1. 前言
从前年开始,就被公众号上Flink文章频繁的刷屏,看来是时候了解下Flink了。
Flink官网第一句话介绍是数据流上的有状态计算。
我第一眼看这句话感觉很拗口,什么是流上的计算?什么是有状态?
作为菜鸟,我觉的学习Flink最好方法是看官网并敲代码实践,不会的百度些博客学学。
2. 创建Flink项目
废话不多说,我们来创建一个Flink项目吧。关于“Flink是什么”,“Flink应用场景”,“Flink安装部署”,“Flink架构原理”等话题,我感觉网上好的博客很多了,我默认此时你至少了解过Flink并安装过Flink吧,不然怎么会搜到我这篇博客?
2.1 在cmd窗口创建
打开cmd命令窗口,输入如下命令
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.10.1 -DarchetypeCatalog=internal
如果你有强迫症,你看不惯一行命令这么长,你可以粘贴下面的。
我的是win10系统,命令以^换行,如果你是Linux系统,要以\换行。
mvn archetype:generate ^
-DarchetypeGroupId=org.apache.flink ^
-DarchetypeArtifactId=flink-quickstart-java ^
-DarchetypeVersion=1.10.1 ^
-DarchetypeCatalog=internal
执行中途,它会询问你输入groupId和artifactId,然后一路回车输入Y,项目就创建好了。
2.2 WordCount例子
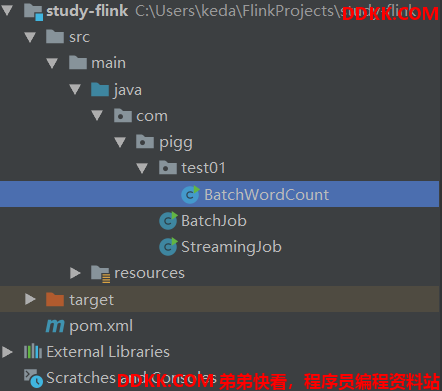
如果你项目创建成功,会有如下代码结构,然后再创建个BatchWordCount类,贴入下面Java代码。
package com.pigg.test01;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class BatchWordCount {
public static void main(String[] args) throws Exception {
//第1步:创建执行环境
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//第2步:创建数据源
DataSource<String> lines = env.fromElements("I love coding", "I love flink", "study flink");
//第3步:处理数据
// 3.1:将每一行按照空格切分,并组成(word, 1)
FlatMapOperator<String, Tuple2<String, Integer>> wordAndOne = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
collector.collect(Tuple2.of(word, 1));
}
}
});
// 3.2:按照第一个字段分组,并按照第二个字段求和
AggregateOperator<Tuple2<String, Integer>> result = wordAndOne.groupBy(0).sum(1);
//第4步:输出打印到控制台
result.print();
//第5步:触发执行job,如果是实时流计算这是要的,这里是批处理,也可以不加
env.execute("BatchWordCount");
}
}
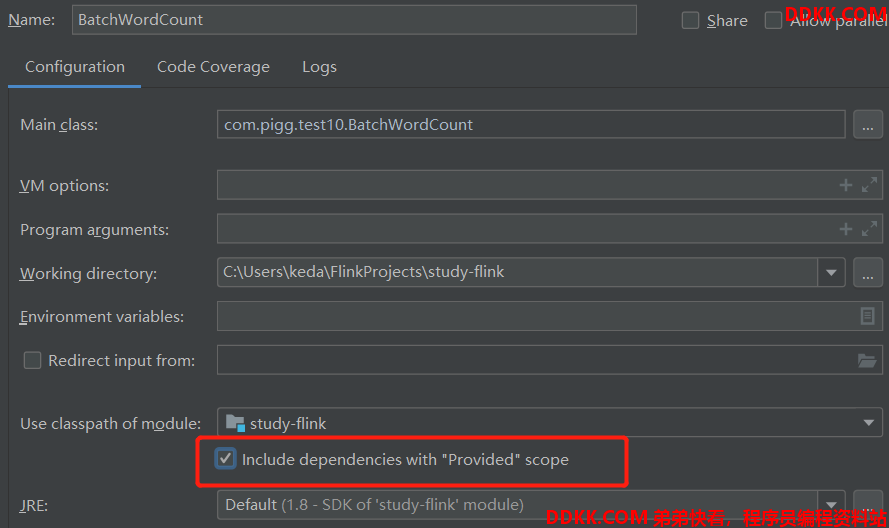
不要深究代码的意思,我们只是先了解下写一个Flink程序的代码结构。运行main方法时,如果报如下错误:
NoClassDefFoundError: org/apache/flink/api/common/functions/FlatMapFunction
你需要把如下选项勾上
执行结果为:
(flink,2)
(love,2)
(I,2)
(coding,1)
(study,1)
2.3 分析Flink程序代码结构
在上面程序中,我注释了5个步骤,Flink的Job程序也基本分5个步骤:
- 第1步:创建执行环境
- 第2步:创建数据源
- 第3步:处理数据流
- 第4步:输出结果到指定位置
- 第5步:触发执行Job
下面我们来逐步学习这5个步骤,其中第3步最为关键,是本博客的重点,更是平时开发的核心。
3. 第1步:创建执行环境
Flink程序最开始都是要创建执行环境,它会自动根据不同的运行场景创建对应的执行环境。
- 如果你在IDEA里运行main方法,Flink创建的是本地执行环境
- 如果你把程序打成jar包,提交到Flink集群上执行,Flink创建的是集群执行环境
创建执行环境很简单,就一句话:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//流数据源
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
4. 第2步:创建数据源
创建数据源是指定义我们的Flink程序从哪里获取数据。
如果是实时计算,一般工作中我们都是从Kafka中获取数据。
如果是跑批处理,一般是从txt,csv,hdfs上读取数据。
还记得一开始说的Flink自我介绍数据流上的有状态计算这句话吗?
我认为很有必要先理解下什么是流?
4.1 什么是流?
对Flink而言,不管是不停采集新增的事件还是已经固定大小的数据集合,它们都是流数据,只不过根据它们是否有界限,分为无界流和有界流。
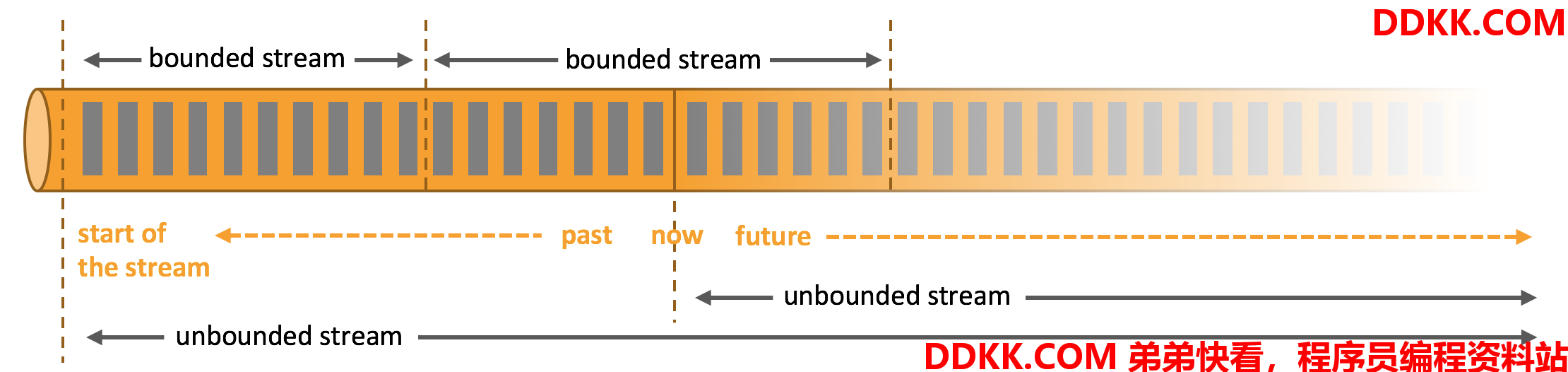
4.1.1 无界流
例如温度传感器,它把采集的温度数据不停的推送到后台给Flink计算,如果触发某个规则,则报警。
无界流有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。
4.1.2 有界流
例如上1个月每天A股指数收盘的数据集合,这种有界的数据可以称为有界流。
有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。
4.2 从指定的数据集合创建流(一般测试时用)
一般在测试自己代码时,可以这样用,以便快速验证自己写的转换算子是否对。
传入一组数字
DataSource<Integer> dataSource1 = env.fromElements(1, 2, 3, 4, 5);
传入一组字符串
DataSource<String> dataSource2 = env.fromElements("I love coding", "I love flink");
传入一个List集合
DataSource<String> dataSource3 = env.fromCollection(Arrays.asList("a", "b", "c"));
4.3 从文件里读取数据
widows上读取本地文件
DataSource<String> dataSource4 = env.readTextFile("D:\\FlinkTest.txt");
Linux上读取本地文件
DataSource<String> localLines = env.readTextFile("file:///usr/local/textfile");
从hdfs读取文件,需要写上hdfs的nameService(高可用集群),或者namenode ip及端口号
DataSource<String> hdfsLines = env.readTextFile("hdfs://nnHost:nnPort/path/textfile");
4.4 从WebSocket读取数据
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
第一个参数是hostname,第二个参数是port
DataStreamSource<String> lines = env.socketTextStream("com.pigg", 8888);
在对应机器上输入如下命令,flink程序就可以接收数据
nc -lk 8888
4.5 从Kafka读取数据
关于Kafka的安装和配置不在本文讨论范围内,网上博客很多,或参考我之前的博客Linux搭建kafka集群并测试
4.5.1 引入jar
Flink和Kafka结合的非常好,Flink官方也提供了Kafka的连接器。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.2.0</version>
</dependency>
4.5.2 编写Kafka数据源
- 一般开发用SpringBoot,Kafka的配置也放在yml文件里,这里作为演示写死了配置
- 这里仅抛砖引玉,网上Flink整合Kafka完整的博客很多,可以自行搜索学习
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
//指定kafka的broker地址
properties.setProperty("bootstrap.servers", "com.pigg:9092");
//指定组ID
properties.setProperty("group.id", "test");
properties.setProperty("auto.offset.reset", "earliest");
//定义kafka消费者
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<>(
"myTopicName",
new SimpleStringSchema(),
properties
);
DataStreamSource<String> lines = env.addSource(kafkaSource)
创建Kafka主题注意点:
Kafka在远程机器上,创建主题不要写localhost,这里用hostname: com.pigg
否则你本机的Flink任务读取不到localhost的Kafka消息,而导致错误
1.创建主题
kafka-topics.sh --create --zookeeper com.pigg:2181 --replication-factor 1 --partitions 1 --topic myTopicName
2.查看主题
kafka-topics.sh --list --zookeeper com.pigg:2181
3.创建生产者
kafka-console-producer.sh --broker-list com.pigg:9092 --topic myTopicName
5. 第3步:处理数据流
恭喜贺喜,终于来到第3步了,说实话第3步的内容真的太大太难,我也不知道如何讲起,毕竟我刚学Flink不到7天,还都是晚上迷迷糊糊看的。所以真的只能厚着脸皮写了,我觉得按照下面顺序写,写的不好,莫怪。
- 什么是DataStream
- 什么是元组
- 基本转换算子(Map,FlatMap,Filter,groupBy,keyBy,Reduce)
- 时间语义
- 窗口和WaterMark
- 聚合算子 (max,min,sum)
- 分流算子

5.1 什么是DataStream
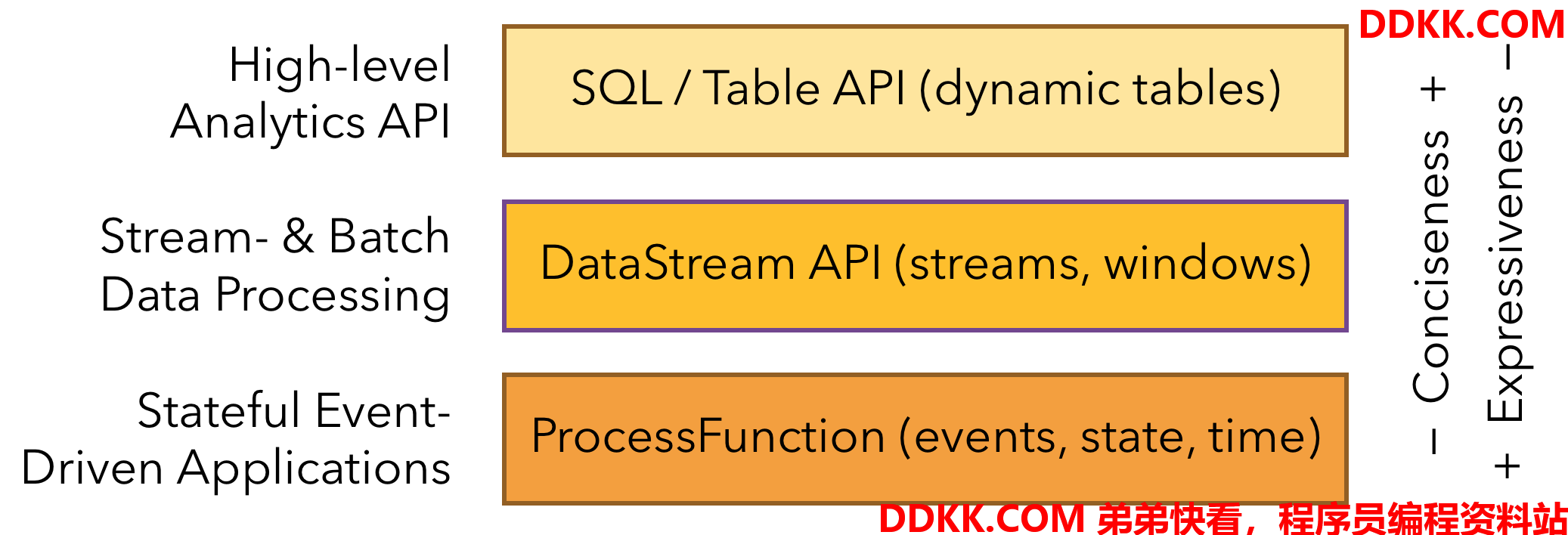
Flink提供了三层API,每层在简洁性和表达性之间进行了不同的权衡,DataStream API为许多通用的流处理操作提供原语,比如window。DataStream API适用于Java和Scala,它基于函数实现,比如map()、reduce()等。
往上翻看读取Kafka的代码,这边返回的类型是DataStreamSource
DataStreamSource<String> lines = env.addSource(kafkaSource)
查看DataStreamSource类图
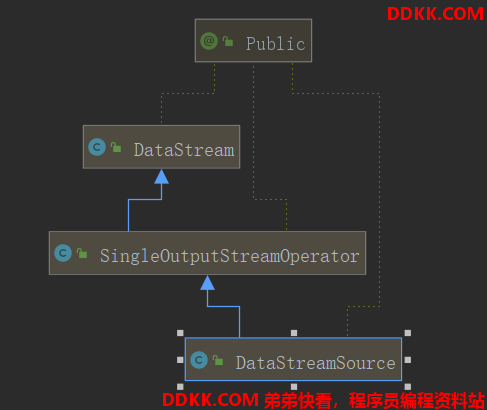
说明上面代码也可以写成下面这样,对流数据lines的操作,就是调用DataStream API操作它。
DataStream<String> lines = env.addSource(kafkaSource)
有时间得看看DataStream.java这个类的代码。map,flatMap,filter等算子的定义都是在这个类里。
5.2 什么是元组(Tuple)
写Java的可能不知道元组,但是玩过Python的小朋友应该都知道。
元组与ArrayList类似,可以放一组数值,但是不同数据的类型可以不同。
从上面的WordCount代码里看,用到了Tuple2<String, Integer>,这表示定义一个元组,它有2个值,
第一个值是String类型,第二个值是Integer类型。
查看Flink里Tuple2类,可以发现Flink定义了Tuple0一直到Tuple25。
5.3 基本转换算子
5.3.1 map
- 转换类型:DataStream → DataStream
- 说明:读取一个元素并生成一个新的元素,例如
- 举例:
| 输入 | map转换 | 输出 |
|---|---|---|
| 1,2,3 | 乘以2 | 2,4,6 |
| a,b,b | 添加一个元素1,组成Tuple2<String, Integer> | (a,1),(b,1),(b,1) |
下面举例a,b,b -> (a,1),(b,1),(b,1)
public class DataSourceTest {
public static void main(String[] args) throws Exception {
//第1步:创建执行环境
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//第2步:创建数据源
DataSource<String> dataSource3 = env.fromCollection(Arrays.asList("a", "b", "b"));
//第3步:执行转换算子
MapOperator<String, Tuple2<String, Integer>> maped = dataSource3.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
return new Tuple2<>(s, 1);
}
});
//第4步:输出打印到控制台
maped.print();
//第5步:执行job,如果是实时流计算这是要的,这里是批处理,也可以不加
env.execute("BatchWordCount");
}
}
5.3.2 flatMap
写Java8多的小朋友估计对flatMap不陌生,暂时叫它扁平map吧。
- 转换类型:DataStream → DataStream
- 说明:多组数据->生成多个流->合并成一个流
- 举例:
| 输入 | flatMap转换 | 输出 |
|---|---|---|
| “I love coding”, “I love flink” | 切分后,组成Tuple2<String, Integer> | (flink,1)2个(love,1)2个(I,1)(coding,1) |
DataSource<String> lines = env.fromElements("I love coding", "I love flink");
//将每一行按照空格切分,并组成(word, 1)
FlatMapOperator<String, Tuple2<String, Integer>> wordAndOne = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
collector.collect(Tuple2.of(word, 1));
}
}
});
5.3.3 filter
- 转换类型:DataStream → DataStream
- 说明:该算子将按照条件对输入数据集进行筛选操作,将符合条件的数据集输出
- 举例:
| 输入 | flatMap转换 | 输出 |
|---|---|---|
| 1, 2, 3, 4, 5, 6 | 找到奇数 | 1,3,5 |
DataStreamSource<Integer> nums = env.fromElements(1, 2, 3, 4, 5, 6);
SingleOutputStreamOperator<Long> filterd = nums.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return value %2 != 0;
}
}).setParallelism(1);
filterd.print();
5.3.4 keyBy
- 转换类型:DataStream → KeyedStream
- 说明:具有相同key的所有记录会分配给到同一分区,类似SQL的group by,在内部,keyBy()是使用hash分区实现
- 举例:
如果是DataSet用groupBy,是DataStream用keyBy
接着上面4.5.2编写Kafka节,把从Kafka读取的数据进行WordCount
DataStreamSource<String> lines = env.addSource(kafkaSource);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne =
lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = line.split(" ");
for (String word : words){
Tuple2<String, Integer> tp = Tuple2.of(word, 1);
out.collect(tp);
}
}
});
//注意下面的.keyBy(0).sum(1),说按照第一值分组,再把同组里第二个值求和
//聚合函数(min,max,sum)都是加在keyBy(DataSet时是groupBy)后面
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = wordAndOne.keyBy(0).sum(1);
上面例子是在元组类型上keyBy,所以传的是数字,如果是POJO类型,可以传入字段名
dataStream.keyBy("someKey")
5.3.5 reduce
- 转换类型:KeyedStream→DataStream
- 说明:在分区的数据流上调用reduce函数:将当前元素与最后一个reduce的值合并生成新值。
reduce函数是将KeyedStream转换为DataStream,也就是reduce调用前必须进行分区,即得先调用keyBy()函数 - 举例:
keyedStream.reduce(new ReduceFunction<Integer>() {
@Override
public Integer reduce(Integer value1, Integer value2)
throws Exception {
return value1 + value2;
}
});
后续
写到这,发现把时间语义,窗口,聚合,分流也写在这一博客,会显的博客太长了,而且质量会更低(我承认我基本是把IDEA的代码贴过来)。而且时间语义和窗口特别重要的知识,我还是放到下一篇博客吧(该贴的代码还是得贴)。
Flink 实战(二) DataStream聚合 keyBy sum min和minBy区别