Springboot: 2.1.7.RELEASE
SpringCloud: Greenwich.SR2
1. Pinpoint概述
Pinpoint是一个由韩国人编写的为大型分布式系统服务的链路跟踪平台,并提供大量链路跟踪数据分析汇总解决方案。自2012年7月开始开发,与2015年1月做为一个开源项目推出。
2. Pinpoint主要特性
- 分布式事务跟踪,跟踪跨分布式应用的消息。
- 自动检测应用拓扑,帮助你搞清楚应用的架构。
- 水平扩展以便支持大规模服务器集群。
- 提供代码级别的可见性以便轻松定位失败点和瓶颈。
- 使用字节码增强技术,添加新功能而无需修改代码。
3. Pinpoint优势
- 无入侵:采用字节码增强技术,新增功能无需修改代码。
- 性能高:对性能的影响非常小(资源使用量最小仅增加3%),异步数据传输,采用UDP协议让出网络连接优先级。
4. Pinpoint架构简介
先看一下官方提供的架构图,如图:
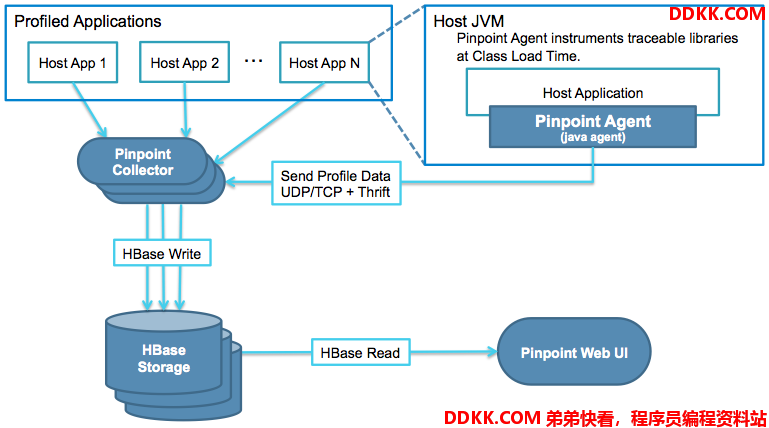
Pinpoint主要包含了4个组件:
- Pinpoint Agent:探针,附加到用于分析的Java服务
- Pinpoint Collector:数据收集组件,部署在Web容器上
- Pinpoint Web UI:数据展示组件,部署在Web容器上
- HBase Storage:数据存储组件
架构图从上往下看,首先是通过Agent组件收集需要的数据,通过UPD/TCP的方式将数据发送给Collector,由Collector将数据分析整理过后存入HBase,通过Web UI组件将分析好的数据从HBase中读出,展示在现代化的UI界面上。
5. Pinpoint数据结构简介
Pinpoint中,核心数据结构由Span, Trace, 和 TraceId组成。
-
Span: RPC (远程过程调用/remote procedure call)跟踪的基本单元; 当一个RPC调用到达时指示工作已经处理完成并包含跟踪数据。为了确保代码级别的可见性,Span拥有带SpanEvent标签的子结构作为数据结构。每个Span包含一个TraceId。
-
Trace: 多个Span的集合; 由关联的RPC (Spans)组成. 在同一个trace中的span共享相同的TransactionId。Trace通过SpanId和ParentSpanId整理为继承树结构.
-
TraceId: 由 TransactionId, SpanId, 和 ParentSpanId 组成的key的集合. TransactionId 指明消息ID,而SpanId 和 ParentSpanId 表示RPC的父-子关系。
-
TransactionId (TxId): 在分布式系统间单个事务发送/接收的消息的ID; 必须跨整个服务器集群做到全局唯一.
-
SpanId: 当收到RPC消息时处理的工作的ID; 在RPC请求到达节点时生成。
-
ParentSpanId (pSpanId): 发起RPC调用的父span的SpanId. 如果节点是事务的起点,这里将没有父span – 对于这种情况, 使用值-1来表示这个span是事务的根span。
6. Pinpoint版本依赖
- Pinpoint所需要的Java版本兼容:
| Pinpoint Version | Agent | Collector | Web |
|---|---|---|---|
| 1.0.x | 6-8 | 6-8 | 6-8 |
| 1.1.x | 6-8 | 7-8 | 7-8 |
| 1.5.x | 6-8 | 7-8 | 7-8 |
| 1.6.x | 6-8 | 7-8 | 7-8 |
| 1.7.x | 6-8 | 8 | 8 |
| 1.8.0 | 6-10 | 8 | 8 |
| 1.8.1+ | 6-11 | 8 | 8 |
- HBase所需要的版本兼容
| Pinpoint Version | HBase 0.94.x | HBase 0.98.x | HBase 1.0.x | HBase 1.2.x | HBase 2.0.x |
|---|---|---|---|---|---|
| 1.0.x | yes | no | no | no | no |
| 1.1.x | no | not tested | yes | not tested | no |
| 1.5.x | no | not tested | yes | not tested | no |
| 1.6.x | no | not tested | not tested | yes | no |
| 1.7.x | no | not tested | not tested | yes | no |
| 1.8.x | no | not tested | not tested | yes | no |
| Pinpoint Version | HBase 0.94.x | HBase 0.98.x | HBase 1.0.x | HBase 1.2.x | HBase 2.0.x |
- Agent – Collector所需要的版本兼容
| Agent Version | Collector 1.0.x | Collector 1.1.x | Collector 1.5.x | Collector 1.6.x | Collector 1.7.x | Collector 1.8.x |
|---|---|---|---|---|---|---|
| 1.0.x | yes | yes | yes | yes | yes | yes |
| 1.1.x | not tested | yes | yes | yes | yes | yes |
| 1.5.x | no | no | yes | yes | yes | yes |
| 1.6.x | no | no | not tested | yes | yes | yes |
| 1.7.x | no | no | no | no | yes | yes |
| 1.8.x | no | no | no | no | no | yes |
| Agent Version | Collector 1.0.x | Collector 1.1.x | Collector 1.5.x | Collector 1.6.x | Collector 1.7.x | Collector 1.8.x |
- Flink所需要的版本兼容
| Pinpoint Version | fLink1.3.X | fLink1.4.X | fLink1.5.X | fLink1.6.X | fLink1.7.X | Pinpoint Version |
|---|---|---|---|---|---|---|
| 1.7.x | yes | yes | no | no | no | 1.7.x |
| 1.8.x | yes | yes | no | no | no | 1.8.x |
| 1.9.x | yes | yes | yes | yes | yes | 1.9.x |
| Pinpoint Version | fLink1.3.X | fLink1.4.X | fLink1.5.X | fLink1.6.X | fLink1.7.X | Pinpoint Version |
| 1.7.x | yes | yes | no | no | no | 1.7.x |
| 1.8.x | yes | yes | no | no | no | 1.8.x |
| 1.9.x | yes | yes | yes | yes | yes | 1.9.x |
7. Spring Cloud与Pinpoint实战
在介绍实战之前,我们先介绍一下Pinpoint部署构建。
笔者构建的一些前置条件:
java:1.8
CentOS:7.6
1、 HBase部署;
存储方式需要使用HBase1.2.x的版本,笔者这里选择的是HBase1.2.6,下载地址为Apache官网,推荐使用有端点续传功能的下载器下载(实在是有点慢),HBase全版本下载地址:http://archive.apache.org/dist/hbase/ ,各位读者选择自己喜欢的版本下载。
下载完成后,将HBase1.2.6放入CentOS的opt目录中,执行如下命令:
tar -xvzf hbase-1.2.6-bin.tar.gz
mv hbase-1.2.6/ /data/service/hbase/
修改hbase中config目录中的JAVA_HOME,将这里的JAVA_HOME修改为自己本地的路径,笔者这里修改如下:
export JAVA_HOME=/opt/jdk1.8.0_221
修改完成后就可以进入hbase的bin目录,启动hbase了,执行如下语句:
./start-hbase.sh
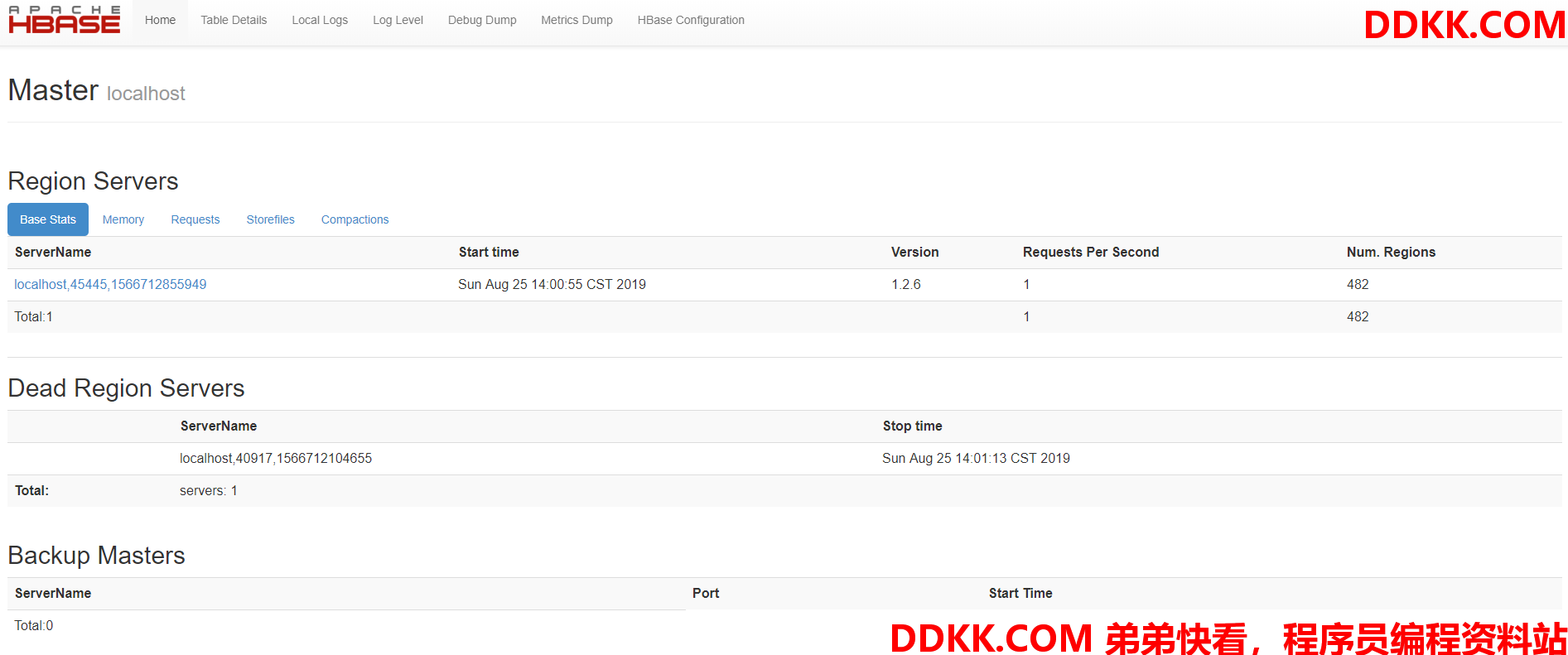
启动成功后,可以执行jps,如果看到有HMaster,可有证明启动成功,如下:
19263 HMaster
也可以打开浏览器访问:http://ip:16010/master-status ,结果如图:
接下来我们先把Pinpoint的HBase的构建脚本导入,进入HBase的bin目录下执行如下语句:
./hbase shell /opt/hbase-create.hbase
数据导入成功我们在HBase的UI界面上可以看到,如图:
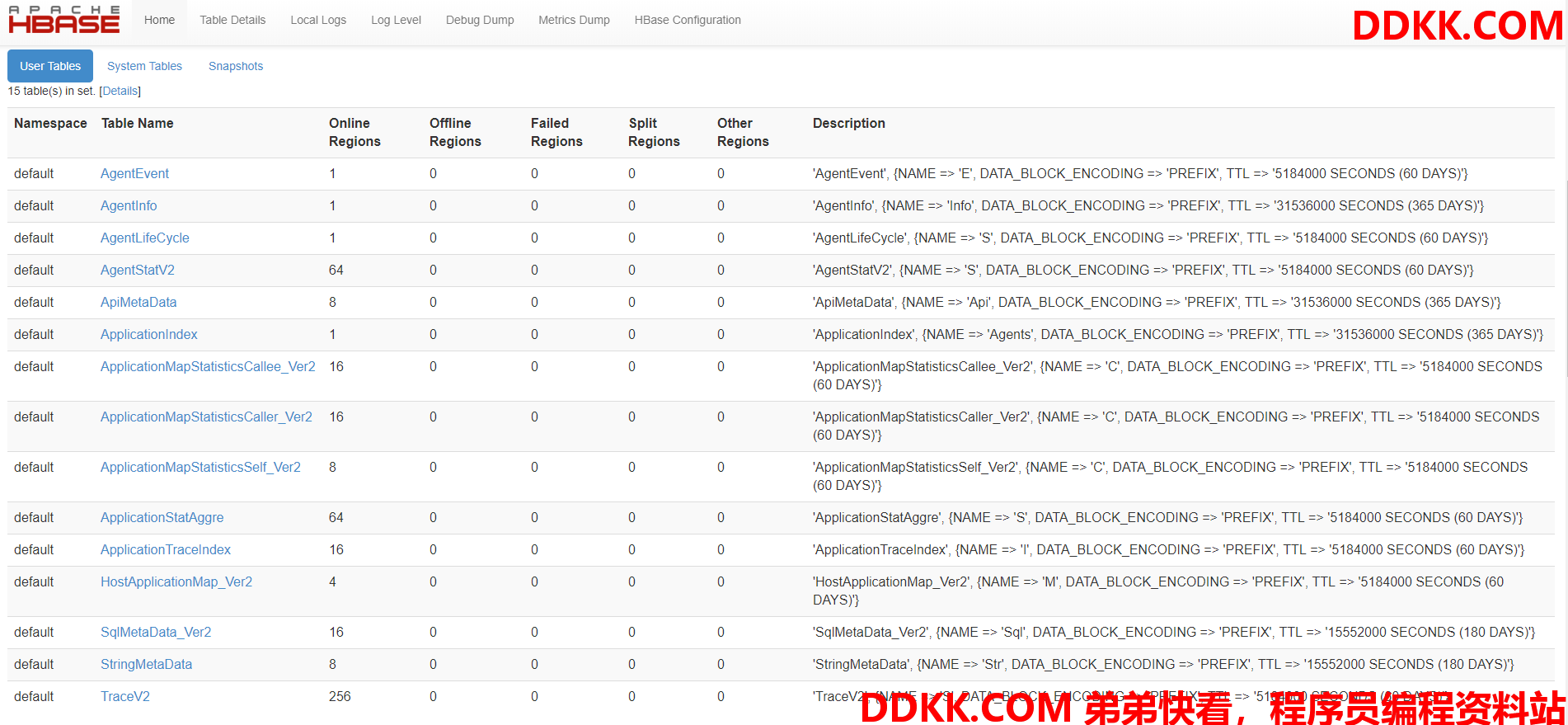
后面的目录是笔者用来存放HBase初始化脚本的路径,各位读者可根据情况自行替换,至此,HBase环境准备完成,接下来开始部署Collector和Web UI。
1、 Collector和WebUI部署;
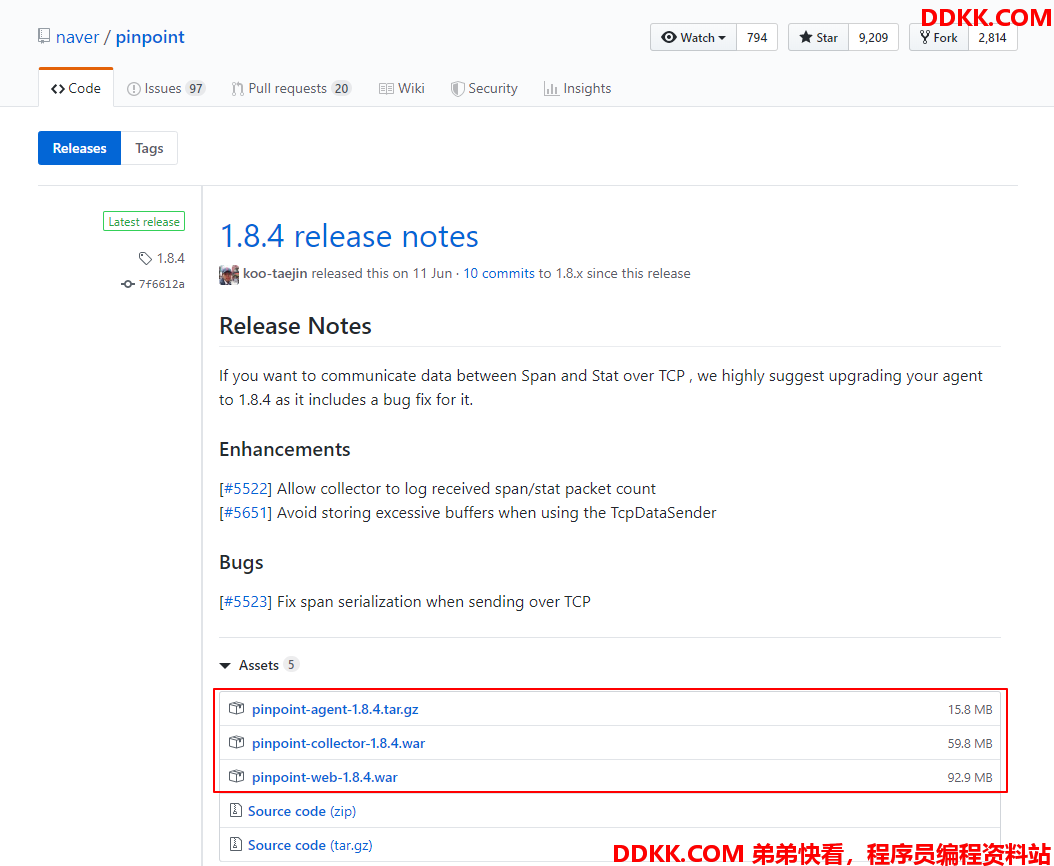
出于简单方便考虑,不推荐初学者自行编译代码进行部署,可以直接使用官方提供的发行版本进行部署。
浏览器访问链接:https://github.com/naver/pinpoint/releases/ ,直接下载当前最新Release版本即可,笔者现在看到的最新版本是1.8.4,如图,需要下载的内容有pinpoint-agent-1.8.4.tar.gz、pinpoint-collector-1.8.4.war和pinpoint-web-1.8.4.war。
首先需要准备两个tomcat,笔者这里下载的tomcat8,解压两份后并重命名为apache-tomcat-pinpoint-collector和apache-tomcat-pinpoint-web。
将apache-tomcat-pinpoint-collector中的config中的server.xml进行修改。
将8005改成18005,8080改成18080,8443改为18443,8009改为18009。
同样也将apache-tomcat-pinpoint-web中的config中的server.xml进行修改。
将8005改成28005,8080改成28080,8443改为28443,8009改为28009。
将apache-tomcat-pinpoint-collector中的webapp/ROOT清空,将pinpoint-collector-1.8.4.war放入并解压。解压完成后就可以进入bin目录使用./startup.sh启动tomcat了,并且使用命令tail -f ../logs/catalina.out观察启动日志是否启动成功。
同样,将apache-tomcat-pinpoint-web中的webapp/ROOT清空,将pinpoint-web-1.8.4.war放入并解压。解压完成后就可以进入bin目录使用./startup.sh启动tomcat了,并且使用命令tail -f ../logs/catalina.out观察启动日志是否启动成功。
当Collector和Web UI都启动成功后,就可以使用打开浏览器访问:http://ip:28080/#/main ,初次访问如图:
1、 Agent启用;
实战案例,本实战案例和上一篇实战案例保持一致,同样是4个服务,包括Zuul-Service、Eureka-Service、Consumer-Service和Provider-Service。具体实现代码本章不再列出,各位读者可以参考上一篇或者Github仓库(https://github.com/meteor1993/SpringCloudLearning/tree/master/chapter15),下面我们介绍Spring Cloud是如何与Pinpoint整合使用的。
接入方式和上一篇的Skywalking是一致的,都是使用探针技术接入应用程序,java -jar的方式来加载Agent探针。
首先在工程的跟目录中执行mvn install,而后在CentOS的opt中新建4个目录,分别存放4个打好包的工程。笔者这里创建的4个目录分别为/opt/project/consumer_service,/opt/project/eureka_service,/opt/project/provider_service和/opt/project/zuul_service,将4个jar包分别放入对应的目录中,并解压刚才我们下载好的pinpoint-agent-1.8.4.tar.gz探针,我们将解压后的探针放在/opt的目录中,接下来,我们使用如下命令,顺次启动4个jar包:
java -javaagent:/opt/pinpoint-bootstrap-1.8.4.jar -Dpinpoint.agentId=consumer-service -Dpinpoint.applicationName=consumer-server -jar /opt/project/consumer_service/consumer-0.0.1-SNAPSHOT.jar
java -javaagent:/opt/pinpoint-bootstrap-1.8.4.jar -Dpinpoint.agentId=eureka-service -Dpinpoint.applicationName=eureka-server -jar /opt/project/eureka_service/eureka-0.0.1-SNAPSHOT.jar
java -javaagent:/opt/pinpoint-bootstrap-1.8.4.jar -Dpinpoint.agentId=provider-service -Dpinpoint.applicationName=provider-server -jar /opt/project/provider_service/provider-0.0.1-SNAPSHOT.jar
java -javaagent:/opt/pinpoint-bootstrap-1.8.4.jar -Dpinpoint.agentId=zuul-service -Dpinpoint.applicationName=zuul-server -jar /opt/project/zuul_service/zuul-0.0.1-SNAPSHOT.jar
上述命令执行完成之后,再打开Web UI查看显示情况。
首先打开浏览器访问:http://192.168.44.129:8080/client/hello?name=spring ,页面正常显示Hello, name is spring,查看Pinpoint的Web UI,如图:
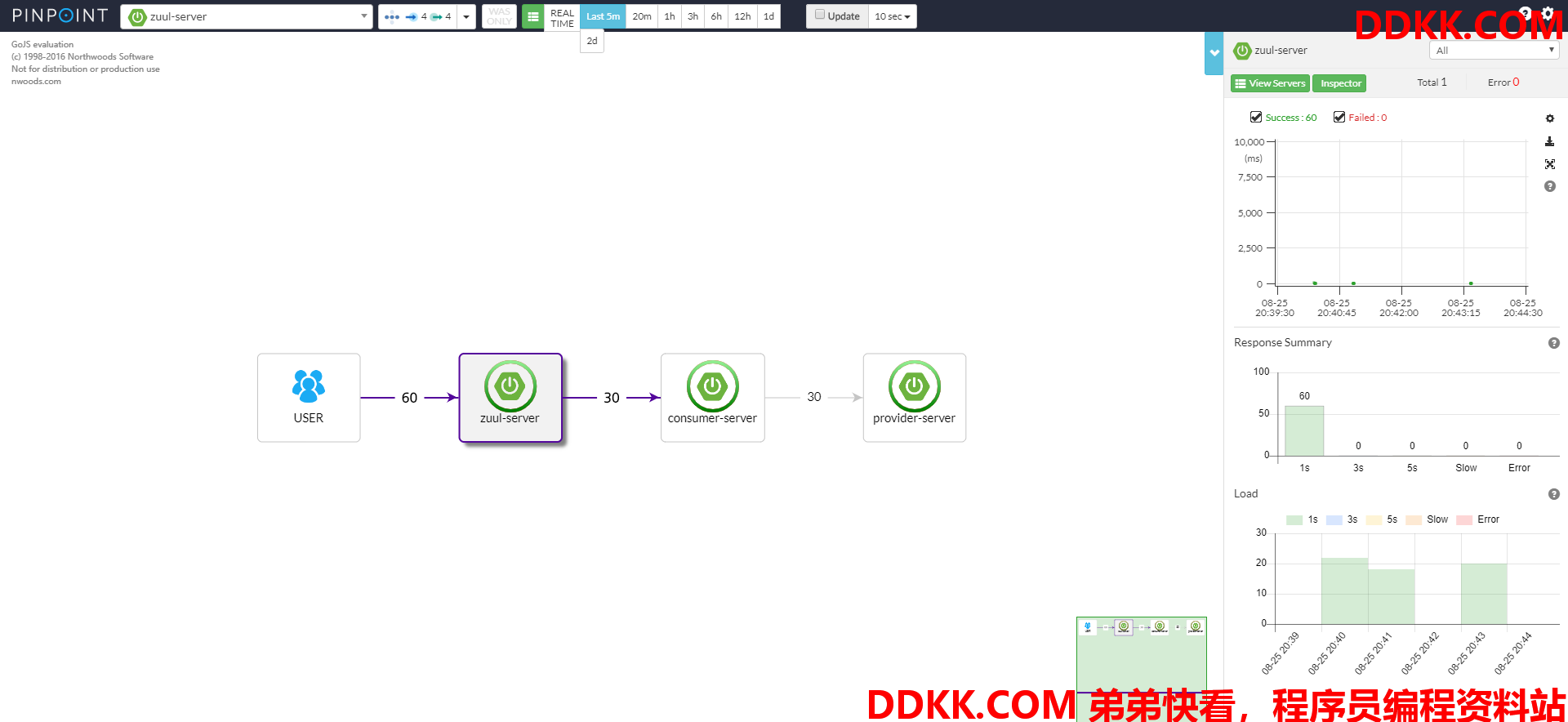
图清楚的显示了我们当前系统的拓扑结构,横线上面的数字代表了调用次数,右边部分,最上面显示的是成功和失败的情况,中间部分显示的是响应时间,下面显示的是加载所使用的时间。
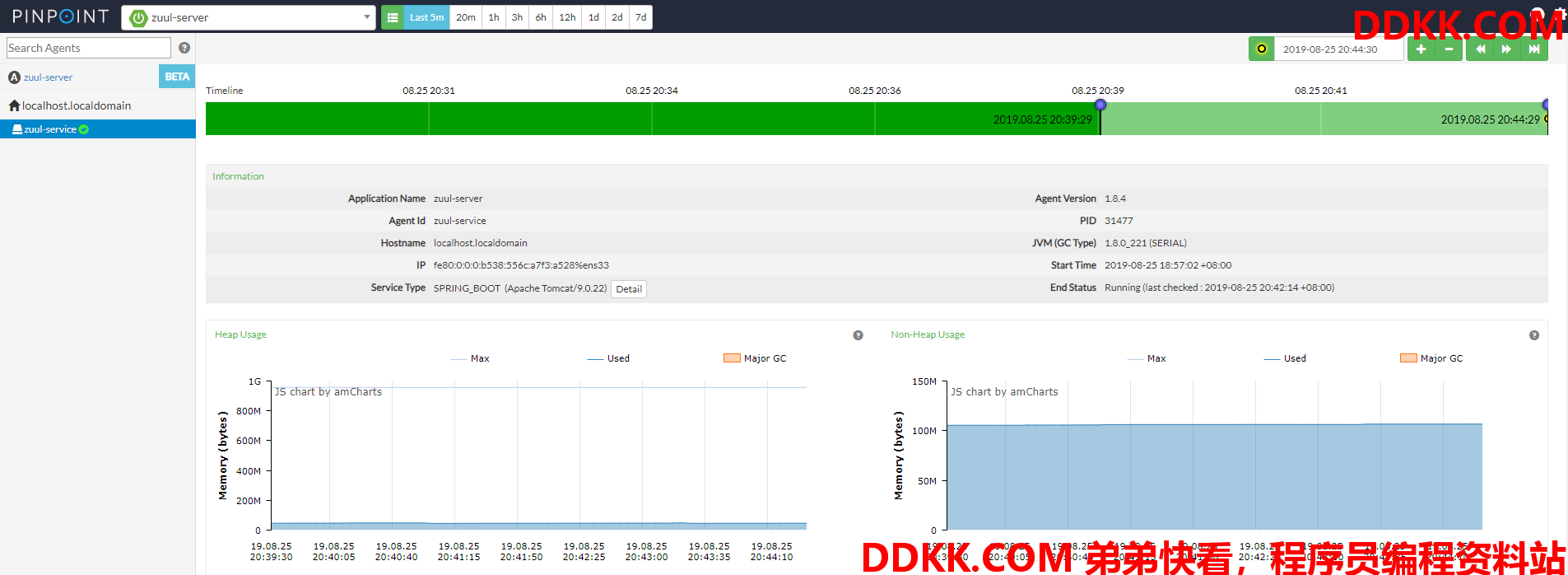
检查器(Inspector):这里已Zuul-Service为例,Timeline显示的是请求的时间段,Information显示的是节点的一些当前信息,包含Application Name、Agent Id、Agent版本、JVM信息、开始时间等。
Heap信息的使用情况,如图:
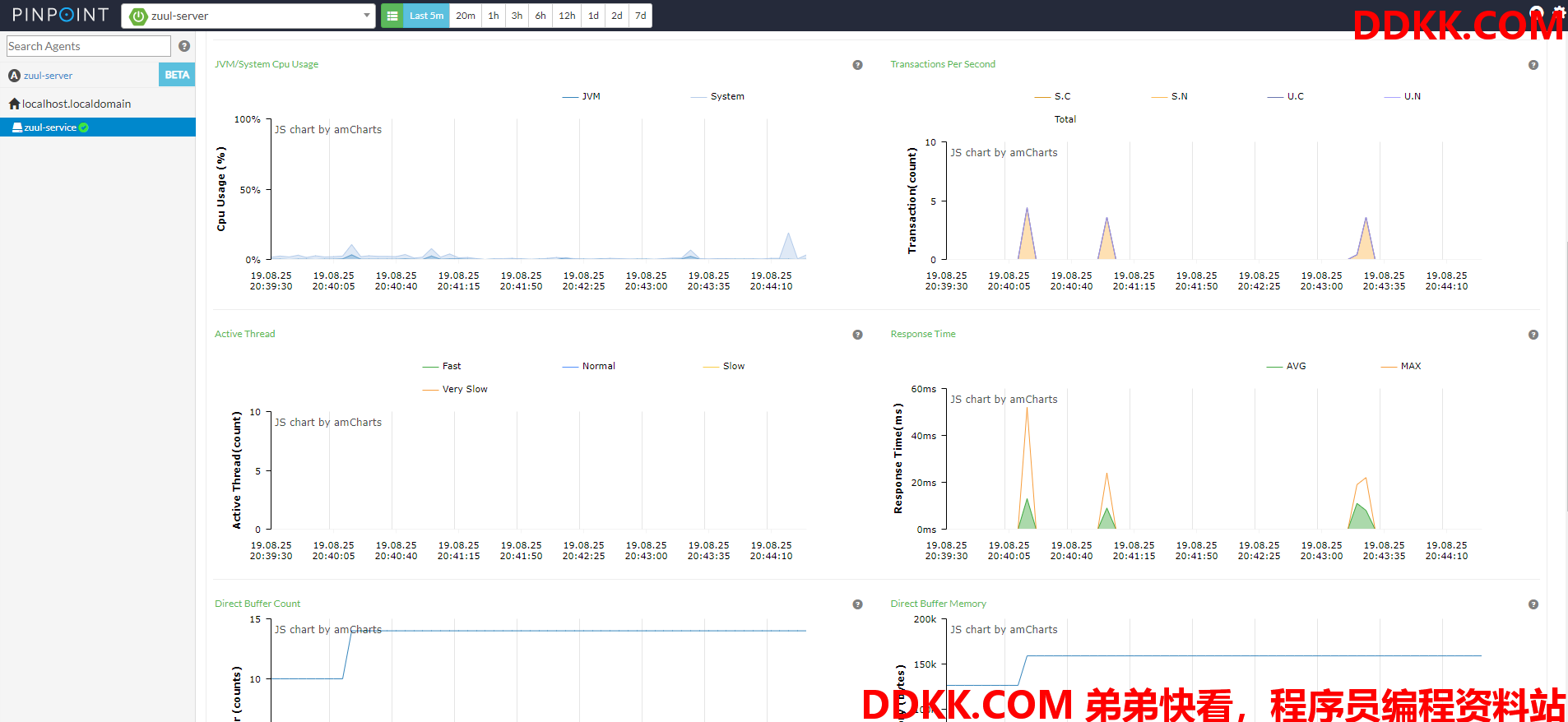
系统CPU、活动线程、响应时间等信息如图:
更多Pinpoint的信息,读者可以通过官方Demo(http://125.209.240.10:10123/#/main )或者自行构建试验来查看结果,这里不再一一赘述。至此,Spring Cloud和Pinpoint的使用介绍也就完成了。更多有关Pinpoint的信息各位读者可以前往Github的官网进行查阅,地址为:https://github.com/naver/pinpoint 。
8. 小结
这里总结一下整个案例的启动顺序:
1、 启动HBase;
2、 启动collector;
3、 启动Web-UI;
4、 启动Agent(Eureka、provider、consumer、zuul);
5、 应用调用;
6、 访问Web-UI查看统计信息;
同Skywalking一样,以上启动顺序供各位读者参考,请各位读者最好按照以上顺序启动,因为不同的组件之前其实是有相互依赖关系的,如果随意更改启动顺序可能会造成某些未知问题。至此,Spring Cloud和APM的相关操作就告一段落了。APM可以很好的帮我们理解系统行为,也是分析系统性能的工具,更是发生问题故障的时候利器,可以帮我们快速的定位查找问题。
版权声明:「DDKK.COM 弟弟快看,程序员编程资料站」本站文章,版权归原作者所有