TCC模式:
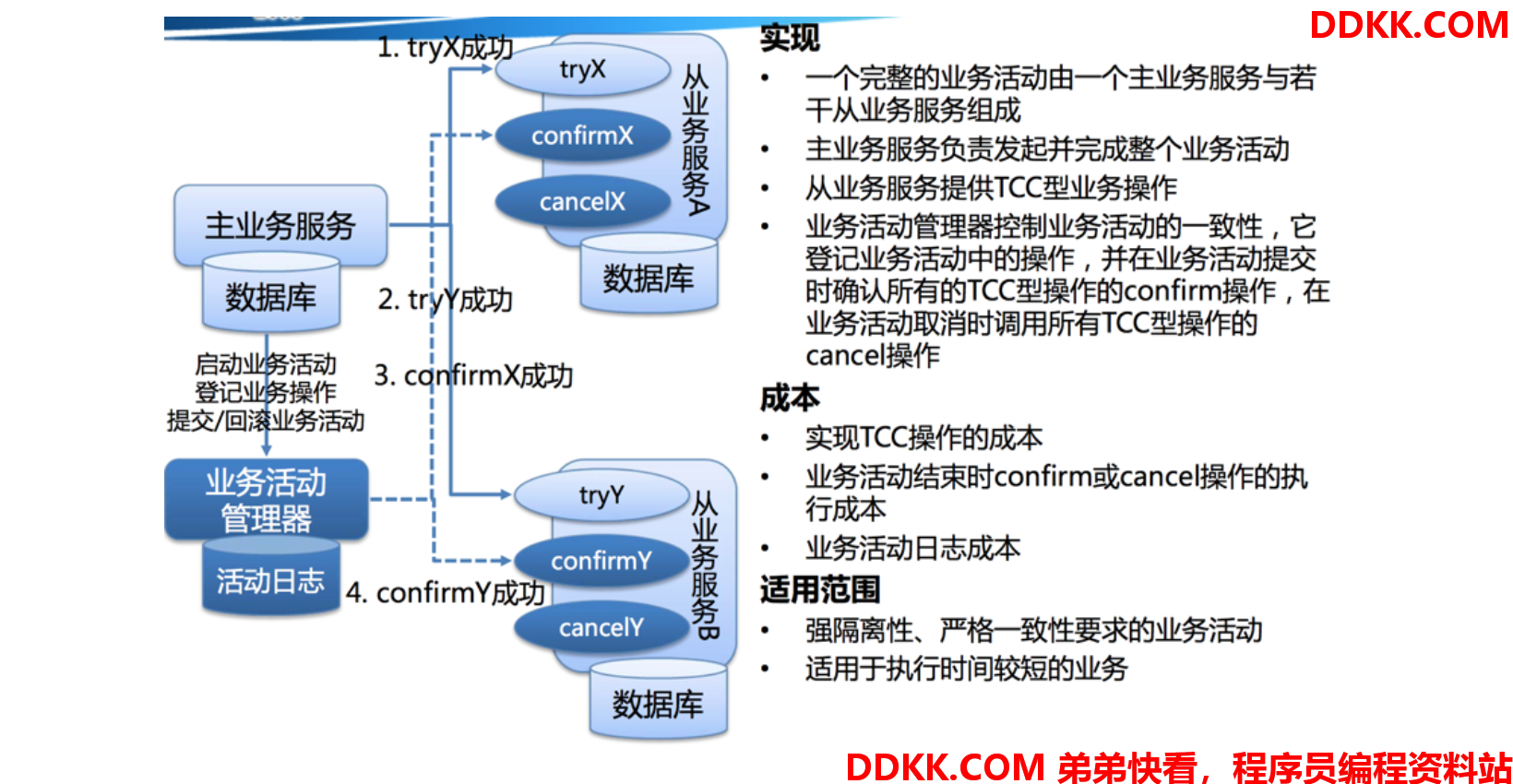
TCC是一种比较成熟的分布式事务解决方案,一个完整的TCC业务由一个主业务服务和若干个从业务服务组成,主业务服务发起并完成整个业务活动,TCC模式要求从服务提供三个接口:Try、Confirm、Cancel
Try:完成所有业务检查,预留必须业务资源
Confirm:真正执行业务,不作任何业务检查,只使用Try阶段预留的业务资源 Confirm操作满足幂等性
Cancel: 释放Try阶段预留的业务资源 Cancel操作满足幂等性整个TCC业务分成两个阶段完成。
业务操作步骤
第一阶段:主业务服务分别调用所有从业务的try操作,并在活动管理器中登记所有从业务服务。当所有从业务服务的try操作都调用成功或者某个从业务服务的try操作失败,进入第二阶段。
第二阶段:活动管理器根据第一阶段的执行结果来执行confirm或cancel操作。如果第一阶段所有try操作都成功,则活动管理器调用所有从业务活动的confirm操作。否则调用所有从业务服务的cancel操
需要注意的是第二阶段confirm或cancel操作本身也是满足最终一致性的过程,在调用confirm或cancel的时候也可能因为某种原因(比如网络)导致调用失败,所以需要活动管理支持重试的能力,同时这也就要求confirm和cancel操作具有幂等性。
例子
举个例子,假入 Bob 要向 Smith 转账,思路大概是:
我们有一个本地方法,里面依次调用
1、 首先在Try阶段,要先调用远程接口把Smith和Bob的钱给冻结起来;
2、 在Confirm阶段,执行远程调用的转账的操作,转账成功进行解冻;
3、 如果第2步执行成功,那么转账成功,如果第二步执行失败,则调用远程冻结接口对应的解冻方法(Cancel);
优点:跟2PC比起来,实现以及流程相对简单了一些,但数据的一致性比2PC也要差一些
缺点:缺点还是比较明显的,在2,3步中都有可能失败。TCC属于应用层的一种补偿方式,所以需要程序员在实现的时候多写很多补偿的代码,在一些场景中,一些业务流程可能用TCC不太好定义及处理。
小结
在补偿模式中一个比较明显的缺陷是,没有隔离性。从第一个工作服务步骤开始一直到所有工作服务完成(或者补偿过程完成),不一致是对其他服务可见的。另外最终一致性的保证还充分的依赖了协调服务的健壮性,如果协调服务异常,就没法达到一致性。
TCC模式在一定程度上弥补了上述的缺陷,在TCC模式中直到明确的confirm动作,所有的业务操作都是隔离的(由业务层面保证)。另外工作服务可以通过指定try操作的超时时间,主动的cancel预留的业务资源,从而实现自治的微服务。
TCC模式和补偿模式一样需要需要有协调服务和工作服务,协调服务也可以作为通用服务一般实现为框架。与补偿模式不同的是TCC服务框架不需要记录详细的业务流水,完成confirm和cancel操作的业务要素由业务服务提供。
TCC模式也不能百分百保证一致性,如果业务服务向TCC服务框架提交confirm后,TCC服务框架向某个工作服务提交confirm失败(比如网络故障),那么就会出现不一致,一般称为heuristic exception。
注意点
1、 允许空回滚;
在调用TCC服务的一阶段Try操作时,可能会出现因为丢包而导致的网络超时,此时事务协调器会触发二阶段回滚,调用TCC服务的Cancel操作;TCC服务在未收到Try请求的情况下收到Cancel请求,这种场景被称为空回滚;TCC服务在实现时应当允许空回滚的执行;
2、 防悬挂控制;
在调用TCC服务的一阶段Try操作时,可能会出现因网络拥堵而导致的超时,此时事务协调器会触发二阶段回滚,调用TCC服务的Cancel操作;在此之后,拥堵在网络上的一阶段Try数据包被TCC服务收到,出现了二阶段Cancel请求比一阶段Try请求先执行的情况;
用户在实现TCC服务时,应当允许空回滚,但是要拒绝执行空回滚之后到来的一阶段Try请求;
3、 幂等控制;
无论是网络数据包重传,还是异常事务的补偿执行,都会导致TCC服务的Try、Confirm或者Cancel操作被重复执行;用户在实现TCC服务时,需要考虑幂等控制,即Try、Confirm、Cancel 执行一次和执行多次的业务结果是一样的;
4、 业务数据可见性控制;
TCC服务的一阶段Try操作会做资源的预留,在二阶段操作执行之前,如果其他事务需要读取被预留的资源数据,那么处于中间状态的业务数据该如何向用户展示,需要业务在实现时考虑清楚;通常的设计原则是“宁可不展示、少展示,也不多展示、错展示”;
5、 业务数据并发访问控制;
TCC服务的一阶段Try操作预留资源之后,在二阶段操作执行之前,预留的资源都不会被释放;如果此时其他分布式事务修改这些业务资源,会出现分布式事务的并发问题;用户在实现TCC服务时,需要考虑业务数据的并发控制,尽量将逻辑锁粒度降到最低,以最大限度的提高分布式事务的并发性;
其他
1、 如其他可能的必要的加入:如果有一些意外的情况发生了,比如说xx服务突然挂了,然后再次重启,TCC分布式事务框架是如何保证之前没执行完的分布式事务继续执行的呢?所以,TCC事务框架都是要记录一些分布式事务的活动日志的,可以在磁盘上的日志文件里记录,也可以在数据库里记录保存下来分布式事务运行的各个阶段和状态如可能是的实现:每次try会生成在每个微服务的数据库中事务记录表中添加一条记录;后台开启xx秒线程定时对事务记录做补偿执行cancel或者confirm方法;没有一个独立的协调服务,都是在本地完成的;
2、 TCC分布式事务框架,比如国内开源的ByteTCC、himly、tcc-transaction,方便感知各个阶段的执行情况以及推进执行下一个阶段的这些事情;
3、 最后在石杉的架构笔记中,有一个案例:;
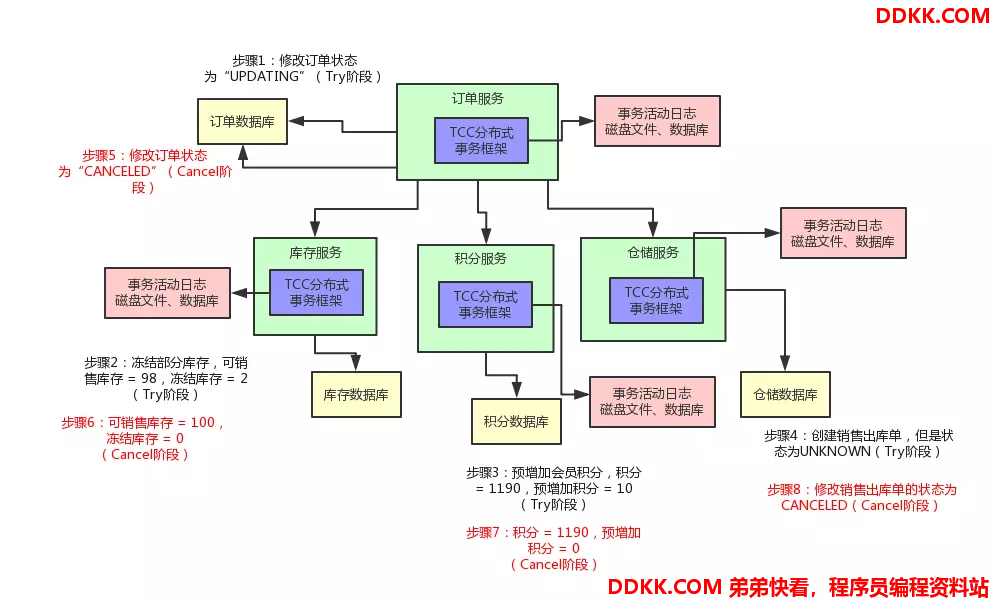
假设你现在有一个电商系统,里面有一个支付订单的场景。
那对一个订单支付之后,我们需要做下面的步骤:
更改订单的状态为“已支付”
扣减商品库存
给会员增加积分
创建销售出库单通知仓库发货
给出的解决方案如下图: