0. 引言
前几章我们已经讲解了solr单机版的基本使用,但实际生产中,为了保证高可用、高性能,我们一般会采用集群模式,所以接下来,我们继续讲解solr集群的搭建和基本操作
1. 集群模式
1.1 分片
在讲解solr集群模式前,我们要先了解“分片”的概念。
当节点由一个拓展为多个时,数据存储和同步问题也随之而来,如果单纯的把数据存储到某一个节点,高可用的目的又实现不了了,如果把数据在每个节点中都存储,那么又会导致空间浪费,于是就出现了分片的概念。
所谓分片就是将数据分成多份,每一份就是一个分片,然后将这些分片存储到不同的节点上,以此实现存储扩展,同时因为不同的数据存储在不同的节点上,实际上也提高了查询的性能。
并且这些分片里,还分为主分片盒副本分片,主分片是不同的数据,副本分片则是主分片的备份,然后将这些分片分布到不同的节点上,这样既实现了数据存储,也实现了数据备份
因为要实现高可用,所以要求相同的主副分片不能在同一个节点上,否则当一个节点挂了,副分片也跟着挂了
1.2 节点治理
当节点变多了之后,节点之间的调用协调就成了问题,solr没有自带服务治理,也就需要引入第三方组件,一般我们通过zookeeper来作为注册中心,管理服务调度
同时为了保证注册中心的高可用,因此我们的zookeeper也需要部署成集群模式。可能有的同学会有疑惑,zk部署成集群模式了,那么又是谁来协调zk多节点呢,这个当然是zk自身了,它的集群模式自带了服务治理功能
1.3 部署架构
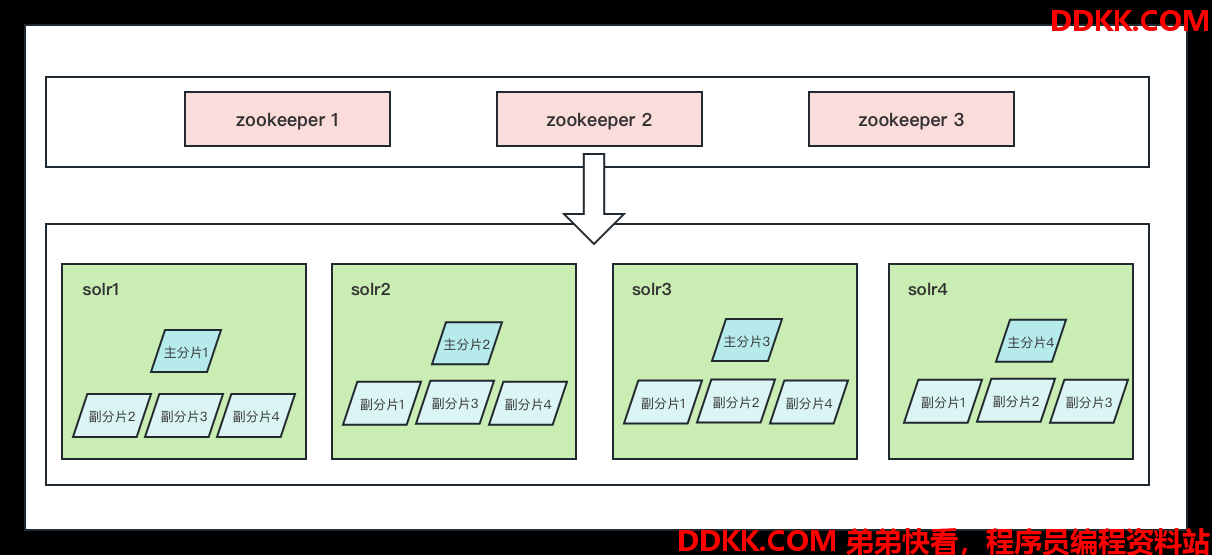
有了以上的基础概念后,我们再来梳理所要部署的solr集群架构。
首先集群模式最小主节点数是3个,这里为了模拟线上环境,搭建4个主分片,每个主分片3个副本分片的效果,我采用4个节点,具体大家可根据服务器环境来选择节点数,但不要小于3个
其次zookeeper搭建集群,最小节点数是3个,于是部署架构如下图所示
2. 搭建
2.1 搭建zookeeper集群
zookeeper的集群搭建可我另一篇文章:搭建zookeeper集群并设置开机自启
但是注意因为我solr版本用的是8.2.0,zookeeper对应版本选3.4.14,版本不对应可能有连接问题。会导致报错TimeoutException: Could not connect to ZooKeeper
2.2 搭建solr集群
1、 之前我们已经搭建过solr单节点,将该节点复制3份到其他3个服务器;
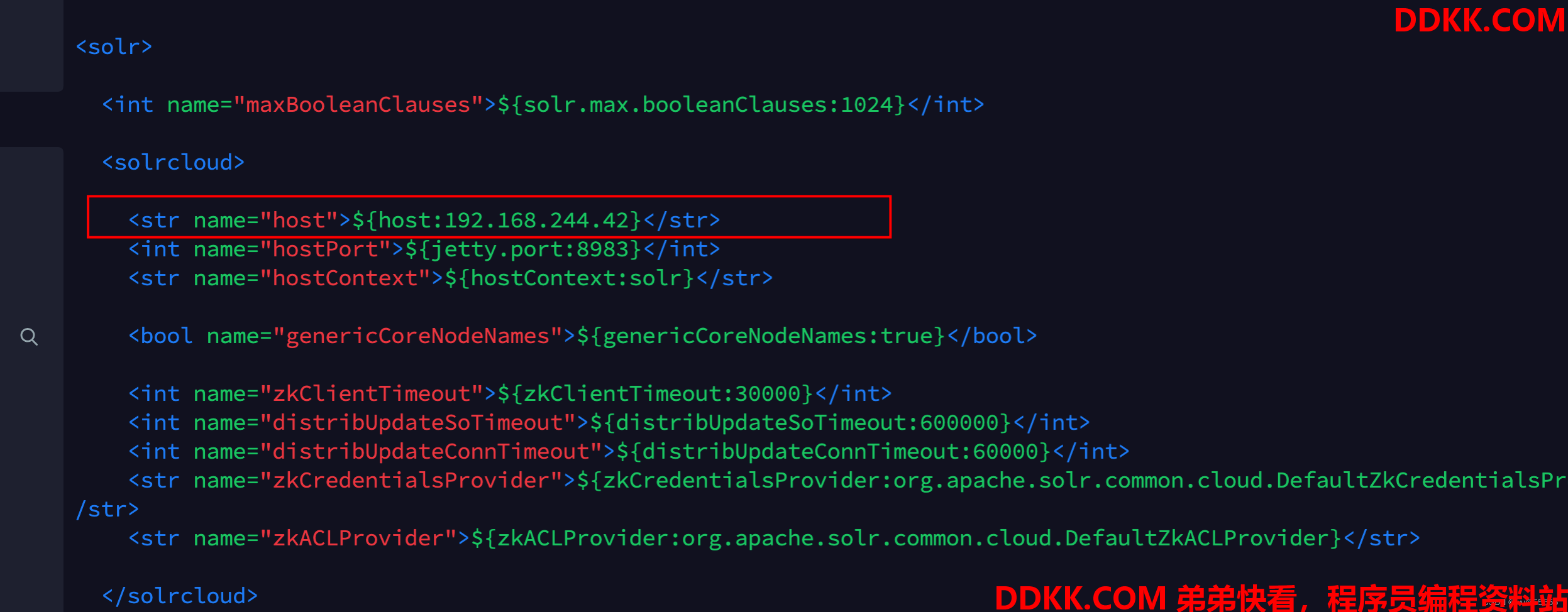
2、 修改solr配置文件solr.xml;
vim server/solr/solr.xml
内容,调整为服务器solr服务器ip,如果端口有调整的话直接修改即可
3、 修改启动脚本文件solr.in.sh,配置zk地址;
vim bin/solr.in.sh
内容
ZK_HOST="192.168.244.42:2181,192.168.244.43:2181,192.168.244.44:2181"
# Set the ZooKeeper client timeout (for SolrCloud mode)
ZK_CLIENT_TIMEOUT="15000"
4、 在其他3个节点,同步调整上述2步;
5、 重启四个solr节点;
# 如下启动指令是单独配置的,参考专栏第一篇文章
service solr restart
能够正常访问solr-admin即证明集群部署成功!
这里如果发现报错SolrException: ruok is not executed because it is not in the whitelist. Check 4lw.commands.whitelist setting in zookeeper configuration file
这是因为要想在不登陆zk客户端的情况下,简单便捷的使用zk的四字指令时,比如ruok是查看zk是否启动的指令,就需要添加zk允许的指令白名单
在zookeeper配置文件conf/zoo.cfg中添加配置项4lw.commands.whitelist=stat,ruok,conf,isro,设置指定的四字指令被远程调用,如果设置的是*则表示所有的指令都允许被调用
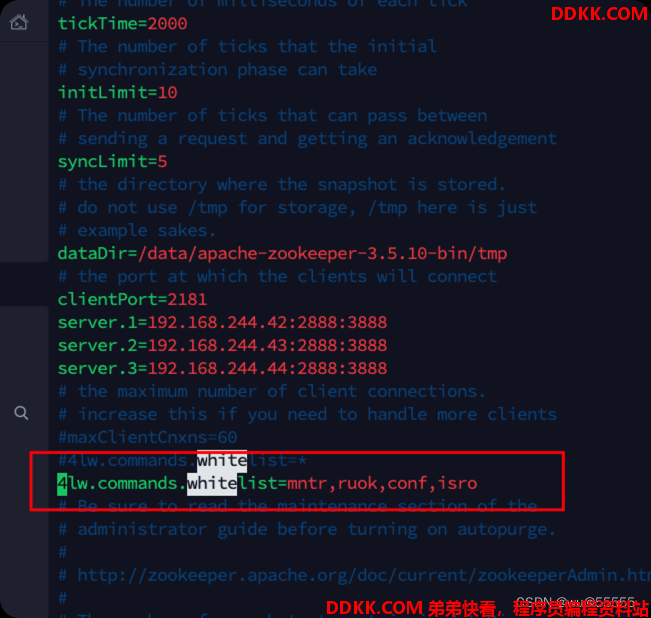
配置完后重启zk,solr,如果是集群记得修改每个zk节点
正常启动,可以在Cloud菜单查看集群节点情况
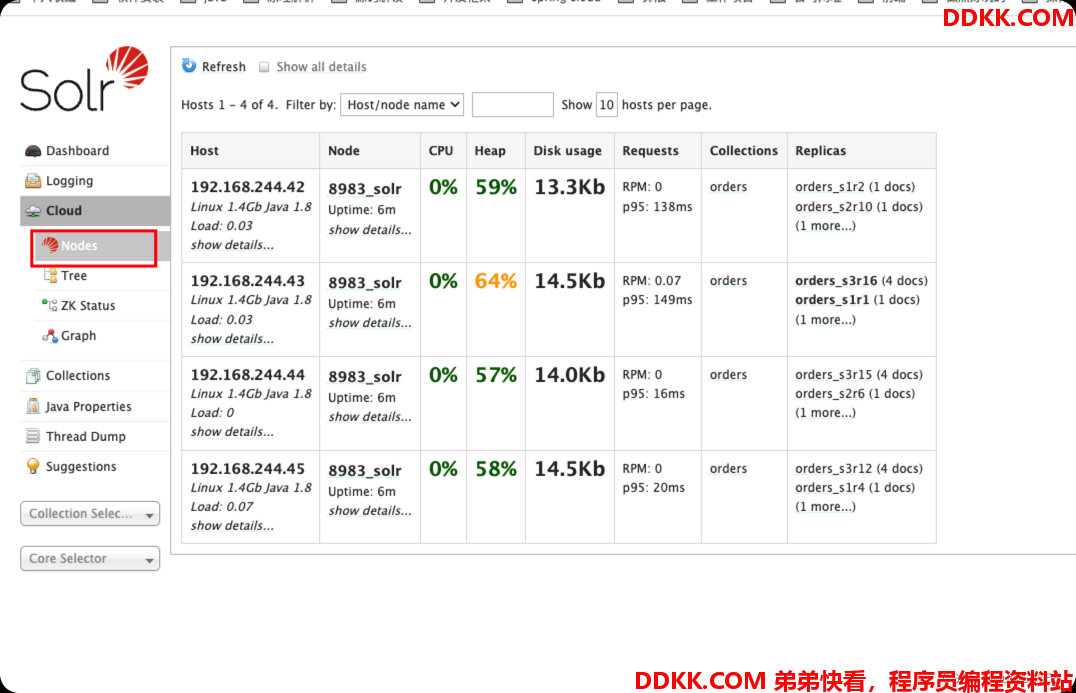
6、 因为用zookeeper管理集群了,我们要将solr的相关配置文件上传到zookeeper上,用zookeeper作为配置中心;
先把我们之前单机solr中创建的orders核心的配置文件上传到其中一个solr节点上
scp -r orders root@192.168.244.42:/data/solr-8.2.0/server/solr
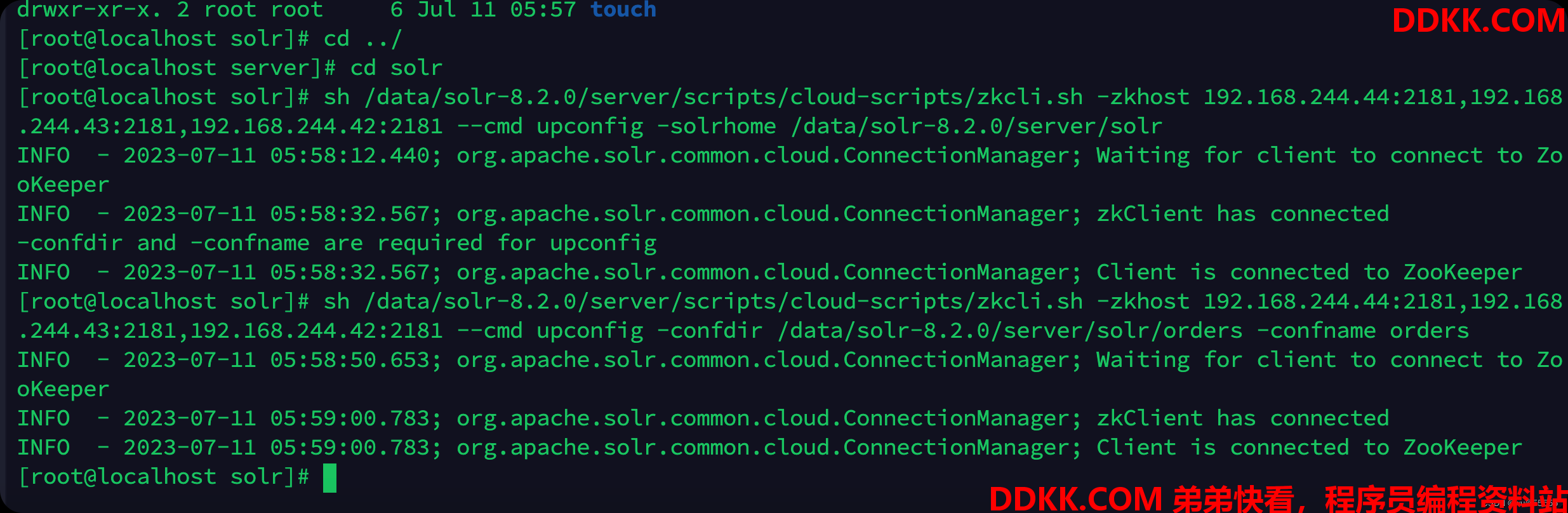
7、 而上传到zk,solr为我们提供了一个脚本文件server/scripts/cloud-scripts/zkcli.sh;
主要将solr.xml和核心(索引)下的配置文件managed-schema,solrconfig.xml
在任意一个solr节点执行:
# 设置solr配置文件路径
sh /data/solr-8.2.0/server/scripts/cloud-scripts/zkcli.sh -zkhost 192.168.244.44:2181,192.168.244.43:2181,192.168.244.42:2181 --cmd upconfig -solrhome /data/solr-8.2.0/server/solr
# 上传核心配置文件目录
sh /data/solr-8.2.0/server/scripts/cloud-scripts/zkcli.sh -zkhost 192.168.244.44:2181,192.168.244.43:2181,192.168.244.42:2181 --cmd upconfig -confdir /data/solr-8.2.0/server/solr/orders -confname orders
后续如果还需要上传其他的核心(索引)配置文件,就只需要执行下面的指令即可
sh /data/solr-8.2.0/server/scripts/cloud-scripts/zkcli.sh -zkhost 192.168.244.44:2181,192.168.244.43:2181,192.168.244.42:2181 --cmd upconfig -confdir /data/solr-8.2.0/server/solr/collection_name -confname collection_name
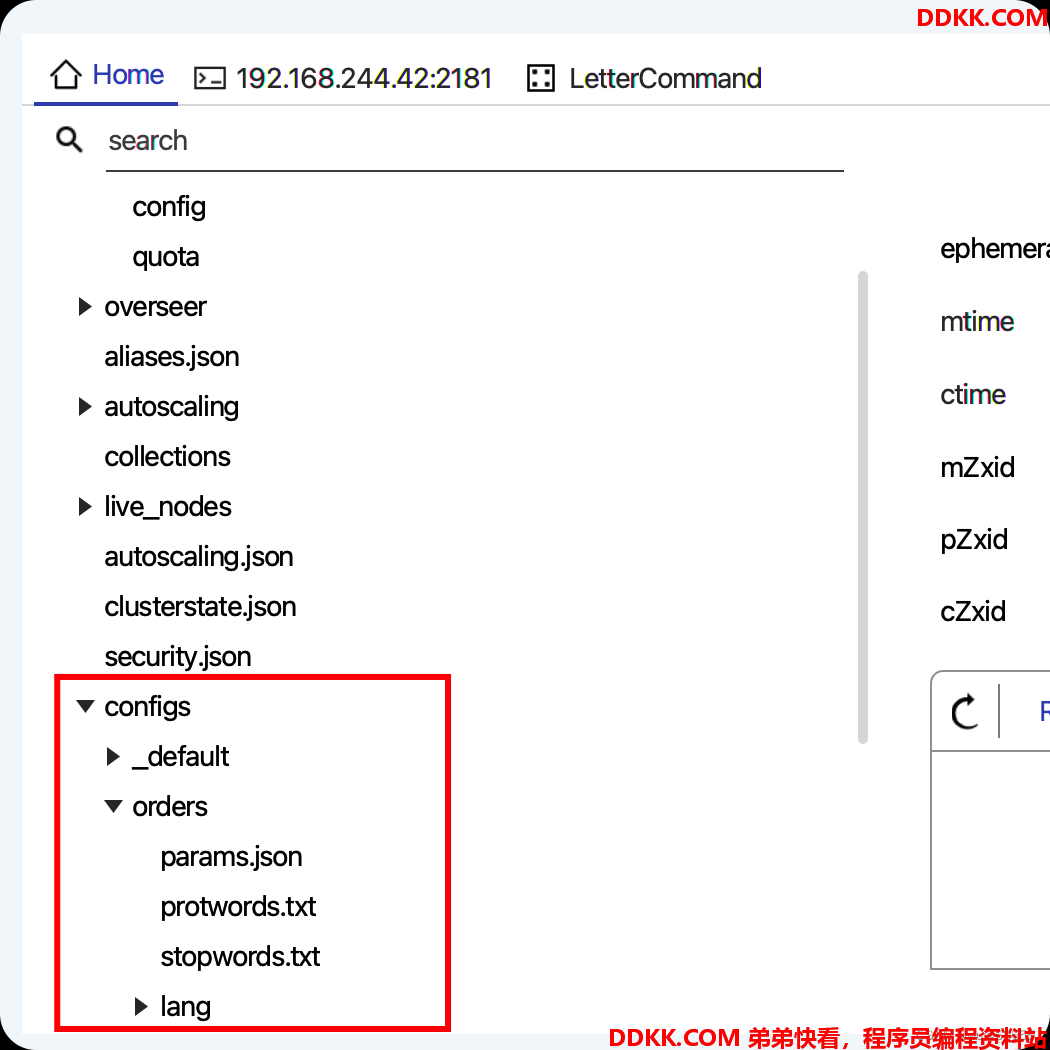
连接zk,也能发现对应的数据了,这里连接使用的是prettyZoo工具,不知道怎么安装的可以查看我之前的博客:
安装zookeeper可视化工具PrettyZoo、ZooKeeperAssistant
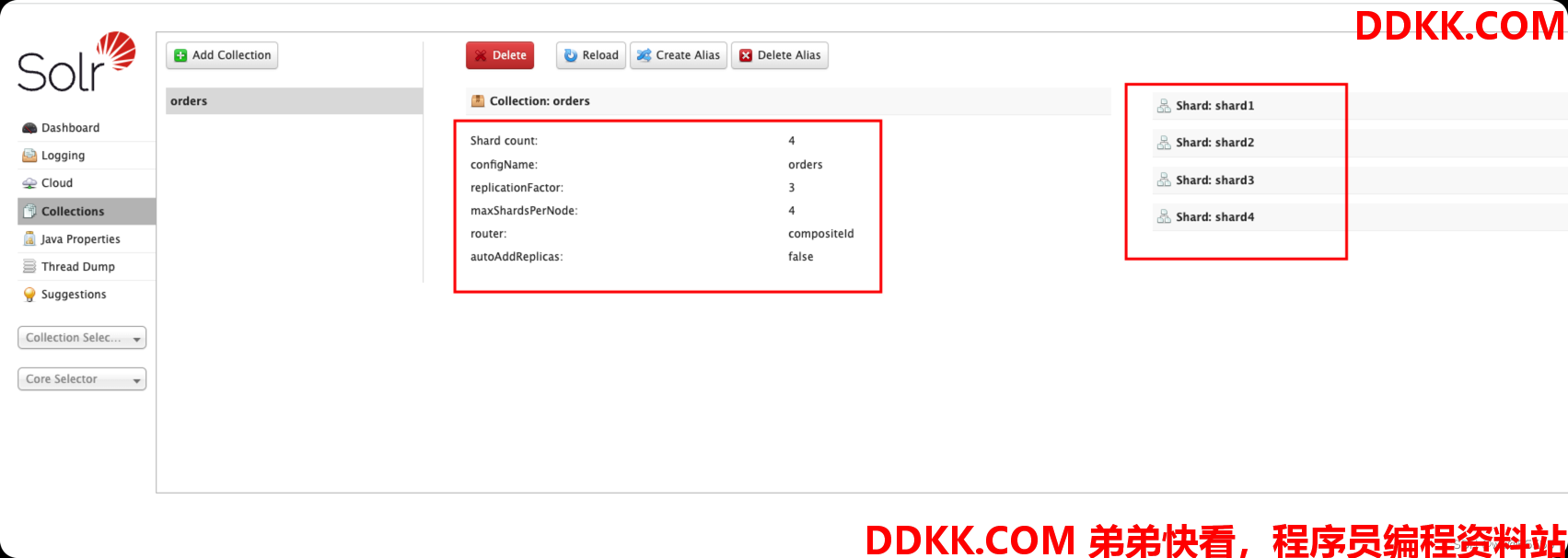
8、 登陆任意一个solr-admin,添加核心,名称与之前上传的orders保持一致,同时因为我们是4个节点,一般设置主分片数与节点数一致,不能超过节点数,同一主副分片不在一个节点上,那么一共就有4个主分片,每个主分片有3个副本分片;
因为solr节点默认的maxShardsPerNode为1,即每个节点只允许创建1个分片(主分片或副分片),明显不满足我们上述的架构,每个节点需要创建1个主分片3个副本分片,所以一个节点需要创建4个分片,则我们需要将maxShardsPerNode调整为4
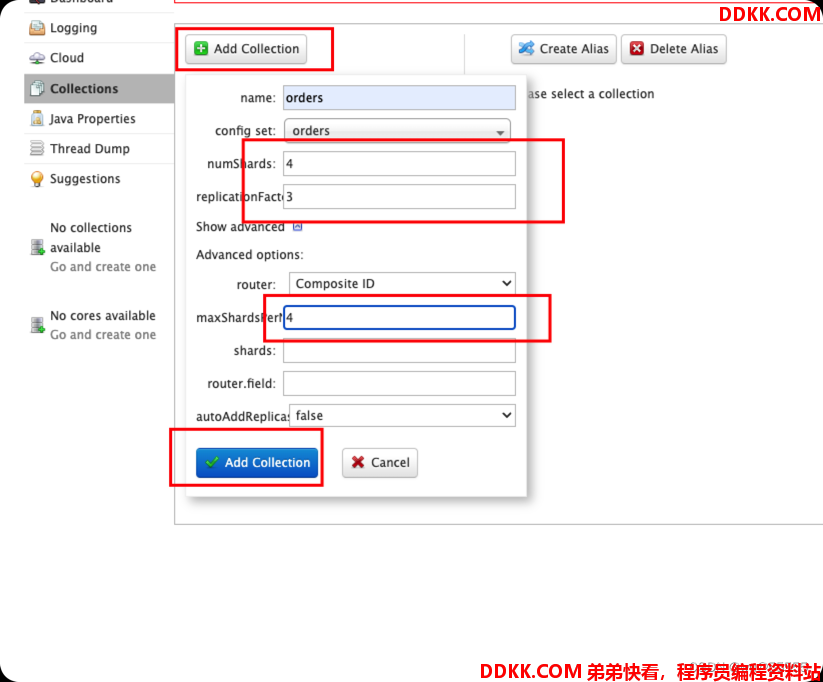
保存后创建的核心会同步到其他节点上
可以在Collections中查看分片情况
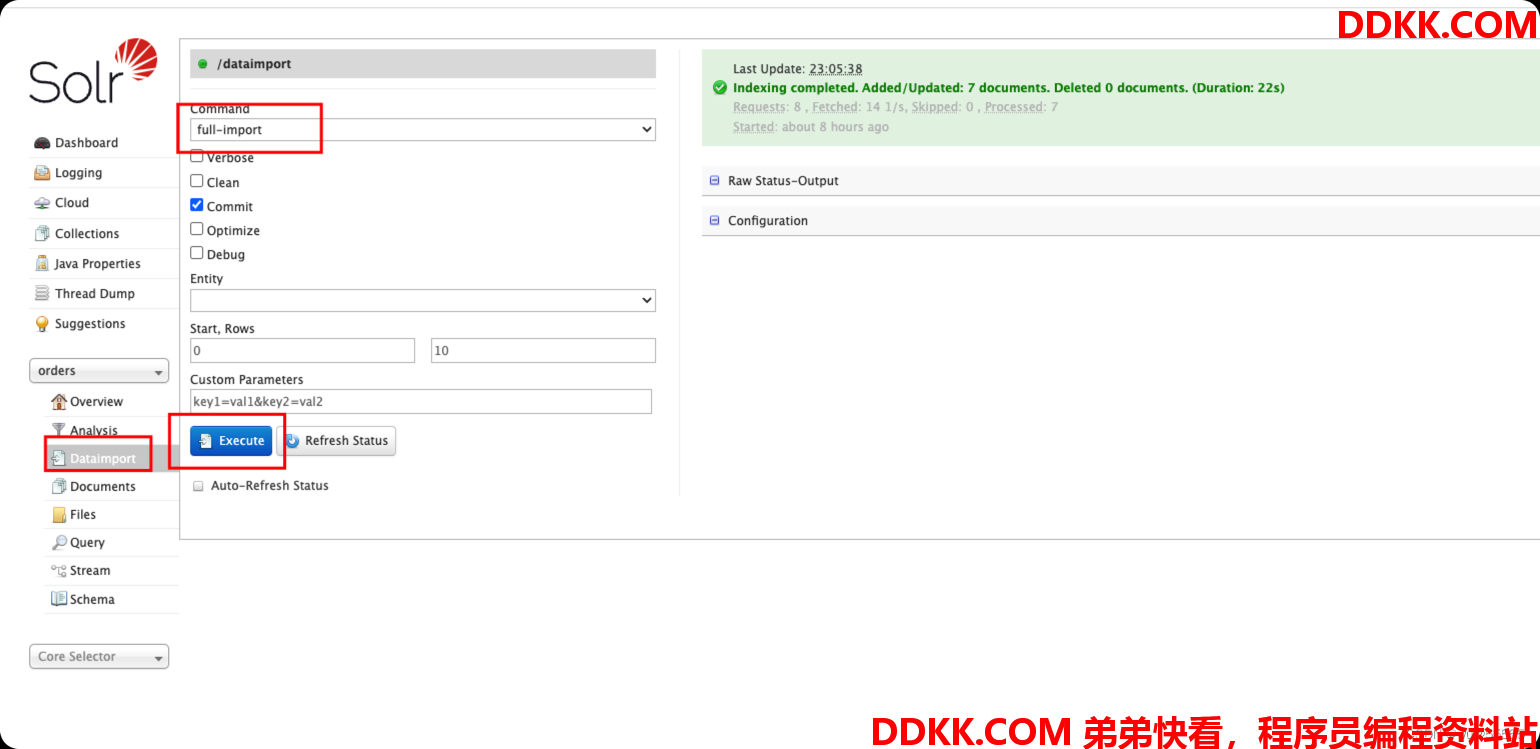
9、 执行全量同步,如果对同步操作不熟悉的,可以查看专栏之前的文章;
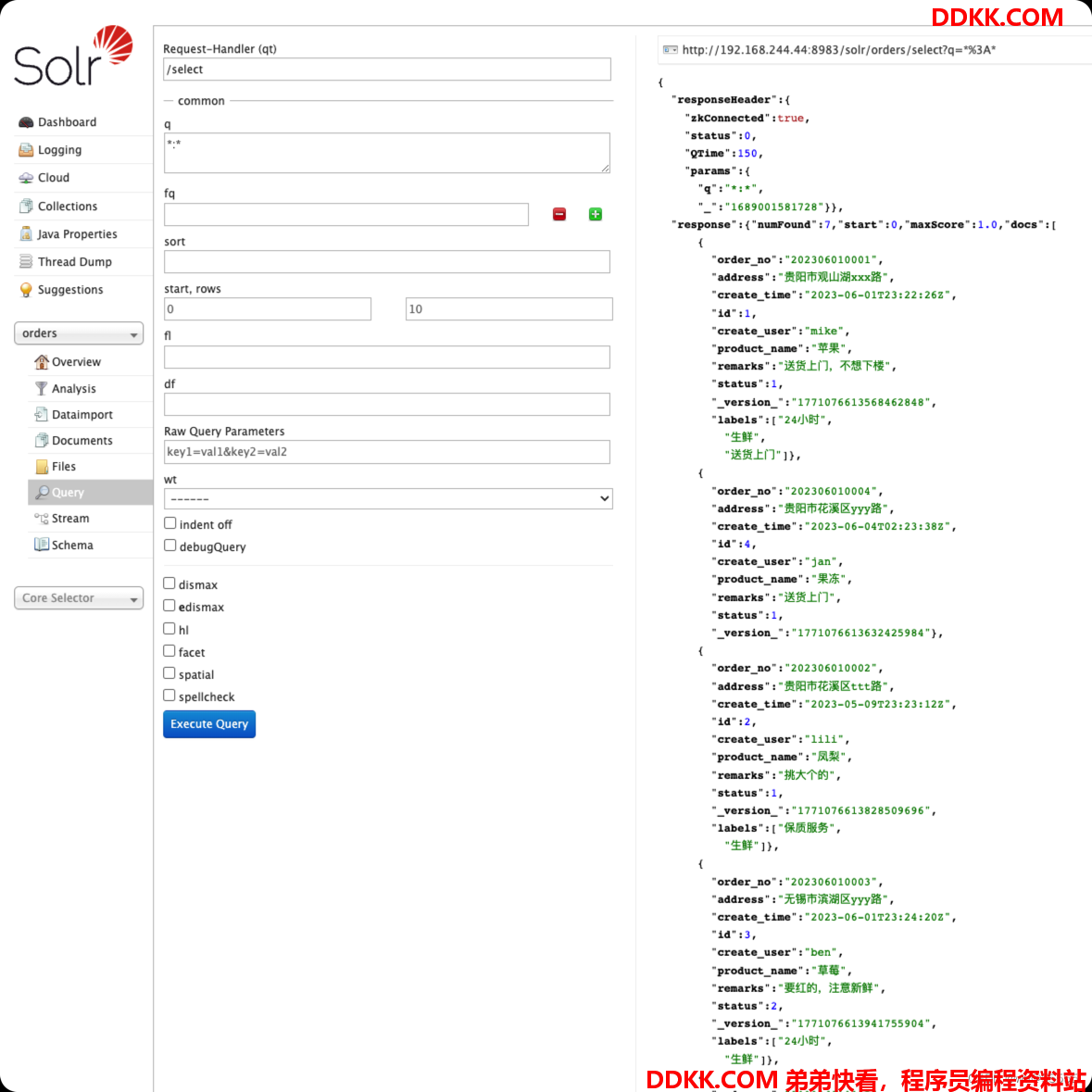
10、 查询数据,发现数据查询成功;
总结
自此,我们针对solr集群的搭建,核心创建,数据同步都讲解完了,同时还需要改变的呢,是我们客户端连接时的代码,要调整为集群模式,也就是通过zk来连接了