zookeeper在将写请求应用到内存数据库之前,会首先记录这次事务,从而生成事务日志。当事务日志的数量达到一定规模之后,会对内存数据库打快照,从而生成快照文件。
持久化相关的类
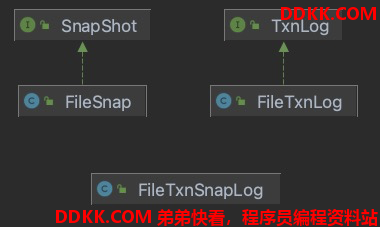
TxnLog包含了对事务日志的操作方法
FileTnxLog实现了TxnLog接口
SnapShot包含了对快照日志的操作方法
FileSnapShot实现了SnapShot接口
FileTnxSnapLog包含TnxLog和SnapShot
事务日志
TxnLog
public interface TxnLog {
// 设置服务端的统计信息
void setServerStats(ServerStats serverStats);
// 滚动当前正在写的日志文件
void rollLog() throws IOException;
// 追加指定日志
boolean append(TxnHeader hdr, Record r) throws IOException;
// 返回可以从指定事务id开始读取之后事务日志的迭代器
TxnIterator read(long zxid) throws IOException;
// 获取最近记录的事务日志的事务id
long getLastLoggedZxid() throws IOException;
// 截取事务日志到指定的事务id
boolean truncate(long zxid) throws IOException;
// 返回当前事务日志所属的dbid
long getDbId() throws IOException;
// 提交日志,保证日志能够持久化
void commit() throws IOException;
/**
*
* @return transaction log's elapsed sync time in milliseconds
*/
long getTxnLogSyncElapsedTime();
// 关闭日志
void close() throws IOException;
// 读取事务日志的迭代器
public interface TxnIterator {
// 获取事务记录的头
TxnHeader getHeader();
// 获取事务记录的内容
Record getTxn();
// 移动到下一个日志
boolean next() throws IOException;
// 关闭文件
void close() throws IOException;
// 获取当前迭代器能够返回的日志预估大小
long getStorageSize() throws IOException;
}
}
文件组成
一个事务日志文件一共有三个部分:
FileHeader TxnList ZeroPad
FileHeader
FileHeader {
magic 4bytes
version 4bytes
dbid 8bytes
}
TxnList
TxnList存放事务记录,包含多个Txn
Txn {
checksum 8bytes
Txnlen 4bytes
TxnHeader {
sessionid 8bytes
cxid 4bytes
zxid 8bytes
time 8bytes
type 4bytes
}
Record
0x42
}
ZeroPad
在文件末尾添加0
FileTxnLog
主要属性
// 文件头部的magic数字
public final static int TXNLOG_MAGIC =
ByteBuffer.wrap("ZKLG".getBytes()).getInt();
// 上一个日志记录的事务id
long lastZxidSeen;
// 日志文件流
volatile BufferedOutputStream logStream = null;
volatile OutputArchive oa;
volatile FileOutputStream fos = null;
// 事务日志文件存放目录
File logDir;
// 当提交时是否确保同步到磁盘
private final boolean forceSync = !System.getProperty("zookeeper.forceSync", "yes").equals("no");
// 内存数据库id
long dbId;
// 等待flush的流
private LinkedList<FileOutputStream> streamsToFlush =
new LinkedList<FileOutputStream>();
内部类
PositionInputStream#
PositionInputStream是一个能够记录当前读入位置的输入流,实现方式就是每次从输入流中读取数据后,就会增加position
static class PositionInputStream extends FilterInputStream {
long position;
protected PositionInputStream(InputStream in) {
super(in);
position = 0;
}
@Override
public int read() throws IOException {
int rc = super.read();
if (rc > -1) {
position++;
}
return rc;
}
public int read(byte[] b) throws IOException {
int rc = super.read(b);
if (rc > 0) {
position += rc;
}
return rc;
}
@Override
public int read(byte[] b, int off, int len) throws IOException {
int rc = super.read(b, off, len);
if (rc > 0) {
position += rc;
}
return rc;
}
@Override
public long skip(long n) throws IOException {
long rc = super.skip(n);
if (rc > 0) {
position += rc;
}
return rc;
}
public long getPosition() {
return position;
}
@Override
public boolean markSupported() {
return false;
}
@Override
public void mark(int readLimit) {
throw new UnsupportedOperationException("mark");
}
@Override
public void reset() {
throw new UnsupportedOperationException("reset");
}
}
FileTxnIterator#
FileTxnIterator的作用就是从事务日志中读取事务记录
首先,会解析日志目录下的文件,提取文件名中的zxid作为当前日志包含事务日志中的最小事务id
然后,将zxid大于等于指定事务id以及小于zxid的最大zxid事务日志文件保存下下来,并根据zxid递减排序
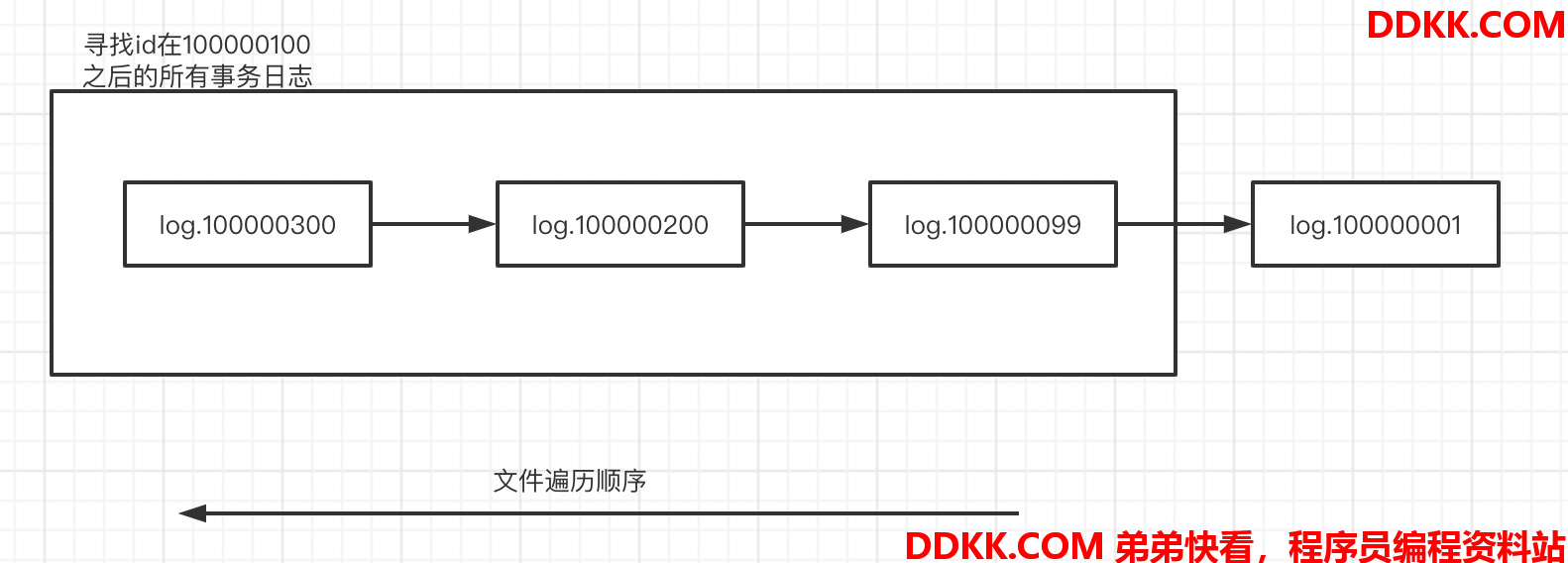
public static class FileTxnIterator implements TxnLog.TxnIterator {
// 日志文件目录
File logDir;
// 当前记录的事务id
long zxid;
// 当前记录的头
TxnHeader hdr;
// 当前记录的内容
Record record;
File logFile;
InputArchive ia;
static final String CRC_ERROR="CRC check failed";
PositionInputStream inputStream=null;
// 包含有大于指定事务id的事务文件
private ArrayList<File> storedFiles;
public FileTxnIterator(File logDir, long zxid, boolean fastForward)
throws IOException {
this.logDir = logDir;
this.zxid = zxid;
// 找到可能包含指定事务id的所有日志,并且排序
init();
// 如果设置了fastForward,会快速定位到该zxid位置,否则会定位到可能包含该zxid的日志的头部
if (fastForward && hdr != null) {
while (hdr.getZxid() < zxid) {
if (!next())
break;
}
}
}
/**
* create an iterator over a transaction database directory
* @param logDir the transaction database directory
* @param zxid the zxid to start reading from
* @throws IOException
*/
public FileTxnIterator(File logDir, long zxid) throws IOException {
this(logDir, zxid, true);
}
void init() throws IOException {
storedFiles = new ArrayList<File>();
// 根据文件名中的zxid进行递减排序
List<File> files = Util.sortDataDir(FileTxnLog.getLogFiles(logDir.listFiles(), 0), LOG_FILE_PREFIX, false);
// 筛选出大于指定zxid的日志和第一个小于zxid的日志文件
for (File f: files) {
if (Util.getZxidFromName(f.getName(), LOG_FILE_PREFIX) >= zxid) {
storedFiles.add(f);
}
// add the last logfile that is less than the zxid
else if (Util.getZxidFromName(f.getName(), LOG_FILE_PREFIX) < zxid) {
storedFiles.add(f);
break;
}
}
// 创建一个指向最后一个文件的输入流
goToNextLog();
// 定位到该文件中的第一条记录
next();
}
// 返回当前还没有处理的日志的预估大小
public long getStorageSize() {
long sum = 0;
for (File f : storedFiles) {
sum += f.length();
}
return sum;
}
// 移动到下一个日志文件,按照zxid递增的顺序来遍历文件
private boolean goToNextLog() throws IOException {
if (storedFiles.size() > 0) {
this.logFile = storedFiles.remove(storedFiles.size()-1);
ia = createInputArchive(this.logFile);
return true;
}
return false;
}
// 移动到下一个事务日志
public boolean next() throws IOException {
if (ia == null) {
return false;
}
try {
// 从日志文件输入流中恢复出日志记录
long crcValue = ia.readLong("crcvalue");
byte[] bytes = Util.readTxnBytes(ia);
// Since we preallocate, we define EOF to be an
if (bytes == null || bytes.length==0) {
throw new EOFException("Failed to read " + logFile);
}
// EOF or corrupted record
// validate CRC
Checksum crc = makeChecksumAlgorithm();
crc.update(bytes, 0, bytes.length);
if (crcValue != crc.getValue())
throw new IOException(CRC_ERROR);
hdr = new TxnHeader();
record = SerializeUtils.deserializeTxn(bytes, hdr);
} catch (EOFException e) {
// EOFException异常代表当前文件读取完毕,尝试调用toToNextLog切换到下一个文件
LOG.debug("EOF exception " + e);
inputStream.close();
inputStream = null;
ia = null;
hdr = null;
// this means that the file has ended
// we should go to the next file
if (!goToNextLog()) {
return false;
}
// if we went to the next log file, we should call next() again
return next();
} catch (IOException e) {
inputStream.close();
throw e;
}
return true;
}
/**
* return the current header
* @return the current header that
* is read
*/
public TxnHeader getHeader() {
return hdr;
}
/**
* return the current transaction
* @return the current transaction
* that is read
*/
public Record getTxn() {
return record;
}
/**
* close the iterator
* and release the resources.
*/
public void close() throws IOException {
if (inputStream != null) {
inputStream.close();
}
}
}
重要方法
append#
// FileTxnLog
public synchronized boolean append(TxnHeader hdr, Record txn)
throws IOException
{
if (hdr == null) {
return false;
}
// 如果当前的事务id小于日志中最大的事务id
// 从这里可以看出事务日志中的事务日志的事务id并不是一定递增的
if (hdr.getZxid() <= lastZxidSeen) {
LOG.warn("Current zxid " + hdr.getZxid()
+ " is <= " + lastZxidSeen + " for "
+ hdr.getType());
} else {
// 更新日志事务id的最大值
lastZxidSeen = hdr.getZxid();
}
// 当前没有创建日志文件
if (logStream==null) {
if(LOG.isInfoEnabled()){
LOG.info("Creating new log file: " + Util.makeLogName(hdr.getZxid()));
}
// 在logDir目录下创建log.当前事务记录id的日志文件
logFileWrite = new File(logDir, Util.makeLogName(hdr.getZxid()));
// 创建文件的输出流
fos = new FileOutputStream(logFileWrite);
logStream=new BufferedOutputStream(fos);
oa = BinaryOutputArchive.getArchive(logStream);
FileHeader fhdr = new FileHeader(TXNLOG_MAGIC,VERSION, dbId);
// 将文件头写入到文件中
fhdr.serialize(oa, "fileheader");
// Make sure that the magic number is written before padding.
logStream.flush();
filePadding.setCurrentSize(fos.getChannel().position());
// 将当前流加入到需要flush的流列表中
streamsToFlush.add(fos);
}
filePadding.padFile(fos.getChannel());
// 将当前事务记录的头和内容序列化成字节数组
byte[] buf = Util.marshallTxnEntry(hdr, txn);
if (buf == null || buf.length == 0) {
throw new IOException("Faulty serialization for header " +
"and txn");
}
// 计算头部和内容的校验和
Checksum crc = makeChecksumAlgorithm();
crc.update(buf, 0, buf.length);
// 将校验和写入到文件中
oa.writeLong(crc.getValue(), "txnEntryCRC");
// 将事务头部、内容以及EOR写入到文件中
Util.writeTxnBytes(oa, buf);
return true;
}
上述方法首先判断当前是否有正在写的日志文件,如果没有会使用当前事务id生成log.事务id的事务日志文件
然后按照日志的格式,将当前事务记录写入到文件中
commit#
// FileTxnLog
public synchronized void commit() throws IOException {
// 当前有正在写入的日志文件,将数据刷写到操作系统,此时并不保证已经落盘
if (logStream != null) {
logStream.flush();
}
// 遍历streamToFlush,当前正在写入的流也已经加入到了streamsToFlush
for (FileOutputStream log : streamsToFlush) {
// 刷写到操作系统
log.flush();
// 如果需要保证落盘,开始落盘
if (forceSync) {
long startSyncNS = System.nanoTime();
FileChannel channel = log.getChannel();
channel.force(false);
// 记录当前文件落盘时间
syncElapsedMS = TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - startSyncNS);
// 落盘时间超过指定的阈值,记录超出此时,并打印提示日志
if (syncElapsedMS > fsyncWarningThresholdMS) {
if(serverStats != null) {
serverStats.incrementFsyncThresholdExceedCount();
}
LOG.warn("fsync-ing the write ahead log in "
+ Thread.currentThread().getName()
+ " took " + syncElapsedMS
+ "ms which will adversely effect operation latency. "
+ "File size is " + channel.size() + " bytes. "
+ "See the ZooKeeper troubleshooting guide");
}
}
}
// 关闭streamsToFlush中的流,并清空streamsToFlush
while (streamsToFlush.size() > 1) {
streamsToFlush.removeFirst().close();
}
}
该方法的作用是保证生成的事务日志文件都刷写到操作系统中,如果设置了强制落盘,会落盘
read#
返回一个迭代器,该迭代器定位到了大于指定zxid的事务记录
public TxnIterator read(long zxid, boolean fastForward) throws IOException {
return new FileTxnIterator(logDir, zxid, fastForward);
}
rollLog#
// FileTxnLog
public synchronized void rollLog() throws IOException {
// flush当前写的事务日志文件流
if (logStream != null) {
this.logStream.flush();
this.logStream = null;
oa = null;
}
}
滚动当前日志
close#
// FileTxnLog
public synchronized void close() throws IOException {
// 关闭日志文件流
if (logStream != null) {
logStream.close();
}
for (FileOutputStream log : streamsToFlush) {
log.close();
}
}
truncate#
public boolean truncate(long zxid) throws IOException {
FileTxnIterator itr = null;
try {
itr = new FileTxnIterator(this.logDir, zxid);
PositionInputStream input = itr.inputStream;
if(input == null) {
throw new IOException("No log files found to truncate! This could " +
"happen if you still have snapshots from an old setup or " +
"log files were deleted accidentally or dataLogDir was changed in zoo.cfg.");
}
long pos = input.getPosition();
// now, truncate at the current position
// 截断当前文件
RandomAccessFile raf=new RandomAccessFile(itr.logFile,"rw");
raf.setLength(pos);
raf.close();
// 将之后的日志文件全部删除
while(itr.goToNextLog()) {
if (!itr.logFile.delete()) {
LOG.warn("Unable to truncate {}", itr.logFile);
}
}
} finally {
close(itr);
}
return true;
}
快照日志
SnapShot
public interface SnapShot {
// 从最近的快照中恢复DateTree和session
long deserialize(DataTree dt, Map<Long, Integer> sessions)
throws IOException;
// 将当前的DataTree和session序列化到文件中
void serialize(DataTree dt, Map<Long, Integer> sessions,
File name)
throws IOException;
// 返回最近生成的快照文件
File findMostRecentSnapshot() throws IOException;
// 关闭序列化
void close() throws IOException;
}
FileSnap
FileSnap是SnapShot的实现
主要属性
// 快照文件目录
File snapDir;
// 是否关闭快照
private volatile boolean close = false;
// 版本
private static final int VERSION = 2;
private static final long dbId = -1;
private static final Logger LOG = LoggerFactory.getLogger(FileSnap.class);
// 快照文件头部的magic字段
public final static int SNAP_MAGIC
= ByteBuffer.wrap("ZKSN".getBytes()).getInt();
// 快照文件前缀
public static final String SNAPSHOT_FILE_PREFIX = "snapshot";
重要方法
serialize
// FileSnap
public synchronized void serialize(DataTree dt, Map<Long, Integer> sessions, File snapShot)
throws IOException {
if (!close) {
try (OutputStream sessOS = new BufferedOutputStream(new FileOutputStream(snapShot));
// CheckedOutputStream是带有校验的输出流,一边写一边更新校验值
CheckedOutputStream crcOut = new CheckedOutputStream(sessOS, new Adler32())) {
//CheckedOutputStream cout = new CheckedOutputStream()
OutputArchive oa = BinaryOutputArchive.getArchive(crcOut);
// 文件头
FileHeader header = new FileHeader(SNAP_MAGIC, VERSION, dbId);
// 实际进行序列化
serialize(dt, sessions, oa, header);
long val = crcOut.getChecksum().getValue();
// 写出校验值
oa.writeLong(val, "val");
oa.writeString("/", "path");
sessOS.flush();
}
}
}
// FileSnap
protected void serialize(DataTree dt,Map<Long, Integer> sessions,
OutputArchive oa, FileHeader header) throws IOException {
// this is really a programmatic error and not something that can
// happen at runtime
if(header==null)
throw new IllegalStateException(
"Snapshot's not open for writing: uninitialized header");
// 写入文件头
header.serialize(oa, "fileheader");
// 写入DataTree 和 session
SerializeUtils.serializeSnapshot(dt,oa,sessions);
}
// SerializeUtils
public static void serializeSnapshot(DataTree dt,OutputArchive oa,
Map<Long, Integer> sessions) throws IOException {
HashMap<Long, Integer> sessSnap = new HashMap<Long, Integer>(sessions);
// 写入当前事务的个数
oa.writeInt(sessSnap.size(), "count");
// 遍历事务,写入事务的id和过期时间
for (Entry<Long, Integer> entry : sessSnap.entrySet()) {
oa.writeLong(entry.getKey().longValue(), "id");
oa.writeInt(entry.getValue().intValue(), "timeout");
}
// 写入dataTree
dt.serialize(oa, "tree");
}
下面看下如何序列化DataTree
public void serialize(OutputArchive oa, String tag) throws IOException {
// 序列化aclCache
aclCache.serialize(oa);
// 序列化节点
serializeNode(oa, new StringBuilder(""));
// / marks end of stream
// we need to check if clear had been called in between the snapshot.
if (root != null) {
oa.writeString("/", "path");
}
}
void serializeNode(OutputArchive oa, StringBuilder path) throws IOException {
String pathString = path.toString();
// 获取路径对应的节点
DataNode node = getNode(pathString);
if (node == null) {
return;
}
String children[] = null;
// 拷贝当前节点
DataNode nodeCopy;
synchronized (node) {
StatPersisted statCopy = new StatPersisted();
copyStatPersisted(node.stat, statCopy);
//we do not need to make a copy of node.data because the contents
//are never changed
nodeCopy = new DataNode(node.data, node.acl, statCopy);
Set<String> childs = node.getChildren();
children = childs.toArray(new String[childs.size()]);
}
// 序列化节点
serializeNodeData(oa, pathString, nodeCopy);
path.append('/');
int off = path.length();
// 遍历子节点并进行序列化
for (String child : children) {
// since this is single buffer being resused
// we need
// to truncate the previous bytes of string.
path.delete(off, Integer.MAX_VALUE);
path.append(child);
serializeNode(oa, path);
}
}
下面看下如何序列化DataTree中的一个节点
public void serializeNodeData(OutputArchive oa, String path, DataNode node) throws IOException {
// 首先写入路径
oa.writeString(path, "path");
// 写入节点内容
oa.writeRecord(node, "node");
}
// DataNode
synchronized public void serialize(OutputArchive archive, String tag)
throws IOException {
archive.startRecord(this, "node");
// 写入数据
archive.writeBuffer(data, "data");
// 写入acl值
archive.writeLong(acl, "acl");
// 写入状态,比如修改时间,创建时间等
stat.serialize(archive, "statpersisted");
archive.endRecord(this, "node");
}
findNValidSnapshots
寻找最近的n个快照文件
private List<File> findNValidSnapshots(int n) throws IOException {
// 遍历快照日志下的文件,从文件名中提取事务id,按照事务id递减排序文件
List<File> files = Util.sortDataDir(snapDir.listFiles(), SNAPSHOT_FILE_PREFIX, false);
int count = 0;
List<File> list = new ArrayList<File>();
// 从这些文件中找到校验通过的n个文件
for (File f : files) {
// we should catch the exceptions
// from the valid snapshot and continue
// until we find a valid one
try {
if (Util.isValidSnapshot(f)) {
list.add(f);
count++;
if (count == n) {
break;
}
}
} catch (IOException e) {
LOG.info("invalid snapshot " + f, e);
}
}
return list;
}
findNRecentSnapshots
遍历快照目录下的快照文件,寻找最近的n个快照
public List<File> findNRecentSnapshots(int n) throws IOException {
List<File> files = Util.sortDataDir(snapDir.listFiles(), SNAPSHOT_FILE_PREFIX, false);
int count = 0;
List<File> list = new ArrayList<File>();
for (File f: files) {
if (count == n)
break;
if (Util.getZxidFromName(f.getName(), SNAPSHOT_FILE_PREFIX) != -1) {
count++;
list.add(f);
}
}
return list;
}
findMostRecentSnapshot
遍历快照目录下的快照文件,找到最近的快照文件
public File findMostRecentSnapshot() throws IOException {
List<File> files = findNValidSnapshots(1);
if (files.size() == 0) {
return null;
}
return files.get(0);
}
deserialize
public long deserialize(DataTree dt, Map<Long, Integer> sessions)
throws IOException {
// we run through 100 snapshots (not all of them)
// if we cannot get it running within 100 snapshots
// we should give up
// 找到最近有效的100个快照文件
// 这里找到的文件并不一定是完全有效的
List<File> snapList = findNValidSnapshots(100);
if (snapList.size() == 0) {
return -1L;
}
File snap = null;
boolean foundValid = false;
// 遍历找到的快照文件,读取文件,并且计算校验和,校验文件是否有效
// 序列化该文件到DateTree session
for (int i = 0, snapListSize = snapList.size(); i < snapListSize; i++) {
snap = snapList.get(i);
LOG.info("Reading snapshot " + snap);
try (InputStream snapIS = new BufferedInputStream(new FileInputStream(snap));
CheckedInputStream crcIn = new CheckedInputStream(snapIS, new Adler32())) {
InputArchive ia = BinaryInputArchive.getArchive(crcIn);
deserialize(dt, sessions, ia);
long checkSum = crcIn.getChecksum().getValue();
long val = ia.readLong("val");
if (val != checkSum) {
throw new IOException("CRC corruption in snapshot : " + snap);
}
foundValid = true;
break;
} catch (IOException e) {
LOG.warn("problem reading snap file " + snap, e);
}
}
if (!foundValid) {
throw new IOException("Not able to find valid snapshots in " + snapDir);
}
dt.lastProcessedZxid = Util.getZxidFromName(snap.getName(), SNAPSHOT_FILE_PREFIX);
return dt.lastProcessedZxid;
}
FileTxnSnapLog
主要属性
// 事务日志目录
private final File dataDir;
// 快照文件目录
private final File snapDir;
// 事务日志
private TxnLog txnLog;
// 快照
private SnapShot snapLog;
private final boolean trustEmptySnapshot;
public final static int VERSION = 2;
public final static String version = "version-";
private static final Logger LOG = LoggerFactory.getLogger(FileTxnSnapLog.class);
// 当目录不存在时是否自动创建目录
public static final String ZOOKEEPER_DATADIR_AUTOCREATE =
"zookeeper.datadir.autocreate";
public static final String ZOOKEEPER_DATADIR_AUTOCREATE_DEFAULT = "true";
重要方法
构造方法
// FileTxnSnapLog
public FileTxnSnapLog(File dataDir, File snapDir) throws IOException {
LOG.debug("Opening datadir:{} snapDir:{}", dataDir, snapDir);
// 事务日志文件目录和快照文件目录
// ${dataDir}/version-2
this.dataDir = new File(dataDir, version + VERSION);
this.snapDir = new File(snapDir, version + VERSION);
// 判断是否自动创建目录
boolean enableAutocreate = Boolean.valueOf(
System.getProperty(ZOOKEEPER_DATADIR_AUTOCREATE,
ZOOKEEPER_DATADIR_AUTOCREATE_DEFAULT));
trustEmptySnapshot = Boolean.getBoolean(ZOOKEEPER_SNAPSHOT_TRUST_EMPTY);
LOG.info(ZOOKEEPER_SNAPSHOT_TRUST_EMPTY + " : " + trustEmptySnapshot);
// 创建目录
if (!this.dataDir.exists()) {
if (!enableAutocreate) {
throw new DatadirException("Missing data directory "
+ this.dataDir
+ ", automatic data directory creation is disabled ("
+ ZOOKEEPER_DATADIR_AUTOCREATE
+ " is false). Please create this directory manually.");
}
if (!this.dataDir.mkdirs()) {
throw new DatadirException("Unable to create data directory "
+ this.dataDir);
}
}
if (!this.dataDir.canWrite()) {
throw new DatadirException("Cannot write to data directory " + this.dataDir);
}
if (!this.snapDir.exists()) {
// by default create this directory, but otherwise complain instead
// See ZOOKEEPER-1161 for more details
if (!enableAutocreate) {
throw new DatadirException("Missing snap directory "
+ this.snapDir
+ ", automatic data directory creation is disabled ("
+ ZOOKEEPER_DATADIR_AUTOCREATE
+ " is false). Please create this directory manually.");
}
if (!this.snapDir.mkdirs()) {
throw new DatadirException("Unable to create snap directory "
+ this.snapDir);
}
}
if (!this.snapDir.canWrite()) {
throw new DatadirException("Cannot write to snap directory " + this.snapDir);
}
// check content of transaction log and snapshot dirs if they are two different directories
// See ZOOKEEPER-2967 for more details
if(!this.dataDir.getPath().equals(this.snapDir.getPath())){
// 当事务日志目录和快照目录不同时,进行校验
// 判断日志目录下是否有快照文件
checkLogDir();
// 判断快照目录下是否有日志文件
checkSnapDir();
}
txnLog = new FileTxnLog(this.dataDir);
snapLog = new FileSnap(this.snapDir);
}
构造方法主要就是创建TxnLog和SnapLog
append
将请求透传给TxnLog
public boolean append(Request si) throws IOException {
return txnLog.append(si.getHdr(), si.getTxn());
}
save
使用DataTree中最新的事务id生成快照文件名,使用SnapLog来生成快照
public void save(DataTree dataTree,
ConcurrentHashMap<Long, Integer> sessionsWithTimeouts)
throws IOException {
long lastZxid = dataTree.lastProcessedZxid;
File snapshotFile = new File(snapDir, Util.makeSnapshotName(lastZxid));
LOG.info("Snapshotting: 0x{} to {}", Long.toHexString(lastZxid),
snapshotFile);
snapLog.serialize(dataTree, sessionsWithTimeouts, snapshotFile);
}
rollLog
public void rollLog() throws IOException {
txnLog.rollLog();
}
close
public void close() throws IOException {
txnLog.close();
snapLog.close();
}
truncateLog
关闭TxnLog和SnapShot,然后截断日志文件,重新创建TxnLog SnapShot
public boolean truncateLog(long zxid) throws IOException {
// close the existing txnLog and snapLog
close();
// truncate it
FileTxnLog truncLog = new FileTxnLog(dataDir);
boolean truncated = truncLog.truncate(zxid);
truncLog.close();
// re-open the txnLog and snapLog
// I'd rather just close/reopen this object itself, however that
// would have a big impact outside ZKDatabase as there are other
// objects holding a reference to this object.
txnLog = new FileTxnLog(dataDir);
snapLog = new FileSnap(snapDir);
return truncated;
}
restore
public long restore(DataTree dt, Map<Long, Integer> sessions,
PlayBackListener listener) throws IOException {
// 使用最近的有效快照文件来还原DataTree和session
long deserializeResult = snapLog.deserialize(dt, sessions);
FileTxnLog txnLog = new FileTxnLog(dataDir);
if (-1L == deserializeResult) {
/* this means that we couldn't find any snapshot, so we need to
* initialize an empty database (reported in ZOOKEEPER-2325) */
if (txnLog.getLastLoggedZxid() != -1) {
// ZOOKEEPER-3056: provides an escape hatch for users upgrading
// from old versions of zookeeper (3.4.x, pre 3.5.3).
if (!trustEmptySnapshot) {
throw new IOException(EMPTY_SNAPSHOT_WARNING + "Something is broken!");
} else {
LOG.warn(EMPTY_SNAPSHOT_WARNING + "This should only be allowed during upgrading.");
}
}
/* TODO: (br33d) we should either put a ConcurrentHashMap on restore()
* or use Map on save() */
save(dt, (ConcurrentHashMap<Long, Integer>)sessions);
/* return a zxid of zero, since we the database is empty */
return 0;
}
// 接着使用事务日志来恢复
return fastForwardFromEdits(dt, sessions, listener);
}
public long fastForwardFromEdits(DataTree dt, Map<Long, Integer> sessions,
PlayBackListener listener) throws IOException {
// 经过快照还原后,dt.lastProcessedZxid即是快照文件中存放的最大事务id
// 从事务日志中接着该事务id接着还原
TxnIterator itr = txnLog.read(dt.lastProcessedZxid+1);
long highestZxid = dt.lastProcessedZxid;
TxnHeader hdr;
try {
while (true) {
// iterator points to
// the first valid txn when initialized
hdr = itr.getHeader();
if (hdr == null) {
//empty logs
return dt.lastProcessedZxid;
}
// 更新目前处理过的最大事务id
if (hdr.getZxid() < highestZxid && highestZxid != 0) {
LOG.error("{}(highestZxid) > {}(next log) for type {}",
highestZxid, hdr.getZxid(), hdr.getType());
} else {
highestZxid = hdr.getZxid();
}
try {
// 处理事务
processTransaction(hdr,dt,sessions, itr.getTxn());
} catch(KeeperException.NoNodeException e) {
throw new IOException("Failed to process transaction type: " +
hdr.getType() + " error: " + e.getMessage(), e);
}
listener.onTxnLoaded(hdr, itr.getTxn());
if (!itr.next())
break;
}
} finally {
if (itr != null) {
itr.close();
}
}
return highestZxid;
}
版权声明:「DDKK.COM 弟弟快看,程序员编程资料站」本站文章,版权归原作者所有