cpu过高、项目运行慢:
1、 进入Linux重端命令行 top 命令:找到java 进程号 7498
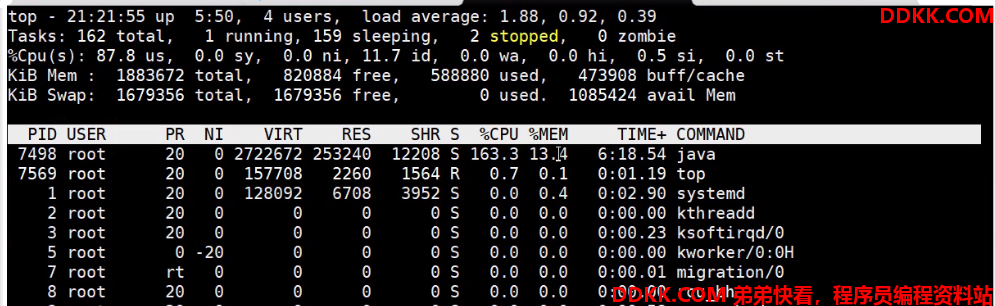
2、 执行 top -p 7498 单独监控该进程,页面:

3、在第 2 步的监控界面输入 H,获取当前进程下的所有线程信息:发现7501、7500两个线程占用内存最大
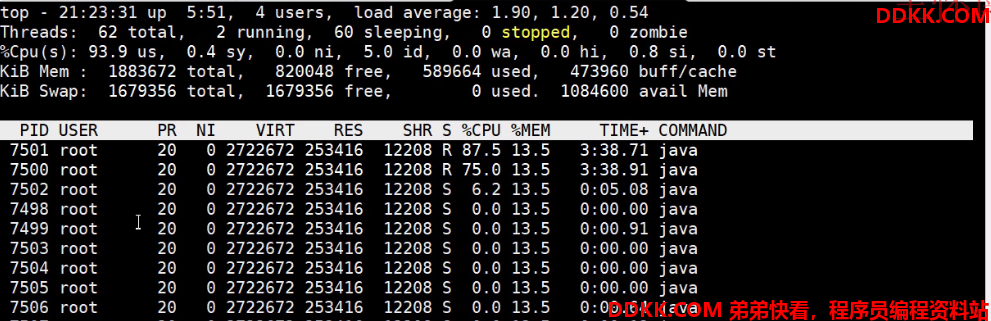
4、执行jstack 7498对当前的进程做dump,输出所有的线程信息,随机截图:
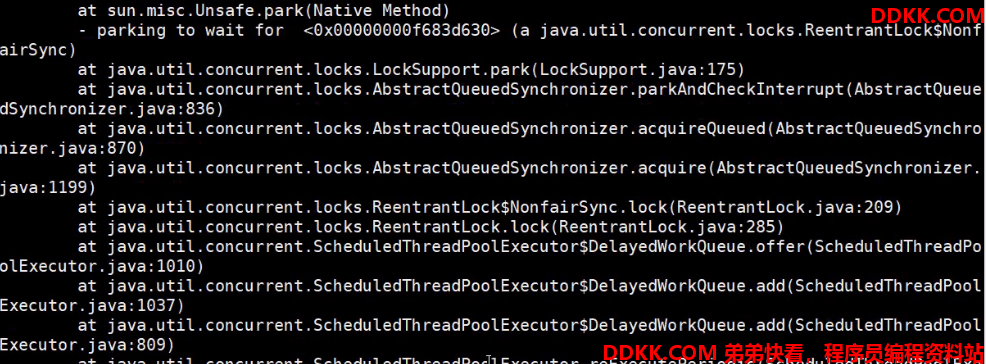
5、里面的线程id 是16进制,随机找到一个截图:
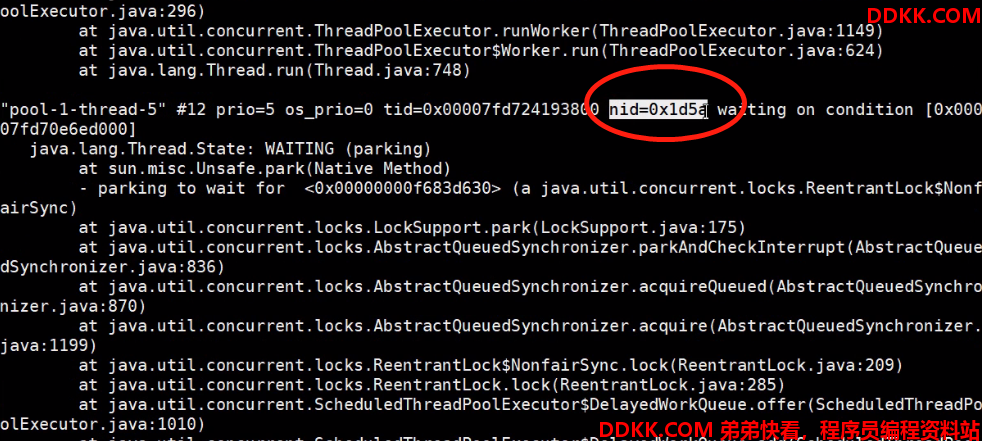
6将第 3步得到的线程编号 7500通过计算器转成16进制是 1D4C、1D4D
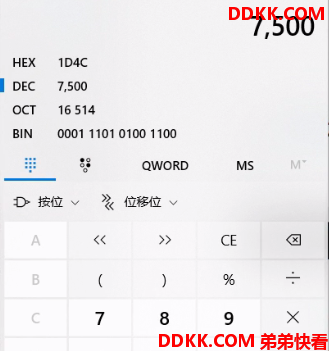

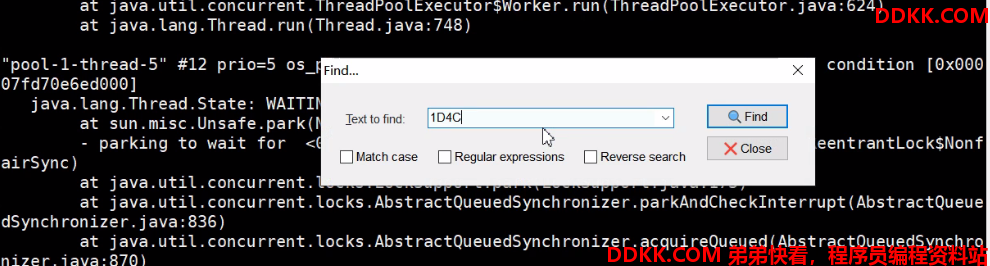
或者printf "%x\n" 7500 生成1D4D 然后 : jstack 7498|grep 1D4D -C 10


7、根据第6步得到的 1D4D在第5步的线程信息里面去找对应线程内容:
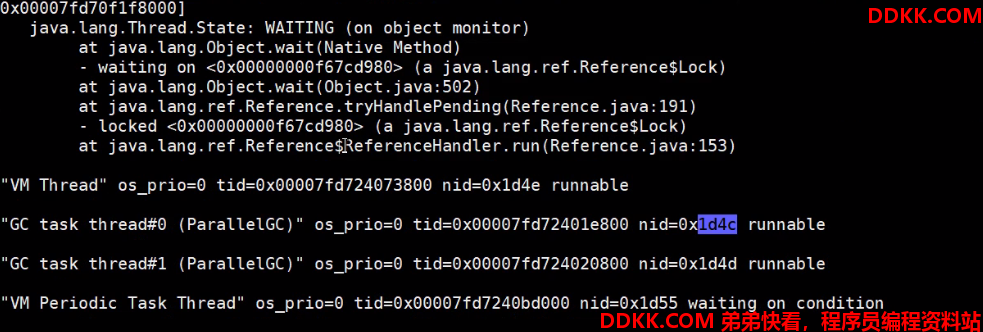
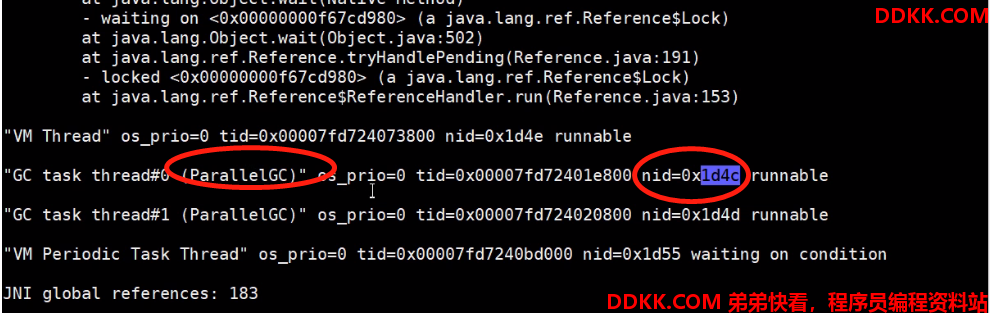
8解读线程信息,定位具体代码位置,发现是两个垃圾回收的线程占用过多的线程资源,疯狂的垃圾回收导致系统变慢;看看日志(加上打印垃圾回收的日志)还有OOM异常;
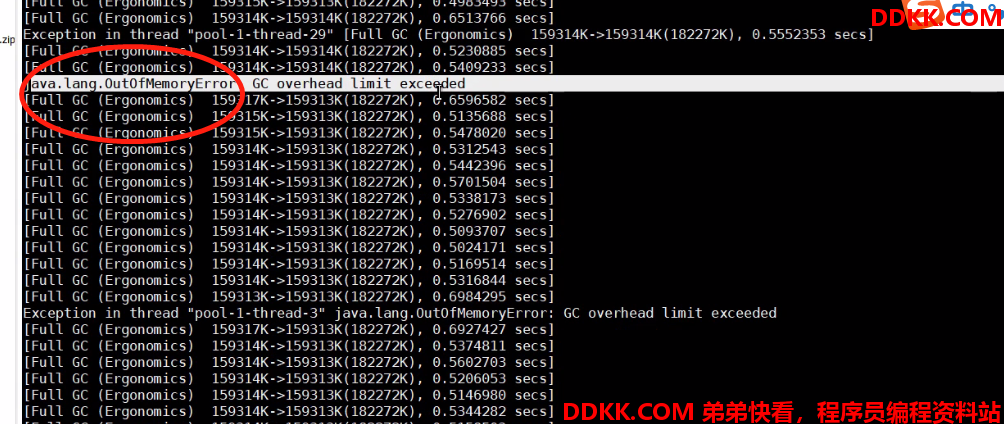
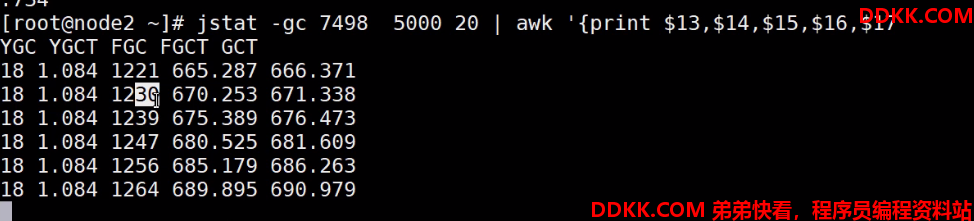
发现新生代不进行垃圾回收,一直进行FGC垃圾回收,5秒钟进行10次,全部时间用来FGC。WAY!!!,找原因!!!!
9、 jmap-heap7498;
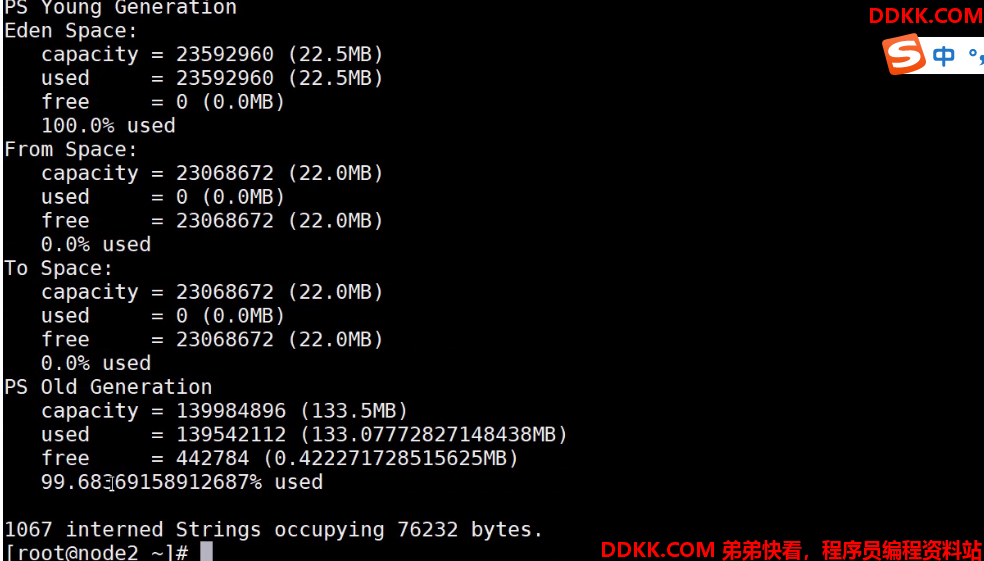
发现老年代已经塞满。
10、 查一下这个进程的占据内存的前20名的对象,找到代码中相应的类,命令:jmap-histo7498|head-20;
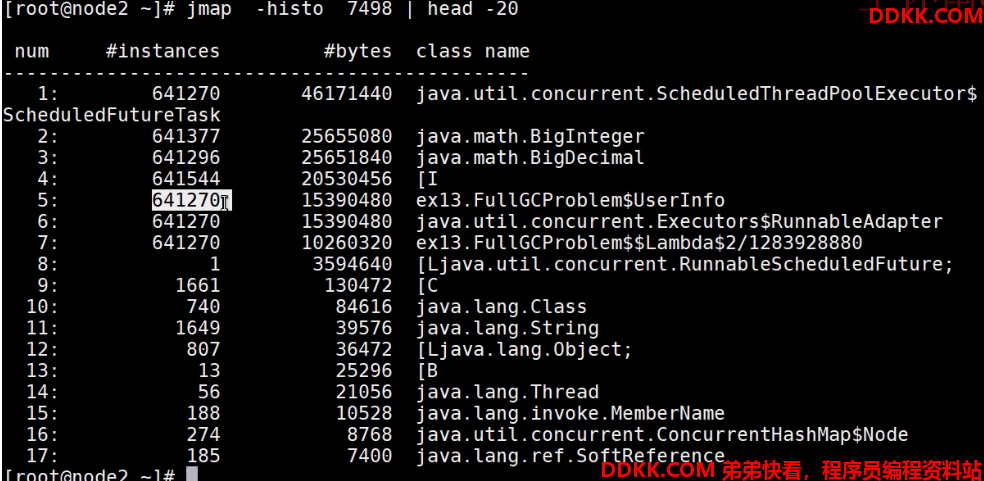
业务代码类找到了,就去项目中看看,这时所有问题都迎刃而解了!!! 今天实战线上排查到此结束!
注意!!!
原因:
业务场景1,此线程有非常多或非常大的对象存在,并且处理这些对象的过程很慢、很耗时,即此线程不结束,对象引用一直存在,不会变成垃圾,因此,GC频繁进行,内存也不会有变化。
业务场景2:内存泄漏引起OOM异常,该回收的垃圾,回收不了,造成系统变慢。如:map中 对象作为key 而没有重写 hashcode 和equal 方法。
业务场景3:慢sql查询大的数据量,导致数据库连接数紧张。