映射关系(mapping)
类比关系型数据库,我们在插入数据之前我们需要首先去创建表结构, 而我们以上对文档的操作却一路没有进行结构的创建,其实在ES中确实可以不创建类似于表结构的东西,但是他也是可以创建表结构的。
在ES中这个表结构叫着映射。它主要的作用就是用于定义字段是否被分词和被检索。
测试准备工作
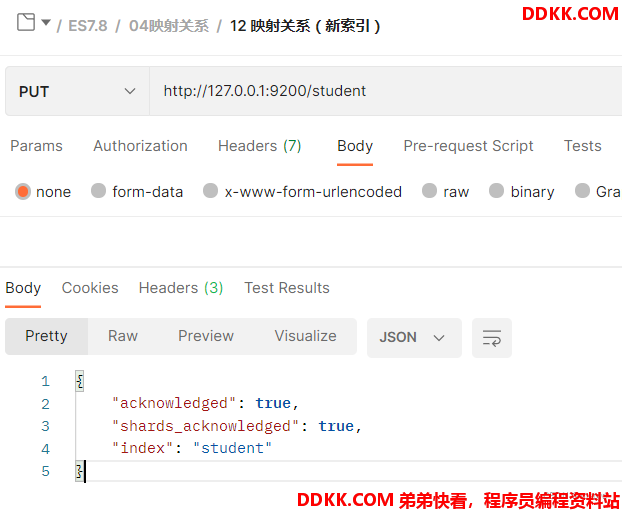
为了更好的实现我们首先创建一个新的索引student.
创建映射关系
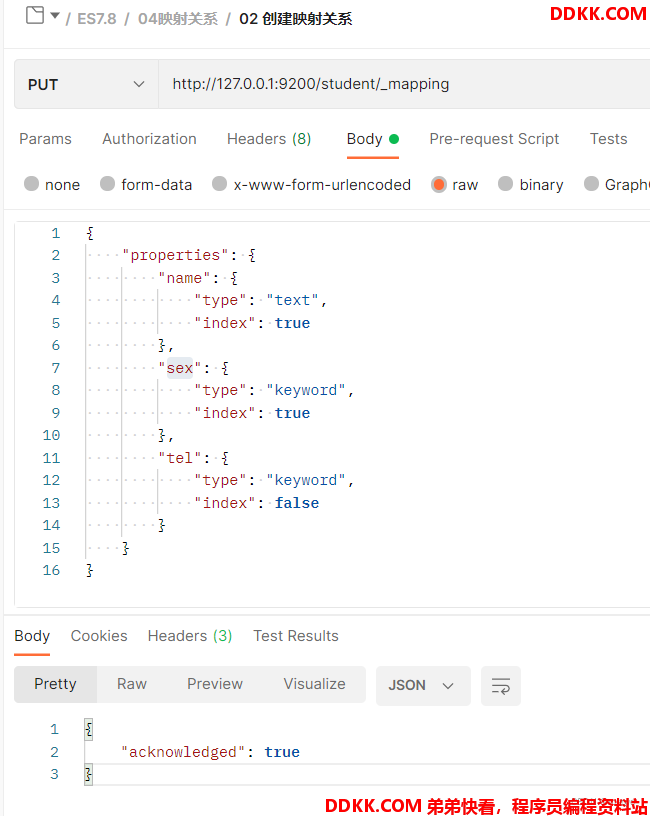
创建新索引之后我们再新索引上建立映射关系。建立映射关系同样要使用PUT请求,请求的URL地址:http://127.0.0.1:9200/student/_mapping
插入测试数据
为了测试插入三条数据,
数据1
{
"name": "张三",
"sex": "男的",
"tel": "18180486815"
}
数据2
{
"name": "张三丰",
"sex": "男学生",
"tel": "18180486814"
}
数据3
{
"name": "张无极",
"sex": "男",
"tel": "18180486823"
}
查询一下保存的结果:
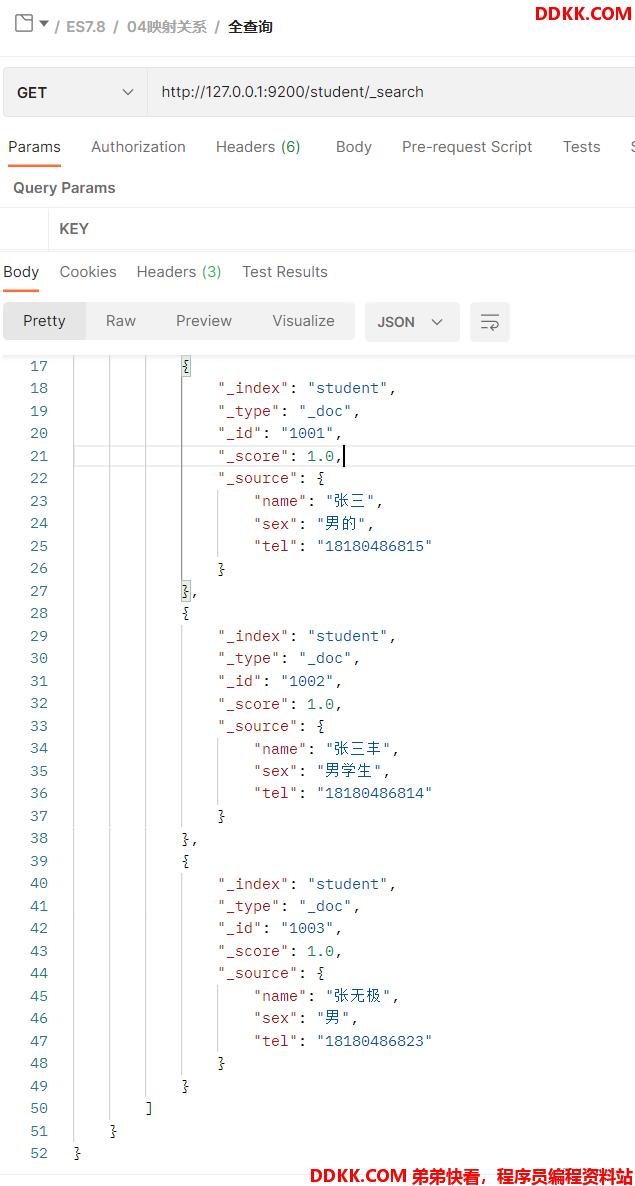
从结果上看已经将测试数据插入成功了。
测试
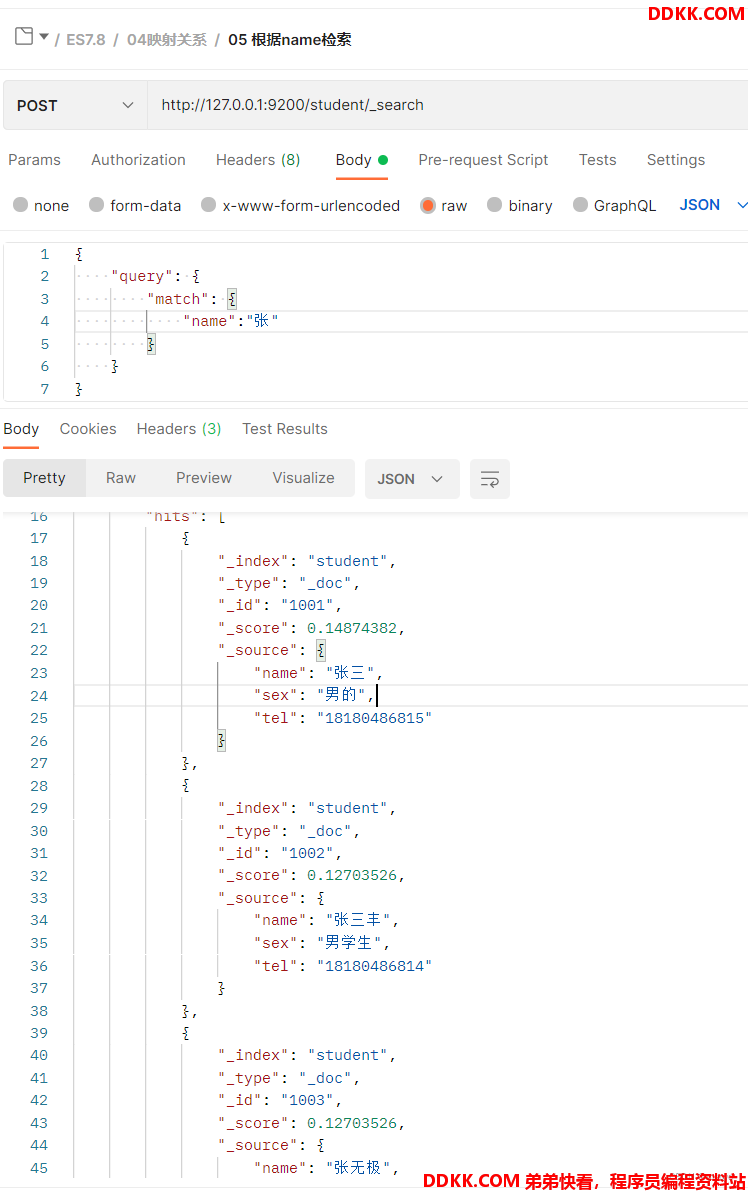
根据name查询
根据name查询,验证检索结果。
响应结果:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 0.14874382,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 0.14874382,
"_source": {
"name": "张三",
"sex": "男的",
"tel": "18180486815"
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": 0.12703526,
"_source": {
"name": "张三丰",
"sex": "男学生",
"tel": "18180486814"
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1003",
"_score": 0.12703526,
"_source": {
"name": "张无极",
"sex": "男",
"tel": "18180486823"
}
}
]
}
}
如果使用name为张极进行查询:
{
"query": {
"match": {
"name":"张极"
}
}
}
响应的结果仍然包含了三条数据,只是因为命中得分顺序发生了改变:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1.0601485,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1003",
"_score": 1.0601485,
"_source": {
"name": "张无极",
"sex": "男",
"tel": "18180486823"
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 0.14874382,
"_source": {
"name": "张三",
"sex": "男的",
"tel": "18180486815"
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": 0.12703526,
"_source": {
"name": "张三丰",
"sex": "男学生",
"tel": "18180486814"
}
}
]
}
}
根据查询的返回结果可以看出,根据张可以查询出所有的name字段带张的文档。也就是说name字段支持全量查询,即验证了text类型是支持全量查询的。
根据keyword类型的sex进行检索
首先将sex查询的内容设置为男。检索的内容体为:
{
"query": {
"match": {
"sex":"男"
}
}
}
执行查询
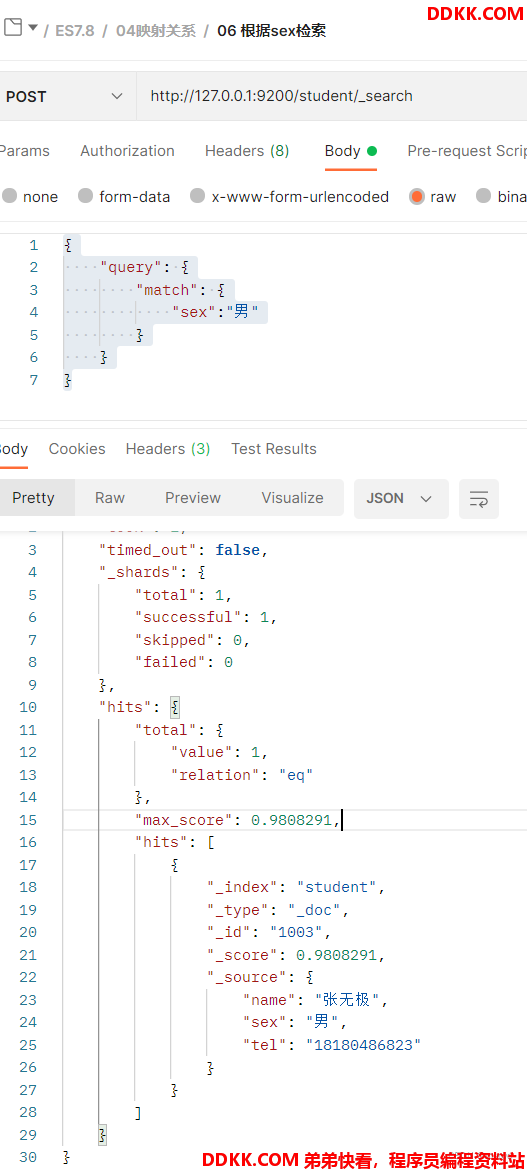
响应结果为:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.9808291,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1003",
"_score": 0.9808291,
"_source": {
"name": "张无极",
"sex": "男",
"tel": "18180486823"
}
}
]
}
}
从结果上可以看出, 该字段精准的匹配了为男的性别,而没匹配上另外两条数据。也就是说,keyword类型的字段是不会进行分词存储的。
测试index=false的映射
我们在创建映射关系时,tel字段设置的index为false。我们再来测试通过tel字段检索。
body:
{
"query": {
"match": {
"tel":"18180486814"
}
}
}
操作
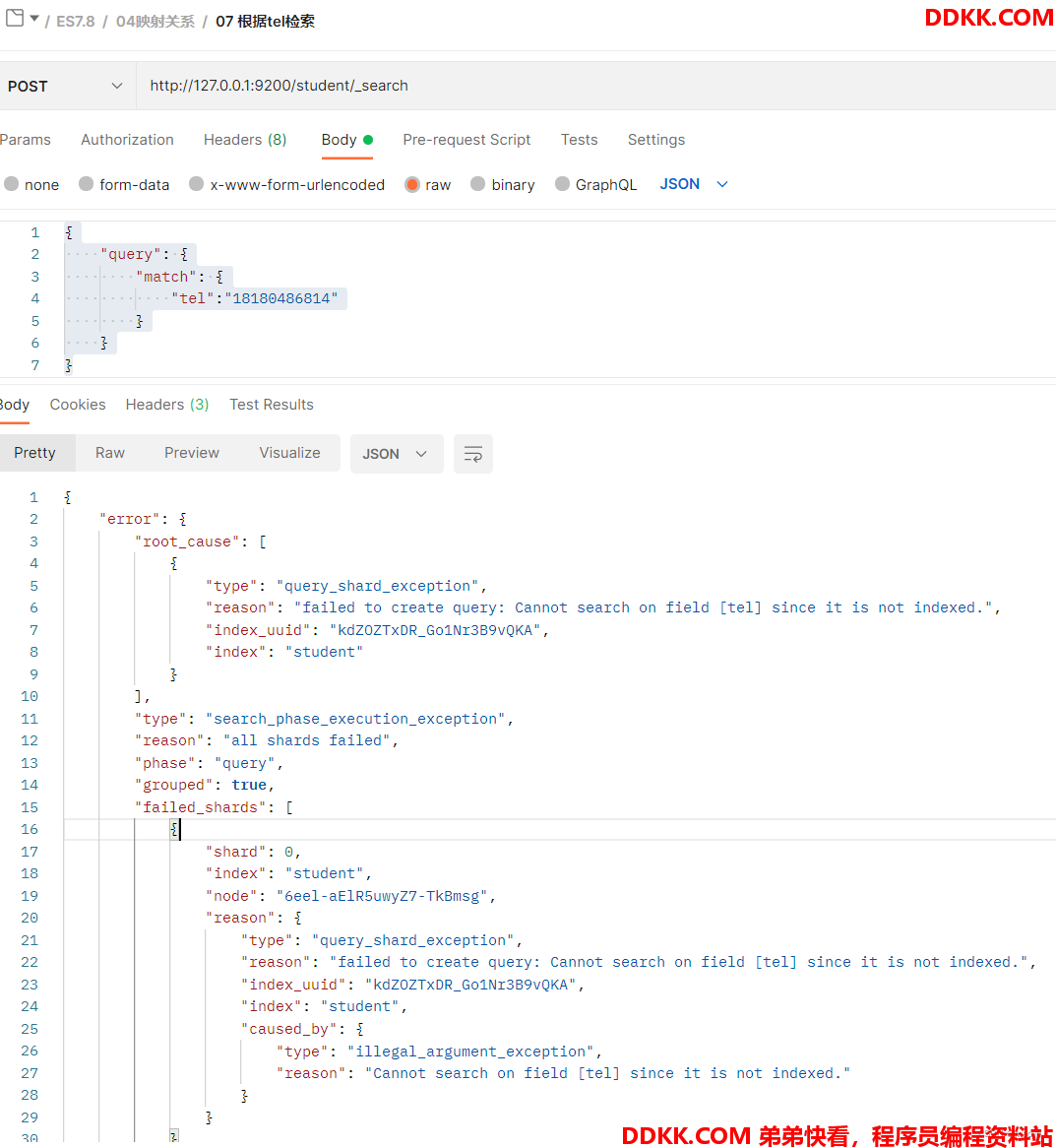
通过查询可以知道,明显查询结果是失败了。并且后台爆出了查询错误提示.
{
"error": {
"root_cause": [
{
"type": "query_shard_exception",
"reason": "failed to create query: Cannot search on field [tel] since it is not indexed.",
"index_uuid": "kdZOZTxDR_Go1Nr3B9vQKA",
"index": "student"
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "student",
"node": "6eel-aElR5uwyZ7-TkBmsg",
"reason": {
"type": "query_shard_exception",
"reason": "failed to create query: Cannot search on field [tel] since it is not indexed.",
"index_uuid": "kdZOZTxDR_Go1Nr3B9vQKA",
"index": "student",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Cannot search on field [tel] since it is not indexed."
}
}
}
]
},
"status": 400
}
可以总结了,index设置为了false的字段其实就是不能被检索的。
总结
1、text类型;
-
会进行分词,分词后建立索引。
-
支持模糊查询,支持精准查询。
-
不支持聚合查询。 2、
keyword类型; -
不分词,直接建立索引。
-
支持模糊查询, 支持准确查询。
-
支持聚合查询。 3、
index; -
控制是否可以被用于检索
-
false, 不能被用于检索 -
true, 可以被用于检索