第一节 Horizontal Pod Autoscaler(HPA)
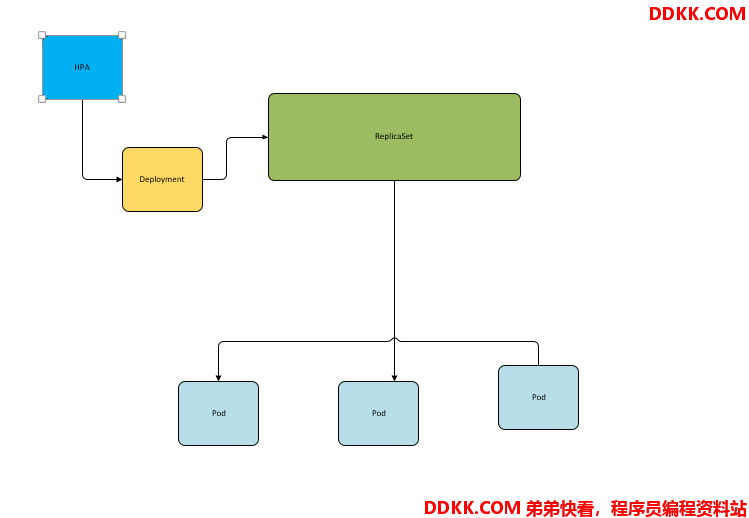
在前面的介绍中,我们可以手动执行kubectl scale命令实现pod扩容,但是这明显不符合kubernetes的定位目标-自动化、智能化。kubernetes期望可以通过监测Pod的使用情况,实现pod数量的自动化调整,于是就产生了HPA这种控制器。
HPA可以获取每个pod利用率,然后和HPA中定义的指标进行对比,同时计算出需要伸缩的具体值,最后实现pod的数量的调整。其实HPA与之前的Deployment一样,也属于一种kubernetes资源对象,它通过追踪分析目标pod的负载变化情况,来确定是否针对性地调整目标pod的副本数。
第二节 安装metrics-server
Github:https://github.com/kubernetes-sigs/metrics-server
注意版本需要对k8s有对应关系

这里的k8s版本是1.17.4,所以选择了v0.3.6
metrics-server可以用来收集集群中的资源使用情况
1、 安装git,下载metrics-server;
#安装git
yum -y install git
#获取metrics-server 注意使用的版本(国内失败的可能性较大,可能需要多次尝试)
git clone -b v0.3.6 https://github.com/kubernetes-incubator/metrics-server
1、 修改deployment,注意修改的是镜像和初始化参数;
cd /root/metrics-server/deploy/1.8+/
vim metrics-server-deployment.yaml
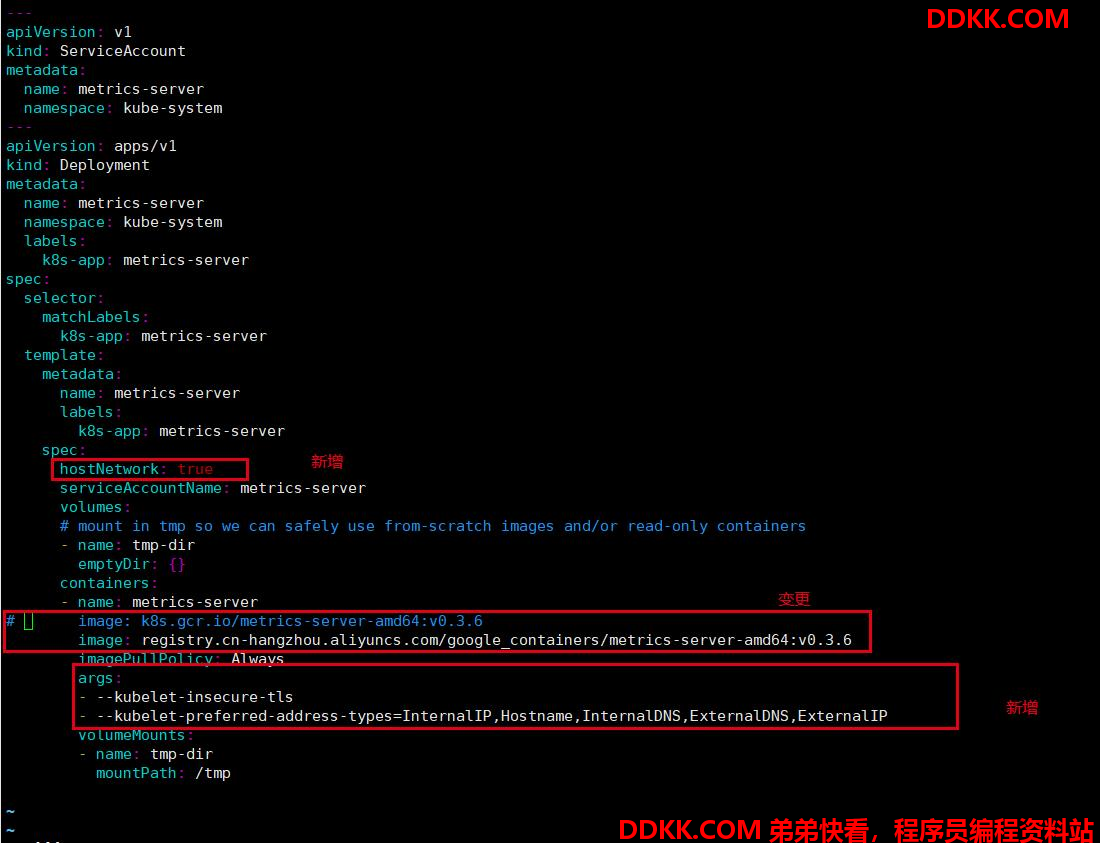
metrics-server-deployment.yaml 资源清单(供参考)
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: metrics-server
namespace: kube-system
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: metrics-server
namespace: kube-system
labels:
k8s-app: metrics-server
spec:
selector:
matchLabels:
k8s-app: metrics-server
template:
metadata:
name: metrics-server
labels:
k8s-app: metrics-server
spec:
hostNetwork: true
serviceAccountName: metrics-server
volumes:
mount in tmp so we can safely use from-scratch images and/or read-only containers
- name: tmp-dir
emptyDir: {
}
containers:
- name: metrics-server
# image: k8s.gcr.io/metrics-server-amd64:v0.3.6
image: registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server-amd64:v0.3.6
imagePullPolicy: Always
args:
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP
volumeMounts:
- name: tmp-dir
mountPath: /tmp
1、 以文件夹的形式部署;
kubectl apply -f ./
4、 查看(如果部署成功了,那么它会在kube-system下面生成一个pod,名称前缀为metrics-server);
kubectl get pods -n kube-system
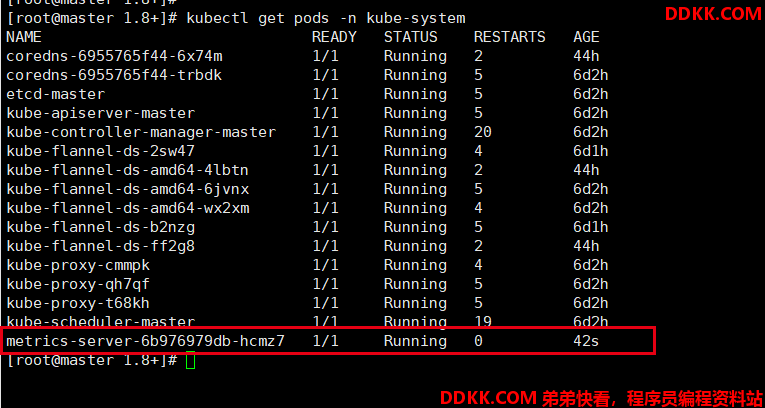
5、 查看资源,可以看到node和pod的资源使用情况;
资源采集需要时间,如果未查到数据,请稍等再试
[root@master 1.8+]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master 199m 9% 1095Mi 63%
node1 69m 3% 338Mi 38%
node2 69m 3% 334Mi 38%
[root@master 1.8+]# kubectl top pod -n kube-system
NAME CPU(cores) MEMORY(bytes)
coredns-6955765f44-6x74m 4m 18Mi
coredns-6955765f44-trbdk 4m 15Mi
etcd-master 27m 61Mi
kube-apiserver-master 60m 330Mi
kube-controller-manager-master 28m 67Mi
kube-flannel-ds-2sw47 4m 31Mi
kube-flannel-ds-amd64-4lbtn 4m 9Mi
kube-flannel-ds-amd64-6jvnx 3m 19Mi
kube-flannel-ds-amd64-wx2xm 3m 15Mi
kube-flannel-ds-b2nzg 3m 22Mi
kube-flannel-ds-ff2g8 4m 31Mi
kube-proxy-cmmpk 2m 19Mi
kube-proxy-qh7qf 1m 25Mi
kube-proxy-t68kh 1m 14Mi
kube-scheduler-master 5m 35Mi
metrics-server-6b976979db-hcmz7 2m 11Mi
[root@master 1.8+]#
第三节 准备deployment和service
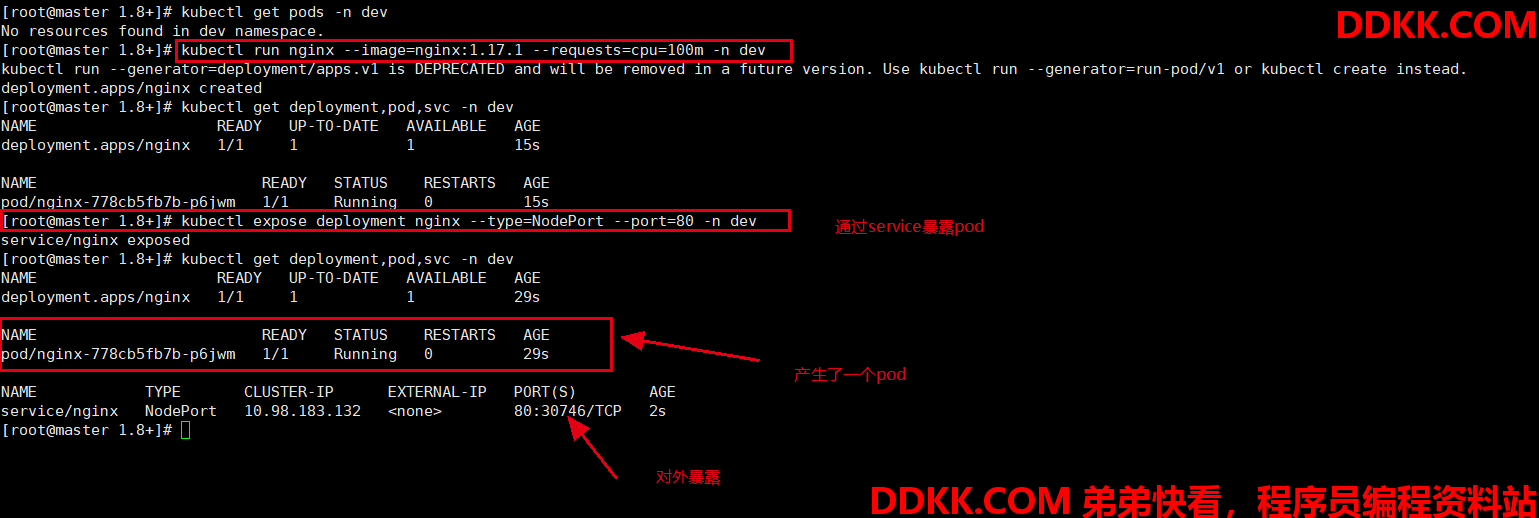
1、 创建deployment;
#创建deployment,通过deployment创建pod
kubectl run nginx --image=nginx:1.17.1 --requests=cpu=100m -n dev
#创建service,通过service将服务暴露出去
kubectl expose deployment nginx --type=NodePort --port=80 -n dev
1、 查看;
kubectl get deployment,pod,svc -n dev
第四节 部署HPA
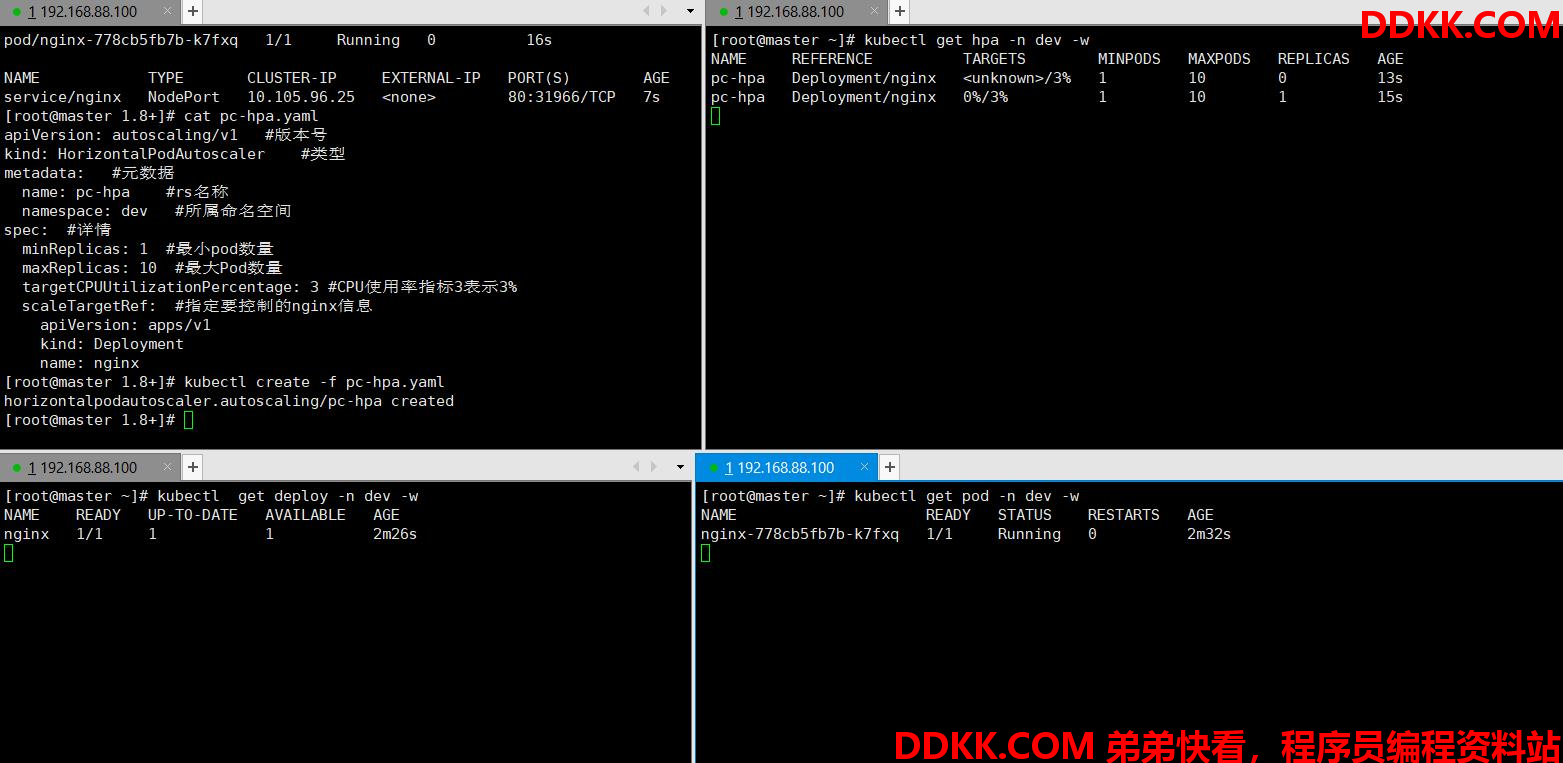
创建pc-hpa.yaml
apiVersion: autoscaling/v1 版本号
kind: HorizontalPodAutoscaler 类型
metadata: 元数据
name: pc-hpa rs名称
namespace: dev 所属命名空间
spec: 详情
minReplicas: 1 最小pod数量
maxReplicas: 10 最大Pod数量
targetCPUUtilizationPercentage: 3CPU使用率指标3表示3%
scaleTargetRef: 指定要控制的nginx信息
apiVersion: apps/v1
kind: Deployment
name: nginx
#创建hpa
[root@master 1.8+]# kubectl create -f pc-hpa.yaml
horizontalpodautoscaler.autoscaling/pc-hpa created
#查看hpa
[root@master 1.8+]# kubectl get hpa -n dev
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
pc-hpa Deployment/nginx 0%/3% 1 10 1 64s
[root@master 1.8+]#
使用压力测试工具,向nginx增加压力,访问http://192.168.88.100:30746(前面service暴露的端口)
postman,jmeter,apifox等均可进行压力测试。如何操作,请自行查阅。

查看集群信息
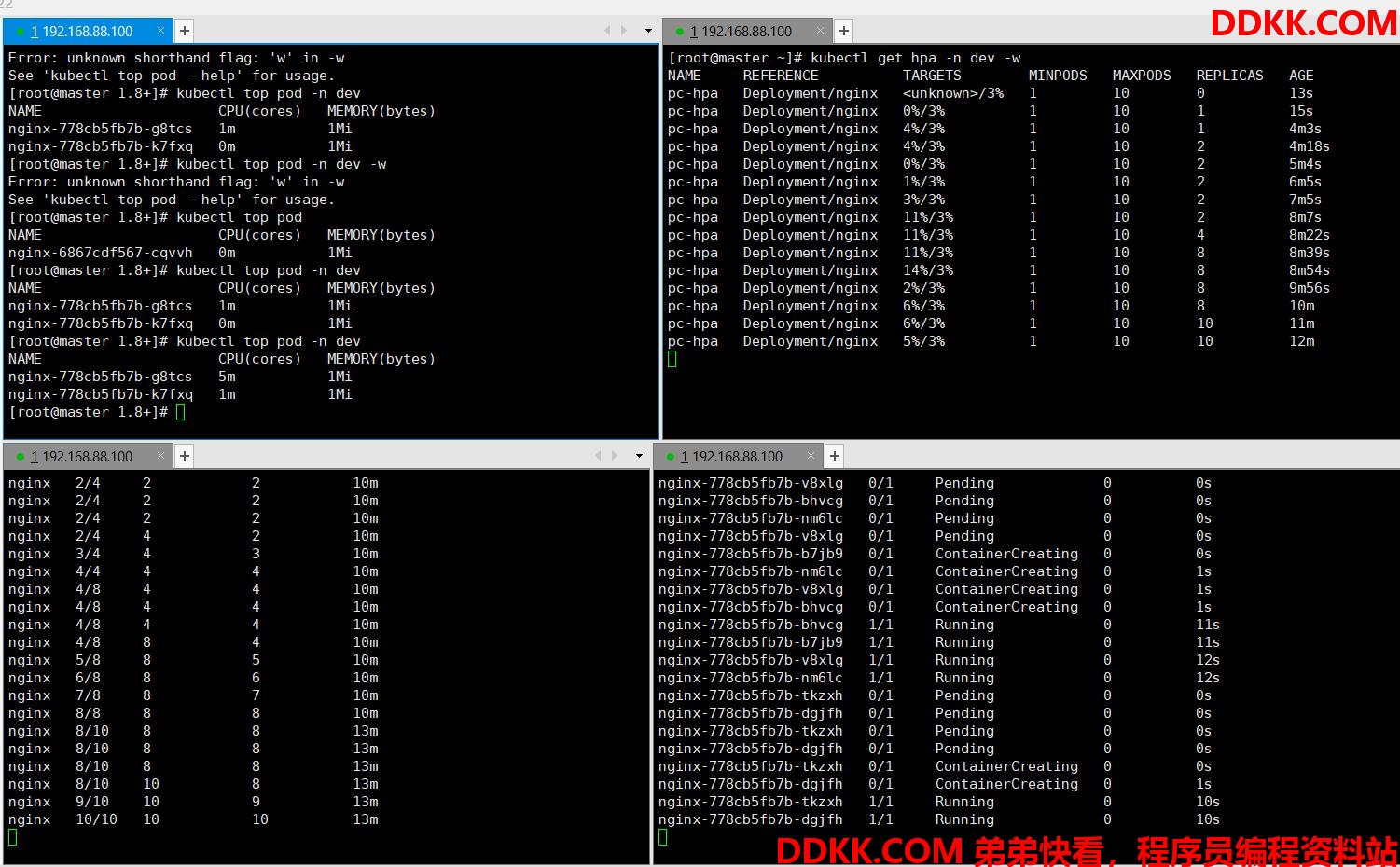
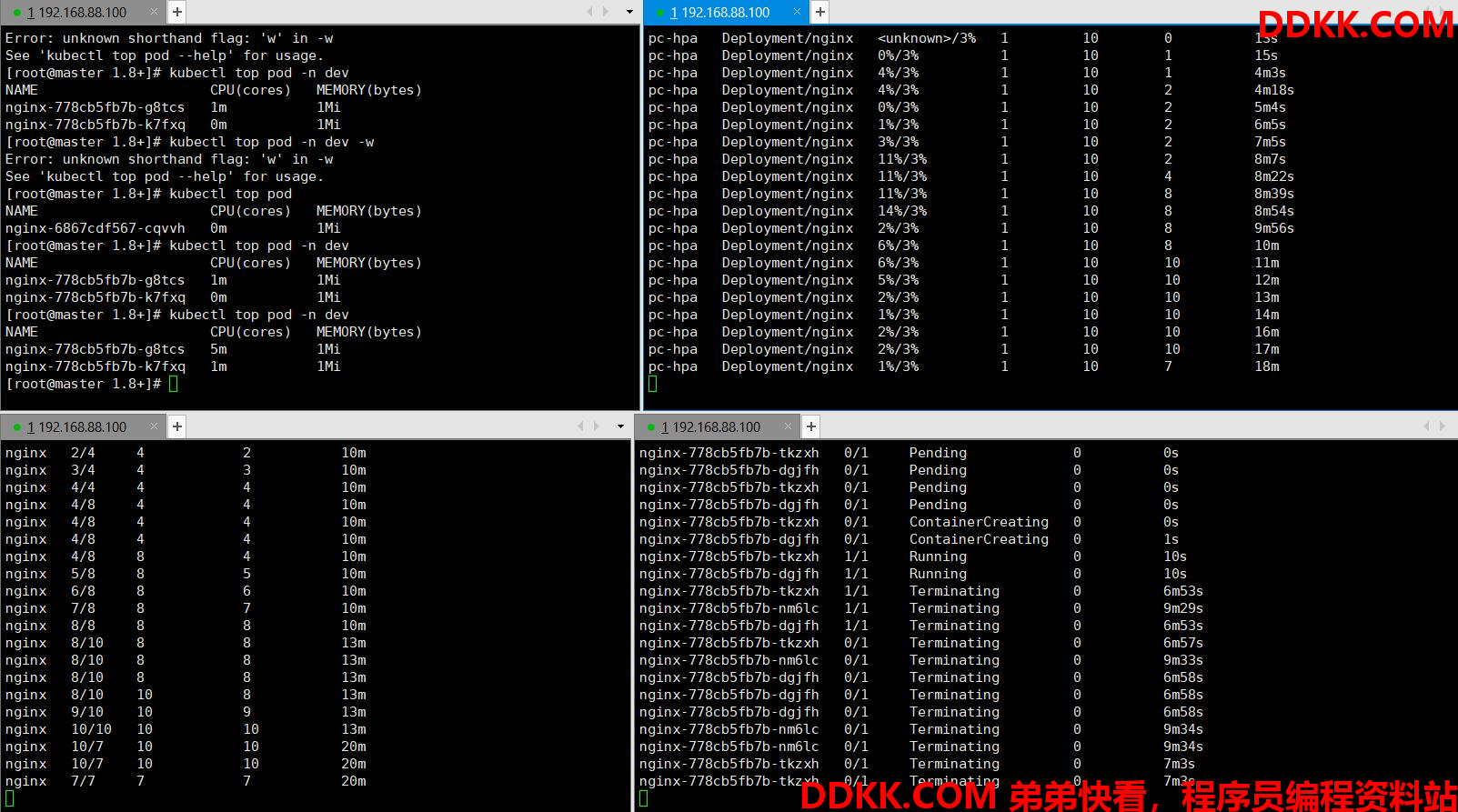
可以发现pod的数量在增加,最大到10,而当撤销压力测试后,等待一些时间pod数量又在减少了,慢慢减少到1。
pod的增减需要等待一些时间才能看到