RabbitMQ 默认的集群模式,也就是普通模式,最大的问题就在于存储队列完整数据的节点一旦宕机,
如果是非持久化队列,则消息丢失;如果是持久化队列+持久化消息,则必须等该节点恢复.
所以后来 RabbitMQ 开始支持队列(完整数据)复制.比如在有5个节点的集群里,可以指定某个队列的完整数据在2个节点上进行存储,从而在性能与高可用之间取得一个平衡,这就是镜像模式,它属于 RabbitMQ 的HA方案.
镜像模式解决了普通模式的问题,消息实体会主动在镜像节点间同步,而不是在消费者获取数据的时候临时从其他节点拉取.当然,该模式的副作用也很明显:
- 消息需要复制到每一个节点,对于持久化消息,网络和磁盘同步复制的开销都会明显增加;
- 如果镜像队列数量过多,大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉.
所以镜像模式适合在对可靠性要求较高的场合中使用.
综上所述,镜像模式的实质是镜像队列,一个队列想做成镜像队列,需要先设置 policy,然后客户端创建队列的时候,RabbitMQ 集群根据“队列名称”自动设置是普通集群模式或镜像模式.
下面我们通过管理后台将前面搭建的单机集群模式修改成镜像模式.
搭建步骤
第一步

第二步
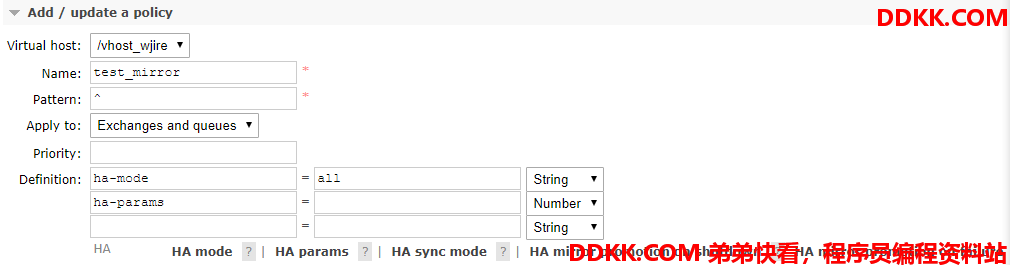
- Virtual host : 虚拟主机.
- Name : 策略名称.
- Pattern : ^ 表示匹配所有队列名称.
- Apply to : 这里选择的是同时应用到交换机和队列.
- ha-mode 和 ha-params 见下表(原贴:http://www.ywnds.com/?p=4741)
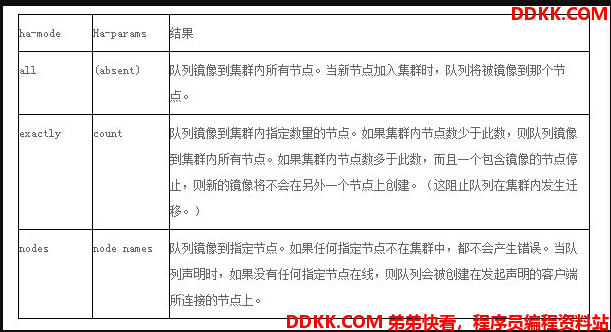
然后我们可以看到,该虚拟主机下面的交换机和队列都被打上了 test_mirror 标签

+1表示有1个镜像节点.
进入该队列详情,可以清晰的看到 : 策略名称,队列的主节点以及镜像节点等.

验证功能
将就上一篇普通集群的代码.
1.生产者连接到 node1 (5672) 发送消息,然后关闭 node1.
通过node2 的管理后台可以看到队列依然在.

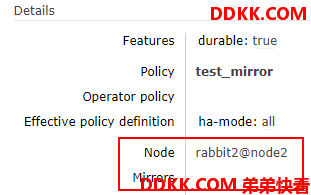
但是有个细节,Node 从 rabbit1@node1 变成了 rabbit2@node2.
进入该队列详情,主节点已经变成了 rabbit2@node2 , 而镜像节点是空.
2.消费者连接到 node2 接收消息
一切正常.
3.重新启动 node1
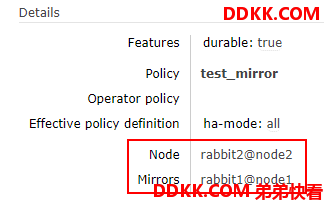
可以看到,队列的主节点没有还原回去.
关于 HA sync mode,HA mirror promotion on shutdown,HA mirror promotion on failure 的测试
一.HA sync mode
该参数有两个值:
- manual : 手动模式(默认值)
- automatic : 自动模式
手动模式下,新加入的节点不会同步老节点的队列(及消息).测试如下:
1.我们先往"test_queue"队列添加10条消息.

2.新增节点 node3

3.这时候我们再看管理后台,多了1个红色的"+1",这个"+1"表示有一个节点没有同步该队列的数据.

我们进入该队列查看详情:
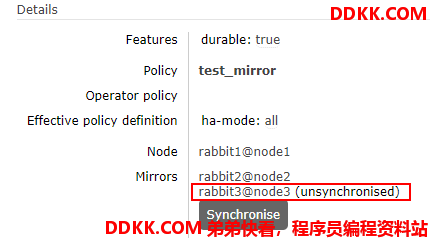
可以看到,有个"同步"的按钮.我们可以手动同步.
如果我们把10条消息消费掉后,系统也会认为数据同步了,因为3个节点的数据一样了.这时候红色的"+1"就会消失,而之前的蓝色"+1"变成了"+2".

自动模式的测试结果就不上图了.
二.HA mirror promotion on failure
该参数有两个值 :
- when-synced
- always (默认值)
默认值为 "always" ,如果队列主节点发生故障,断开连接或者从群集中删除了,则最早的镜像节点将被提升为新的主节点.但是在某些情况下,此镜像节点可能没有同步数据,这将导致数据丢失.
"when-synced" ,意味着当队列主节点发生故障的时候,队列将变得不可用,直到主节点恢复.如果队列主节点永久丢失,除非将队列删除(同时会删除其所有内容)并重新声明,否则该队列将永不可用;
这相当于通过降低安全性(将非同步镜像节点升级为主节点),从而增加对队列主机可用性的依赖,因为有时候队列可用性比数据一致性更重要.
三.HA mirror promotion on shutdown
该参数也有两个值 :
- when-synced (默认值)
- always
该参数的默认值为 "when-synced", 如果队列主节点关闭了(即显式停止RabbitMQ服务或关闭操作系统),那么所有节点上的该队列都将关闭.
"always" 意味着如果队列主节点关闭了,可以提升一个未同步的节点为新的主节点,以避免数据丢失.
但是,如果 HA mirror promotion on failure 的值为 "when-synced" ,即使 HA mirror promotion on shutdown 的值为 "always" ,也不会提升未同步的节点.这意味着如果队列主节点发生故障,队列将在主节点恢复之前变为不可用.如果队列主机永久丢失,除非将队列删除(也将删除其所有内容)并重新声明,否则该队列将不可用.
测试
1、 删除之前创建的node2,node3,只保留node1;;
2、 删除原来的策略,重新建了一个,并且HAsyncmode,HAmirrorpromotiononfailure和HAmirrorpromotiononshutdown3个参数都未设定,即都使用默认值;;
3、 发送10条消息;;
4、 新建node2,并加入集群.;
目前该队列情况如下:node1 是队列主节点,并且 node2 尚未同步数据.

5、 停止node1,即停止队列主节点(rabbitmqctlstop_app);

这时候,该队列变成了不可用,连接 node2 发送消息,接收消息都会失败.
这个结果符合 HA sync mode ,HA mirror promotion on failure 和 HA mirror promotion on shutdown 3个参数默认值的预期.
6、 恢复node1(rabbitmqctlstart_app),进入该队列详情,点击![ ][nbsp16]按钮,手动同步一下队列数据,这时候,两个节点的状态是:node1为队列主节点,node2已同步数据;

7、 再次关闭node1.;
从管理后台可以看见,该队列依然可用,并且 node2 被提升成了队列主节点.同样符合 HA mirror promotion on failure 和 HA mirror promotion on shutdown 默认值的预期.

至于将HA mirror promotion on shutdown 设为 "always ", HA mirror promotion on failure 设为 "when-synced" 的情况就不再测试了.
内存及硬盘控制(转载)
一.内存控制
vm_memory_high_watermark 该值为内存阈值,默认为0.4.意思为物理内存的40%.40%的内存并不是内存的最大的限制,它是一个发布的节制,当达到40%时Erlang会做GC.最坏的情况是使用内存80%.如果把该值配置为0.将关闭所有的publishing.
Paging 内存阈值,该值为默认为0.5,该值为 vm_memory_high_watermark 的20%时,将把内存数据写到磁盘.
如机器内存16G,当 RabbitMQ占用内存1.28G(16*0.4*0.2)时会把内存数据放到磁盘.
二.硬盘控制
当RabbitMQ的磁盘空闲空间小于50M(默认),生产者将被BLOCK.如果采用集群模式,磁盘节点空闲空间小于50M将导致其他节点的生产者都被block,可以通过 disk_free_limit 来对进行配置.
原贴:http://www.ywnds.com/?p=4741
HAProxy1.7.8 负载均衡
在某网站下载了一个 window 可以用的版本 haproxy-1.7.8
修改haproxy.cfg 配置文件
global
maxconn 15000
nbproc 1
daemon
defaults
mode tcp
retries 3
option abortonclose
maxconn 2000
timeout connect 300000ms
timeout client 300000ms
timeout server 300000ms
log 192.168.1.5 local0 err
listen RabbitMQ
bind 192.168.1.5:8848
mode http
balance roundrobin
server node1 192.168.1.5:5672 weight 1 maxconn 2000 check inter 5s rise 1 fall 3
server node2 192.168.1.5:5673 weight 1 maxconn 2000 check inter 5s rise 1 fall 3
listen status
bind 192.168.1.5:1188
mode http
stats refresh 30s
stats uri /
stats auth admin:admin
stats hide-version
stats admin if TRUE