Zab也是一个强一致性算法,也是(multi-)Paxos的一种,全称是Zookeeper atomic broadcast protocol,是Zookeeper内部用到的一致性协议。相比Paxos,也易于理解。其保证了消息的全局有序和因果有序,拥有强一致性。Zab和Raft也是非常相似的,只是其中有些概念名词不一样。
名词概念
为了读懂后面的内容,有些术语需要了解:
Peer:节点。代表了系统中的进程,往往系统有多个进程,也就有多个节点提供服务
Quorum:多数。当有N个Peer,多数就代表Q(Q>N/2)个Peer
Leader:主节点,最多存在一个。代表zookeeper系统中主要的工作进程,Leader才是真正处理所有zookeeper写请求的节点,写请求会从Leader广播到Quorum Follower
Follower:从节点,可以有多个。如果client对zookeeper发起一个读请求,Follower可以直接处理。如果client对zookeeper发起一个写请求,Follower需要转发到唯一的Leader,再有Leader处理并发起广播
Election:说明节点处于选举状态。整个集群都处于选举状态中。
Epoch:逻辑时钟,相当于paxos中的proposerID,Raft中的term,相当于一个国家,朝代纪元(每个 leader 就像皇帝,都有自己的年号,所以每次改朝换代,leader 变更之后,都会在前一个年代的基础上加 1。这样就算旧的 leader 崩溃恢复之后,也没有人听他的了,因为 follower 只听从当前年代的 leader 的命令。)
zxid:事务id。zk为了保证消息有序性,提出了事务编号这个概念。zxid是一个二元组<e,c>,e代表选举纪元(如果将选举理解更皇帝的选举,这纪元代表年号),c代表事务的计数,同一纪元内每次出现写请求,c自增(代表某个年号内经过了多少年)。容易理解,纪元不变时,计数不断增加,纪元变化时,计数清零(是一个 64 位的数字,低 32 位是一个简单的单调递增的计数器,针对客户端每一个事务请求,计数器加 1;高 32 位则代表 Leader 周期 epoch 的编号,每个当选产生一个新的 Leader 服务器,就会从这个 Leader 服务器上取出其本地日志中最大事务的ZXID,并从中读取 epoch 值,然后加 1,以此作为新的 epoch,并将低 32 位从 0 开始计数。)
history: a log of transaction proposals accepted; 历史提议日志文件
acceptedEpoch: the epoch number of the last NEWEPOCH message accepted; 集群中的最近最新Epoch
currentEpoch: the epoch number of the last NEWLEADER message accepted; 集群中的最近最新Leader的Epoch
lastZxid: zxid of the last proposal in the history log; 历史提议日志文件的最后一个提议的zxid
vote:选票,代表二元组<zi,i>。zk会给每个peer打上唯一标识,即i,二元组的i就代表了选举的peer,而zi代表了这个peer上最新的zxid
state:节点状态,目前只有这三种election、leading、following
lastCommittedZxid:最近提交成功的事务
oldThreshold:日志中记录最早提交成功的事务。之所以设置一个最早的门槛,就是觉得没有必要保留非常久远以前的事务,以便减少对内存的占用以及数据同步带来的网络开销
协议实现
Zab协议中描述的如下四个阶段
Phase 0: Leader election(选举阶段,Leader不存在)
节点在一开始都处于选举阶段,只要有一个节点得到超半数Quorums节点的票数的支持,它就可以当选prospective leader。只有到达 Phase 3 prospective leader 才会成为established leader(EL)。
Phase 1: Discovery(发现阶段,Leader不存在)
在这个阶段,PL收集Follower发来的acceptedEpoch,并确定了PL的Epoch和Zxid最大,则会生成一个NEWEPOCH分发给Follower,Follower确认无误后返回ACK给PL。这个一阶段的主要目的是PL生成NEWEPOCH,同时更新Followers的acceptedEpoch,并寻找最新的historylog,赋值给PL的history。
一个follower 只会连接一个 leader,如果有一个节点 f 认为另一个 follower 是 leader,f 在尝试连接 p 时会被拒绝,f 被拒绝之后,就会进入 Phase 0。
Phase 2: Synchronization(同步阶段,Leader不存在)
同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。只有当 quorum 都同步完成,PL才会成为EL。follower 只会接收 zxid 比自己的 lastZxid 大的提议。
这个一阶段的主要目的是同步PL的historylog副本。
Phase 3: Broadcast(广播阶段,Leader存在)
到了这个阶段,Zookeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。这个一阶段的主要目的是接受请求,进行消息广播值得注意的是,ZAB 提交事务并不像 2PC 一样需要全部 follower 都 ACK,只需要得到 quorum (超过半数的节点)的 ACK 就可以了。
但是实际上zookeeper(3.3.3的版本的实现为准)中会有一些改进简化,简化为三个阶段
改进简化原因
- 阶段0的选举leader实际上很简陋,只是“看对眼”了就选为预备leader,所以预备leader的数据可能并非最新
- 预备leader数据过期,就需要用阶段1来弥补,通过互相传输数据,来发现最新的数据,并完成预备leader的数据升级
- 更多的网络间数据传输代表了更大的网络开销
Phase 1 快速选举Leader阶段(FLE)
首先初始化一些数据
- ReceivedVotes:投票箱,存储投票节点以及当前投票信息
- OutOfElection:存储已经成为Leader、Follower,不参与投票的节点信息,以及它的历史投票信息
- 在选票中写上自己的大名
- send notification:发起选票通知,该节点会携带选票,进入目标节点的队列中,相当于给自己投了一票,并毛遂自荐给其他人
如果当前节点处于选举状态,则它也会接到选票通知。它会从队列中不断轮询节点,以便获取选票信息(如果超时,则不断放松超时时间,直至上限)。根据轮询出来的发送节点的状态,来做相应的处理。
- election:如果发送节点的轮次(round)大于自己,说明自己的选举信息过时,则更新自己的选举轮次,清空投票箱,更新自己的选票内容,并将新的选票通知给其他节点;如果发送节点的轮次等于自己,并且投票内容比自己的更新,则只需要更新自己的选票,并通知给其他节点就行;如果发送节点的轮次小于自己,说明投票内容过期,没有参考意义,直接忽略。所有未被忽略的选票,都会进入投票箱。最终根据选票箱中的结果,判断当前节点的选票是不是占大多数,如果是就根据当前节点的选票选出Leader
- leading或following:发送节点轮次等于自己,说明发送节点还参与投票,如果发送节点是Leading或者它的选票在选票箱中占大多数,则直接完成选举;如果发送节点已经完成选举(轮次不同)或者它收集的选票较少,那么它的信息都会存放在OutOfElection中。当节点不断完成选举,OutOfElection中数量逐渐变成Quorum时,就把OutOfElection当做投票箱,从中检查发送节点的选票是否占多数,如果是就直接选出Leader
Phase 2 恢复阶段
经过FLE,已经选出了日志中具有最新已提交的事务的节点作为预备Leader。下面就分Leader和Follower两个视角来介绍具体实现。
Leader视角
首先,更新lastZxid,将纪元+1,计数清零,宣布改朝换代啦。然后在每次接收到Follower的数据同步请求时,都会将自己lastZxid反馈回去,表示所有Follower以自己的lastZxid为准。接下来,根据具体情况来判断该如何将数据同步给Follower
- 如果Leader的历史提交事务比Follower的最新事务要新,说明Follower的数据有待更新。更新方式取决于,Leader最早事务有没有比Follower最新事务要新:如果前者更新,说明在Leader看来Follower所有记录的事务都太过陈旧,没有保留价值,这时只需要将Leader所有history发给Follower就行(响应SNAP);如果后者更新,说明在Leader看来,Follower从自己的lastZxid开始到Leader日志的最新事务,都需要同步,于是将这一部分截取并发送给Follower(响应DIFF)
- 如果Leader的历史提交事务没有Follower的最新事务新,说明Follower存在没有提交的事务,这些事务都应该被丢弃(响应TRUNC)
当Follower完成同步时,会发送同步ack,当Leader收到Quorum ack时,表示数据同步阶段大功告成,进入最后的广播阶段。
Follower视角
通知Leader,表示自己希望能同步Leader中的数据。
- 当收到Leader的拒绝响应时,说明Leader不承认自己作为Follower,有可能该Leader并不可靠,于是开始重新开始FLE
- 当收到SNAP或DIFF响应时,Follower会同步Leader发送过来的事务
- 当收到TRUNC响应,Follower会丢弃所有未完成的数据
当每个Follower完成上述的同步过程时,会发送ack给Leader,并进入广播阶段。
Phase 3 广播阶段
进入到这个阶段,说明所有数据完成同步,Leader已经转正。开始zookeper最常见的工作流程:广播。
广播阶段是真正接受事务请求(写请求)的阶段,也代表了zookeeper正常工作阶段。所有节点都能接受客户端的写请求,但是Follower会转发给Leader,只有Leader才能将这些请求转化成事务,广播出去。这个节点一样有两个角色,下面还是按照这两个角色来讲解。
Leader视角:
- Leader必须经过ready,才能接受写请求。完成ready的Leader不断接受写请求,转化成事务请求,广播给Quorum Follower。
- 当Leader接收到ack时,说明Follower完成相应处理,Leader广播提交请求,Follower完成提交。
- 当发现新Peer请求作为Follower加入时,将自己的纪元、事务日志发送给该Peer,以便它完成上述恢复阶段的过程。收到该Peer的同步完成的ack时,Leader会发送提交请求,以便Peer提交所有同步完成的事务。这时,该Peer转正为Follower,被Leader纳入Quorum Follower中。
Follower视角:
- Follower被发现是Leading状态,则执行ready过程,用来接受写请求。
- 当接受到Leader广播过来的事务请求时,Follower会将事务记录在history,并响应ack。
- 当接收到Leader广播过来的提交请求时,Follower会检查history中有没有尚未提交的事务,如果有,需要等待之前的事务按照FIFO顺序提交之后,才能提交本事务。
ZAB与Raft的比较
1.选举对比
- 检测 leader down 机:Raft 协议 leader 宕机仅仅由 folower 进行检测,当 folower 收不到 leader 心跳时,则认为 leader 宕机,变为 candidate。Zk 的 leader down 机分别由 leader 和 folower 检测,leader 维护了一个 Quorum 集合,当该 Quorum 集合不再超过半数,leader 自动变为 LOOKING 状态。folower 与 leader 之间维护了一个超链接,连接断开则 folower 变为 LOOKING 状态。
- leader 选举的投票过程:Raft 每个选举周期每个节点只能投一次票,选举失败进入下次周期才能重新投票。Zk 每次选举节点需要不断的变换选票以便选出数据最新的节点为 leader
- 保证 commited 的数据出现在未来 leader 中:Raft选取 leader 时拒绝数据比自己旧的节点的投票。Zk 通过在选取 leader 时不断更新选票使得拥有最新数据的节点当选 leader
2.日志复制
- 选取新 leader 后数据同步:Raft 没有固定在某个特定的阶段做这件事情,通过每个节点的 AppendEntry RPC 分别做数据同步。Zk 则在新leader 选举之后,有一个 Recovery Phase 做这个件事情。
- 选取新 leader 后同步的数据量:Raft 只需要传输和新 leader 差异的部分。Zab 的原始协议需要传输 leader 的全部数据,Zk 优化后,视情况而定,最坏情况下需要传输 leader 全部数据。
- 新 leader 对之前 leader 未 commit 数据的处理:Raft 不会直接 commit 之前 leader 的数据,通过 commit 本 term 的数据间接的 commit 之前 leader 的数据。Zk 在 Recovery Phase直接 commit 之前 leader 的数据。
- 新加入集群节点的数据同步:Raft 对于新加入集群的节点数据同步不会影响客户端的写请求。Zk 对于新加入集群的节点,需要单独走一下 Recovery Phase,目前是通过读写锁同步的,因此会阻塞客户端的写请求。
3.日志压缩
Raft 和 Zk 状态机的实现机制不同使得两者在 snapshot 的时候有很大差别。Raft是典型的传统复制窗台机,对于更新请求,严格复制对应的 command。Zk 则不是严格的复制状态机,对于更新请求,复制的不是响应的 command 而是更新后的值。如图所示。
- Raft 的 snapshot 机制对应了某一个时刻完成的状态机的数据
- Zk 是一种 fuzzy snapshot 机制,Zk snapshot 的时候,会记录下来当前的 zxid,恢复的时候,从该 snapshot 开始,replay 所有的 log 实现最终数据的正确性。Zk 甚至不存在一个时刻和 snapshot 的数据完全一致。
Zk之所以可以这样做,很大程度上依赖于其状态机的实现,比如 y++ 这条 log 在 Raft的复制状态机机制下如果被重复执行就会导致错误的结果,但是 y <- 2 被重复执行不会影响数据的正确性。
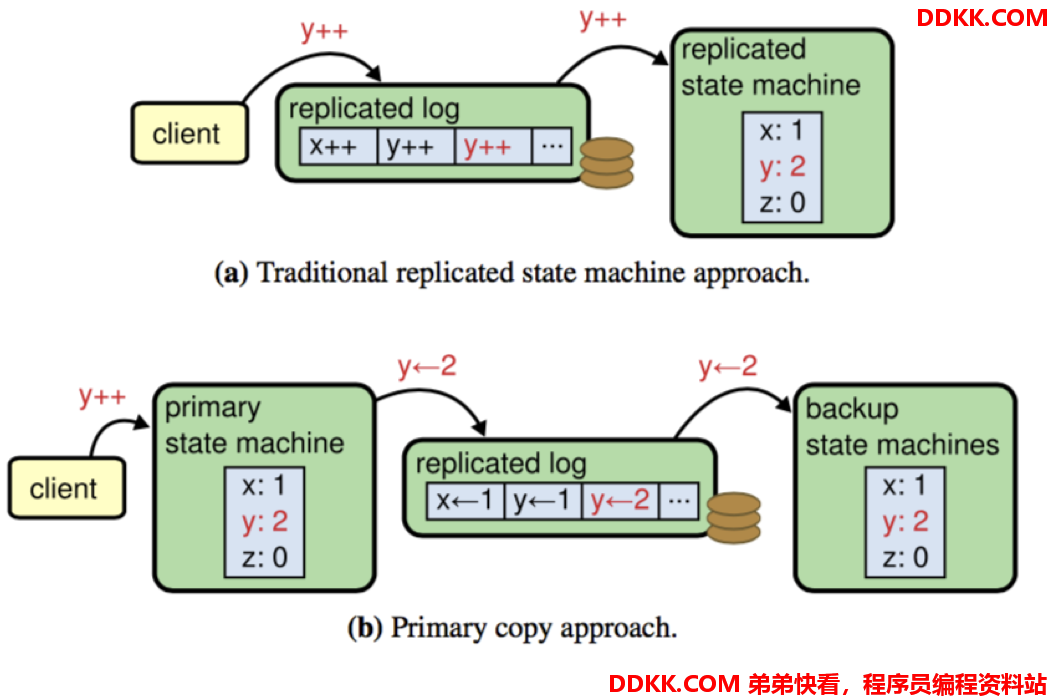
4.客户端读取
- Raft 严格禁止 stale read 的存在,无论是 Raft log read 或 readIndex read 或 lease read 都不会出现 stale read。
- Zk 默认情况下会出现 stale read,如果想避免 stale read 必须使用 sync() + read()
总结
个人认为 Zab 协议设计的优秀之处有两点,一是简化二阶段提交,提升了在正常工作情况下的性能;二是巧妙地利用率自增序列,简化了异常恢复的逻辑,也很好地保证了顺序处理这一特性。
参考资料和衍生阅读:
https://cloud.tencent.com/developer/news/261787
https://blog.csdn.net/A_zhenzhen/article/details/78839843
https://www.jianshu.com/p/fb527a64deee
https://my.oschina.net/u/1378920/blog/914215
https://www.jianshu.com/p/24307e7ca9da
https://niceaz.com/2018/11/03/raft-and-zab/#log-replication-and-commitment