一、前言
算子会将一个或多个DataStream转换成一个新的DataStream。
在工作中使用最多的也就这些DataStream转换算子,学好这些算子是入门Flink的必要。
好在Flink的某些算子和Java8的lambda函数很像,这便于理解。下面我会先介绍Java的语法,再介绍Flink的语法,由浅入深。
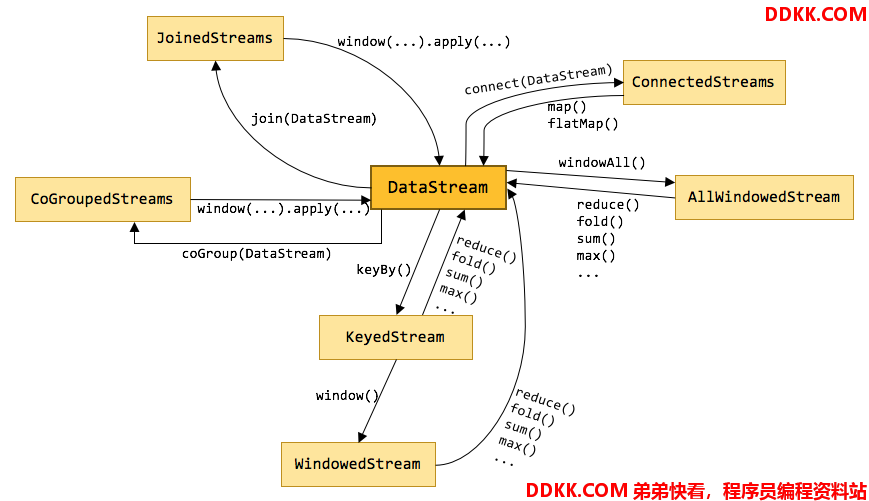
下面可以从图中看到DataStream和不同Stream之间,经过不同算子可以相互转换。
二、Map
2.1 Java Lambda的Map
Map对于Stream中包含的元素使用给定的转换函数进行转换操作,新生成的Stream只包含转换生成的元素。
简单来说,Map是映射的意思,可将T类型输入,转成R类型的输出。
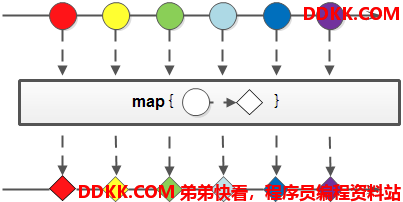
如下示例是获取WordCount对象集合中的word字段集合。List转换成List代码如下:
public class MapJavaDemo {
public static void main(String[] args) {
List<WordCount> wordCountList = new ArrayList<>();
wordCountList.add(new WordCount("Flink", 3));
wordCountList.add(new WordCount("Elasticsearch", 1));
//将每个字段从WordCount类型转成String类型,生成List<String>
List<String> words = wordCountList.stream()
.map(WordCount::getWord)
.collect(Collectors.toList());
System.out.println(words);
}
}
运行结果如下:
[Flink, Elasticsearch]
上面.map(WordCount::getWord)也可以写成.map(a -> a.getWord()),WordCount::getWord是一种简写方法罢了,a -> a.getWord()表达的更加直白。
2.2 Flink的Map
转换类型:DataStream → DataStream
- 说明:读取一个元素并生成一个新的元素,例如
- 举例:
| 输入 | map转换 | 输出 |
|---|---|---|
| 1,2,3 | 乘以2 | 2,4,6 |
| a,b,b | 添加一个元素1,组成Tuple2<String, Integer> | (a,1),(b,1),(b,1) |
下面代码举例
- 第一步:获取WordCount对象中word集合
- 第二步:将每个count * 2
public class MapFlinkDemo {
public static void main(String[] args) throws Exception {
//创建环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
List<WordCount> wordCountList = new ArrayList<>();
wordCountList.add(new WordCount("Flink", 3));
wordCountList.add(new WordCount("Elasticsearch", 1));
//设置数据源
DataSource<WordCount> dataSource = env.fromCollection(wordCountList);
//转换1:获取WordCount对象中word集合
MapOperator<WordCount, String> words = dataSource.map(a -> a.getWord());
//输出结果1
words.print();
//转换2:将每个count * 2
MapOperator<WordCount, Object> doubleCount = dataSource.map(a -> {
a.setCount(a.getCount() * 2);
return a;
});
//输出结果2
doubleCount.print();
}
}
运行结果如下:
Flink
Elasticsearch
WordCount{
word='Flink', count=6}
WordCount{
word='Elasticsearch', count=2}
三、FlatMap
FlatMap也称扁平化map,它可把多个集合放到一个集合里。
举例说明:
- WordCount程序中是把输入值,按照空格(" ")切分。
- “i love you"和"you love me” -> [“i”,“love”,“you”]和[“you”,“love”,“me”]
- Arrays.stream()将上面2个数组生成的2个Stream流,
- flatMap()把2个Stream流合成1个Stream
3.1 Java Lambda的FlatMap
public class FlatMapJavaDemo {
public static void main(String[] args) {
List<String> wordCountList = new ArrayList<>();
wordCountList.add("i love you");
wordCountList.add("you love me");
Map<String, Long> collect = wordCountList.stream()
//这一行会生成2个String[]:["i","love","you"]和["you","love","me"]
.map(a -> a.split(" "))
//Arrays.stream()将上面2个数组生成的2个Stream<String>流,
//flatMap()把2个Stream<String>流合成1个Stream<String>
.flatMap(Arrays::stream)
//在1个Stream<String>上面根据单词聚合统计
.collect(Collectors.groupingBy(w -> w, Collectors.counting()));
System.out.println(collect);
}
}
运行结果如下:
{
love=2, me=1, i=1, you=2}
3.2 Flink的FlatMap
- 转换类型:DataStream → DataStream
- 说明:多组数据->生成多个流->合并成一个流
- 举例:
| 输入 | flatMap转换 | 输出 |
|---|---|---|
| “I love coding”, “I love flink” | 切分后,组成Tuple2<String, Integer> | (flink,1)2个(love,1)2个(I,1)(coding,1) |
public class FlatMapFlinkDemo {
public static void main(String[] args) throws Exception {
//创建环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
List<String> wordCountList = new ArrayList<>();
wordCountList.add("i love you");
wordCountList.add("you love me");
//设置数据源
DataSource<String> dataSource = env.fromCollection(wordCountList);
//数据转换
FlatMapOperator<String, String> wordStream = dataSource.flatMap(
(FlatMapFunction<String, String>) (in, out) -> {
Arrays.stream(in.split(" ")).forEach(out::collect);
}
).returns(Types.STRING);
wordStream.print();
}
}
四、Filter
4.1 Java Lambda的Filter
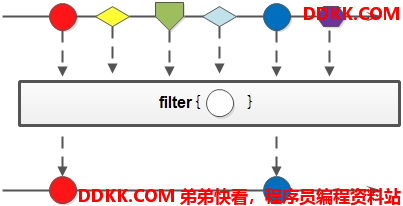
这里的filter方法接收的是Predicate<? super T> predicate,这个返回boolean类型。
public class FilterJavaDemo {
public static void main(String[] args) {
List<WordCount> wordCountList = new ArrayList<>();
wordCountList.add(new WordCount("Flink", 3));
wordCountList.add(new WordCount("Elasticsearch", 1));
List<WordCount> collect = wordCountList.stream().filter(a -> a.getCount() > 1).collect(Collectors.toList());
System.out.println(collect);
}
}
[WordCount{word='Flink', count=3}]
4.2 Flink的Filter
- 转换类型:DataStream → DataStream
- 说明:该算子将按照条件对输入数据集进行筛选操作,将符合条件的数据集输出
- 举例:
| 输入 | flatMap转换 | 输出 |
|---|---|---|
| 1, 2, 3, 4, 5, 6 | 找到奇数 | 1,3,5 |
public class FilterFlinkDemo {
public static void main(String[] args) throws Exception {
//创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
List<WordCount> wordCountList = new ArrayList<>();
wordCountList.add(new WordCount("Flink", 3));
wordCountList.add(new WordCount("Elasticsearch", 1));
DataSource<WordCount> source = env.fromCollection(wordCountList);
FilterOperator<WordCount> filter = source.filter(a -> a.getCount() > 1);
filter.print();
}
}
运行结果如下:
WordCount{word='Flink', count=3}
五、KeyBy
在Flink中KeyBy就是分组,如果是DataSet用groupBy,是DataStream用keyBy。
5.1 Java lambda的groupingBy
先按第一个字段分组,再按第二个字段求和
public class GroupByJavaDemo {
public static void main(String[] args) {
List<WordCount> wordCountList = new ArrayList<>();
wordCountList.add(new WordCount("Flink", 3));
wordCountList.add(new WordCount("Flink", 2));
wordCountList.add(new WordCount("Elasticsearch", 1));
wordCountList.add(new WordCount("Elasticsearch", 5));
//先按第一个字段分组,再按第二个字段求和
Map<String, Integer> groupByThenSum = wordCountList.stream()
.collect(
Collectors.groupingBy(
WordCount::getWord,
Collectors.summingInt(WordCount::getCount)
)
);
System.out.println(groupByThenSum);
}
}
{Elasticsearch=6, Flink=5}
5.2 Flink的KeyBy
- 转换类型:DataStream → KeyedStream
- 说明:具有相同key的所有记录会分配给到同一分区,类似SQL的group by,在内部,keyBy()是使用hash分区实现
- 如果是元祖,keyBy()里是下标,如keyBy(0), keyBy(0,1)
- 如果是POJO,keyBy()里是字段名,如keyBy(“word”),如果根据多个字段分组,keyBy(“field1”, “field2”)
- 举例:WordCount程序
public class StreamWordCountLambdaBetter {
public static void main(String[] args) throws Exception {
//创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//创建数据源
DataStreamSource<String> lines = env.socketTextStream(BaseConstant.URL, BaseConstant.PORT);
//将一行数据,按照空格分隔,将每个字符转成Tuple2.of(s, 1)
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.flatMap(
(String line, Collector<Tuple2<String, Integer>> out) -> {
Arrays.stream(line.split(" ")).forEach(thisWord -> {
out.collect(Tuple2.of(thisWord, 1));
});
}
).returns(Types.TUPLE(Types.STRING, Types.INT));
//统计操作
SingleOutputStreamOperator<Tuple2<String, Integer>> sumResult = wordAndOne
.keyBy(value -> value.f0)
.sum(1);
//sink
sumResult.print();
//执行
env.execute("StreamWordCountLambdaBetter");
}
}
六、Aggregations
6.1 Java Lambda的聚合函数
Java8中聚合函数非常简单,很容易理解和上手。
long count = pigs.stream().filter(a -> a.getAge() > 5).count();
System.out.println("age > 5的人数 = " + count);
//limit,取前几个
System.out.println("top2");
Stream<Pig> top2Pigs = pigs.stream().sorted(comparing(Pig::getAge)).limit(2);
top2Pigs.forEach(System.out::println);
int sumAge = pigs.stream().mapToInt(Pig::getAge).sum();
int maxAge = pigs.stream().mapToInt(Pig::getAge).max().getAsInt();
int minAge = pigs.stream().mapToInt(Pig::getAge).min().getAsInt();
double avgAge = pigs.stream().mapToInt(Pig::getAge).average().getAsDouble();
System.out.println("sumAge = " + sumAge);
System.out.println("maxAge = " + maxAge);
System.out.println("minAge = " + minAge);
System.out.println("avgAge = " + avgAge);
Optional<Pig> pigMaxAgeOptional = pigs.stream().collect(Collectors.maxBy(comparing(Pig::getAge)));
if (pigMaxAgeOptional.isPresent()){
System.out.println("maxAge = " + pigMaxAgeOptional.get().getAge());
}
6.2 Flink中的Aggregations
Flink中聚合有如下
其中要注意:
- min根据指定的字段取最小,它只返回最小的那个字段,而不是整个数据元素,对于其他的字段取了第一次取的值,不能保证每个字段的数值正确。
- minBy根据指定字段取最小,返回的是整个元素。
keyedStream.sum(0);
keyedStream.sum(“key”);
keyedStream.min(0);
keyedStream.min(“key”);
keyedStream.max(0);
keyedStream.max(“key”);
keyedStream.minBy(0);
keyedStream.minBy(“key”);
keyedStream.maxBy(0);
keyedStream.maxBy(“key”);
public class StreamMinTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
List data = new ArrayList<Tuple3<String, String, Integer>>();
data.add(new Tuple3<>("男", "老王", 80));
data.add(new Tuple3<>("男", "小王", 25));
data.add(new Tuple3<>("男", "老李", 85));
data.add(new Tuple3<>("男", "小李", 20));
DataStreamSource peoples = env.fromCollection(data);
//求年龄最小的人
SingleOutputStreamOperator minResult = peoples.keyBy(0).min(2);
minResult.print();
env.execute("StreamMinTest");
}
}
返回结果如下:
1> (男,老王,80)
1> (男,老王,25)
1> (男,老王,25)#年龄算对了,但是别的字段还是第一个老王
1> (男,老王,20)#年龄最小的居然还是第一个老王?
七、总结
本篇博客只是总结了部分Java8和Flink的算子,他们在Java和Flink上有共性,所以拿来一起讲,
这个是网上别的Flink博客所没有的。
感觉学习还是温故而知新,不能停下学习的脚步,也得时不时的回顾以前的知识,才能有新的收获。
下一篇博客Flink 实战(五) DataStream 常用算子(下)得讲讲Transformations 常用算子中的Reduce、Fold、Union、Connect、Split & Select。