, may remain zero with
options like XX. */
/* Parse options. At the end 'scoreidx' is set to the argument position
* of the score of the first score-element pair. */
//判断可选参数,并设置可选参数标记
//出现一个,并增加scoreidx值。
scoreidx = 2;
while(scoreidx < c->argc) {
char *opt = c->argv[scoreidx]->ptr;
if (!strcasecmp(opt,"nx")) flags |= ZADD_NX;
else if (!strcasecmp(opt,"xx")) flags |= ZADD_XX;
else if (!strcasecmp(opt,"ch")) flags |= ZADD_CH;
else if (!strcasecmp(opt,"incr")) flags |= ZADD_INCR;
else break;
scoreidx++;
}
//赋值可选参数值
/* Turn options into simple to check vars. */
int incr = (flags & ZADD_INCR) != 0;
int nx = (flags & ZADD_NX) != 0;
int xx = (flags & ZADD_XX) != 0;
int ch = (flags & ZADD_CH) != 0;
/* After the options, we expect to have an even number of args, since
* we expect any number of score-element pairs. */
//判断成员和分值是否成对出现
elements = c->argc-scoreidx;
if (elements % 2) {
addReply(c,shared.syntaxerr);
return;
}
//计算成员的数量
elements /= 2; /* Now this holds the number of score-element pairs. */
//看nx和xx是否同时使用,如果同时使用抛出错误。
/* Check for incompatible options. */
if (nx && xx) {
addReplyError(c,
"XX and NX options at the same time are not compatible");
return;
}
//如果使用了incr命令,则成员数量不能超过1个
if (incr && elements > 1) {
addReplyError(c,
"INCR option supports a single increment-element pair");
return;
}
/* Start parsing all the scores, we need to emit any syntax error
* before executing additions to the sorted set, as the command should
* either execute fully or nothing at all. */
//判断每个分值是否为double类型
//并把分值放到一个数组中
scores = zmalloc(sizeof(double)*elements);
for (j = 0; j < elements; j++) {
if (getDoubleFromObjectOrReply(c,c->argv[scoreidx+j*2],&scores[j],NULL)
!= REDIS_OK) goto cleanup;
}
/* Lookup the key and create the sorted set if does not exist. */
//获取有序集合对象
zobj = lookupKeyWrite(c->db,key);
//如果不存在则创建一个默认对象
if (zobj == NULL) {
//如果没有对象,并且有xx标记,则啥都不干,直接返回
if (xx) goto reply_to_client; /* No key + XX option: nothing to do. */
//如果添加的成员超过压缩表配置,则创建一个有序集合对象
if (server.zset_max_ziplist_entries == 0 ||
server.zset_max_ziplist_value < sdslen(c->argv[scoreidx+1]->ptr))
{
zobj = createZsetObject();
}
//否则使用压缩表来创建一个有序集合对象
else {
zobj = createZsetZiplistObject();
}
//向字典中添加这个对象
dbAdd(c->db,key,zobj);
} else {
//如果对象类型不是有序集合,则报错
if (zobj->type != REDIS_ZSET) {
addReply(c,shared.wrongtypeerr);
goto cleanup;
}
}
//遍历成员和分值
for (j = 0; j < elements; j++) {
//获取当前分值
score = scores[j];
//如果数据结构是压缩表
if (zobj->encoding == REDIS_ENCODING_ZIPLIST) {
unsigned char *eptr;
/* Prefer non-encoded element when dealing with ziplists. */
ele = c->argv[scoreidx+1+j*2];
if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) {
if (nx) continue;
if (incr) {
score += curscore;
if (isnan(score)) {
addReplyError(c,nanerr);
goto cleanup;
}
}
/* Remove and re-insert when score changed. */
//当成员分值修改的时候,删除原来的分值,并插入新的分值
if (score != curscore) {
zobj->ptr = zzlDelete(zobj->ptr,eptr);
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
server.dirty++;
updated++;
}
processed++;
} else if (!xx) {
/* Optimize: check if the element is too large or the list
* becomes too long *before* executing zzlInsert. */
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
if (zzlLength(zobj->ptr) > server.zset_max_ziplist_entries)
zsetConvert(zobj,REDIS_ENCODING_SKIPLIST);
if (sdslen(ele->ptr) > server.zset_max_ziplist_value)
zsetConvert(zobj,REDIS_ENCODING_SKIPLIST);
server.dirty++;
added++;
processed++;
}
}
//如果数据结构是压缩表
else if (zobj->encoding == REDIS_ENCODING_SKIPLIST) {
zset *zs = zobj->ptr;
zskiplistNode *znode;
dictEntry *de;
ele = c->argv[scoreidx+1+j*2] =
tryObjectEncoding(c->argv[scoreidx+1+j*2]);
de = dictFind(zs->dict,ele);
if (de != NULL) {
if (nx) continue;
curobj = dictGetKey(de);
curscore = *(double*)dictGetVal(de);
if (incr) {
score += curscore;
if (isnan(score)) {
addReplyError(c,nanerr);
/* Don't need to check if the sorted set is empty
* because we know it has at least one element. */
goto cleanup;
}
}
/* Remove and re-insert when score changed. We can safely
* delete the key object from the skiplist, since the
* dictionary still has a reference to it. */
* //当成员分值修改的时候,删除原来的分值,并插入新的分值
if (score != curscore) {
redisAssertWithInfo(c,curobj,zslDelete(zs->zsl,curscore,curobj));
znode = zslInsert(zs->zsl,score,curobj);
incrRefCount(curobj); /* Re-inserted in skiplist. */
dictGetVal(de) = &znode->score; /* Update score ptr. */
server.dirty++;
updated++;
}
processed++;
}
//如果没有使用xx标记,并且没有找到成员,则新增成员
else if (!xx) {
znode = zslInsert(zs->zsl,score,ele);
incrRefCount(ele); /* Inserted in skiplist. */
redisAssertWithInfo(c,NULL,dictAdd(zs->dict,ele,&znode->score) == DICT_OK);
incrRefCount(ele); /* Added to dictionary. */
server.dirty++;
added++;
processed++;
}
} else {
redisPanic("Unknown sorted set encoding");
}
}
//回复操作
//如果使用了incr标记,则返回修改后的分值。
//如果使用了ch标记,则返回新增和修改的成员数量。
reply_to_client:
if (incr) {
/* ZINCRBY or INCR option. */
if (processed)
addReplyDouble(c,score);
else
addReply(c,shared.nullbulk);
} else {
/* ZADD. */
addReplyLongLong(c,ch ? added+updated : added);
}
// 结束操作
cleanup:
zfree(scores);
if (added || updated) {
signalModifiedKey(c->db,key);
notifyKeyspaceEvent(REDIS_NOTIFY_ZSET,
incr ? "zincr" : "zadd", key, c->db->id);
}
}
2.4 代码理解
这一个方法着实有点长和混乱,如果不能静下心来慢慢看,真的很容易就直接撂挑子不看了,啥乱七八糟的,不过我们还是要沉着冷静,慢慢看。
首先可以看到 zaddCommand 和 zincrbyCommand 两个方法都是调用了 zaddGenericCommand,只不过传入了不同的参数,所以我们重点研究下 zaddGenericCommand 这个方法即可,经过半天的仔细阅读梳理出他大概做了以下一些事情。
1、 解析可选参数,并设置可选参数标记,用于后续各种判断逻辑;
2、 判断成员和分值是否成对出现,并计算成员的数量;
3、 判断nx和xx是否同时使用;
4、 判断使用Incr的时候,成员数量是否超过1个;
5、 获取有序集合对象,如果不存在则创建一个有序集合对象,默认使用压缩表来实现;
6、 如果存在的话,则判断对象类型是否为有序集合类型;
7、 遍历成员和分值,如果是压缩表则调用压缩表相关方法,对成员和分值进行新增和修改;
8、 如果是跳跃表则调用跳跃表相关方法,对成员和分值进行新增和修改;
9、 进行响应操作,根据不同的可选参数,返回不同的结果;
10、 进行结束操作,标记键被修改,触发通知事件;
虽然代码有点多,但是核心思想和套路和之前的那些代码差不多,如果仔细阅读和学习了之前的代码,读这一大段应该还是可以勉强理解的,但倘若一上来学习有序集合读这一大段估计够呛很容易劝退。
通过代码可以发现有序集合也使用了两种数据结构来实现,一种是一压缩表碰到好几次已经是老熟人了,一种是跳跃表。在使用跳跃表的同时,还会使用字典来保存成员和分值,以此来保证性能和效率。
3 总结
1、 有序集合使用了两种数据结构来实现,一种是压缩表,一种是跳跃表;
2、 使用跳跃表的时候,还会使用字典来保存分值;
3、 使用zadd命令的时候,分值在前面,成员在后面;
4、 zadd命令有几个可选参数nx、xx、ch、incr;
5、 可选参数nx和xx不能同时使用;
6、 可选参数incr真能用于一个成员;
7、 zadd命令和zincrby命令都是调用了zaddGenericCommand这个方法;
8、 zadd命令的返回结果会根据可选参数的不同而不同;