今天分析 Java 语法糖及实现原理:
Java中的泛型
1、泛型是什么
泛型,即“参数化类型”,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。 引入一个类型变量 T (其他大写字母都可以,不过常用的就是 T , E , K , V 等等),并且用 <> 括起来,并放在类名的后面。泛型类 是允许有多个类型变量的。 按照约定,类型参数名称命名为单个大写字母,以便可以在使用普通类或接口名称时能够容易地区分类型参数。以下是常用的类
型参数名称列表:
E- 元素,主要由 Java 集合 (Collections) 框架使用。
K- 键,主要用于表示映射中的键的参数类型。
V- 值,主要用于表示映射中的值的参数类型。
N- 数字,主要用于表示数字。
T- 类型,主要用于表示第一类通用型参数。
S- 类型,主要用于表示第二类通用类型参数。
U- 类型,主要用于表示第三类通用类型参数。
V- 类型,主要用于表示第四个通用类型参数。
泛型类和泛型接口
可以为任何类、接口增加泛型声明

泛型接口与泛型类的定义基本相同。

3、泛型类和接口的使用
而实现泛型接口的类,有两种实现方法:
1)未传入泛型实参时:

在new 出类的实例时,需要指定具体类型:

2)、传入泛型实参

在new 出类的实例时,和普通的类没区别。

泛型方法,是在调用方法的时候指明泛型的具体类型 ,泛型方法可以在任何地方和任何场景中使用,包括普通类和泛型类。
4、为什么我们需要泛型?
通过两段代码我们就可以知道为何我们需要泛型


实际开发中,经常有数值类型求和的需求,例如实现 int 类型的加法 , 有时候还需要实现 long 类型的求和 , 如果还需要 double 类型
的求和,需要重新在重载一个输入是 double 类型的 add 方法。所以泛型的好处就是: 适用于多种数据类型执行相同的代码 ;泛型中的类型在使用时指定,不需要强制类型转换
二、虚拟机是如何实现泛型的?
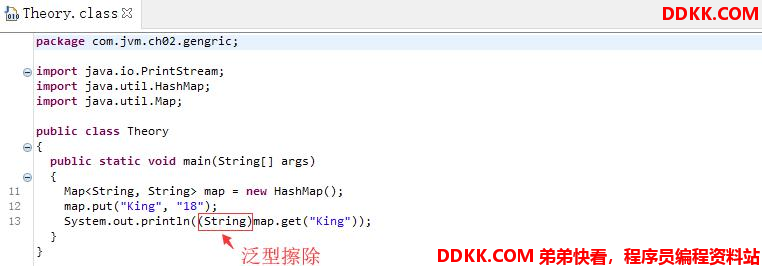
1、泛型擦除
Java 语言中的泛型,它只在程序源码中存在,在编译后的字节码文件中,就已经替换为原来的原生类型( Raw Type ,也称为裸类 型)了,并且在相应的地方插入了强制转型代码,因此,对于运行期的 Java 语言来说, ArrayList < int >与 ArrayList < String >就是同一 个类,所以泛型技术实际上是 Java 语言的一颗语法糖, Java 语言中的泛型实现方法称为类型擦除,基于这种方法实现的泛型称为伪泛 型。将一段 Java 代码编译成 Class 文件,然后再用字节码反编译工具进行反编译后,将会发现泛型都不见了,程序又变回了 Java 泛型 出现之前的写法,泛型类型都变回了原生类型(因为)

使用泛型注意事项(小甜点,了解即可)
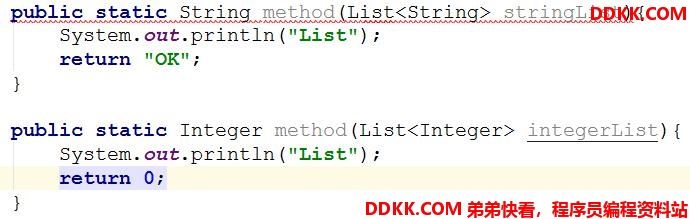
上面这段代码是不能被编译的,因为参数 List < Integer >和 List < String >编译之后都被擦除了,变成了一样的原生类型 List < E >,擦除动作导致这两种方法的特征签名变得一模一样(注意在 IDEA 中是不行的,但是 jdk 的编译器是可以,因为 jdk 是根据方法返回值+ 方法名+ 参数)。
2、弱记忆
JVM 版本兼容性问题: JDK1.5 以前,为了确保泛型的兼容性, JVM 除了擦除,其实还是保留了泛型信息 (Signature 是其中最重要的 一项属性,它的作用就是存储一个方法在字节码层面的特征签名,这个属性中保存的参数类型并不是原生类型,而是包括了参数化类 型的信息)---- 弱记忆 另外,从 Signature 属性的出现我们还可以得出结论,擦除法所谓的擦除,仅仅是对方法的 Code 属性中的字节码进行擦除,实际 上元数据中还是保留了泛型信息,这也是我们能通过反射手段取得参数化类型的根本依据。
三、Stream
1、什么是Stream?
Java8 中, Collection 新增了两个流方法,分别是 Stream() 和 parallelStream() ,Java8 中添加了一个新的接口类 Stream ,相当于高级版的 Iterator ,它可以通过 Lambda 表达式对集合进行 大批量 数据操作,或 者各种非常便利、高效的聚合 数据操作。
2、为什么要使用Stream?
在Java8 之前,我们通常是通过 for 循环或者 Iterator 迭代来重新排序合并数据,又或者通过重新定义 Collections.sorts 的
Comparator 方法来实现,这两种方式对于 大数据量系统 来说,效率并不是很理想。
Stream 的聚合操作与数据库 SQL 的聚合操作 sorted 、 filter 、 map 等类似。我们在应用层就可以高效地实现类似数据库 SQL 的
聚合操作了,而在数据操作方面, Stream 不仅可以通过串行的方式实现数据操作,还可以通过并行的方式处理大批量数据, 提高数据 的处理效率 。
3、Stream使用入门

可以看到,如果实现同样的功能,那么使用循环的方式,代码行数将达到 6 行。

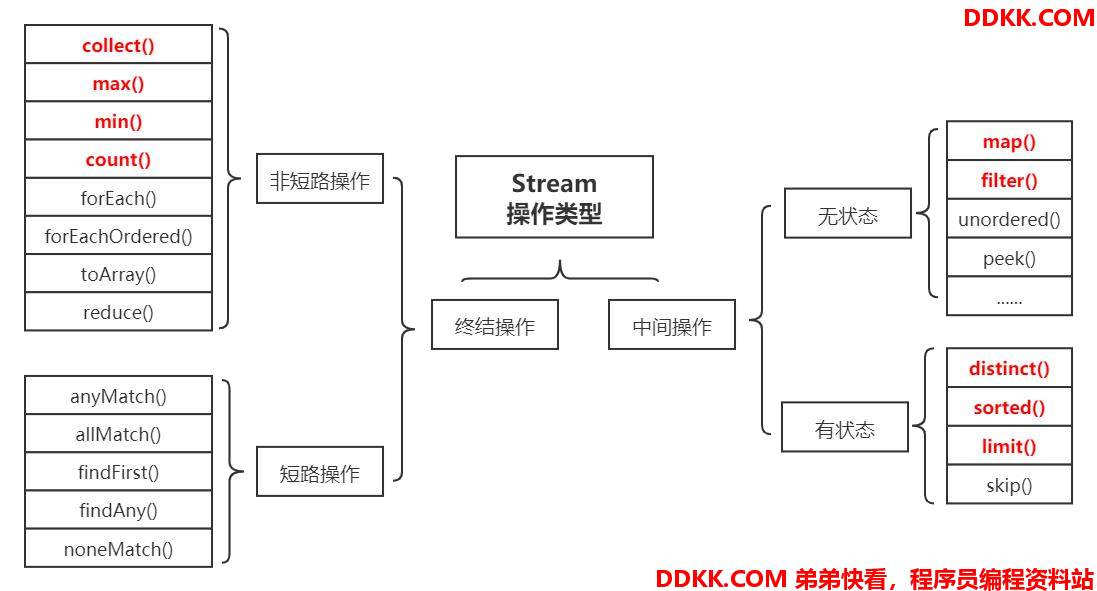
4、Stream操作分类
官方将 Stream 中的操作分为两大类:终结操作( Terminal operations )和中间操作( Intermediate operations )。
1)中间操作 会返回一个新的流,一个流可以后面跟随 零个或多个中间操作 。其目的主要是打开流,做出某种程度的数据映射 / 过滤, 然后会返回一个新的流,交给下一个操作使用。这类操作都是惰性化的(lazy) ,就是说,仅仅调用到这类方法,并没有真正开始流的 遍历。而是在终结操作开始的时候才真正开始执行。 中间操作 又可以分为 无状态 ( Stateless )与 有状态 ( Stateful )操作,无状态是指元素的处理不受之前元素的影响,有状态是指该 操作只有拿到所有元素之后才能继续下去。
2)终结操作 是指返回最终的结果。一个流只能有一个终结操作,当这个操作执行后,这个流就被使用 “ 光 ” 了,无法再被操作。所以 这必定这个流的最后一个操作。终结操作 的执行才会真正开始流的遍历,并且会生成一个结果。 终结操作 又可以分为 短路 ( Short-circuiting )与 非短路 ( Unshort-circuiting )操作, 短路 是指遇到某些符合条件的元素就可以得到最终结果,
非短路 是指必须处理完所有元素才能得到最终结果。操作分类详情如下图所示:
演示案例
见代码StuWithStream

因为Stream 操作类型非常多,总结一下常用的
map(): 将流中的元素进行再次加工形成一个新流,流中的每一个元素映射为另外的元素。
filter(): 返回结果生成新的流中只包含满足筛选条件的数据
limit() :返回指定数量的元素的流。返回的是 Stream 里前面的 n 个元素。
skip() :和 limit() 相反,将前几个元素跳过(取出)再返回一个流,如果流中的元素小于或者等于 n ,就会返回一个空的流。
sorted() :将流中的元素按照自然排序方式进行排序。
distinct():将流中的元素去重之后输出。
peek() :对流中每个元素执行操作,并返回一个新的流,返回的流还是包含原来流中的元素。
四、Stream的底层实现
1、Stream操作叠加
一个Stream 的各个操作是由处理管道组装,并统一完成数据处理的。 我们知道 Stream 有中间操作和终结操作,那么对于一个写好的 Stream 处理代码来说,中间操作是通过 AbstractPipeline 生成了一个中间操作 Sink 链表 当我们调用终结操作时,会生成一个最终的 ReducingSink ,通过这个 ReducingSink 触发之前的中间操作,从最后一个 ReducingSink 开始,递归产生一个 Sink
链。如下图所示:

2、Stream源码实现(不重要)
stream方法
因为names 是 ArrayList 集合,所以 names.stream() 方法将会调用集合类基础接口 Collection 的 Stream 方法
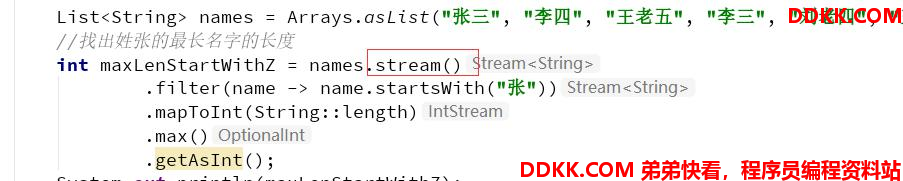
然后,Stream 方法就会调用 StreamSupport 类的 Stream 方法,

Stream 方法中初始化了一个 ReferencePipeline 的 Head 内部类对象:

filter方法
再调用 filter ,这个方法都是无状态的中间操作,所以执行 filter 时,并没有进行任何的操作,而是分别创建了一个 Stage 来标识用
户的每一次操作。
而通常情况下 Stream 的操作又需要一个回调函数,所以一个完整的 Stage 是由数据来源、操作、回调函数组成的三元组来表示。
如下图所示,分别是 ReferencePipeline 的 filter 方法和 map 方法:

max方法




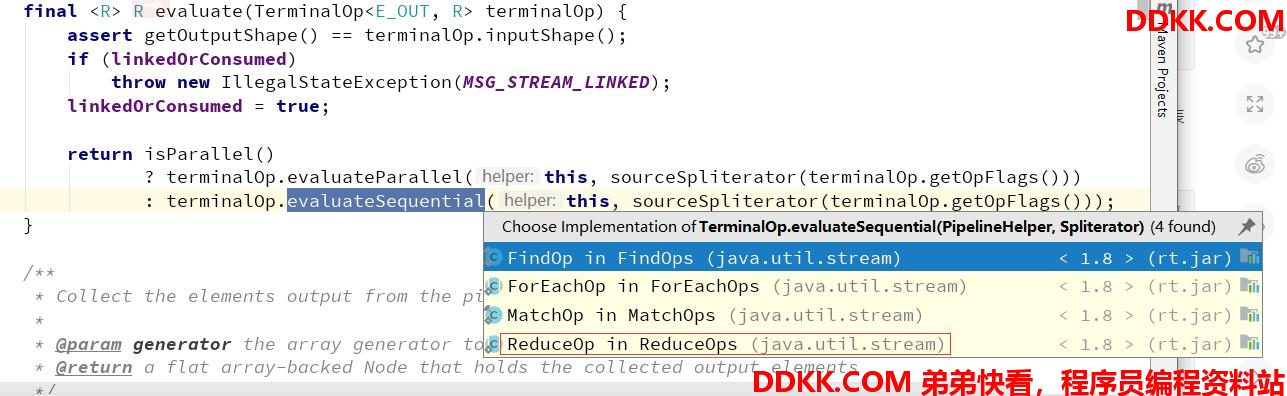

当Sink 链表生成完成后, Stream 开始执行,通过 spliterator 迭代集合,执行 Sink 链表中的具体操作。 java8 中的 Spliterator 的 forEachRemaining 会迭代集合,每迭代一次,都会执行一次 filter 操作,如果 filter 操作通过,就会触发 map 操作,然后将结果放入到临时数组 object 中,再进行下一次的迭代。完成中间操作后,就会触发终结操作 max 。




Stream并发Stream源码实现(不重要)
并发的处理函数对比 parallelStream()方法
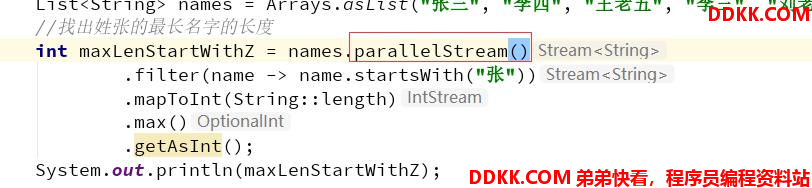

这里的并行处理指的是, Stream结合了ForkJoin框架 ,对 Stream 处理进行了分片, Splititerator 中的 estimateSize 方法会估算出分 片的数据量。 通过预估的数据量获取最小处理单元的阈值,如果当前分片大小大于最小处理单元的阈值,就继续切分集合。每个分片将会生成一个 Sink 链表,当所有的分片操作完成后, ForkJoin 框架将会合并分片任何结果集。
3、Stream的性能
常规数据迭代 ,100的性能对比


常规的迭代> Stream并行迭代> Stream串行迭代
为什么这样:
1、 常规迭代代码简单,越简单的代码执行效率越高;
2、 Stream串行迭代,使用了复杂的设计,导致执行速度偏低所以是性能最低的;
3、 Stream并行迭代使用了Fork-Join线程池,所以效率比Stream串行迭代快,但是对比常规迭代还是要慢(毕竟设计和代码复杂);
大数据迭代
一亿的数组性能对比(默认线程池)


为什么这样:
1、 Stream 并行迭代 使用了 Fork-Join 线程池 , 而线程池线程数为 cpu 的核心数(我的电脑为 12 核),大数据场景下,能够利用多线 程机制,所以效率比 Stream 串行迭代快,同时多线程机制切换带来的开销相对来说还不算多,所以对比常规迭代还是要快(虽然设计 和代码复杂)
2、 常规迭代代码简单,越简单的代码执行效率越高;
3、 Stream串行迭代,使用了复杂的设计,导致执行速度偏低所以是性能最低的;
一亿的数组性能对比(线程池数量=2)


为什么这样:
Stream 并行迭代 使用了 Fork-Join 线程池 , 大数据场景下,虽然利用多线程机制,但是线程池线程数为 2 ,所以多个请求争抢着执行任 务,想象对请求来说任务是被交替执行完成,所以对比常规迭代还是要慢(虽然用到了多线程技术)
一亿的数组性能对比(线程池数量=240)

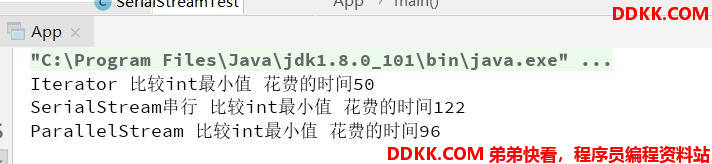
为什么这样:
Stream 并行迭代 使用了 Fork-Join 线程池 , 而线程池线程数为 240 ,大数据场景下,虽然利用多线程机制,但是线程太多,线程的上下 文切换成本过高,所以导致了执行效率反而没有常规迭代快。
如何合理使用Stream?
我们可以看到:在循环迭代次数较少的情况下,常规的迭代方式性能反而更好;而在大数据循环迭代中, parallelStream (合理的线程 池数上)有一定的优势。 但是由于所有使用并行流 parallelStream 的地方都是使用同一个 Fork-Join 线程池,而线程池线程数仅为 cpu 的核心数。 切记,如果对底层不太熟悉的话请不要乱用并行流 parallerStream (尤其是你的服务器核心数比较少的情况下)