一、概述
1、Flink 是什么
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数 据流进行状态计算。
2 、Flink 特点
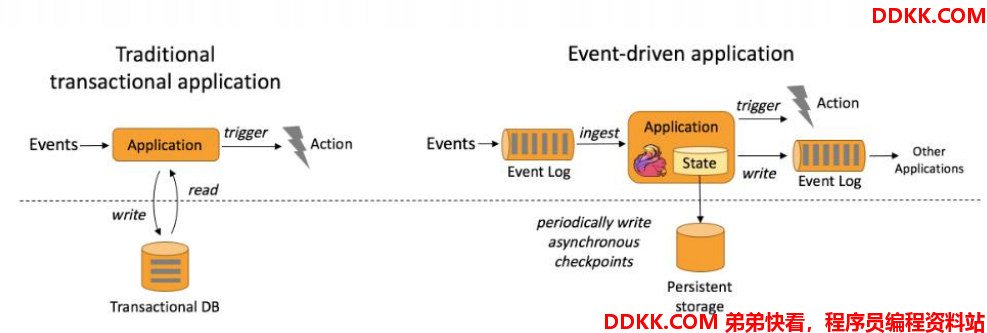
2.1、事件驱动(Event-driver)
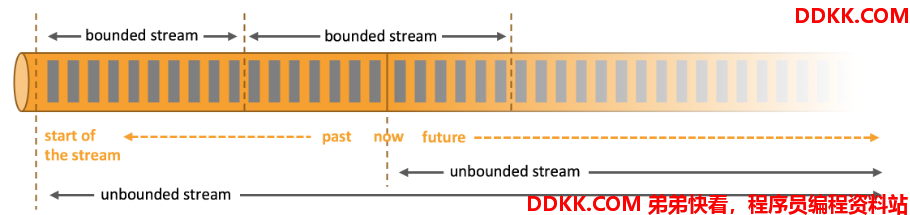
2.2、有界流和无界流
有界流:相对于离线数据集
无界流:相对于实时数据
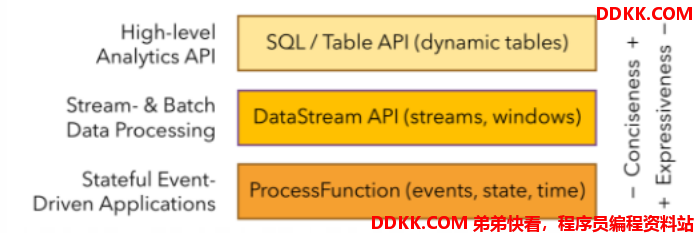
2.3、分层 API
越顶层越抽象,表达含义越简明,使用越方便
越底层越具体,表达能力越丰富,使用越灵活
2.4、支持事件时间(Event-time)
事件时间:数据产生的时间
2.5、支持处理时间(Processing-time)
处理时间:程序处理数据的时间
2.6、精准一次性的状态保证(Exactly-once)
2.7、低延迟、高吞吐
2.8、高可用、动态扩展
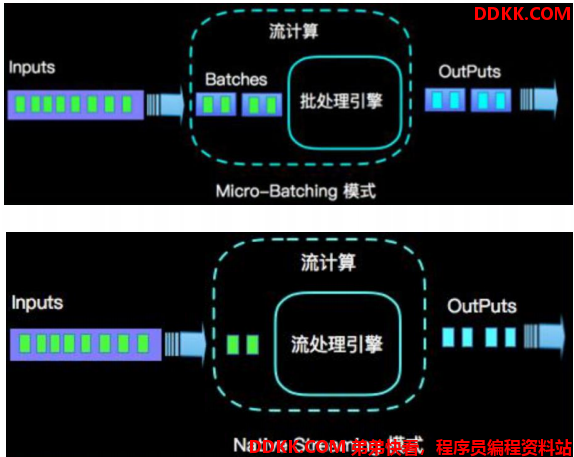
3、区别SparkStreaming
Flink是真正意义上的流式计算框架,基本数据模式是数据流,以及事件序列。
SparkStreaming是微批次的,通常都要设置批次大小,几百毫秒或者几秒,这一小批数据是 RDD集合,并且DAG引擎把job分为不同的Stage。
二、入口 wordcount
1、 pom依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.10.1</version>
</dependency>
</dependencies>
2、有界数据 wordcount
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class DataSetWordcount {
public static void main(String[] args) throws Exception {
// 1、创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2、读取数据
String path = "D:\\project\\flink\\src\\main\\resources\\wordcount.txt";
// DataSet -> Operator -> DataSource
DataSet<String> inputDataSet = env.readTextFile(path);
// 3、扁平化 + 分组 + sum
DataSet<Tuple2<String, Integer>> resultDataSet = inputDataSet.flatMap(new MyFlatMapFunction())
.groupBy(0) // (word, 1) -> 0 表示 word
.sum(1);
resultDataSet.print();
}
public static class MyFlatMapFunction implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String input, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = input.split(" ");
for (String word : words) {
collector.collect(new Tuple2<>(word, 1));
}
}
}
}
3、无界数据 wordcount
在192.168.200.102 主机启动 nc -lk 9999
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class StreamWordcount {
public static void main(String[] args) throws Exception {
// 1、创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、读取 socket 数据
DataStreamSource<String> inputDataStream = env.socketTextStream("192.168.200.102", 9999);
// 3、计算
SingleOutputStreamOperator<Tuple2<String, Integer>> resultDataStream = inputDataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String input, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = input.split(" ");
for (String word : words) {
collector.collect(new Tuple2<>(word, 1));
}
}
}).keyBy(0)
.sum(1);
// 4、输出
resultDataStream.print();
// 5、启动 env
env.execute();
}
}