概念:
简单地说,正则表达式就是处理字符串的方法,它以行为单位来进行字符串的处理操作,正则表达式通过一些特殊符号的辅助,可以让用户轻易地完成【查找、删除、替换】某特定字符串的处理过程。
正则表达式基本上是一种【表示法】,只要程序支持这种表示法,那么该程序就可以用来作为正则表达式的字符串处理之用。
正则表达式的字符串表示方式依照不同的严谨度而区分为:基础正则表达式和扩展正则表达式
正则表达式与通配符是完全不一样的东西,因为【通配符(wildcard)代表的是bash操作接口的一个功能】,但正则表达式则是一种字符串处理的表示方式。
基础正则表达式:
语系对正则表达式的影响
文件其实记录的仅有0与1,我们看到的字符文字与数字都是通过编码表转换来的。不同语系的编码数据并不相同,所以就会造成数据选取结果的差异。使用正则表达式时,要特别注意当时环境的语系是什么。
我们的示例以 LANG=C 这个语系来进行。
另外,为了避免这样编码所造成的英文与数字选取问题,因此有一些特殊符号需要我们了解
| 特殊符号 | 代表意义 |
| [:alnum:] | 代表英文大小写字符及数字,亦即 0-9, A-Z, a-z |
| [:alpha:] | 代表任何英文大小写字符,亦即 A-Z, a-z |
| [:blank:] | 代表空白键与 [Tab] 按键两者 |
| [:cntrl:] | 代表键盘上面的控制按键,亦即包括 CR, LF, Tab, Del.. 等等 |
| [:digit:] | 代表数字而已,亦即 0-9 |
| [:graph:] | 除了空白字符 (空白键与 [Tab] 按键) 外的其他所有按键 |
| [:lower:] | 代表小写字符,亦即 a-z |
| [:print:] | 代表任何可以被打印出来的字符 |
| [:punct:] | 代表标点符号 ( punctuation symbol ),亦即: ” ‘ ? ! ; : `$`… |
| [:upper:] | 代表大写字符,亦即 A-Z |
| [:space:] | 任何会产生空白的字符,包括空白键 , [Tab], CR 等等 |
| [:xdigit:] | 代表 16 进位的数字类型,因此包括: 0-9, A-F, a-f 的数字与字符 |
grep的一些高级选项:
grep [-A] [-B] [--color=auto] '查找字符' filename
-A:后面可接数字,为after的意思,除了列出该行外,后续的n行也列出来
-B:后面可接数字,为befer的意思,除了列出该行外,前面的n行也列出来
--color=auto:可将正确的那个选取数据列出颜色
grep在数据中查找一个字符串时,是以【整行】为单位来进行数据的选取
基础正则表达式字符集合(characters)
| RE 字符 | 意义与范例 |
| ^word | 意义:待查找的字符串(word)在行首! 范例:搜寻行首为 开始的那一行,并列出行号
` |
| word$ | 意义:待查找的字符串(word)在行尾! 范例:将行尾为 ! 的那一行列印出来,并列出行号
|
| . | 意义:代表『一定有一个任意字节』的字符! 范例:搜寻的字串可以是 (eve) (eae) (eee) (e e), 但不能仅有 (ee) !亦即 e 与 e 中间『一定』仅有一个字节,而空白字节也是字节!
|
| \ | 意义:转义符,将特殊符号的特殊意义去除! 范例:搜寻含有单引号 ‘ 的那一行!
|
| * | 意义:重复零个到无穷多个的前一个 RE 字符 范例:找出含有 (es) (ess) (esss) 等等的字串,注意,因为 * 可以是 0 个,所以 es 也是符合带搜寻字串。另外,因为 * 为重复『前一个 RE 字符』的符号, 因此,在 * 之前必须要紧接著一个 RE 字符喔!例如任意字节则为 『.*』 !
|
| [list] | 意义:字符集合的 RE 字符,里面列出想要选取的字符! 范例:搜寻含有 (gl) 或 (gd) 的那一行,需要特别留意的是,在 [] 当中『谨代表一个待查找的字符』, 例如『 a[afl]y 』代表搜寻的字串可以是 aay, afy, aly 即 [afl] 代表 a 或 f 或 l 的意思!
|
| [n1-n2] | 意义:字符集合的 RE 字符,里面列出想要选取的字符范围! 范例:搜寻含有任意数字的那一行!需特别留意,在字节集合 [] 中的减号 – 是有特殊意义的,他代表两个字节之间的所有连续字符!但这个连续与否与 ASCII 编码有关,因此,你的编码需要配置正确(在 bash 当中,需要确定 LANG 与 LANGUAGE 的变量是否正确!) 例如所有大写字节则为 [A-Z]
|
| [^list] | 意义:字符集合的 RE 字符,里面列出不要的字符串或范围! 范例:查找的字符串可以是 (oog) (ood) 但不能是 (oot) ,那个 ^ 在 [] 内时,代表的意义是『反向选择』的意思。 例如,我不要大写字节,则为 [^A-Z]。但是,需要特别注意的是,如果以 grep -n [^A-Z] regular_express.txt 来搜寻,却发现该文件内的所有行都被列出,为什么?因为这个 [^A-Z] 是『非大写字符』的意思, 因为每一行均有非大写字节,例如第一行的 “Open Source” 就有 p,e,n,o…. 等等的小写字
|
| \{n,m\} | 意义:连续 n 到 m 个的『前一个 RE 字符』 意义:若为 \{n\} 则是连续 n 个的前一个 RE 字符, 意义:若是 \{n,\} 则是连续 n 个以上的前一个 RE 字符! 范例:在 g 与 g 之间有 2 个到 3 个的 o 存在的字串,亦即 (goog)(gooog)
注:因为 { 与 } 的符号在 shell 是有特殊意义的,因此, 我们必须要使用转义字符 \ 来让他失去特殊意义才行 |
再次强调:正则表达式的特殊字符与一般在命令行输入命令的通配符不同。例如,在万用字节当中的 * 代表的是『 0 ~ 无限多个字节』的意思,但是在正规表示法当中, * 则是『重复 0 到无穷多个的前一个 RE 字符』的意思
举例来说,不支持正规表示法的 ls 这个工具中,若我们使用 『ls -l * 』 代表的是任意档名的文件,而 『ls -l a* 』代表的是以 a 为开头的任何档名的文件, 但在正规表示法中,我们要找到含有以 a 为开头的文件,则必须要这样:(需搭配支持正规表示法的工具)
ls| grep -n ‘^a.*’
.* 就代表零个或多个任意字节
另外,那个 ^ 符号,在字节集合符号(括号[])之内与之外是不同的! 在 [] 内代表『反向选择』,在 [] 之外则代表定位在行首的意义!
sed工具
sed本身是一个管道命令,可以分析标准输入。而且sed还可以将数据进行替换、删除、新增、选取特定行等功能。
sed [-nefr] 操作
选项与参数:
-n:使用安静(silent)模式,在一般 sed 的用法中,所有来自 stdin 的数据一般都会被列出到屏
幕上,但若加了-n,则只有经过sed特殊处理的那一行(或操作)才会列出
-e:直接在命令行模式进行sed的操作编辑
-f:直接将sed的操作写在一个文件内,-f filename则可以执行 filename 内的 sed 操作
-r:sed的操作使用的是扩展型正则表达式的语法(默认是基础型)
-i:直接修改读取的文件内容,而不是由屏幕输出
操作说明: [n1[,n2]]function
n1,n2:不见得会存在,一般代表【选择进行操作的行数】,举例来说,如果我的操作
是需要在10到20行之间进行的,则【10,20[操作行为]】
function有下面这些东西:
a:新增,a的后面可以接字符,而这些字符会在新的一行出现(目前的下一行)
c:替换,c的后面可以接字符,这些字符可以替换n1、n2之间的行
d:删除,因为是删除,所以d后面通常不接任何东西
i:插入,i的后面可以接字符,而这些字符会在新的一行出现(目前的上一行)
p:打印,亦即将某个选择的数据打印出来,通常p会与参数sed -n一起运行
s:替换,可以直接进行替换的工作,常搭配正则表达式
下面我们来练习:
新增与删除:
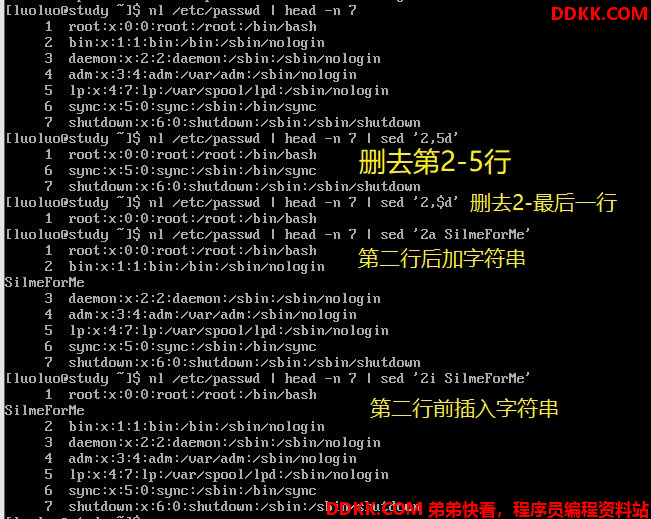
如果想要插入多行字符串,在输命令时就用 【\+Enter】到第二行继续输入即可
替换与显示功能:
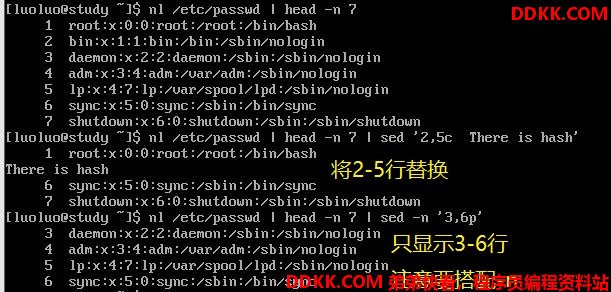
部分数据的查找并替换功能
除了整行的处理模式之外,sed还可以以行为单位进行部分数据的查找并替换的功能。
sed的查找与替换与vi类似:
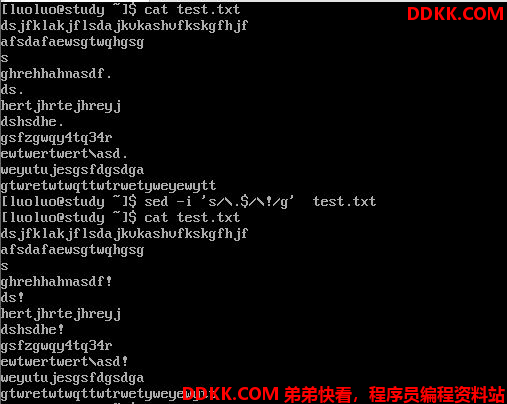
sed 's/要被替换的字符/新的字符/g'
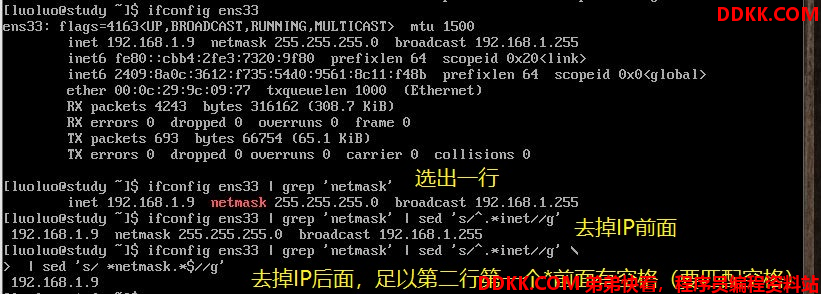
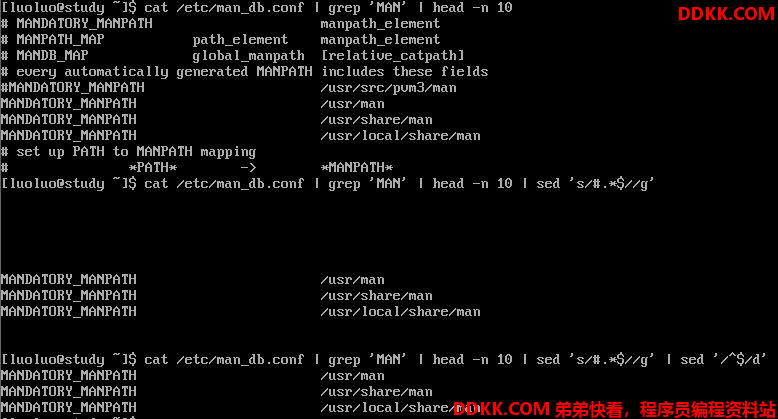
直接修改文件内容(危险操作)
sed还可以直接修改文件内容,而不必用管道命令或数据流重定向。
不过,这个操作会直接修改到原始的文件
扩展正则表达式
| RE 字符 | 意义与范例 |
| + | 意义:重复『一个或一个以上』的前一个 RE 字符 范例:查找 (god) (good) (goood)… 等等的字串。 那个 o+ 代表『一个以上的 o 』
|
| ? | 意义:『零个或一个』的前一个 RE 字符 范例:搜寻 (gd) (god) 这两个字串。 那个 o? 代表『空的或 1 个 o 』
|
| | | 意义:用或( or )的方式找出数个字串 范例:搜寻 gd 或 good 这两个字串,注意,是『或』!
|
| () | 意义:找出『群组』字串 范例:搜寻 (glad) 或 (good) 这两个字串,因为 g 与 d 是重复的,所以, 我就可以将 la 与 oo 列於 ( ) 当中,并以 | 来分隔开来,就可以啦!
|
| ()+ | 意义:多个重复群组的判别 范例:将『AxyzxyzxyzxyzC』用 echo 打印,然后再使用如下的方法搜寻一下!
上面的例子意思是说,我要找开头是 A 结尾是 C ,中间有一个以上的 “xyz” 字串的意思~ |
注意:! 在正则表达式中并不是特殊字符。
文件的格式化与相关处理
格式化打印:printf
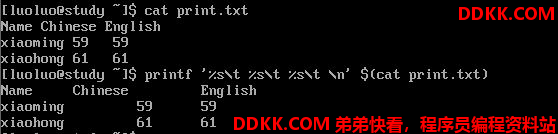
printf '打印格式' 实际内容
格式方面的几个特殊样式:
\a:警告声音输出
\b:退格键
\f:清除屏幕(form feed)
\n:输出新的一行
\r:回车按键
\t:水平的tab
\v:垂直的tab
\xNN: NN为两位数的数字,可以转换数字成为字符
关于C语言程序内,常见的变量格式
%ns:那个n是数字,s代表string,即多少个字符
%ni:那个n是数字,i代表integer,即多少整数位数
%N.nf:那个n与N都是数字,f代表floating(浮点),如果有小数位数
假设我共要十个位数,但小数点有两位,即为%10.2f
关于printf,还可以参考这两个表格
常见格式替代符
%s |
字符串 |
%f |
浮点格式 |
%c |
ASCII字符,即显示对应参数的第一个字符 |
%d,%i |
十进制整数 |
%o |
八进制值 |
%u |
不带正负号的十进制值 |
%x |
十六进制值(a-f) |
%X |
十六进制值(A-F) |
%% |
表示%本身 |
常见转义字符
\a |
警告字符,通常为ASCII的BEL字符 |
\b |
后退 |
\f |
换页 |
\n |
换行 |
\r |
回车 |
\t |
水平制表符 |
\v |
垂直制表符 |
\\ |
表示\本身 |
另外,如果是用%N.nf,要注意,浮点数小数点也占一位。
除了格式化之外,它还可以根据ASCII的数字与字符对应来显示数据,我们来看个例子:
十六进制的45可以得到什么ASCII字符

awk:好用的数据处理工具
awk也是一个非常棒的数据处理工具,相较于sed常常作用于一整个行的处理,awk则比较倾向于一行当中分成数个字段来处理。awk通常的运行的模式是这样的:
awk '条件类型1{操作1} 条件类型2{操作2} ...' filename
awk后面接两个单引号并加上大括号{}来设置想要对数据进行的处理操作,awk可以处理后续接的文件,也可以读取来自前个命令的标准输出。但如前面所说awk主要是处理每一行的字段内的数据,而默认的字段的分隔符为“空格键”或“Tab键”。
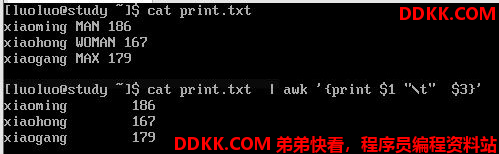
上面是awk的常用操作(去除第一段和第三端,中间用制表符隔开),不论那一行都要这样处理,因此,就不需要“条件限制”
每一行的字段都有变量名称,如$1、$2等,而$0则代表一整行数据
其实,awk内部处理主要依赖了3个变量
- NF:每一行(
$0)拥有的字段数 - NR:目前awk所处理的是第几行数据
- FS:目前的分隔字符,默认是空格键
我们可以如下输出变量

awk中的变量要大写,而且不需要$符
那么我们接下来看看“条件类型”
/etc/passwd 文件以:的形式存放了一些用户数据,我们来让UID小于10的输出
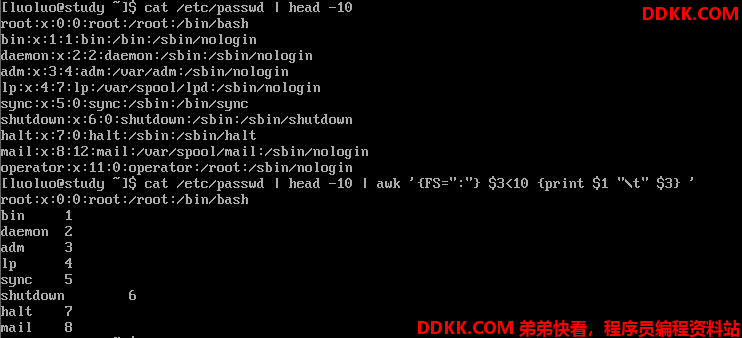
为什么第一行没有成功呢?因为我们读入第一行的时候,那些变量$1、$2……还是默认以空格为分隔,虽然我们定义了FS=”:”,但是只能在第二行开始生效,那怎么办?我们可以预先设置awk的变量,利用 BEGIN 这个关键词:
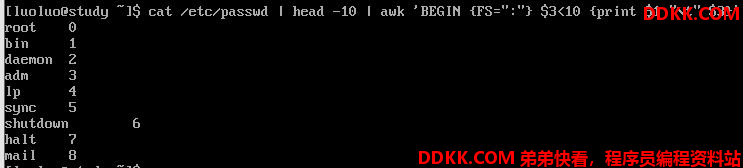
例外,我们还可以用awk来进行计算功能

- awk的命令间隔:所有awk的操作,亦即在{}中操作,如果有需要多个命令辅助时,可利用分号间隔,或者接以Enter键来隔开每个命令
- 逻辑运算当中,等于是==
- 格式化输出时,注意加\n换行
- 与bash shell不同,在awk中,变量可以直接使用,不需要
$
文件比对工具
diff
diff就是用在比对两个文件之间的差异,并且以行为单位来比对,一般都是用在ASCII纯文本文件的比对上,由于是以行为单位的比对,因此diff通常使用在同一个文件(或软件)的新旧版本差异上。我们呢俩将/etc/passwd处理成一个新的版本,处理方式为:将第4行删除,第6行则替换为【no six line 】,新的文件放置到 /tmp/test 中

这个就是我们一会实验的文件,现在来看看diff的语法
diff [-bBi] from-file to-file
from-file:一个文件名,作为原始比对文件的文件名
to-file:一个文件名,作为目标比对文件的文件名
注意:from-file或to-file可以用-替换(标准输入)
-b:忽略一行中,仅有多个空白的差异
-B:忽略空白行的差异
-i:忽略大小写的不同
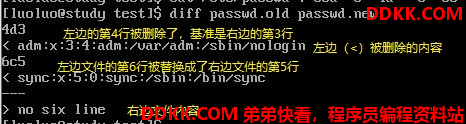
diff还可以比对目录的差异。
cmp
相对于diff的广泛用途,cmp似乎就用的没有那么多了,cmp主要也是在比对两个文件,它主要利用字节单位去比对(diff是以行去比对),因此,当然也可以比对二进制文件。
cmp [-l] file1 file2
-l:将所有不同点的字节处都列出来,因为cmp默认仅会输出第一个发现的不同点
patch
patch这个命令与diff有着密不可分的关系。我们前面说,diff可以用来辨别两个版本之间的差异,我们上面创建的那两个文件passwd.old与passwd.new就是两个不同版本的文件,那么,我们应该如何升级(让旧的文件升级成为新的文件),先比较新旧版本的差异,并将差异文件制作成为补丁文件,再由补丁文件更新旧文件即可。
由于默认CentOS7没有patch这个软件,所以我们先来通过挂载的光盘来安装patch这个软件
首先用命令将光盘挂在到/mnt下
su -
mount /dev/sr0 /mnt
然后找到patch包,用rpm将它安装
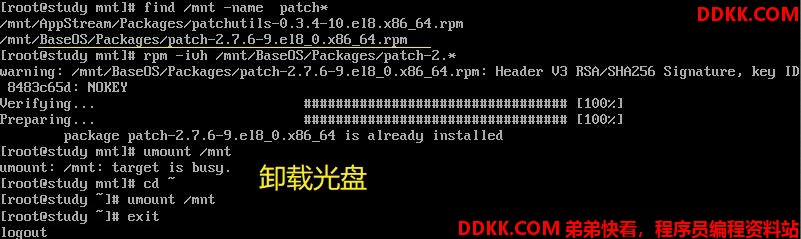
来了解一下patch:
patch -pN < patch_file <==更新
patch -R -pN < patch_file <==还原
-p:后面可以接【取消几层目录】的意思
-R:代表还原,将新的文件还原成为旧的文件
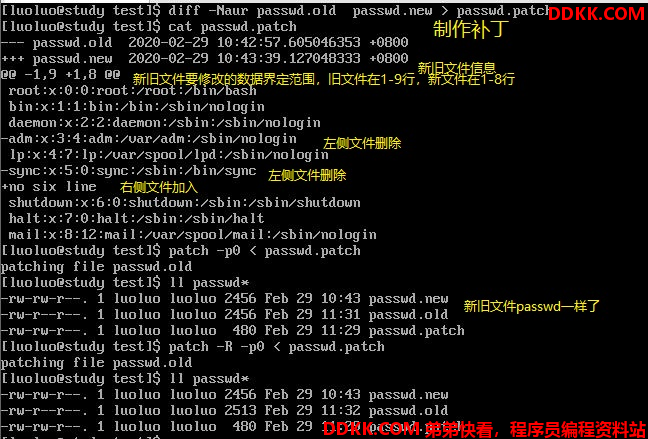
为什么这里会使用-p0呢?因为我们比对新旧版的数据时是在同一个目录下,因此不需要减去目录。如果是使用整体目录比对(diff 旧目录 新目录)时,就得要根据建立 patch 文件所在目录进行目录的删减。
patch后面我们还会聊。
文件打印设置:pr
我们可以通过pr来打印东西,还可以加入一些设置,比如加入打印的标题等,请参考pr的说明。
shell 脚本
shell script 程序化脚本,可以理解为是针对shell 所写的【剧本】
shell脚本是利用 shell 的功能所写的一个【程序(program)】。这个程序是使用纯文本文件,将一些shell的语法与命令(含外部命令)写在里面,搭配正则表达式、管道命令和数据流重定向等功能,以达到我们所想要的处理目的。
为什么要学习shell脚本
- 自动化管理的重要根据
- 跟踪与管理系统的重要工作
- 简单检测入侵
- 连续命令单一化
- 简易的数据处理
- 跨平台的支持与学习历程较短
编写shell
关于shell脚本有下面这么几点要注意
- 命令是从上而下、从左到右地分析与执行
- 命令的执行:命令、选项与参数间的多个空格会被忽略
- 空白行也将被忽略掉,并且Tab按键所产生的空白同样视为空格
- 如果读到一个Enter符号(CR),就尝试开始执行该行(或该串)命令
- 至于如果一行的内容太多,则可以使用【\Enter】来扩展至下一行
- 【#】可做注释,任何加在#后面的数据将全部被视为注释文字而被忽略
如此一来,我们在脚本内所编写的程序,就会被一行一行的执行。现在我们假设你写的这个程序文件名是 /home/luoluo/shell.sh,那如何执行这个文件?很简单,可以如下
- 直接命令执行:shell.sh文件必须要具备可读可执行的权限
- 变量【PATH】:将shell.sh放在PATH指定的目录内,例如:~/bin/
- 以bash程序来执行,即 bash shell.sh 或者 sh shell.sh(/bin/sh是/bin/bash的链接文件)
第一个脚本:
对,还是编写hello world!来吧。
在家目录下新建一个目录bin,创建一个hello.sh,写入如下内容
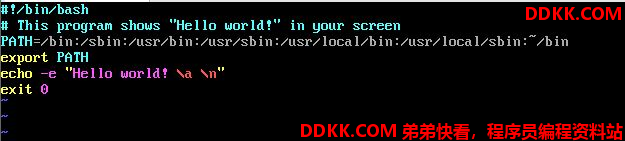
-
**第一行的 #!/bin/bash 在声明这个脚本使用的shell名称:**因为我们使用的是bash,所以,必须要以【#!/bin/bash】来声明这个文件内使用bash的语法。这样以【#!】开头的行被称为 shebang 行。当这个程序执行时,他就可以加载 bash 的相关环境配置文件(一般来说就是非登录shell的~/.bashrc),并且执行bash来使我们下面的命令能够执行。
-
**程序内容的说明,**除了第一行的#!/bin/bash是声明shell以外,其他的#都是注释,建议养成习惯写上
-
内容和功能
-
版本信息
-
作者与联系方式
-
建文件日期
-
历史记录等
-
**主要环境变量的声明,**建议务必将一些重要的环境变量设置好(比如PATH和LANG)。
-
主要程序部分
-
**执行结果告知,**定义返回值,例如上面的 exit 0 ,就是返回一个0,这正好对应了
$? 变量。
写脚本的良好习惯:
每个脚本的文件头处记录好:
- 脚本的功能
- 脚本的版本信息
- 脚本的作者与联络方式
- 脚本的版权声明方式
- 脚本的History
- 脚本内比较特殊的命令,使用绝对路径来执行
- 脚本运行时需要的环境变量预先声明与设置
shell脚本练习:
交互式脚本:变量内容由用户决定

随日期变化:利用 date 建立文件
假设我想要建立三个空文件(通过touch),文件名最开头由用户输入决定,假设用户输入filename,而今天的日期是2020/3/2,我想要以前天、昨天、今天的日期来建立这些文件,即filename_20200301,如下设置即可:
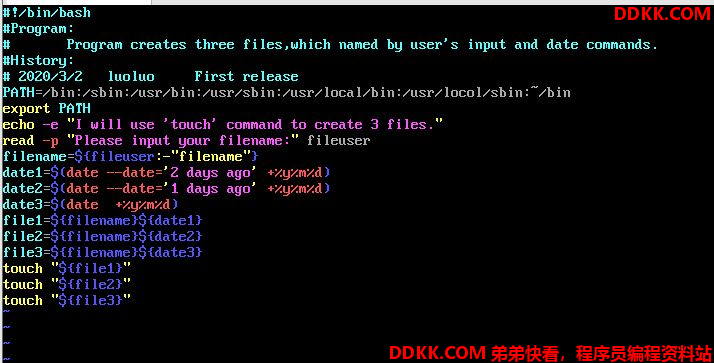
还记得吗?$(command)获取命令的结果
数值运算:简单的加减乘除

在Linux的bash中默认仅支持整数的数据,但是可以使用bc这个命令
echo "2.5*5" | bc
12.5
举一反三,我们再来测试一下如何计算Pi这个东西
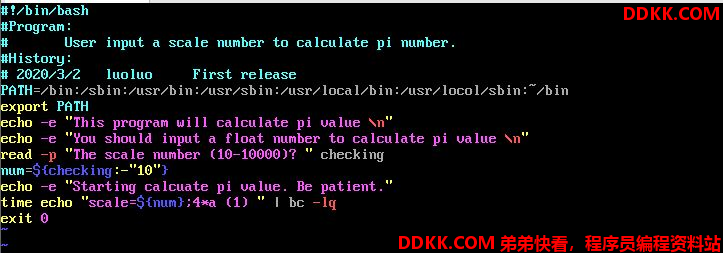
里面有几个操作可能你比较陌生
bc(选项)(参数)
-i:强制进入交互式模式;
-l:定义使用的标准数学库
-w:对POSIX bc的扩展给出警告信息;
-q:不打印正常的GNU bc环境信息;
-v:显示指令版本信息;
-h:显示指令的帮助信息。
- 4*a(1)是bc主动提供的一个计算pi的函数,至于scale就是要bc计算几个小数点位的意思。
脚本的执行方式差异(source、sh script、./script)
不同的脚本执行方式会造成不一样的结果,尤其是对bash的环境影响很大。脚本的执行除了前面提到的方式外,还可以通过 source 或小数点 (.)来执行。那么这些究竟有什么不同呢?
利用直接执行的方式来执行脚本
不论是绝对路径?相对路径还是 $PATH 内,还是bash (或 sh)来执行脚本,该脚本都会使用一个新的bash环境来执行脚本内的命令。也就是说,使用这些方式执行时,其实脚本是在子进程的bash里面执行的。
当子进程完成后,在子进程内的各项变量或操作将会结束而不会传回到父进程中。
即用直接执行的方法执行脚本的话,脚本中的定义都是属于子进程中的定义。当 script.sh 执行完毕后,子进程bash内的所有数据便会删除。
利用 source 来执行脚本:在父进程中执行
而source 可就不一样了,这个操作是在父进程中执行的,所以脚本里写的变量啥的脚本执行完后也会生效。
善用判断式
利用 test 命令的测试功能
test可以检测文件或相关属性
test -e 文件或目录
这样并不会直接显示信息,我们可以结合$?来判断文件或目录存在不存在,或者直接这样
test -e 文件或目录 && echo "exist" || echo "not exist"
关于test,更多参数如下:
| 测试的参数 | 代表意义 |
| 1. 关於某个档名的『文件类型』判断,如 test -e filename 表示存在否 |
| -e | 该『档名』是否存在?(常用) |
| -f | 该『档名』是否存在且为文件(file)?(常用) |
| -d | 该『档名』是否存在且为目录(directory)?(常用) |
| -b | 该『档名』是否存在且为一个 block device 装置? |
| -c | 该『档名』是否存在且为一个 character device 装置? |
| -S | 该『档名』是否存在且为一个 Socket 文件? |
| -p | 该『档名』是否存在且为一个 FIFO (pipe) 文件? |
| -L | 该『档名』是否存在且为一个连结档? |
| 2. 关於文件的权限侦测,如 test -r filename 表示可读否 (但 root 权限常有例外) |
| -r | 侦测该档名是否存在且具有『可读』的权限? |
| -w | 侦测该档名是否存在且具有『可写』的权限? |
| -x | 侦测该档名是否存在且具有『可运行』的权限? |
| -u | 侦测该档名是否存在且具有『SUID』的属性? |
| -g | 侦测该档名是否存在且具有『SGID』的属性? |
| -k | 侦测该档名是否存在且具有『Sticky bit』的属性? |
| -s | 侦测该档名是否存在且为『非空白文件』? |
| 3. 两个文件之间的比较,如: test file1 -nt file2 |
| -nt | (newer than)判断 file1 是否比 file2 新 |
| -ot | (older than)判断 file1 是否比 file2 旧 |
| -ef | 判断 file1 与 file2 是否为同一文件,可用在判断 hard link 的判定上。 主要意义在判定,两个文件是否均指向同一个 inode 哩! |
| 4. 关於两个整数之间的判定,例如 test n1 -eq n2 | |
| -eq | 两数值相等 (equal) |
| -ne | 两数值不等 (not equal) |
| -gt | n1 大於 n2 (greater than) |
| -lt | n1 小於 n2 (less than) |
| -ge | n1 大於等於 n2 (greater than or equal) |
| -le | n1 小於等於 n2 (less than or equal) |
| 5. 判定字串的数据 |
| test -z string | 判定字串是否为 0 ?若 string 为空字串,则为 true | |
| test -n string | 判定字串是否非为 0 ?<span “>若 string 为空字串,则为 false。 注: -n 亦可省略 |
|
| test str1 = str2 | 判定 str1 是否等於 str2 ,若相等,则回传 true | |
| test str1 != str2 | 判定 str1 是否不等於 str2 ,若相等,则回传 false |
| 6. 多重条件判定,例如: test -r filename -a -x filename |
| -a | (and)两状况同时成立!例如 test -r file -a -x file,则 file 同时具有 r 与 x 权限时,才回传 true。 |
| -o | (or)两状况任何一个成立!例如 test -r file -o -x file,则 file 具有 r 或 x 权限时,就可回传 true。 |
| ! | 反相状态,如 test ! -x file ,当 file 不具有 x 时,回传 true |
好,我们来利用test帮助我们呢写几个简单的例子,首先让用户输入一个用户名,我们判断:
1、 是否存在,若不存在则给与一个【Filenamedoesnotexist】,并中断程序;
2、 若这个文件存在,则判断它是个文件或目录,结果输出【Filenameisregularfile】或【Filenameisdirectory】;
3、 判断一下,执行者的身份对这个文件或目录所拥有的权限,并输出权限数据;
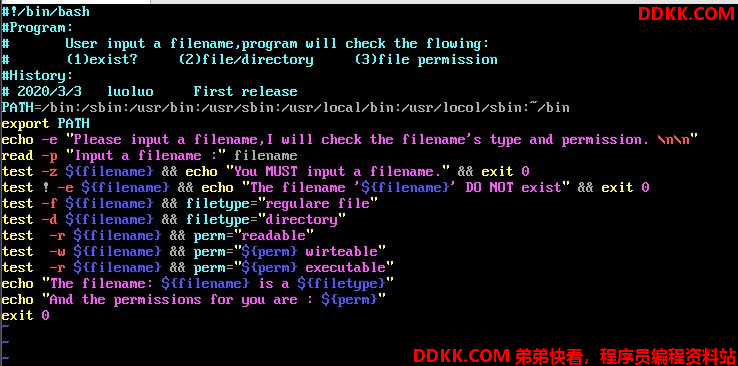
另外注意,由于root在很多权限的限制上面都是无效的,所以使用root执行这个脚本时,常常会发现ls -l 观察到的结果并不相同。
利用判断符号[ ]
除了我们很喜欢使用的test之外,其实,我们还可以使用判断符号[ ],来进行数据的判断。举例来说,我们想知道 ${HOME} 这个变量是否为空,可以这样:
[-z "${HOME}" ] ; echo $?
注意,为了区别于一般情景下的中括号,这里的中括号的两端需要有空格符来分隔,所以,你最好注意:
- 在中括号[]内的每个组件都需要空格来分隔
- 在中括号内的变量,最好都以双引号括号起来
- 在中括号内的常数,最好都以单或双引号括号起来
我们来用中括号做一个小案例:
1、 当执行一个程序的时候,这个程序会让用户选择Y或N;
2、 如果用户输入Y或y时,就显示【OK,continue】;
3、 如果用户输入n或N时,就显示【Oh,interrupt】;
4、 如果不是Y/y/N/n之内的其他字符,就显示【Idon’tknowwhatyourchoiceis】;

这里使用 -o (或)连接两个判断
shell 脚本的默认变量($0、$1)
我们知道命令可以带有选项与参数,例如 ls -al 可以查看包含隐藏文件的所有属性与权限。那么 shell 脚本能不能在脚本文件名后面加参数呢?有趣,举例来说,如果你想要重新启动系统的网络,可以这样:
file /etc/init.d/net/work
#查询文件类型,会发现是可执行文件
/etc/init.d/network restart
如果你要根据程序的执行给与一些变量去进行不同的任务时,通过命令后面接参数,那么一个命令就能够处理完毕而不需要手动输入一些变量操作。
脚本是如何完成这个功能的呢?其实脚本针对参数已经设置好了一些变量的名称,如下:
/path/to/scriptname opt1 opt2 opt3 opt4
$0 $1 $2 $3 $4
除了一些数字变量之外,我们还有一些较为特殊的变量可以在脚本内使用来调用这些参数:
$#:代表后面接的参数【个数】,以上表为例这里显示为【4】$@:代表【”$1″ “$2” “$3” “4”】之意,每个变量都是独立的(用双引号括起来)$*:代表【”$1c$2c$3c$4″】其中c为分隔字符,默认为空格,所以本例中代表【”$1$2$3$4″】
我们再来做个例子,执行一个脚本,会显示如下内容:
- 程序的文件名叫什么
- 共有几个参数
- 若参数的个数小于2则告知用户参数数量太少
- 全部的参数内容是什么
- 第一个参数是什么
- 第二个参数是什么
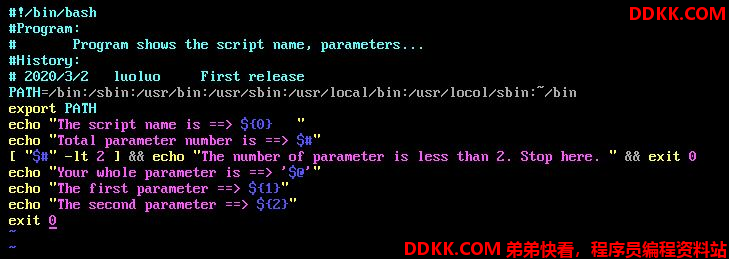

shift:造成参数变量号码偏移
除此之外,后面所接的变量是否能够进行偏移(shift)呢?不理解吗?没关系,我们来看下面的例子

结果如下:

这个shift会移动变量。
这部分就先记录到这里了,shell脚本部分并没有结束,只是下一篇文章我们再接着学习shell脚本。