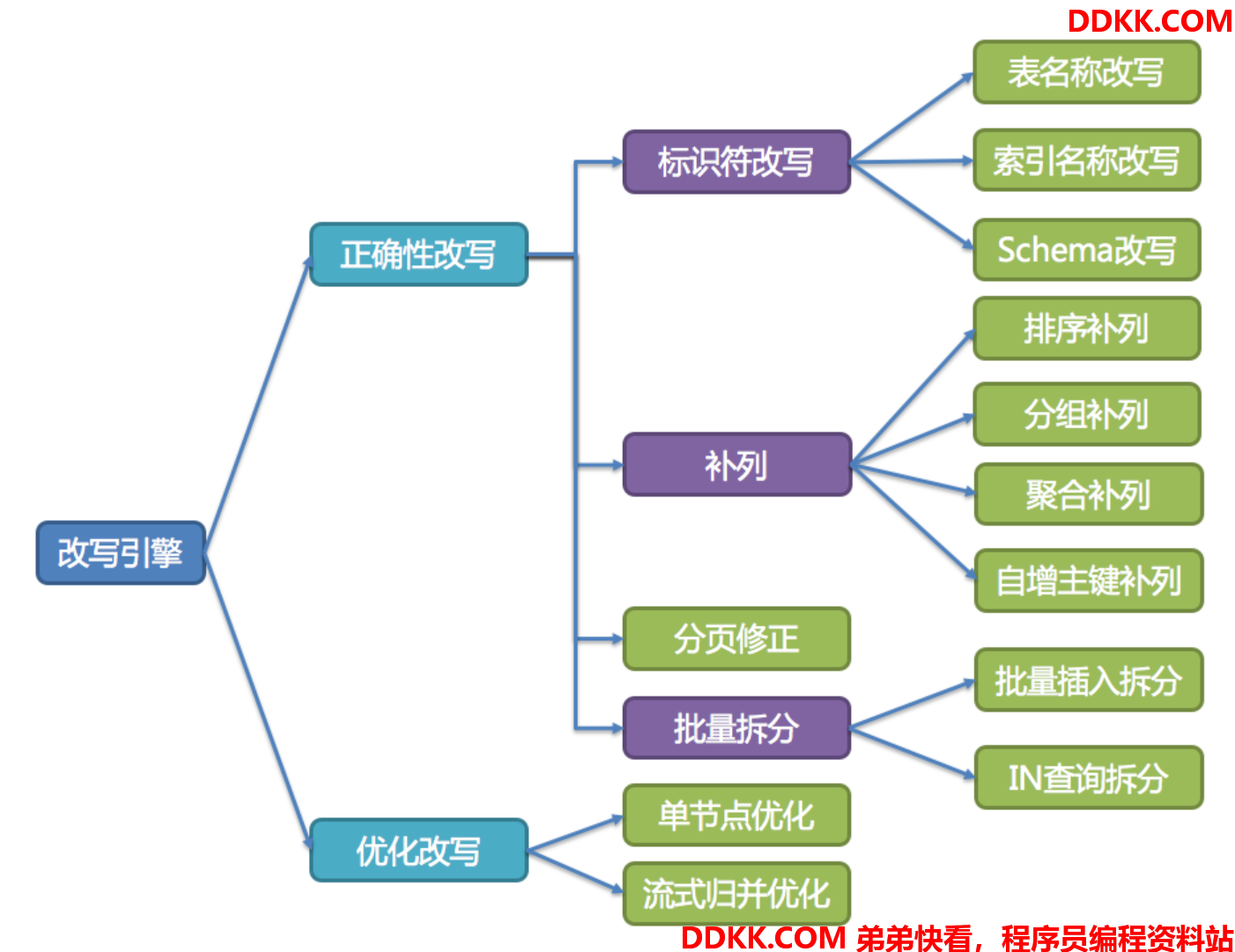
路由引擎
根据解析上下文匹配数据库和表的分片策略,并生成路由路径。 对于携带分片键的SQL,根据分片键的不同可以划分为单片路由(分片键的操作符是等号)、多片路由(分片键的操作符是IN)和范围路由(分片键的操作符是BETWEEN)。 不携带分片键的SQL则采用广播路由。
分片策略通常可以采用由数据库内置或由用户方配置。 数据库内置的方案较为简单,内置的分片策略大致可分为尾数取模、哈希、范围、标签、时间等。 由用户方配置的分片策略则更加灵活,可以根据使用方需求定制复合分片策略。 如果配合数据自动迁移来使用,可以做到无需用户关注分片策略,自动由数据库中间层分片和平衡数据即可,进而做到使分布式数据库具有的弹性伸缩的能力。 在ShardingSphere的线路规划中,弹性伸缩将于4.x开启。
分片路由
用于根据分片键进行路由的场景,又细分为直接路由、标准路由和笛卡尔积路由这3种类型。
直接路由
满足直接路由的条件相对苛刻,它需要通过Hint(使用HintAPI直接指定路由至库表)方式分片,并且是只分库不分表的前提下,则可以避免SQL解析和之后的结果归并。 因此它的兼容性最好,可以执行包括子查询、自定义函数等复杂情况的任意SQL。直接路由还可以用于分片键不在SQL中的场景。例如,设置用于数据库分片的键为3,
hintManager.setDatabaseShardingValue(3);
假如路由算法为value % 2,当一个逻辑库t_order对应2个真实库t_order_0和t_order_1时,路由后SQL将在t_order_1上执行。下方是使用API的代码样例:
String sql = "SELECT * FROM t_order";
try (
HintManager hintManager = HintManager.getInstance();
Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
hintManager.setDatabaseShardingValue(3);
try (ResultSet rs = pstmt.executeQuery()) {
while (rs.next()) {
//...
}
}
}
标准路由
标准路由是ShardingSphere最为推荐使用的分片方式,它的适用范围是不包含关联查询或仅包含绑定表之间关联查询的SQL。 当分片运算符是等于号时,路由结果将落入单库(表),当分片运算符是BETWEEN或IN时,则路由结果不一定落入唯一的库(表),因此一条逻辑SQL最终可能被拆分为多条用于执行的真实SQL。 举例说明,如果按照order_id的奇数和偶数进行数据分片,一个单表查询的SQL如下:
SELECT * FROM t_order WHERE order_id IN (1, 2);
那么路由的结果应为:
SELECT * FROM t_order_0 WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 WHERE order_id IN (1, 2);
绑定表的关联查询与单表查询复杂度和性能相当。举例说明,如果一个包含绑定表的关联查询的SQL如下:
SELECT * FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
那么路由的结果应为:
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
可以看到,SQL拆分的数目与单表是一致的。
笛卡尔路由
笛卡尔路由是最复杂的情况,它无法根据绑定表的关系定位分片规则,因此非绑定表之间的关联查询需要拆解为笛卡尔积组合执行。 如果上个示例中的SQL并未配置绑定表关系,那么路由的结果应为:
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
笛卡尔路由查询性能较低,需谨慎使用。
广播路由
对于不携带分片键的SQL,则采取广播路由的方式。根据SQL类型又可以划分为全库表路由、全库路由、全实例路由、单播路由和阻断路由这5种类型。
全库表路由
全库表路由用于处理对数据库中与其逻辑表相关的所有真实表的操作,主要包括不带分片键的DQL和DML,以及DDL等。例如:
SELECT * FROM t_order WHERE good_prority IN (1, 10);
则会遍历所有数据库中的所有表,逐一匹配逻辑表和真实表名,能够匹配得上则执行。路由后成为
SELECT * FROM t_order_0 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_1 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_2 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_3 WHERE good_prority IN (1, 10);
全库路由
全库路由用于处理对数据库的操作,包括用于库设置的SET类型的数据库管理命令,以及TCL这样的事务控制语句。 在这种情况下,会根据逻辑库的名字遍历所有符合名字匹配的真实库,并在真实库中执行该命令,例如:
SET autocommit=0;
在t_order中执行,t_order有2个真实库。则实际会在t_order_0和t_order_1上都执行这个命令。
全实例路由
全实例路由用于DCL操作,授权语句针对的是数据库的实例。无论一个实例中包含多少个Schema,每个数据库的实例只执行一次。例如:
CREATE USER customer@127.0.0.1 identified BY '123';
这个命令将在所有的真实数据库实例中执行,以确保customer用户可以访问每一个实例。
单播路由
单播路由用于获取某一真实表信息的场景,它仅需要从任意库中的任意真实表中获取数据即可。例如:
DESCRIBE t_order;
t_order的两个真实表t_order_0,t_order_1的描述结构相同,所以这个命令在任意真实表上选择执行一次。
阻断路由
阻断路由用于屏蔽SQL对数据库的操作,例如:
USE order_db;
这个命令不会在真实数据库中执行,因为ShardingSphere采用的是逻辑Schema的方式,无需将切换数据库Schema的命令发送至数据库中。
路由引擎的整体结构划分如下图。
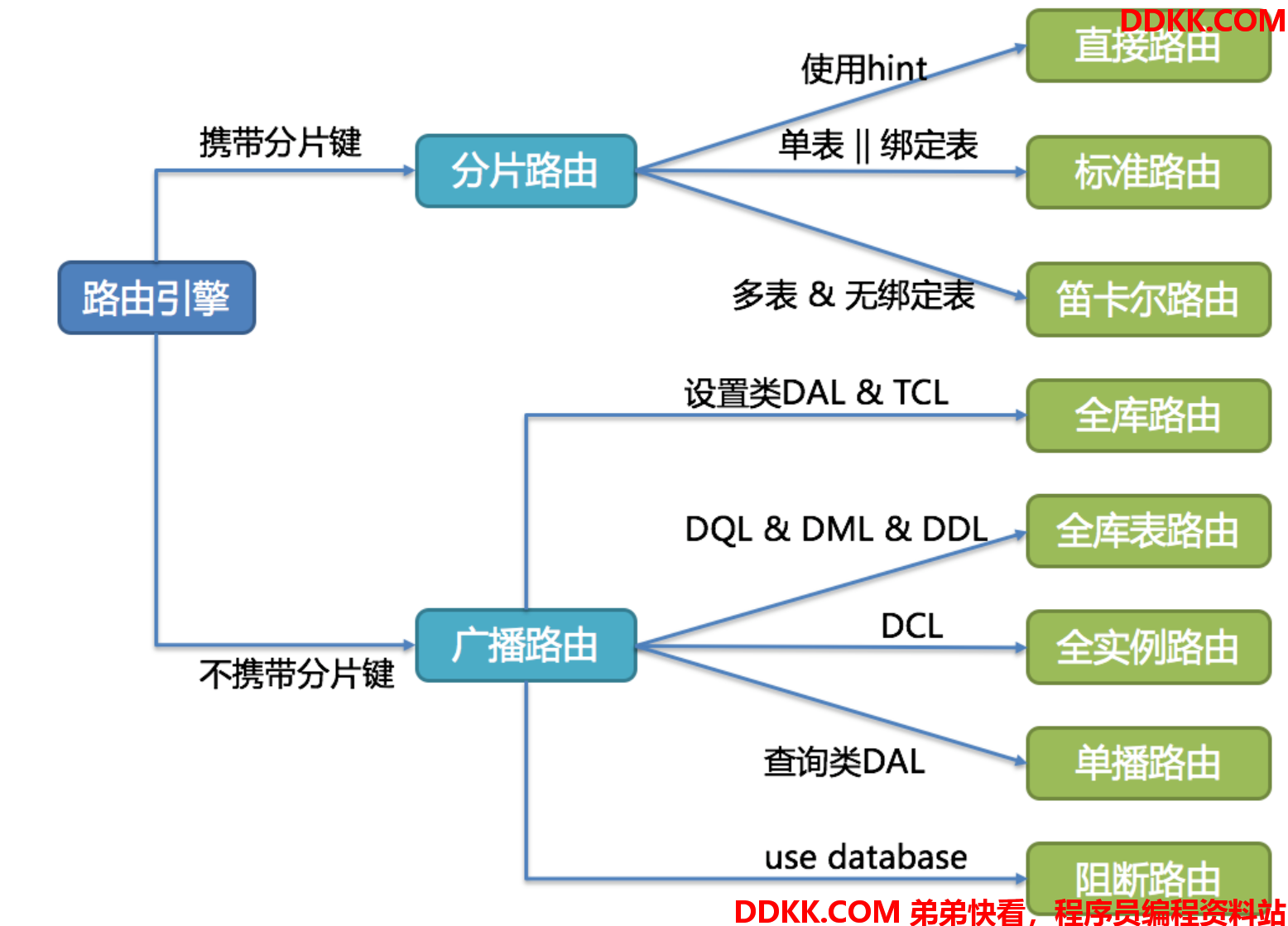
改写引擎
工程师面向逻辑库与逻辑表书写的SQL,并不能够直接在真实的数据库中执行,SQL改写用于将逻辑SQL改写为在真实数据库中可以正确执行的SQL。 它包括正确性改写和优化改写两部分。
正确性改写
在包含分表的场景中,需要将分表配置中的逻辑表名称改写为路由之后所获取的真实表名称。仅分库则不需要表名称的改写。除此之外,还包括补列和分页信息修正等内容。
标识符改写
需要改写的标识符包括表名称、索引名称以及Schema名称。
表名称改写是指将找到逻辑表在原始SQL中的位置,并将其改写为真实表的过程。表名称改写是一个典型的需要对SQL进行解析的场景。 从一个最简单的例子开始,若逻辑SQL为:
SELECT order_id FROM t_order WHERE order_id=1;
假设该SQL配置分片键order_id,并且order_id=1的情况,将路由至分片表1。那么改写之后的SQL应该为:
SELECT order_id FROM t_order_1 WHERE order_id=1;
在这种最简单的SQL场景中,是否将SQL解析为抽象语法树似乎无关紧要,只要通过字符串查找和替换就可以达到SQL改写的效果。 但是下面的场景,就无法仅仅通过字符串的查找替换来正确的改写SQL了:
SELECT order_id FROM t_order WHERE order_id=1 AND remarks=' t_order xxx';
正确改写的SQL应该是:
SELECT order_id FROM t_order_1 WHERE order_id=1 AND remarks=' t_order xxx';
而非:
SELECT order_id FROM t_order_1 WHERE order_id=1 AND remarks=' t_order_1 xxx';
由于表名之外可能含有表名称的类似字符,因此不能通过简单的字符串替换的方式去改写SQL。
下面再来看一个更加复杂的SQL改写场景:
SELECT t_order.order_id FROM t_order WHERE t_order.order_id=1 AND remarks=' t_order xxx';
上面的SQL将表名作为字段的标识符,因此在SQL改写时需要一并修改:
SELECT t_order_1.order_id FROM t_order_1 WHERE t_order_1.order_id=1 AND remarks=' t_order xxx';
而如果SQL中定义了表的别名,则无需连同别名一起修改,即使别名与表名相同亦是如此。例如:
SELECT t_order.order_id FROM t_order AS t_order WHERE t_order.order_id=1 AND remarks=' t_order xxx';
SQL改写则仅需要改写表名称就可以了:
SELECT t_order.order_id FROM t_order_1 AS t_order WHERE t_order.order_id=1 AND remarks=' t_order xxx';
索引名称是另一个有可能改写的标识符。 在某些数据库中(如MySQL),索引是以表为维度创建的,在不同的表中的索引是可以重名的; 而在另外的一些数据库中(如PostgreSQL),索引是以数据库为维度创建的,即使是作用在不同表上的索引,它们也要求其名称的唯一性。
在ShardingSphere中,管理Schema的方式与管理表如出一辙,它采用逻辑Schema去管理一组数据源。 因此,ShardingSphere需要将用户在SQL中书写的逻辑Schema替换为真实的数据库Schema。
ShardingSphere目前还不支持在DQL和DML语句中使用Schema。 它目前仅支持在数据库管理语句中使用Schema,例如:
SHOW COLUMNS FROM t_order FROM order_ds;
Schema的改写指的是将逻辑Schema采用单播路由的方式,改写为随机查找到的一个正确的真实Schema。
补列
需要在查询语句中补列通常由两种情况导致。 第一种情况是ShardingSphere需要在结果归并时获取相应数据,但该数据并未能通过查询的SQL返回。 这种情况主要是针对GROUP BY和ORDER BY。结果归并时,需要根据GROUP BY和ORDER BY的字段项进行分组和排序,但如果原始SQL的选择项中若并未包含分组项或排序项,则需要对原始SQL进行改写。 先看一下原始SQL中带有结果归并所需信息的场景:
SELECT order_id, user_id FROM t_order ORDER BY user_id;
由于使用user_id进行排序,在结果归并中需要能够获取到user_id的数据,而上面的SQL是能够获取到user_id数据的,因此无需补列。
如果选择项中不包含结果归并时所需的列,则需要进行补列,如以下SQL:
SELECT order_id FROM t_order ORDER BY user_id;
由于原始SQL中并不包含需要在结果归并中需要获取的user_id,因此需要对SQL进行补列改写。补列之后的SQL是:
SELECT order_id, user_id AS ORDER_BY_DERIVED_0 FROM t_order ORDER BY user_id;
值得一提的是,补列只会补充缺失的列,不会全部补充,而且,在SELECT语句中包含*的SQL,也会根据表的元数据信息选择性补列。下面是一个较为复杂的SQL补列场景:
SELECT o.* FROM t_order o, t_order_item i WHERE o.order_id=i.order_id ORDER BY user_id, order_item_id;
我们假设只有t_order_item表中包含order_item_id列,那么根据表的元数据信息可知,在结果归并时,排序项中的user_id是存在于t_order表中的,无需补列;order_item_id并不在t_order中,因此需要补列。 补列之后的SQL是:
SELECT o.*, order_item_id AS ORDER_BY_DERIVED_0 FROM t_order o, t_order_item i WHERE o.order_id=i.order_id ORDER BY user_id, order_item_id;
补列的另一种情况是使用AVG聚合函数。在分布式的场景中,使用avg1 + avg2 + avg3 / 3计算平均值并不正确,需要改写为 (sum1 + sum2 + sum3) / (count1 + count2 + count3)。 这就需要将包含AVG的SQL改写为SUM和COUNT,并在结果归并时重新计算平均值。例如以下SQL:
SELECT AVG(price) FROM t_order WHERE user_id=1;
需要改写为:
SELECT COUNT(price) AS AVG_DERIVED_COUNT_0, SUM(price) AS AVG_DERIVED_ SUM _0 FROM t_order WHERE user_id=1;
然后才能够通过结果归并正确的计算平均值。
最后一种补列是在执行INSERT的SQL语句时,如果使用数据库自增主键,是无需写入主键字段的。 但数据库的自增主键是无法满足分布式场景下的主键唯一的,因此ShardingSphere提供了分布式自增主键的生成策略,并且可以通过补列,让使用方无需改动现有代码,即可将分布式自增主键透明的替换数据库现有的自增主键。 分布式自增主键的生成策略将在下文中详述,这里只阐述与SQL改写相关的内容。 举例说明,假设表t_order的主键是order_id,原始的SQL为:
INSERT INTO t_order (field1, field2) VALUES (10, 1);
可以看到,上述SQL中并未包含自增主键,是需要数据库自行填充的。ShardingSphere配置自增主键后,SQL将改写为:
INSERT INTO t_order (field1, field2, order_id) VALUES (10, 1, xxxxx);
改写后的SQL将在INSERT FIELD和INSERT VALUE的最后部分增加主键列名称以及自动生成的自增主键值。上述SQL中的xxxxx表示自动生成的自增主键值。
如果INSERT的SQL中并未包含表的列名称,ShardingSphere也可以根据判断参数个数以及表元信息中的列数量对比,并自动生成自增主键。例如,原始的SQL为:
INSERT INTO t_order VALUES (10, 1);
改写的SQL将只在主键所在的列顺序处增加自增主键即可:
INSERT INTO t_order VALUES (xxxxx, 10, 1);
自增主键补列时,如果使用占位符的方式书写SQL,则只需要改写参数列表即可,无需改写SQL本身。
分页修正
从多个数据库获取分页数据与单数据库的场景是不同的。 假设每10条数据为一页,取第2页数据。在分片环境下获取LIMIT 10, 10,归并之后再根据排序条件取出前10条数据是不正确的。 举例说明,若SQL为:
SELECT score FROM t_score ORDER BY score DESC LIMIT 1, 2;
下图展示了不进行SQL的改写的分页执行结果。
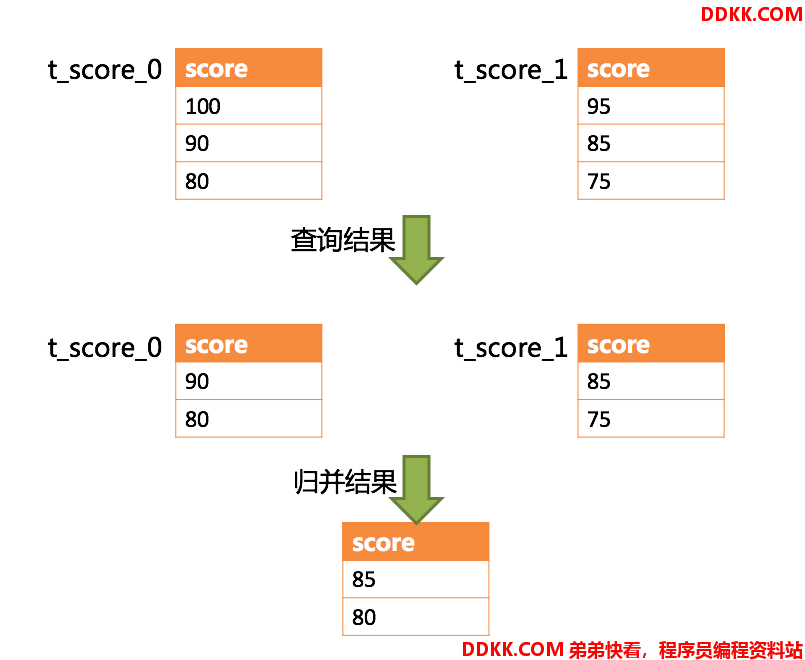
通过图中所示,想要取得两个表中共同的按照分数排序的第2条和第3条数据,应该是95和90。 由于执行的SQL只能从每个表中获取第2条和第3条数据,即从t_score_0表中获取的是90和80;从t_score_0表中获取的是85和75。 因此进行结果归并时,只能从获取的90,80,85和75之中进行归并,那么结果归并无论怎么实现,都不可能获得正确的结果。
正确的做法是将分页条件改写为LIMIT 0, 3,取出所有前两页数据,再结合排序条件计算出正确的数据。 下图展示了进行SQL改写之后的分页执行结果。
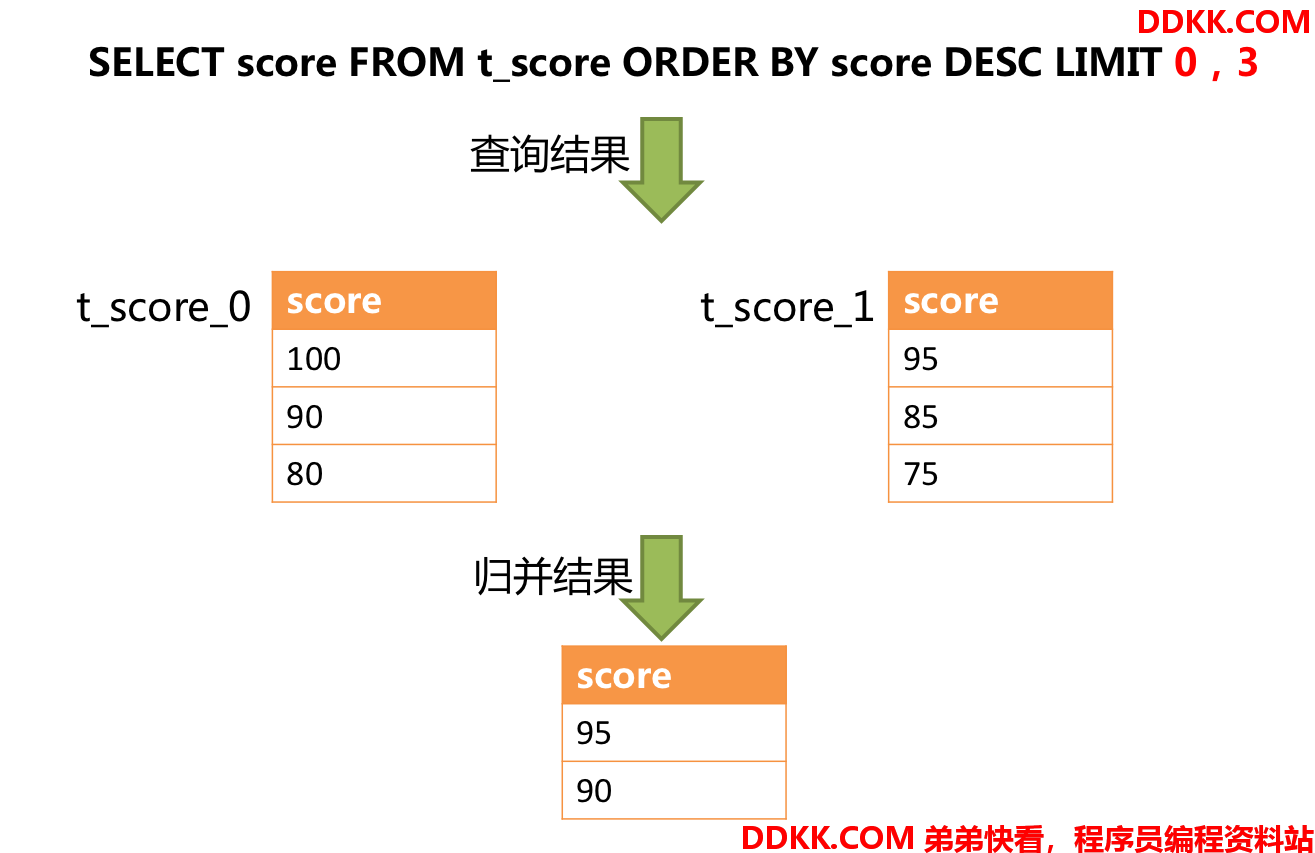 ]
]越获取偏移量位置靠后数据,使用LIMIT分页方式的效率就越低。 有很多方法可以避免使用LIMIT进行分页。比如构建行记录数量与行偏移量的二级索引,或使用上次分页数据结尾ID作为下次查询条件的分页方式等。
分页信息修正时,如果使用占位符的方式书写SQL,则只需要改写参数列表即可,无需改写SQL本身。
批量拆分
在使用批量插入的SQL时,如果插入的数据是跨分片的,那么需要对SQL进行改写来防止将多余的数据写入到数据库中。 插入操作与查询操作的不同之处在于,查询语句中即使用了不存在于当前分片的分片键,也不会对数据产生影响;而插入操作则必须将多余的分片键删除。 举例说明,如下SQL:
INSERT INTO t_order (order_id, xxx) VALUES (1, 'xxx'), (2, 'xxx'), (3, 'xxx');
假设数据库仍然是按照order_id的奇偶值分为两片的,仅将这条SQL中的表名进行修改,然后发送至数据库完成SQL的执行 ,则两个分片都会写入相同的记录。 虽然只有符合分片查询条件的数据才能够被查询语句取出,但存在冗余数据的实现方案并不合理。因此需要将SQL改写为:
INSERT INTO t_order_0 (order_id, xxx) VALUES (2, 'xxx');
INSERT INTO t_order_1 (order_id, xxx) VALUES (1, 'xxx'), (3, 'xxx');
使用IN的查询与批量插入的情况相似,不过IN操作并不会导致数据查询结果错误。通过对IN查询的改写,可以进一步的提升查询性能。如以下SQL:
SELECT * FROM t_order WHERE order_id IN (1, 2, 3);
改写为:
SELECT * FROM t_order_0 WHERE order_id IN (2);
SELECT * FROM t_order_1 WHERE order_id IN (1, 3);
可以进一步的提升查询性能。ShardingSphere暂时还未实现此改写策略,目前的改写结果是:
SELECT * FROM t_order_0 WHERE order_id IN (1, 2, 3);
SELECT * FROM t_order_1 WHERE order_id IN (1, 2, 3);
虽然SQL的执行结果是正确的,但并未达到最优的查询效率。
优化改写
优化改写的目的是在不影响查询正确性的情况下,对性能进行提升的有效手段。它分为单节点优化和流式归并优化。
单节点优化
路由至单节点的SQL,则无需优化改写。 当获得一次查询的路由结果后,如果是路由至唯一的数据节点,则无需涉及到结果归并。因此补列和分页信息等改写都没有必要进行。 尤其是分页信息的改写,无需将数据从第1条开始取,大量的降低了对数据库的压力,并且节省了网络带宽的无谓消耗。
流式归并优化
它仅为包含GROUP BY的SQL增加ORDER BY以及和分组项相同的排序项和排序顺序,用于将内存归并转化为流式归并。 在结果归并的部分中,将对流式归并和内存归并进行详细说明。
改写引擎的整体结构划分如下图所示。