一、map
map算子把input类型数据转换为output类型数据
eg:String input = “sensor,123456,33.0”
SensorReading(“sensor”,123456L,33.0d)
dataStream.map(new Mapfunction<input,output>{xxx})
import com.tan.flink.bean.SensorReading;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Transform_Map {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> inputDataStream = env.socketTextStream("192.168.200.102", 9999);
SingleOutputStreamOperator<SensorReading> resultDataStream = inputDataStream.map(new MapFunction<String, SensorReading>() {
@Override
public SensorReading map(String input) throws Exception {
String[] fields = input.split(",");
String id = fields[0];
Long timestamp = Long.parseLong(fields[1]);
Double temperatur = Double.parseDouble(fields[2]);
return new SensorReading(id, timestamp, temperatur);
}
});
resultDataStream.print();
env.execute();
}
}
二、flatMap
flatMap 扁平化算子:把输入input类型转化为output类型输出,与map不同,flatmap输出多个output类型。
eg:String input = “hello,word”
output:Tuple2(“hello”,1)、Tuple2(“word”,1)
dataStream.flatMap(new FlatMapFunction<input,outpu>{xxx})
inputDataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String input, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = input.split(",");
for (String word : words) {
collector.collect(new Tuple2<>(word, 1));
}
}
});
三、filter
filter算子把input类型输入数据过滤出来 。为true留下来,false过滤掉。
eg:String input = “hello,world”
dataStream.filter(new FilterFunction{return boolean})
inputDataStream.filter(new FilterFunction<String>() {
@Override
public boolean filter(String input) throws Exception {
return input.contains("hello");
}
});
四、keyby
DataStream → KeyedStream:逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同 key 的元素,在内部以 hash 的形式实现的。
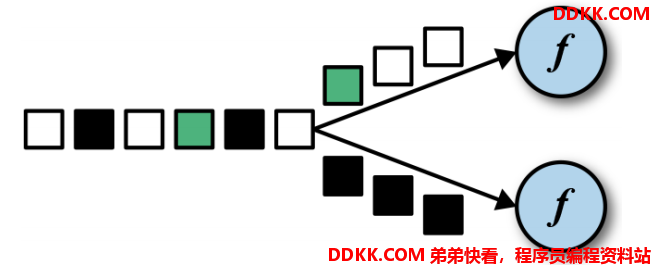
eg:dataStream.keyby(param)
param 可以是输入数据字段下标,默认从0开始,比如Tuple2(word,1),param=0,就是按照word分流。
param 可以是输入数据的字段名称,比如一个类Sensor有三个字段:id,timestamp,temperature。param=“id”,就是按照id进行分流。
还有其他KeySelector。后面结合滚动聚合算子进行案例。
五、滚动聚合算子(rolling Aggregation)
5.1、sum
案例:统计wordcount
SingleOutputStreamOperator<Tuple2<String, Integer>> wordDataStream = inputDataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String input, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = input.split(" ");
for (String word : words) {
collector.collect(new Tuple2<>(word, 1));
}
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> resultDataStream = wordDataStream.keyBy(0)
.sum(1);
5.2、max
选择每条流的最大值
案例:根据输入数据(比如 第一次输入 hello,9 、第二次输入 world,7,结果还是 hello,9)
inputDataStream.map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String input) throws Exception {
String[] fields = input.split(" ");
return new Tuple2(fields[0], Long.parseLong(fields[1]));
}
}).keyBy(0)
.max(1);
5.3、min
选择每条流的最小值
案例:根据输入数据(比如 第一次输入 hello,9 、第二次输入 world,7,结果是 hello,7)
inputDataStream.map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String input) throws Exception {
String[] fields = input.split(" ");
return new Tuple2(fields[0], Long.parseLong(fields[1]));
}
}).keyBy(0)
.min(1);
5.4、minby
针对keyedStream中的某个字段数据进行选择最小值
案例:根据每次传感器id传来的数据选择温度最小的
DataStreamSource<SensorReading> inputDataStream = env.addSource(new SourceFromCustom.CustomSource());
SingleOutputStreamOperator<SensorReading> resultDataStream = inputDataStream.keyBy("id")
.minBy("temperature");
5.5、maxby
原理同maxby
5.6、reduce
KeyedStream → DataStream:一个分组数据流的聚合操作,合并当前的元素和上次聚合的结果,产生一个新的值,返回的流中包含每一次聚合的结果,而不是只返回最后一次聚合的最终结果。
案例:根据传感器id传来的数据比较上一次时间戳的温度,选择最大温度的时间戳数据
import com.tan.flink.bean.SensorReading;
import com.tan.flink.source.SourceFromCustom;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Transform_keyed_Reduce {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<SensorReading> inputDataStream = env.addSource(new SourceFromCustom.CustomSource());
SingleOutputStreamOperator<SensorReading> resultDataStream = inputDataStream.keyBy("id")
.reduce(new CustomReduceFunction());
resultDataStream.print();
env.execute();
}
public static class CustomReduceFunction implements ReduceFunction<SensorReading> {
@Override
public SensorReading reduce(SensorReading sensorReading, SensorReading input) throws Exception {
String id = sensorReading.getId();
Long timestamp = input.getTimestamp();
double temperature = Math.max(sensorReading.getTemperature(), input.getTemperature());
return new SensorReading(id, timestamp, temperature);
}
}
}
六、split和select
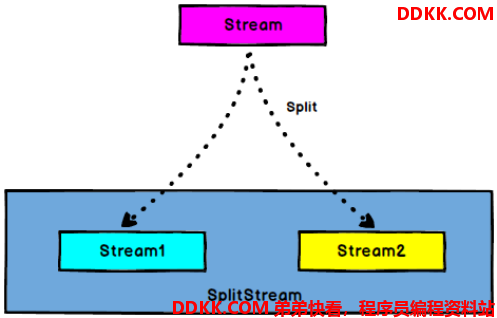
6.1、split
DataStream → SplitStream:根据某些特征把一个 DataStream 拆分成两个或者多个 DataStream。
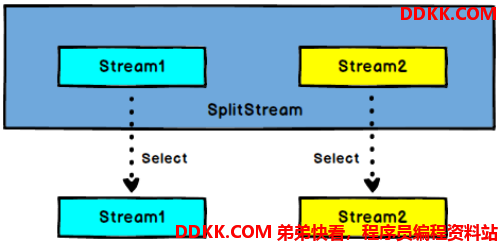
6.2、select
SplitStream→DataStream:从一个 SplitStream 中获取一个或者多个
DataStream。
6.3、案例
根据传感器的温度,以60度为标准,大于等于60度为high流,其他为low流
import com.tan.flink.bean.SensorReading;
import com.tan.flink.source.SourceFromCustom;
import org.apache.flink.shaded.guava18.com.google.common.collect.Lists;
import org.apache.flink.streaming.api.collector.selector.OutputSelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SplitStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Transform_Split_Select {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<SensorReading> inputDatStream = env.addSource(new SourceFromCustom.CustomSource());
SplitStream<SensorReading> splitStream = inputDatStream.split(new OutputSelector<SensorReading>() {
@Override
public Iterable<String> select(SensorReading sensorReading) {
Double temperature = sensorReading.getTemperature();
if (temperature >= 60) {
return Lists.newArrayList("high");
} else {
return Lists.newArrayList("low");
}
}
});
DataStream<SensorReading> high = splitStream.select("high");
DataStream<SensorReading> low = splitStream.select("low");
DataStream<SensorReading> all = splitStream.select("high", "low");
high.print("high").setParallelism(1);
low.print("low").setParallelism(1);
all.print("all").setParallelism(1);
env.execute();
}
}
七、connect和CoMap
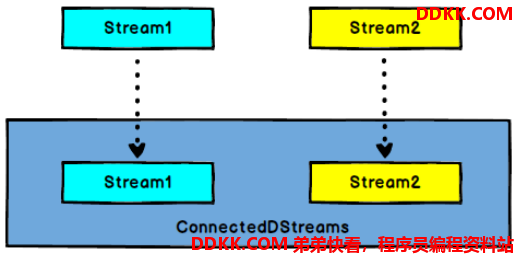
7.1、connect
DataStream,DataStream → ConnectedStreams:连接两个保持他们类型的数据流,两个数据流被 Connect 之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立。输入数据类型可以一样也可以不一样。
7.2、CoMap、CoFlatMap
ConnectedStreams → DataStream:作用于 ConnectedStreams 上,功能与 map和 flatMap 一样,对 ConnectedStreams 中的每一个 Stream 分别进行 map 和 flatMap处理。最终处理的结果可以一样也可以不一样。
7.3、案例
根据传感器传来的温度数据分为高温度和低温度两条流进行connect,进行CoMap或者CoFlatMap算子之后输出数据。
import com.tan.flink.bean.SensorReading;
import com.tan.flink.source.SourceFromCustom;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.shaded.guava18.com.google.common.collect.Lists;
import org.apache.flink.streaming.api.collector.selector.OutputSelector;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
public class Transform_Connect_CoMap {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<SensorReading> inputDatStream = env.addSource(new SourceFromCustom.CustomSource());
SplitStream<SensorReading> splitStream = inputDatStream.split(new OutputSelector<SensorReading>() {
@Override
public Iterable<String> select(SensorReading sensorReading) {
Double temperature = sensorReading.getTemperature();
if (temperature >= 60) {
return Lists.newArrayList("high");
} else {
return Lists.newArrayList("low");
}
}
});
DataStream<SensorReading> high = splitStream.select("high");
SingleOutputStreamOperator<Tuple2<String, Double>> highDataStream = high.map(new MapFunction<SensorReading, Tuple2<String, Double>>() {
@Override
public Tuple2<String, Double> map(SensorReading sensorReading) throws Exception {
return new Tuple2<>(sensorReading.getId(), sensorReading.getTemperature());
}
});
DataStream<SensorReading> lowDataStream = splitStream.select("low");
ConnectedStreams<Tuple2<String, Double>, SensorReading> connectDataStream = highDataStream.connect(lowDataStream);
SingleOutputStreamOperator<Object> resultDataStream = connectDataStream.map(new CoMapFunction<Tuple2<String, Double>, SensorReading, Object>() {
@Override
public Object map1(Tuple2<String, Double> input) throws Exception {
// 处理高温数据
return new Tuple3<>(input.f0, input.f1, "warnning");
}
@Override
public Object map2(SensorReading input) throws Exception {
// 处理正常温度数据
return new Tuple3<>(input.getId(), input.getTimestamp(), input.getTemperature());
}
});
resultDataStream.print();
env.execute();
}
}
八、Union
DataStream → DataStream:对两个或者两个以上的DataStream进行union操作,产生一个包含所有DataStream元素的新DataStream。注意:如果你将一个DataStream跟它自己做union操作,在新的DataStream中,你将看到每一个元素都出现两次。
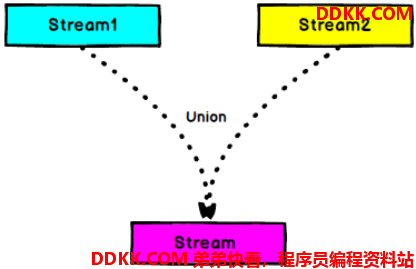
8.2、Connect 与 Union 区别:
Union 之前两个流的类型必须是一样,Connect 可以不一样,在之后的 coMap中可以再去调整成为一样的,也可以不一样的。
Connect 只能操作两个流,Union 可以操作多个。
8.1 案例
根据传感器传来的温度数据分为高温度和低温度两条流进行connect,进行union。
import com.tan.flink.bean.SensorReading;
import com.tan.flink.source.SourceFromCustom;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.shaded.guava18.com.google.common.collect.Lists;
import org.apache.flink.streaming.api.collector.selector.OutputSelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.SplitStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Transform_Union {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<SensorReading> inputDatStream = env.addSource(new SourceFromCustom.CustomSource());
SplitStream<SensorReading> splitStream = inputDatStream.split(new OutputSelector<SensorReading>() {
@Override
public Iterable<String> select(SensorReading sensorReading) {
Double temperature = sensorReading.getTemperature();
if (temperature >= 60) {
return Lists.newArrayList("high");
} else {
return Lists.newArrayList("low");
}
}
});
DataStream<SensorReading> high = splitStream.select("high");
DataStream<SensorReading> low = splitStream.select("low");
DataStream<SensorReading> unionDataStream = high.union(low);
SingleOutputStreamOperator<Tuple3<String, Long, Object>> resultDataStream = unionDataStream.map(new MapFunction<SensorReading, Tuple3<String, Long, Object>>() {
@Override
public Tuple3<String, Long, Object> map(SensorReading input) throws Exception {
if (input.getTemperature() >= 60) {
return new Tuple3<String, Long, Object>(input.getId(), input.getTimestamp(), "warnning");
} else {
return new Tuple3<String, Long, Object>(input.getId(), input.getTimestamp(), input.getTemperature());
}
}
});
resultDataStream.print();
env.execute();
}
}