0. 引言
solr作为搜索引擎,常用在我们对于搜索速度有较高要求且大数据量的业务场景,我们之前已经配置过英文分词器,但是针对中文分词不够灵活和实用,要实现真正意义上的中文分词,还需要单独安装中文分词器
1. IK中文分词器简介
IK中文分词器是一个国人开源的,基于java开发的轻量级中文分词器,能够实现对中文进行自然语言处理,并且支持自定义分词库,IK分词器本身也支持英文和数字的分词,满足中英文混合的业务场景。
为什么需要中文分词器?
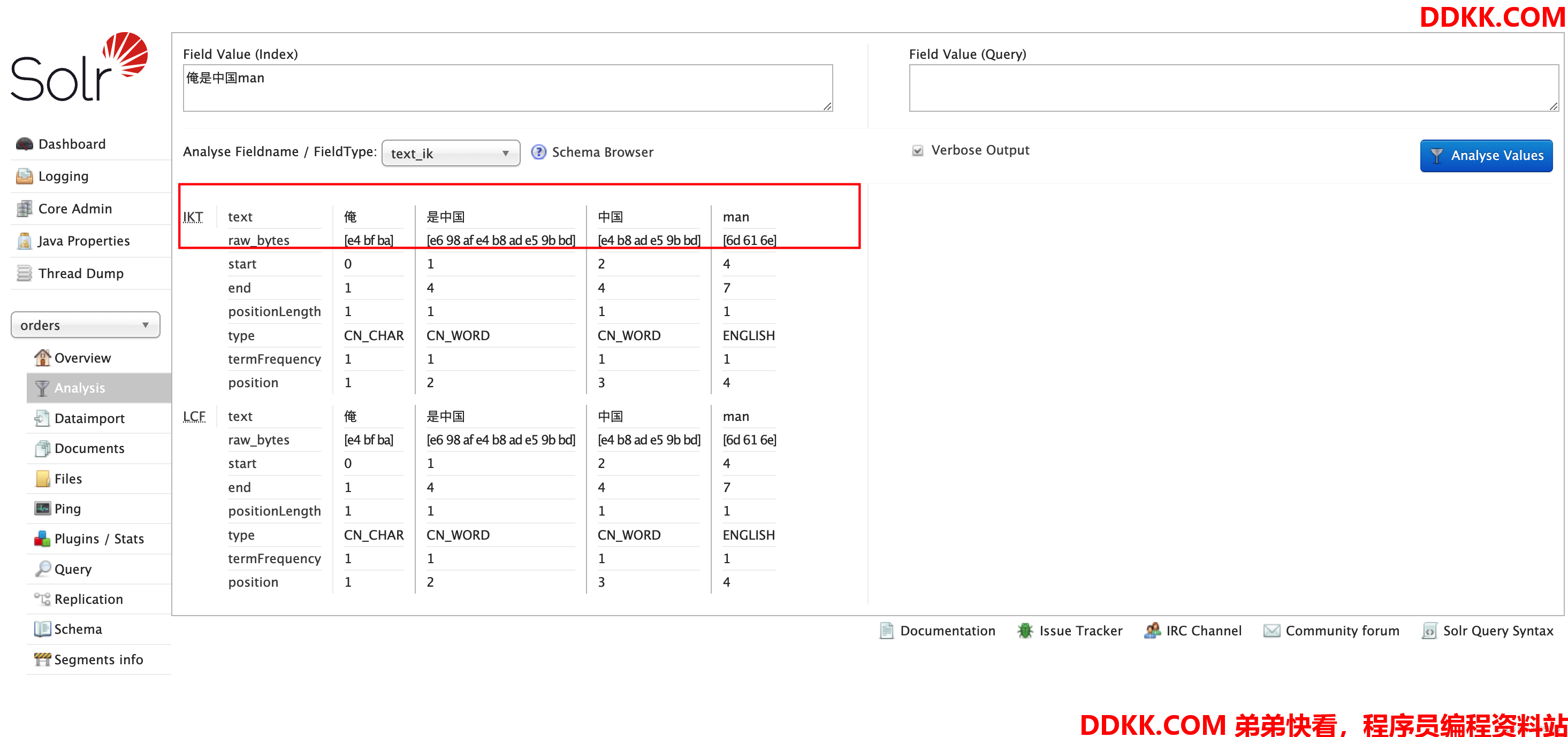
我们可以在solr Analysis中进行分词,采用默认的英文分词器,可以看到中文被切分成了单个汉字,而按照自然语言来讲,我们更希望将其分词为俺,中国,man,这样本身也符合语言习惯,同时不用单个字分词,也节约了存储空间,所以我们需要更加灵活的中文分词器
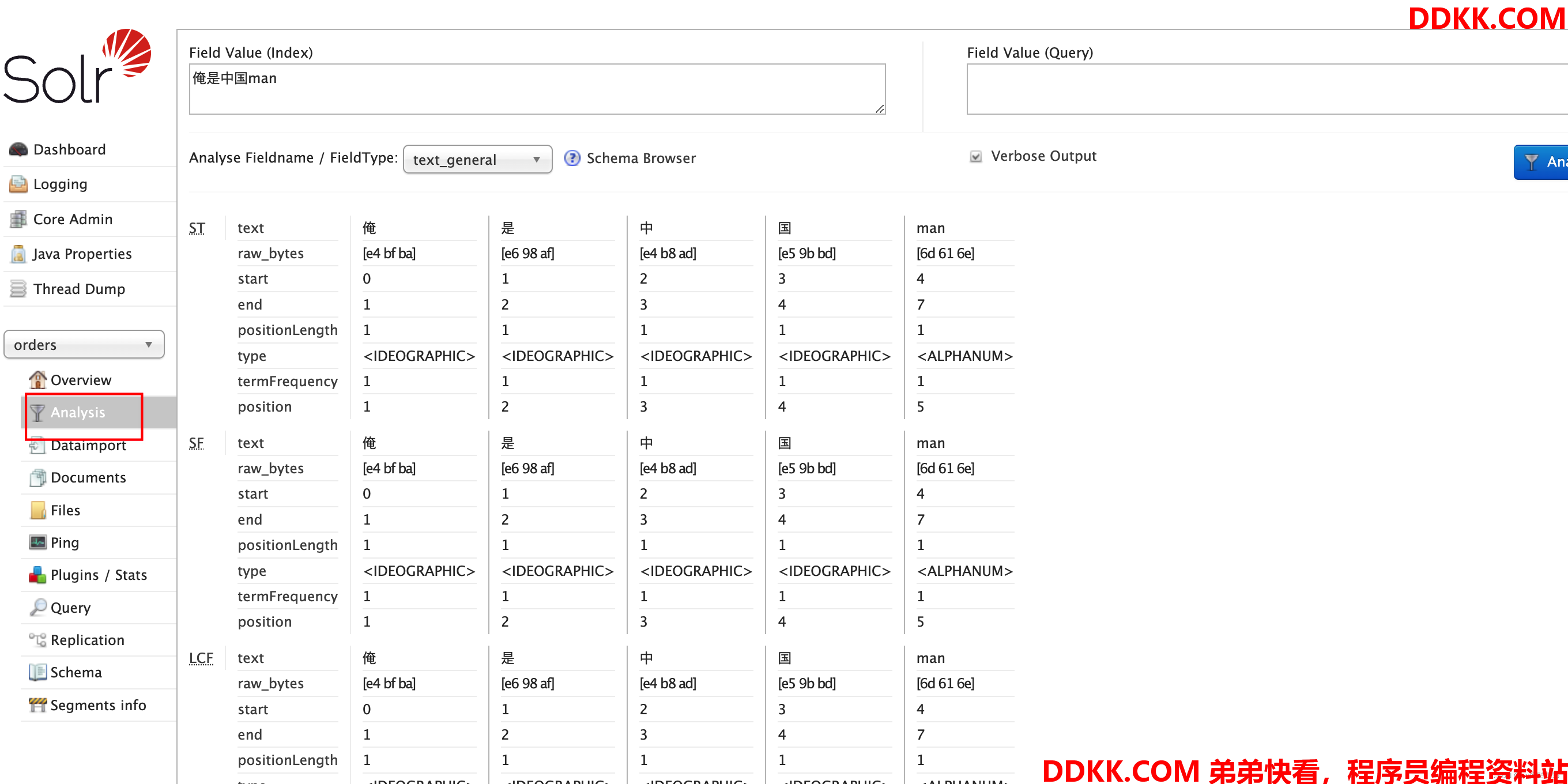
这种
2. IK分词器安装
1、 下载ik分词器,版本与solr版本保持一致;
下载地址:https://central.sonatype.com/artifact/com.github.magese/ik-analyzer/8.2.0
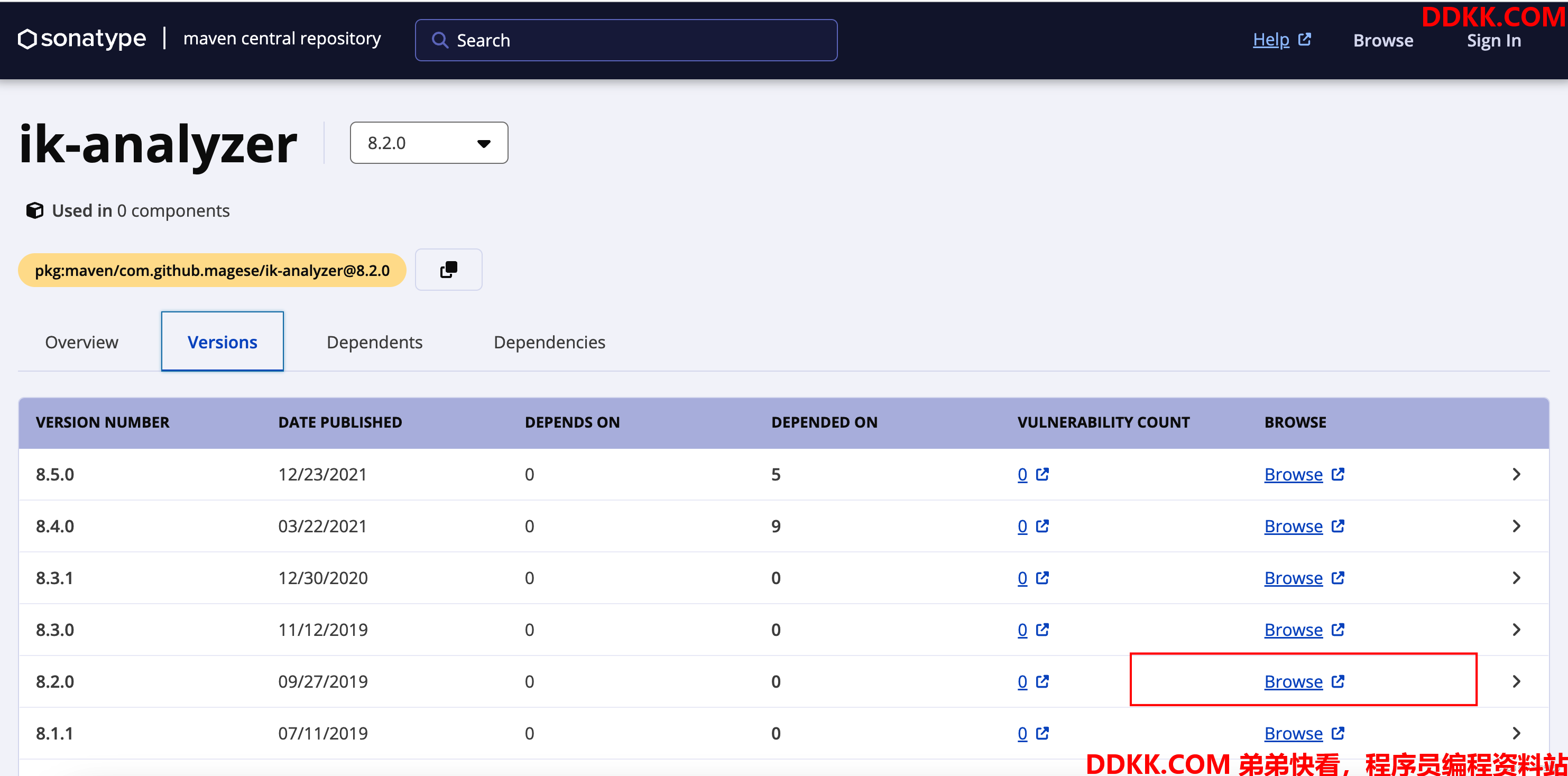
在Versions页面,选择solr对应版本的,点击Browse,选择ik-analyzer-8.2.0.jar下载
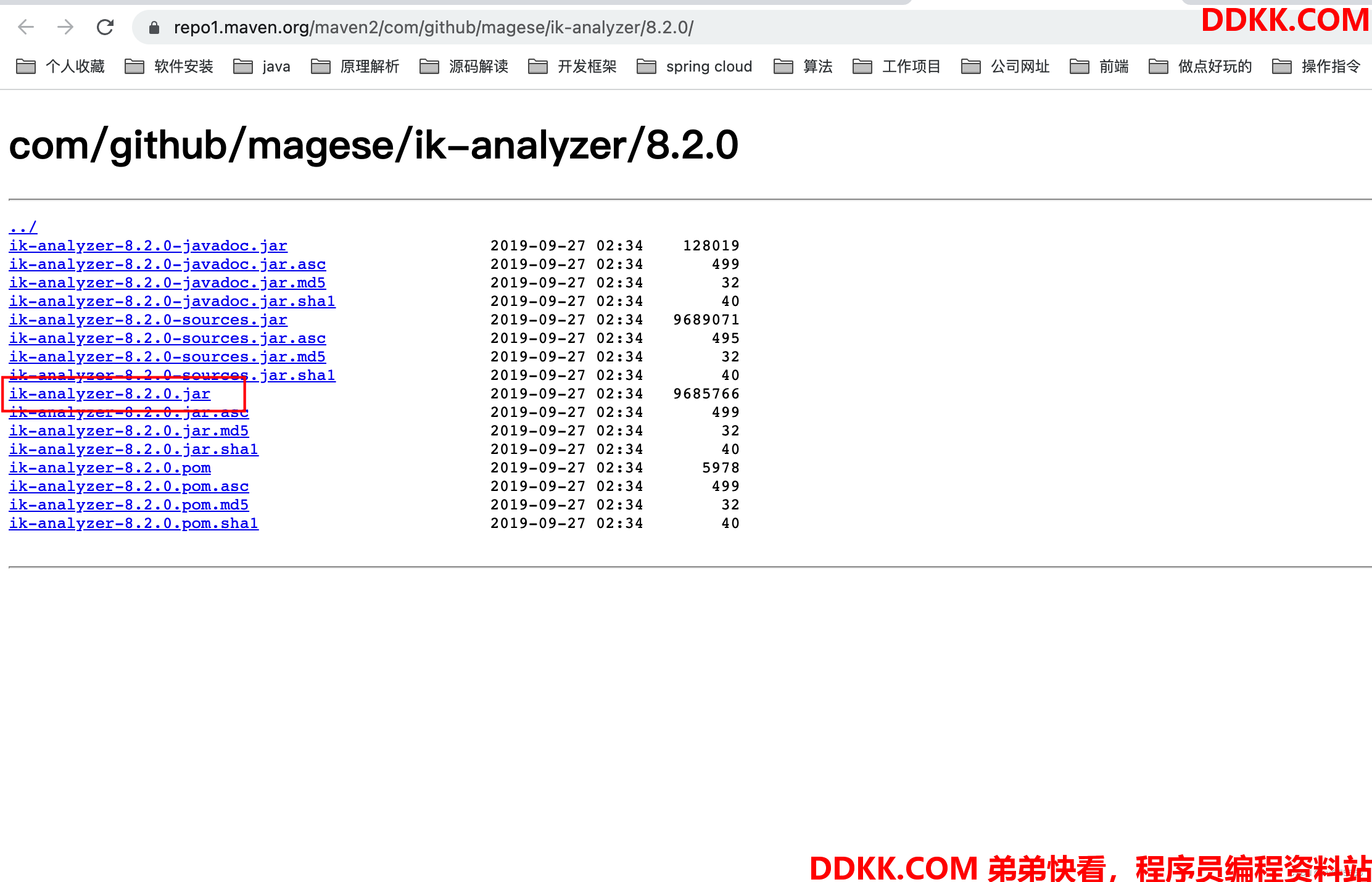
2、 将该jar包上传到solr服务器的server/solr-webapp/webapp/WEB-INF/lib目录下,或者你也可以直接在服务器上使用wget指令下载;
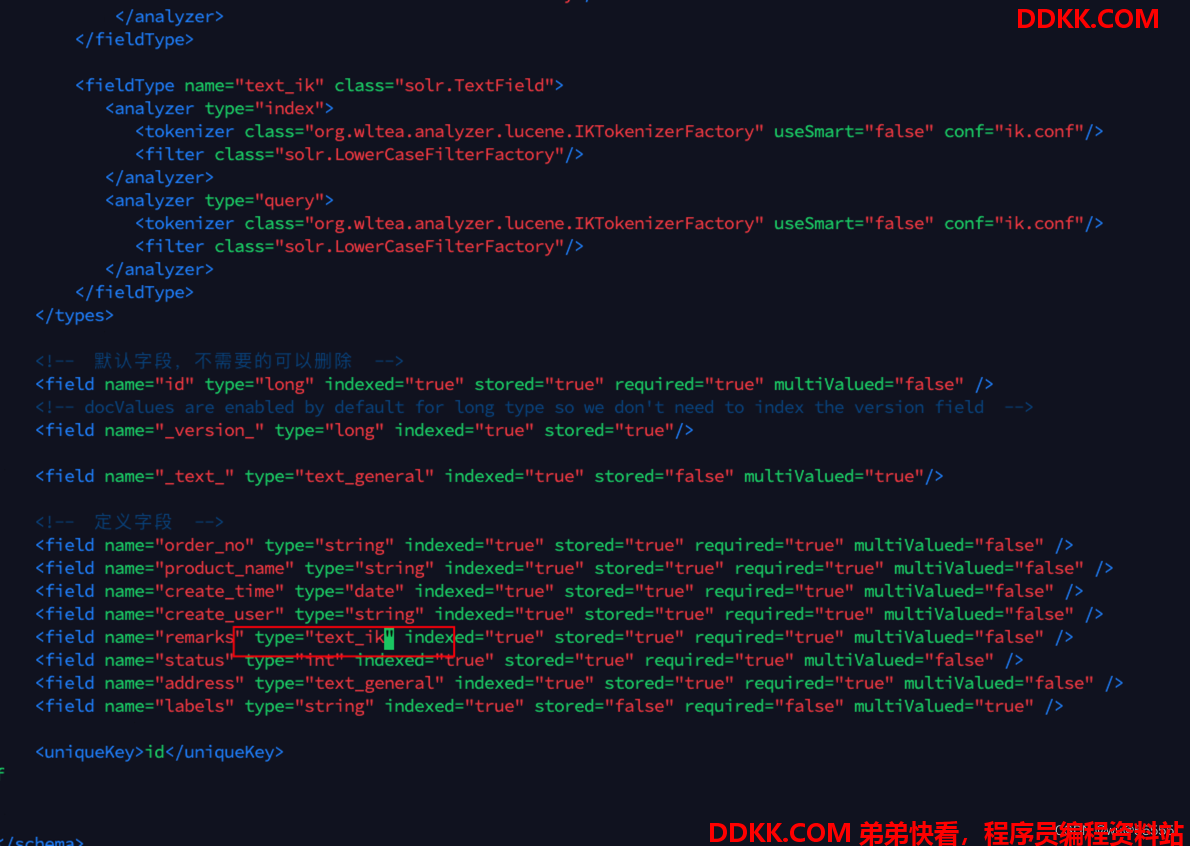
3、 修改对应核心的managed-schema(或schema.xml)配置文件,新建一个字段类型text_ik;
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
4、 同时我们把需要修改分词器的字段的分词器调整一下,比如这里我们将remarks字段修改为中文分词器;
<field name="remarks" type="text_ik" indexed="true" stored="true" required="true" multiValued="false" />
5、 重启solr;
service solr stop
service solr start
这里因为我的solr配置了开机自启,加入了service,所以可以直接用service管理启动停止,如果没有配置使用solr本身的启动停止指令即可
./bin/solr stop -all
./bin/solr start -force
6、 查看分词效果;
我们再次进行分词,这次选择中文分词器,然后查看分词效果,可以看到这次分词就成了词组,而不是之前的单个字,这样后续的匹配效果也更佳
同时因为remarks字段配置了IK分词器,我们也直接直接用该字段测试分词效果
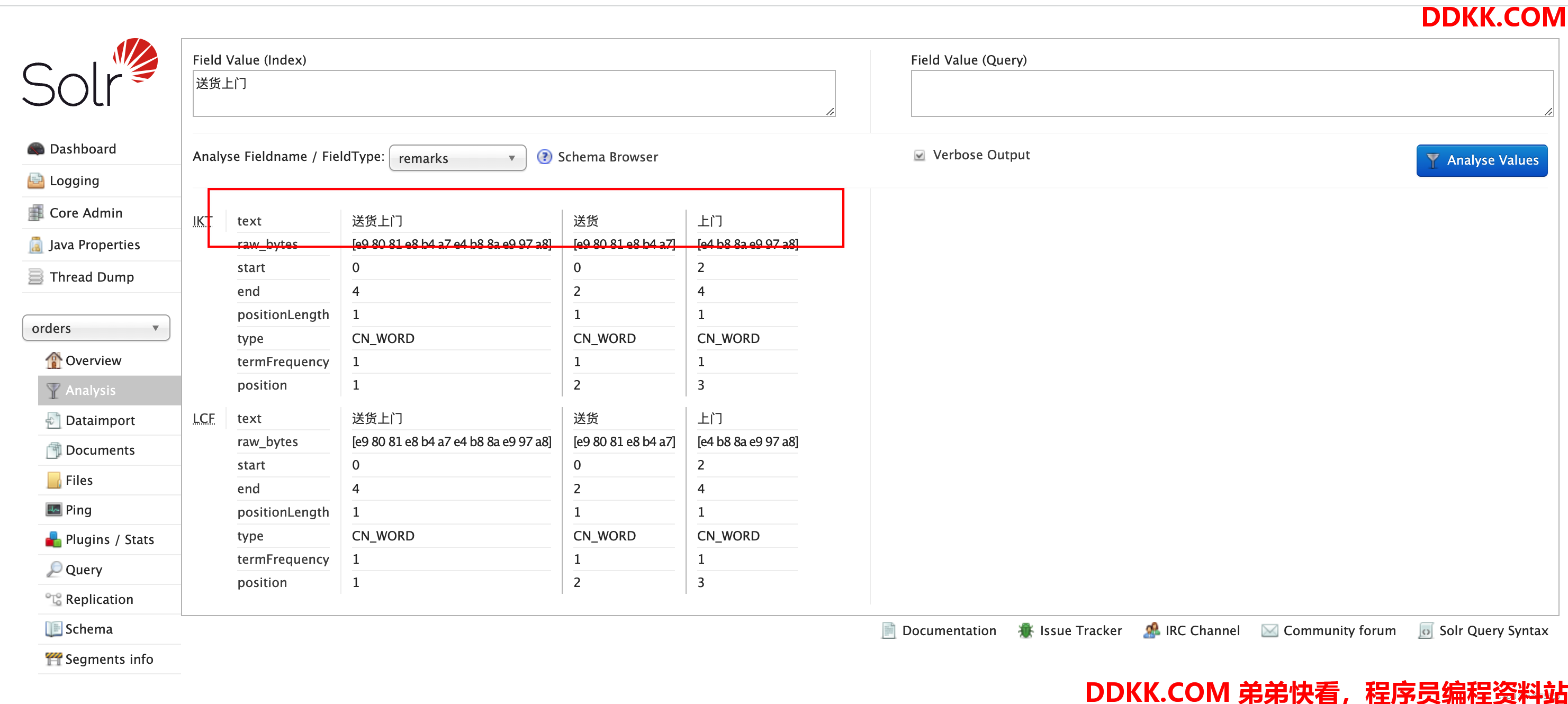
配置中文分词器后,历史数据没有达到对应效果
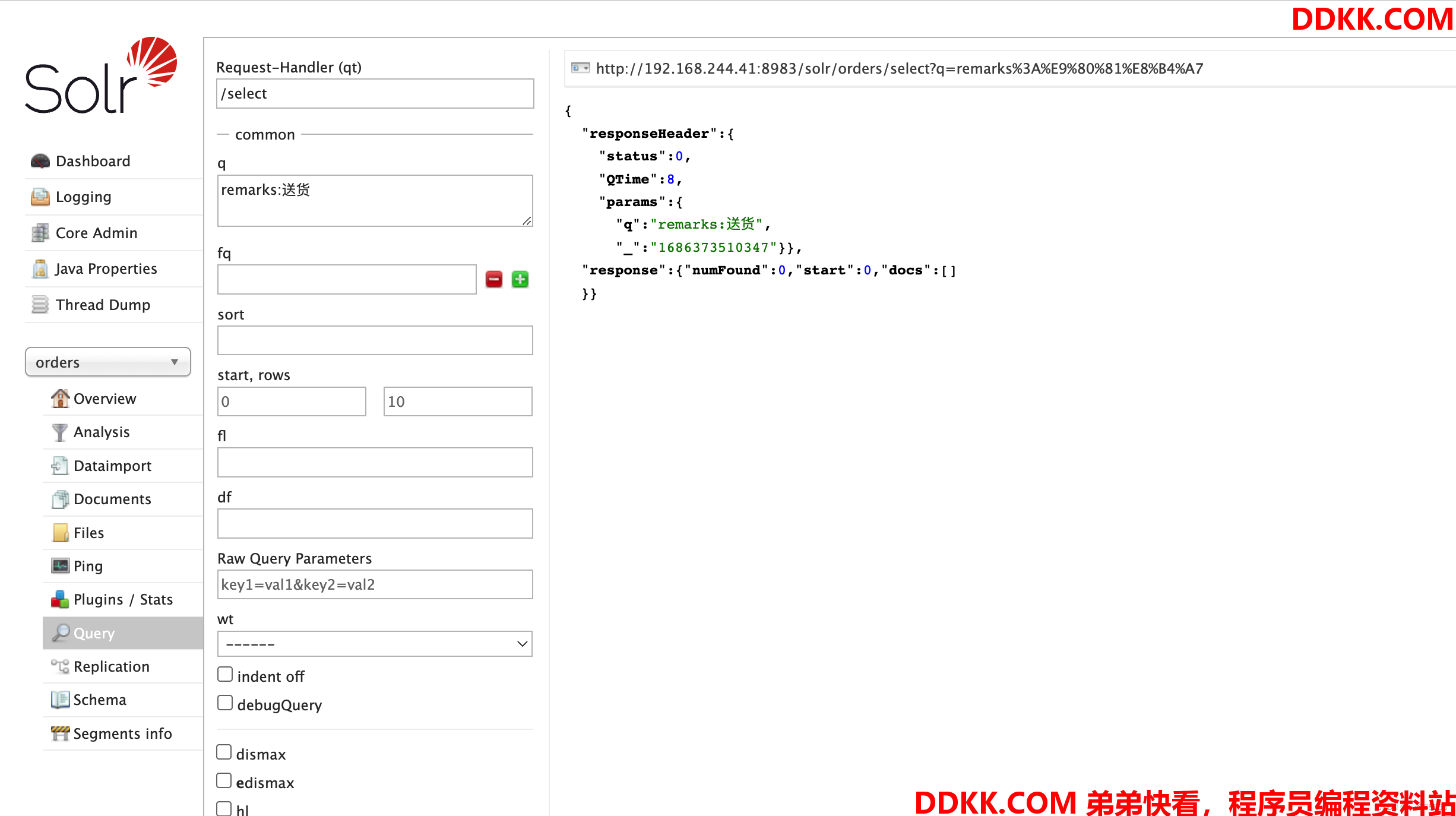
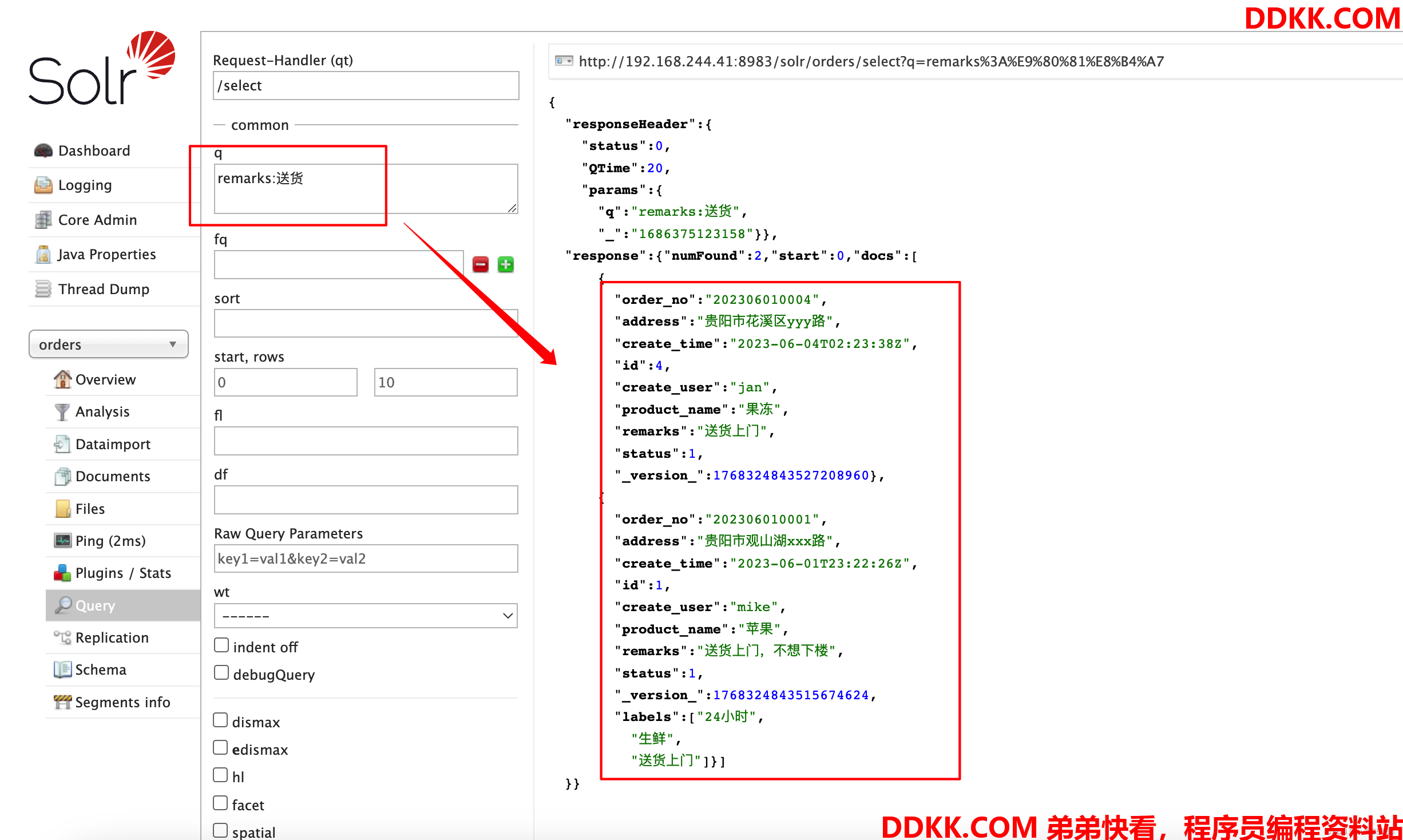
我们修改分词器后,使用remarks查询,发现尽管有数据,还是查询不出来
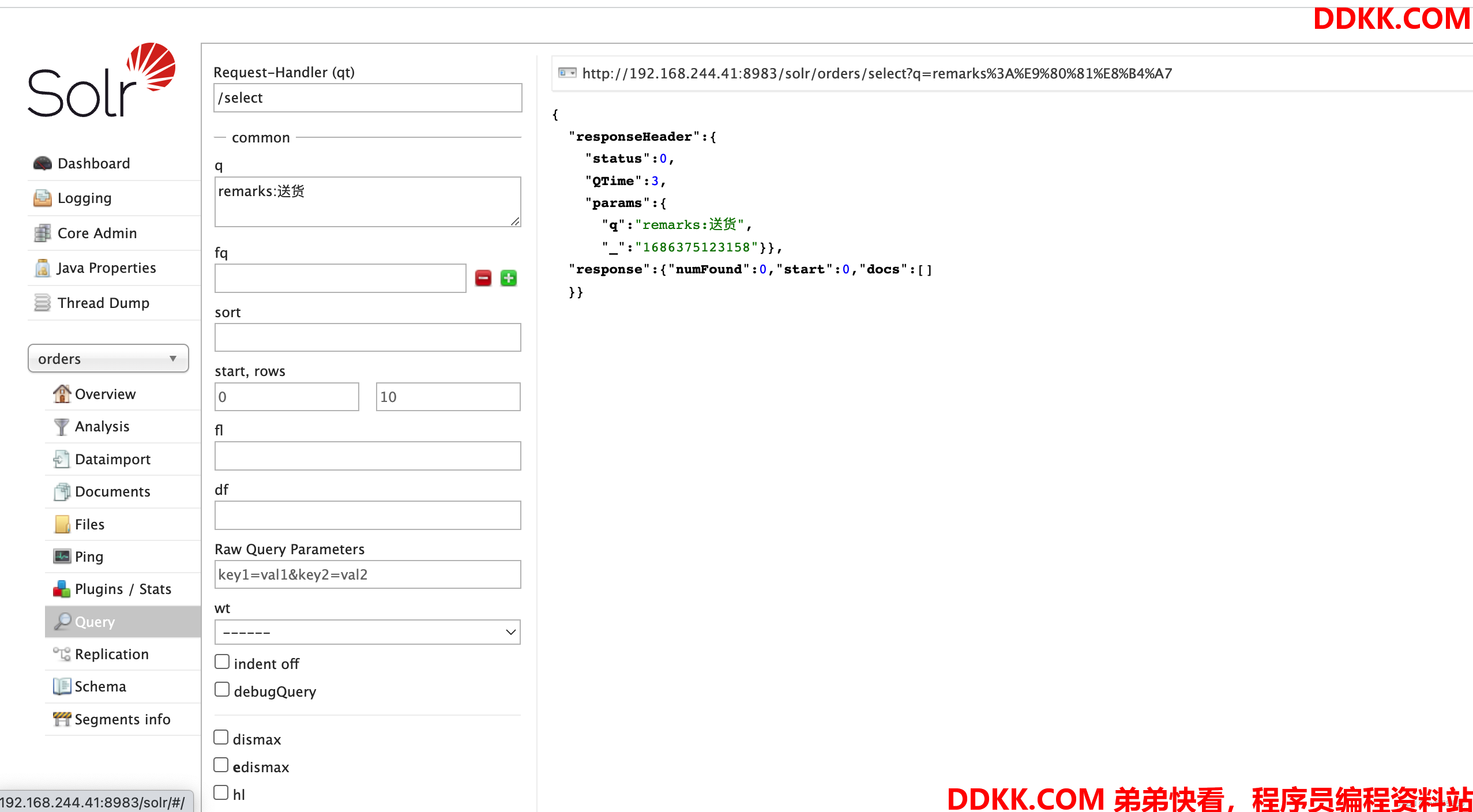
我们上述进行分词测试,“送货”应该是能查询出来的,但是没有匹配上,这是因为怎么回事呢?
这是由于历史的数据已经按照之前的分词配置创建好了分词库,修改分词器并不会让历史数据重新创建分词,想实现这个效果,那就要重新加载索引数据
(1)删除历史索引数据
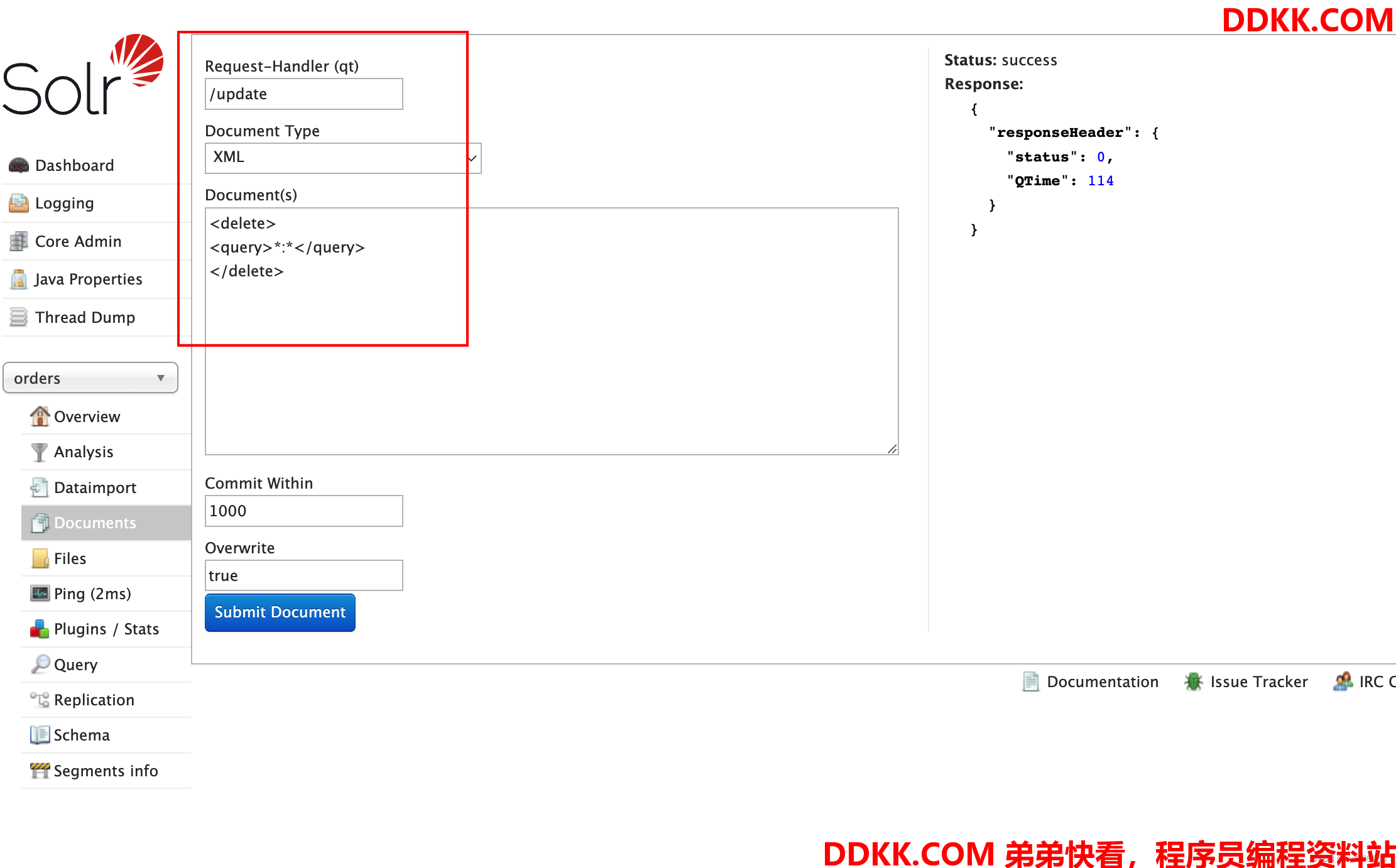
(2)重新加载索引
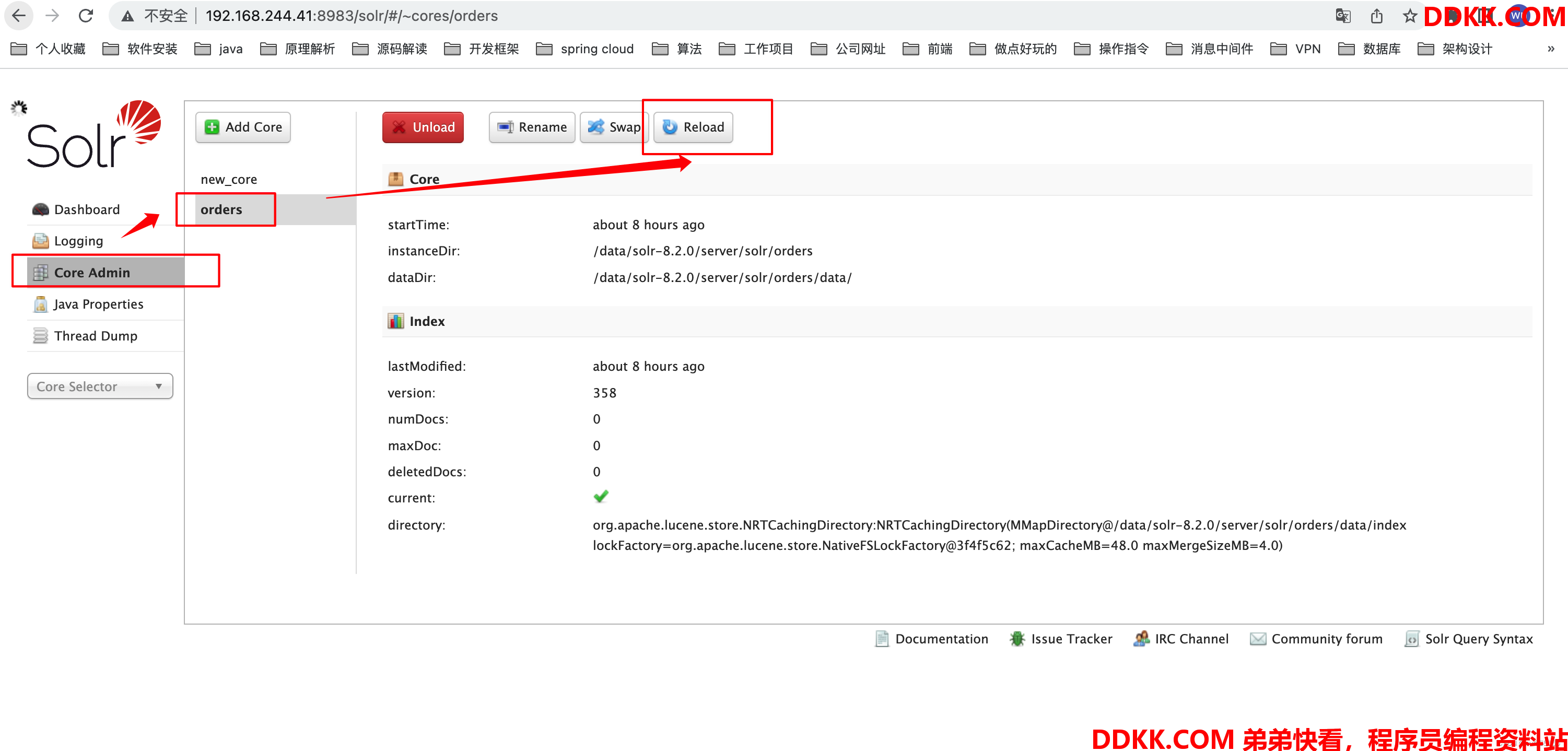
(3)重启solr
(4)重新导入,即使用full-import即可
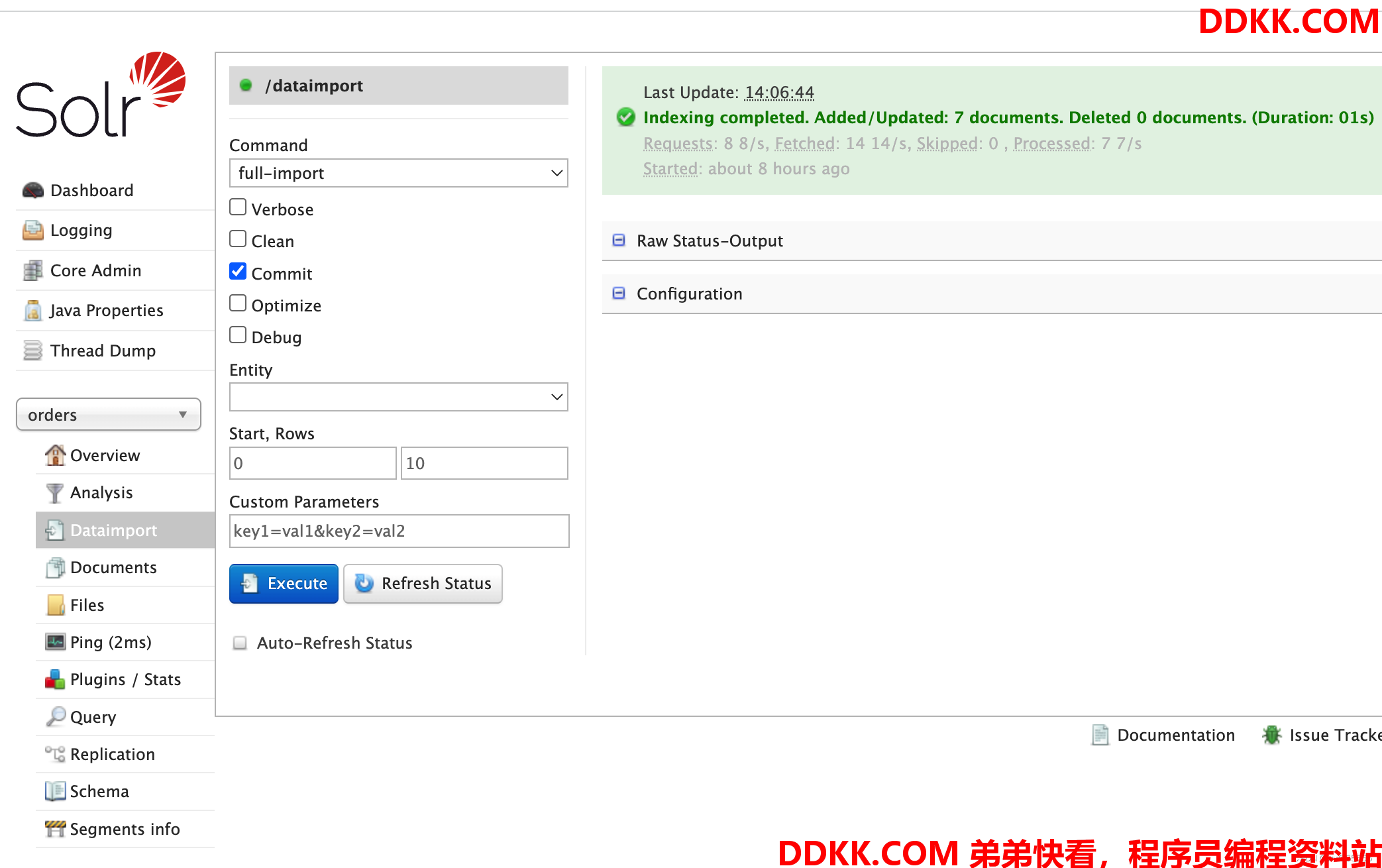
(5)再次查询,发现已经可以正常查询出数据了
3. 总结
至此,我们针对IK中文分词器的简单使用就结束了, 实际上上手使用并不困难,难的是在复杂业务场景下的各类性能需求,但这些也不是我们在“快速上手”专栏所需考虑的了,对于陌生知识,也希望大家保持好奇,减少恐惧,大部分的使用场景实际上是简单的, 但同时也要对熟悉的知识保持敬畏,永远不要自大
还是那句话,动手试试吧!