Redis RDB持久化机制
1. RDB的介绍
因为Redis是内存数据库,因此将数据存储在内存中,如果一旦服务器进程退出,服务器中的数据库状态就会消失不见,为了解决这个问题,Redis提供了两种持久化的机制:RDB和AOF。本篇主要剖析RDB持久化的过程。
RDB持久化是把当前进程数据生成时间点快照(point-in-time snapshot)保存到硬盘的过程,避免数据意外丢失。
1.1 RDB触发机制
RDB触发机制分为手动触发和自动触发。
-
手动触发的两条命令:
-
SAVE:阻塞当前Redis服务器,知道RDB过程完成为止。 -
BGSAVE:Redis 进程执行fork()操作创建出一个子进程,在后台完成RDB持久化的过程。(主流) -
自动触发的配置:
-
c save 900 1 //服务器在900秒之内,对数据库执行了至少1次修改 save 300 10 //服务器在300秒之内,对数据库执行了至少10修改 save 60 1000 //服务器在60秒之内,对数据库执行了至少1000修改 // 满足以上三个条件中的任意一个,则自动触发 BGSAVE 操作 // 或者使用命令CONFIG SET 命令配置
1.2 RDB持久化的流程
我们用图来表示 BGSAVE命令 的触发流程,如下图所示:
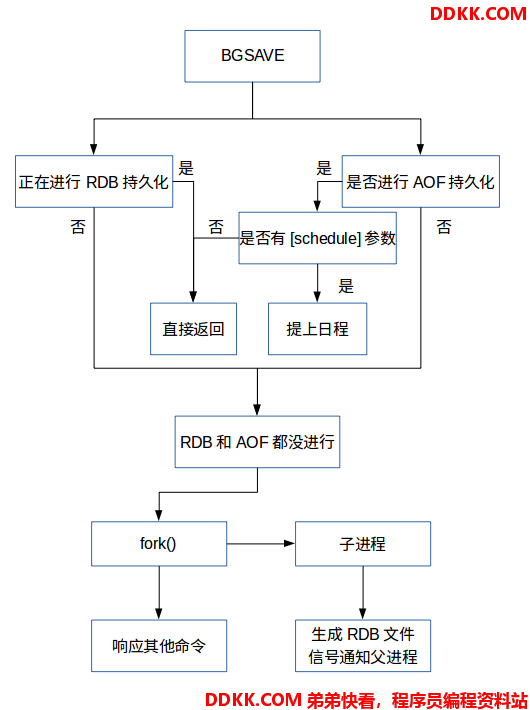
RDB命令源码如下:Redis 3.2 RDB源码注释
/* BGSAVE [SCHEDULE] */
// BGSAVE 命令实现
void bgsaveCommand(client *c) {
int schedule = 0; //SCHEDULE控制BGSAVE的执行,避免和AOF重写进程冲突
/* The SCHEDULE option changes the behavior of BGSAVE when an AOF rewrite
* is in progress. Instead of returning an error a BGSAVE gets scheduled. */
if (c->argc > 1) {
// 设置schedule标志
if (c->argc == 2 && !strcasecmp(c->argv[1]->ptr,"schedule")) {
schedule = 1;
} else {
addReply(c,shared.syntaxerr);
return;
}
}
// 如果正在执行RDB持久化操作,则退出
if (server.rdb_child_pid != -1) {
addReplyError(c,"Background save already in progress");
// 如果正在执行AOF持久化操作,需要将BGSAVE提上日程表
} else if (server.aof_child_pid != -1) {
// 如果schedule为真,设置rdb_bgsave_scheduled为1,表示将BGSAVE提上日程表
if (schedule) {
server.rdb_bgsave_scheduled = 1;
addReplyStatus(c,"Background saving scheduled");
} else { //没有设置schedule,则不能立即执行BGSAVE
addReplyError(c,
"An AOF log rewriting in progress: can't BGSAVE right now. "
"Use BGSAVE SCHEDULE in order to schedule a BGSAVE whenver "
"possible.");
}
// 执行BGSAVE
} else if (rdbSaveBackground(server.rdb_filename) == C_OK) {
addReplyStatus(c,"Background saving started");
} else {
addReply(c,shared.err);
}
}
我们后面会重点讲解rdbSaveBackground()函数的工作过程。
1.3 RDB的优缺点
RDB的优点:
- RDB是一个紧凑压缩的二进制文件,代表Redis在某个时间点上的数据快照。非常适用于备份,全景复制等场景。
- Redis 加载RDB恢复数据远远快于AOF的方式。
RDB的缺点:
- RDB没有办法做到实时持久化或秒级持久化。因为BGSAVE每次运行的又要进行fork()的调用创建子进程,这属于重量级操作,频繁执行成本过高,因为虽然Linux支持读时共享,写时拷贝(copy-on-write)的技术,但是仍然会有大量的父进程的空间内存页表,信号控制表,寄存器资源等等的复制。
- RDB文件使用特定的二进制格式保存,Redis版本演进的过程中,有多个RDB版本,这导致版本兼容的问题。
2. RDB 的源码剖析
阅读此部分,可以跳过源码,只看文字部分,因为所有过程的依据我都以源码的方式给出,因此篇幅会比较长,但是我都以文字解释,所以可以跳过源码,只读文字,理解RDB的过程。也可以上github查看所有代码的注释:Redis 3.2 源码注释
之前我们给出了 BGSAVE命令 的源码,因此我们就重点剖析 rdbSaveBackground()的工作过程,一层一层的剥开封装。
在RDB持久化之前需要设置一些标识,用来标识服务器当前的状态,定义在server.h/struct redisServer 结构体中,我们列出会用到的一部分,如果需要可以在这里查看。Redis 3.2 源码注释
struct redisServer {
// 数据库数组,长度为16
redisDb *db;
// 从节点列表和监视器列表
list *slaves, *qiank; /* List of slaves and MONITORs */
/* RDB / AOF loading information ××××××××××××××××××××××××××××××××××××××××××××××××××××××××××*/
// 正在载入状态
int loading; /* We are loading data from disk if true */
// 设置载入的总字节
off_t loading_total_bytes;
// 已载入的字节数
off_t loading_loaded_bytes;
// 载入的开始时间
time_t loading_start_time;
// 在load时,用来设置读或写的最大字节数max_processing_chunk
off_t loading_process_events_interval_bytes;
// 服务器内存使用的
size_t stat_peak_memory; /* Max used memory record */
// 计算fork()的时间
long long stat_fork_time; /* Time needed to perform latest fork() */
// 计算fork的速率,GB/每秒
double stat_fork_rate; /* Fork rate in GB/sec. */
/* RDB persistence ××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××*/
// 脏键,记录数据库被修改的次数
long long dirty; /* Changes to DB from the last save */
// 在BGSAVE之前要备份脏键dirty的值,如果BGSAVE失败会还原
long long dirty_before_bgsave; /* Used to restore dirty on failed BGSAVE */
// 执行BGSAVE的子进程的pid
pid_t rdb_child_pid; /* PID of RDB saving child */
// 保存save参数的数组
struct saveparam *saveparams; /* Save points array for RDB */
// 数组长度
int saveparamslen; /* Number of saving points */
// RDB文件的名字,默认为dump.rdb
char *rdb_filename; /* Name of RDB file */
// 是否采用LZF压缩算法压缩RDB文件,默认yes
int rdb_compression; /* Use compression in RDB? */
// RDB文件是否使用校验和,默认yes
int rdb_checksum; /* Use RDB checksum? */
// 上一次执行SAVE成功的时间
time_t lastsave; /* Unix time of last successful save */
// 最近一个尝试执行BGSAVE的时间
time_t lastbgsave_try; /* Unix time of last attempted bgsave */
// 最近执行BGSAVE的时间
time_t rdb_save_time_last; /* Time used by last RDB save run. */
// BGSAVE开始的时间
time_t rdb_save_time_start; /* Current RDB save start time. */
// 当rdb_bgsave_scheduled为真时,才能开始BGSAVE
int rdb_bgsave_scheduled; /* BGSAVE when possible if true. */
// rdb执行的类型,是写入磁盘,还是写入从节点的socket
int rdb_child_type; /* Type of save by active child. */
// BGSAVE执行完的状态
int lastbgsave_status; /* C_OK or C_ERR */
// 如果不能执行BGSAVE则不能写
int stop_writes_on_bgsave_err; /* Don't allow writes if can't BGSAVE */
// 无磁盘同步,管道的写端
int rdb_pipe_write_result_to_parent; /* RDB pipes used to return the state */
// 无磁盘同步,管道的读端
int rdb_pipe_read_result_from_child; /* of each slave in diskless SYNC. */
/* time cache ××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××*/
// 保存秒单位的Unix时间戳的缓存
time_t unixtime; /* Unix time sampled every cron cycle. */
// 保存毫秒单位的Unix时间戳的缓存
long long mstime; /* Like 'unixtime' but with milliseconds resolution. */
/* Latency monitor ××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××*/
// 延迟的阀值
long long latency_monitor_threshold;
// 延迟与造成延迟的事件关联的字典
dict *latency_events;
};
然后我们直接给rdbSaveBackground()函数出源码:
在这里,就可以看见fork()函数的执行,在子进程中执行了rdbSave()函数,父进程则执行了一些设置状态的操作。
// 后台进行RDB持久化BGSAVE操作
int rdbSaveBackground(char *filename) {
pid_t childpid;
long long start;
// 当前没有正在进行AOF和RDB操作,否则返回C_ERR
if (server.aof_child_pid != -1 || server.rdb_child_pid != -1) return C_ERR;
// 备份当前数据库的脏键值
server.dirty_before_bgsave = server.dirty;
// 最近一个执行BGSAVE的时间
server.lastbgsave_try = time(NULL);
// fork函数开始时间,记录fork函数的耗时
start = ustime();
// 创建子进程
if ((childpid = fork()) == 0) {
int retval;
// 子进程执行的代码
/* Child */
// 关闭监听的套接字
closeListeningSockets(0);
// 设置进程标题,方便识别
redisSetProcTitle("redis-rdb-bgsave");
// 执行保存操作,将数据库的写到filename文件中
retval = rdbSave(filename);
if (retval == C_OK) {
// 得到子进程进程的脏私有虚拟页面大小,如果做RDB的同时父进程正在写入的数据,那么子进程就会拷贝一个份父进程的内存,而不是和父进程共享一份内存。
size_t private_dirty = zmalloc_get_private_dirty();
// 将子进程分配的内容写日志
if (private_dirty) {
serverLog(LL_NOTICE,
"RDB: %zu MB of memory used by copy-on-write",
private_dirty/(1024*1024));
}
}
// 子进程退出,发送信号给父进程,发送0表示BGSAVE成功,1表示失败
exitFromChild((retval == C_OK) ? 0 : 1);
} else {
// 父进程执行的代码
/* Parent */
// 计算出fork的执行时间
server.stat_fork_time = ustime()-start;
// 计算fork的速率,GB/每秒
server.stat_fork_rate = (double) zmalloc_used_memory() * 1000000 / server.stat_fork_time / (1024*1024*1024); /* GB per second. */
//如果fork执行时长,超过设置的阀值,则要将其加入到一个字典中,与传入"fork"关联,以便进行延迟诊断
latencyAddSampleIfNeeded("fork",server.stat_fork_time/1000);
// 如果fork出错
if (childpid == -1) {
server.lastbgsave_status = C_ERR; //设置BGSAVE错误
// 更新日志信息
serverLog(LL_WARNING,"Can't save in background: fork: %s",
strerror(errno));
return C_ERR;
}
// 更新日志信息
serverLog(LL_NOTICE,"Background saving started by pid %d",childpid);
server.rdb_save_time_start = time(NULL); //设置BGSAVE开始的时间
server.rdb_child_pid = childpid; //设置负责执行BGSAVE操作的子进程id
server.rdb_child_type = RDB_CHILD_TYPE_DISK;//设置BGSAVE的类型,往磁盘中写入
//关闭哈希表的resize,因为resize过程中会有复制拷贝动作
updateDictResizePolicy();
return C_OK;
}
return C_OK; /* unreached */
}
我们接着看rdbSave()函数的源码:
在该函数中,就可以看见RDB文件的初始操作,刚开始生成一个临时的RDB文件,只有在执行成功后,才会进行rename操作,然后以写权限打开文件,然后调用了rdbSaveRio()函数将数据库的内容写到临时的RDB文件,之后进行刷新缓冲区和同步操作,就关闭文件进行rename操作和更新服务器状态。
我在此说一下rio,rio是Redis抽象的IO层,它可以面向三种对象,分别是缓冲区,文件IO和socket IO,在这里是调用
rioInitWithFile()初始化了一个文件IO对象rdb,实际上SAVE和LOAD命令分别对rdb对象的写和读操作的封装,因此,可以直接调用rdbSave*一类的函数进行写操作。具体的rio源码剖析:Redis 输入输出的抽象(rio)源码剖析和注释,Redis 在复制部分,还实现了无盘复制,生成的RDB文件不保存在磁盘中,而是直接写向一个网络的socket,所以,在初始化rio时,只需调用初始化socket IO的接口,而写和读操作的函数接口都不变。
/* Save the DB on disk. Return C_ERR on error, C_OK on success. */
// 将数据库保存在磁盘上,返回C_OK成功,否则返回C_ERR
int rdbSave(char *filename) {
char tmpfile[256];
char cwd[MAXPATHLEN]; /* Current working dir path for error messages. */
FILE *fp;
rio rdb;
int error = 0;
// 创建临时文件
snprintf(tmpfile,256,"temp-%d.rdb", (int) getpid());
// 以写方式打开该文件
fp = fopen(tmpfile,"w");
// 打开失败,获取文件目录,写入日志
if (!fp) {
char *cwdp = getcwd(cwd,MAXPATHLEN);
// 写日志信息到logfile
serverLog(LL_WARNING,
"Failed opening the RDB file %s (in server root dir %s) "
"for saving: %s",
filename,
cwdp ? cwdp : "unknown",
strerror(errno));
return C_ERR;
}
// 初始化一个rio对象,该对象是一个文件对象IO
rioInitWithFile(&rdb,fp);
// 将数据库的内容写到rio中
if (rdbSaveRio(&rdb,&error) == C_ERR) {
errno = error;
goto werr;
}
/* Make sure data will not remain on the OS's output buffers */
// 冲洗缓冲区,确保所有的数据都写入磁盘
if (fflush(fp) == EOF) goto werr;
// 将fp指向的文件同步到磁盘中
if (fsync(fileno(fp)) == -1) goto werr;
// 关闭文件
if (fclose(fp) == EOF) goto werr;
/* Use RENAME to make sure the DB file is changed atomically only
* if the generate DB file is ok. */
// 原子性改变rdb文件的名字
if (rename(tmpfile,filename) == -1) {
// 改变名字失败,则获得当前目录路径,发送日志信息,删除临时文件
char *cwdp = getcwd(cwd,MAXPATHLEN);
serverLog(LL_WARNING,
"Error moving temp DB file %s on the final "
"destination %s (in server root dir %s): %s",
tmpfile,
filename,
cwdp ? cwdp : "unknown",
strerror(errno));
unlink(tmpfile);
return C_ERR;
}
// 写日志文件
serverLog(LL_NOTICE,"DB saved on disk");
// 重置服务器的脏键
server.dirty = 0;
// 更新上一次SAVE操作的时间
server.lastsave = time(NULL);
// 更新SAVE操作的状态
server.lastbgsave_status = C_OK;
return C_OK;
// rdbSaveRio()函数的写错误处理,写日志,关闭文件,删除临时文件,发送C_ERR
werr:
serverLog(LL_WARNING,"Write error saving DB on disk: %s", strerror(errno));
fclose(fp);
unlink(tmpfile);
return C_ERR;
}
因此,我们接着往下挖,查看一下rdbSaveRio()函数干了什么。
在rdbSaveRio()函数中,我们已经清楚的看到往RDB文件中写了什么内容。
例如:Redis标识,RDB版本号,rdb文件的默认信息,还有就是写数据库中的内容,接下来写入一个EOF码,最后执行校验和。因此一个完成的RDB文件如图所示:

// 将一个RDB格式文件内容写入到rio中,成功返回C_OK,否则C_ERR和一部分或所有的出错信息
// 当函数返回C_ERR,并且error不是NULL,那么error被设置为一个错误码errno
int rdbSaveRio(rio *rdb, int *error) {
dictIterator *di = NULL;
dictEntry *de;
char magic[10];
int j;
long long now = mstime();
uint64_t cksum;
// 开启了校验和选项
if (server.rdb_checksum)
// 设置校验和的函数
rdb->update_cksum = rioGenericUpdateChecksum;
// 将Redis版本信息保存到magic中
snprintf(magic,sizeof(magic),"REDIS%04d",RDB_VERSION);
// 将magic写到rio中
if (rdbWriteRaw(rdb,magic,9) == -1) goto werr;
// 将rdb文件的默认信息写到rio中
if (rdbSaveInfoAuxFields(rdb) == -1) goto werr;
// 遍历所有服务器内的数据库
for (j = 0; j < server.dbnum; j++) {
redisDb *db = server.db+j; //当前的数据库指针
dict *d = db->dict; //当数据库的键值对字典
// 跳过为空的数据库
if (dictSize(d) == 0) continue;
// 创建一个字典类型的迭代器
di = dictGetSafeIterator(d);
if (!di) return C_ERR;
/* Write the SELECT DB opcode */
// 写入数据库的选择标识码 RDB_OPCODE_SELECTDB为254
if (rdbSaveType(rdb,RDB_OPCODE_SELECTDB) == -1) goto werr;
// 写入数据库的id,占了一个字节的长度
if (rdbSaveLen(rdb,j) == -1) goto werr;
/* Write the RESIZE DB opcode. We trim the size to UINT32_MAX, which
* is currently the largest type we are able to represent in RDB sizes.
* However this does not limit the actual size of the DB to load since
* these sizes are just hints to resize the hash tables. */
// 写入调整数据库的操作码,我们将大小限制在UINT32_MAX以内,这并不代表数据库的实际大小,只是提示去重新调整哈希表的大小
uint32_t db_size, expires_size;
// 如果字典的大小大于UINT32_MAX,则设置db_size为最大的UINT32_MAX
db_size = (dictSize(db->dict) <= UINT32_MAX) ?
dictSize(db->dict) :
UINT32_MAX;
// 设置有过期时间键的大小超过UINT32_MAX,则设置expires_size为最大的UINT32_MAX
expires_size = (dictSize(db->expires) <= UINT32_MAX) ?
dictSize(db->expires) :
UINT32_MAX;
// 写入调整哈希表大小的操作码,RDB_OPCODE_RESIZEDB = 251
if (rdbSaveType(rdb,RDB_OPCODE_RESIZEDB) == -1) goto werr;
// 写入提示调整哈希表大小的两个值,如果
if (rdbSaveLen(rdb,db_size) == -1) goto werr;
if (rdbSaveLen(rdb,expires_size) == -1) goto werr;
/* Iterate this DB writing every entry */
// 遍历数据库所有的键值对
while((de = dictNext(di)) != NULL) {
sds keystr = dictGetKey(de); //当前键
robj key, *o = dictGetVal(de); //当前键的值
long long expire;
// 在栈中创建一个键对象并初始化
initStaticStringObject(key,keystr);
// 当前键的过期时间
expire = getExpire(db,&key);
// 将键的键对象,值对象,过期时间写到rio中
if (rdbSaveKeyValuePair(rdb,&key,o,expire,now) == -1) goto werr;
}
dictReleaseIterator(di); //释放迭代器
}
di = NULL; /* So that we don't release it again on error. */
/* EOF opcode */
// 写入一个EOF码,RDB_OPCODE_EOF = 255
if (rdbSaveType(rdb,RDB_OPCODE_EOF) == -1) goto werr;
/* CRC64 checksum. It will be zero if checksum computation is disabled, the
* loading code skips the check in this case. */
// CRC64检验和,当校验和计算为0,没有开启是,在载入rdb文件时会跳过
cksum = rdb->cksum;
memrev64ifbe(&cksum);
if (rioWrite(rdb,&cksum,8) == 0) goto werr;
return C_OK;
// 写入错误
werr:
if (error) *error = errno; //保存错误码
if (di) dictReleaseIterator(di); //如果没有释放迭代器,则释放
return C_ERR;
}
调用rdbSaveInfoAuxFields()函数写入一些默认的辅助信息,具体如下:
/* Save a few default AUX fields with information about the RDB generated. */
// 将一个rdb文件的默认信息写入到rio中
int rdbSaveInfoAuxFields(rio *rdb) {
// 判断主机的总线宽度,是64位还是32位
int redis_bits = (sizeof(void*) == 8) ? 64 : 32;
/* Add a few fields about the state when the RDB was created. */
// 添加rdb文件的状态信息:Redis版本,redis位数,当前时间和Redis当前使用的内存数
if (rdbSaveAuxFieldStrStr(rdb,"redis-ver",REDIS_VERSION) == -1) return -1;
if (rdbSaveAuxFieldStrInt(rdb,"redis-bits",redis_bits) == -1) return -1;
if (rdbSaveAuxFieldStrInt(rdb,"ctime",time(NULL)) == -1) return -1;
if (rdbSaveAuxFieldStrInt(rdb,"used-mem",zmalloc_used_memory()) == -1) return -1;
return 1;
}
因此,一个空数据库持久化生成的dump.rdb文件,使用od -cx dump.rdb命令查看一下
0000000 R E D I S 0 0 0 7 372 \t r e d i s
4552 4944 3053 3030 fa37 7209 6465 7369
0000020 - v e r 005 3 . 2 . 8 372 \n r e d i
762d 7265 3305 322e 382e 0afa 6572 6964
0000040 s - b i t s 300 @ 372 005 c t i m e 302
2d73 6962 7374 40c0 05fa 7463 6d69 c265
0000060 u 7 \f Y 372 \b u s e d - m e m 302 0
3775 590c 08fa 7375 6465 6d2d 6d65 30c2
0000100 211 \f \0 377 8 341 Y 220 225 346 L 245
0c89 ff00 e138 9059 e695 a54c
0000114
我们将其统计整合一下:
REDIS0007 372\t //Redis版本号:REDIS0007
redis-ver 005 3.2.8 372\n //Redis的版本:redis-ver 3.2.8
redis-bits 300 @ 372 005 //主机系统位数:redis-bits
ctime 302 246 242 \b Y 372 \b //RDB操作的时间
userd-mem 302 205 \f \0 //子进程使用的内存量
377 //八进制377 = 十六进制255 = EOF常量
8 341 Y 220 225 346 L 245 //校验和:8字节
虽然大概的看懂了一些,但是仍然还有一些八进制数字看不懂,这就是我们所描述RDB文件的特点:紧凑压缩。这些都是一些压缩过的数据或操作码。接下来,还是通过源码,查看这些压缩的规则,Redis将各种类型编码封装成许多函数,不利于查看编码规则,因此,我们就给出rdbLoad()函数,这个函数是服务器启动时,将RDB文件中的内容载入到数据库中。
rdbLoad()函数源码如下:
// 将指定的RDB文件读到数据库中
int rdbLoad(char *filename) {
uint32_t dbid;
int type, rdbver;
redisDb *db = server.db+0;
char buf[1024];
long long expiretime, now = mstime(); //获取当前load操作的时间
FILE *fp;
rio rdb;
// 只读打开文件
if ((fp = fopen(filename,"r")) == NULL) return C_ERR;
// 初始化一个文件流对象rio且设置对应文件指针
rioInitWithFile(&rdb,fp);
// 设置计算校验和的函数
rdb.update_cksum = rdbLoadProgressCallback;
// 设置载入读或写的最大字节数,2M
rdb.max_processing_chunk = server.loading_process_events_interval_bytes;
// 读出9个字节到buf,buf中保存着Redis版本"redis0007"
if (rioRead(&rdb,buf,9) == 0) goto eoferr;
buf[9] = '\0'; //"redis0007\0"
//检查读出的版本号标识
if (memcmp(buf,"REDIS",5) != 0) {
fclose(fp);
serverLog(LL_WARNING,"Wrong signature trying to load DB from file");
errno = EINVAL; //读出的值非法
return C_ERR;
}
// 转换成整数检查版本大小
rdbver = atoi(buf+5);
if (rdbver < 1 || rdbver > RDB_VERSION) {
fclose(fp);
serverLog(LL_WARNING,"Can't handle RDB format version %d",rdbver);
errno = EINVAL;
return C_ERR;
}
// 设置载入时server的状态信息
startLoading(fp);
// 开始读取RDB文件到数据库中
while(1) {
robj *key, *val;
expiretime = -1;
/* Read type. */
// 首先读出类型
if ((type = rdbLoadType(&rdb)) == -1) goto eoferr;
/* Handle special types. */
// 处理特殊情况
// 如果首先是读出过期时间单位为秒
if (type == RDB_OPCODE_EXPIRETIME) {
/* EXPIRETIME: load an expire associated with the next key
* to load. Note that after loading an expire we need to
* load the actual type, and continue. */
// 从rio中读出过期时间
if ((expiretime = rdbLoadTime(&rdb)) == -1) goto eoferr;
/* We read the time so we need to read the object type again. */
// 从过期时间后读出一个键值对的类型
if ((type = rdbLoadType(&rdb)) == -1) goto eoferr;
/* the EXPIRETIME opcode specifies time in seconds, so convert
* into milliseconds. */
expiretime *= 1000; //转换成毫秒
//读出过期时间单位为毫秒
} else if (type == RDB_OPCODE_EXPIRETIME_MS) {
/* EXPIRETIME_MS: milliseconds precision expire times introduced
* with RDB v3. Like EXPIRETIME but no with more precision. */
// 从rio中读出过期时间
if ((expiretime = rdbLoadMillisecondTime(&rdb)) == -1) goto eoferr;
/* We read the time so we need to read the object type again. */
// 从过期时间后读出一个键值对的类型
if ((type = rdbLoadType(&rdb)) == -1) goto eoferr;
// 如果读到EOF,则直接跳出循环
} else if (type == RDB_OPCODE_EOF) {
/* EOF: End of file, exit the main loop. */
break;
// 读出的是切换数据库操作
} else if (type == RDB_OPCODE_SELECTDB) {
/* SELECTDB: Select the specified database. */
// 读取出一个长度,保存的是数据库的ID
if ((dbid = rdbLoadLen(&rdb,NULL)) == RDB_LENERR)
goto eoferr;
// 检查读出的ID是否合法
if (dbid >= (unsigned)server.dbnum) {
serverLog(LL_WARNING,
"FATAL: Data file was created with a Redis "
"server configured to handle more than %d "
"databases. Exiting\n", server.dbnum);
exit(1);
}
// 切换数据库
db = server.db+dbid;
// 跳过本层循环,在读一个type
continue; /* Read type again. */
// 如果读出调整哈希表的操作
} else if (type == RDB_OPCODE_RESIZEDB) {
/* RESIZEDB: Hint about the size of the keys in the currently
* selected data base, in order to avoid useless rehashing. */
uint32_t db_size, expires_size;
// 读出一个数据库键值对字典的大小
if ((db_size = rdbLoadLen(&rdb,NULL)) == RDB_LENERR)
goto eoferr;
// 读出一个数据库过期字典的大小
if ((expires_size = rdbLoadLen(&rdb,NULL)) == RDB_LENERR)
goto eoferr;
// 扩展两个字典
dictExpand(db->dict,db_size);
dictExpand(db->expires,expires_size);
// 重新读出一个type
continue; /* Read type again. */
// 读出的是一个辅助字段
} else if (type == RDB_OPCODE_AUX) {
/* AUX: generic string-string fields. Use to add state to RDB
* which is backward compatible. Implementations of RDB loading
* are requierd to skip AUX fields they don't understand.
*
* An AUX field is composed of two strings: key and value. */
robj *auxkey, *auxval;
// 读出辅助字段的键对象和值对象
if ((auxkey = rdbLoadStringObject(&rdb)) == NULL) goto eoferr;
if ((auxval = rdbLoadStringObject(&rdb)) == NULL) goto eoferr;
// 键对象的第一个字符是%
if (((char*)auxkey->ptr)[0] == '%') {
/* All the fields with a name staring with '%' are considered
* information fields and are logged at startup with a log
* level of NOTICE. */
// 写日志信息
serverLog(LL_NOTICE,"RDB '%s': %s",
(char*)auxkey->ptr,
(char*)auxval->ptr);
} else {
/* We ignore fields we don't understand, as by AUX field
* contract. */
serverLog(LL_DEBUG,"Unrecognized RDB AUX field: '%s'",
(char*)auxkey->ptr);
}
decrRefCount(auxkey);
decrRefCount(auxval);
// 重新读出一个type
continue; /* Read type again. */
}
/* Read key */
// 读出一个key对象
if ((key = rdbLoadStringObject(&rdb)) == NULL) goto eoferr;
/* Read value */
// 读出一个val对象
if ((val = rdbLoadObject(type,&rdb)) == NULL) goto eoferr;
/* Check if the key already expired. This function is used when loading
* an RDB file from disk, either at startup, or when an RDB was
* received from the master. In the latter case, the master is
* responsible for key expiry. If we would expire keys here, the
* snapshot taken by the master may not be reflected on the slave. */
// 如果当前环境不是从节点,且该键设置了过期时间,已经过期
if (server.masterhost == NULL && expiretime != -1 && expiretime < now) {
// 释放键值对
decrRefCount(key);
decrRefCount(val);
continue;
}
/* Add the new object in the hash table */
// 将没有过期的键值对添加到数据库键值对字典中
dbAdd(db,key,val);
/* Set the expire time if needed */
// 如果需要,设置过期时间
if (expiretime != -1) setExpire(db,key,expiretime);
decrRefCount(key); //释放临时对象
}
// 此时已经读出完所有数据库的键值对,读到了EOF,但是EOF不是RDB文件的结束,还要进行校验和
/* Verify the checksum if RDB version is >= 5 */
// 当RDB版本大于5时,且开启了校验和的功能,那么进行校验和
if (rdbver >= 5 && server.rdb_checksum) {
uint64_t cksum, expected = rdb.cksum;
// 读出一个8字节的校验和,然后比较
if (rioRead(&rdb,&cksum,8) == 0) goto eoferr;
memrev64ifbe(&cksum);
if (cksum == 0) {
serverLog(LL_WARNING,"RDB file was saved with checksum disabled: no check performed.");
} else if (cksum != expected) {
serverLog(LL_WARNING,"Wrong RDB checksum. Aborting now.");
rdbExitReportCorruptRDB("RDB CRC error");
}
}
fclose(fp); //关闭RDB文件
stopLoading(); //设置载入完成的状态
return C_OK;
// 错误退出
eoferr: /* unexpected end of file is handled here with a fatal exit */
serverLog(LL_WARNING,"Short read or OOM loading DB. Unrecoverable error, aborting now.");
// 检查rdb错误发送信息且退出
rdbExitReportCorruptRDB("Unexpected EOF reading RDB file");
return C_ERR; /* Just to avoid warning */
}
从这个函数中,我们可以看到许多RDB_TYPE_*类型的对象,他们定义在rdb.h中。
/* Dup object types to RDB object types. Only reason is readability (are we
* dealing with RDB types or with in-memory object types?). */
#define RDB_TYPE_STRING 0 //字符串类型
#define RDB_TYPE_LIST 1 //列表类型
#define RDB_TYPE_SET 2 //集合类型
#define RDB_TYPE_ZSET 3 //有序集合类型
#define RDB_TYPE_HASH 4 //哈希类型
/* NOTE: WHEN ADDING NEW RDB TYPE, UPDATE rdbIsObjectType() BELOW */
/* Object types for encoded objects. */
#define RDB_TYPE_HASH_ZIPMAP 9
#define RDB_TYPE_LIST_ZIPLIST 10 //列表对象的ziplist编码类型
#define RDB_TYPE_SET_INTSET 11 //集合对象的intset编码类型
#define RDB_TYPE_ZSET_ZIPLIST 12 //有序集合的ziplist编码类型
#define RDB_TYPE_HASH_ZIPLIST 13 //哈希对象的ziplist编码类型
#define RDB_TYPE_LIST_QUICKLIST 14 //列表对象的quicklist编码类型
/* NOTE: WHEN ADDING NEW RDB TYPE, UPDATE rdbIsObjectType() BELOW */
/* Test if a type is an object type. */
// 测试t是否是一个对象的编码类型
#define rdbIsObjectType(t) ((t >= 0 && t <= 4) || (t >= 9 && t <= 14))
/* Special RDB opcodes (saved/loaded with rdbSaveType/rdbLoadType). */
#define RDB_OPCODE_AUX 250 //辅助标识
#define RDB_OPCODE_RESIZEDB 251 //提示调整哈希表大小的操作码
#define RDB_OPCODE_EXPIRETIME_MS 252 //过期时间毫秒
#define RDB_OPCODE_EXPIRETIME 253 //过期时间秒
#define RDB_OPCODE_SELECTDB 254 //选择数据库的操作
#define RDB_OPCODE_EOF 255 //EOF码
因此,看到这,我们就可以剖析dump.rdb文件了。
0000000 R E D I S 0 0 0 7 372 \t r e d i s
4552 4944 3053 3030 fa37 7209 6465 7369
0000020 - v e r 005 3 . 2 . 8 372 \n r e d i
762d 7265 3305 322e 382e 0afa 6572 6964
0000040 s - b i t s 300 @ 372 005 c t i m e 302
2d73 6962 7374 40c0 05fa 7463 6d69 c265
0000060 u 7 \f Y 372 \b u s e d - m e m 302 0
3775 590c 08fa 7375 6465 6d2d 6d65 30c2
0000100 211 \f \0 377 8 341 Y 220 225 346 L 245
0c89 ff00 e138 9059 e695 a54c
0000114
八进制372 对应着十进制的RDB_OPCODE_AUX,然后在到rdbLoad()函数中,找到type == RDB_OPCODE_AUX的情况,要分别读出一个键对象和一个值对象;
-
读对象时,先读1个字节的长度,因此八进制'\t'对应十进制的9,所以在读键对象的长度为9字节,正如所分析的,redis-ver长度为9字节。
-
然后读出一值对象,先读
1字节的长度,因此八进制的005对应十进制的5,所以在读出值对象的长度为5字节,正如所分析的,3.2.8长度为5字节。
判断完type == RDB_OPCODE_AUX的情况,然后根据代码,要跳出当前循环,于是,在读出1个字节的type,此时type =还是372,于是还是分别读出一个键对象和一个值对象;
- 读对象时,先读1个字节的长度,因此八进制'\n'对应十进制的10,所以在读键对象的长度为10字节,正如所分析的,redis-bits长度为10字节。
- 然后读出一值对象,先读1字节的长度,因此八进制的300对应十进制的192,此时,这显然不对,是因为RDB是经过压缩过得文件,接下来,我们介绍压缩的规则:
/* When a length of a string object stored on disk has the first two bits
* set, the remaining two bits specify a special encoding for the object
* accordingly to the following defines: */
#define RDB_ENC_INT8 0 /* 8位有符号整数 8 bit signed integer */
#define RDB_ENC_INT16 1 /* 16位有符号整数 16 bit signed integer */
#define RDB_ENC_INT32 2 /* 32位有符号整数 32 bit signed integer */
#define RDB_ENC_LZF 3 /* LZF压缩过的字符串 string compressed with FASTLZ */
#define RDB_6BITLEN 0 //6位长
#define RDB_14BITLEN 1 //14位长
#define RDB_32BITLEN 2 //32位长
#define RDB_ENCVAL 3 //编码值
#define RDB_LENERR UINT_MAX //错误值
一个字符串压缩可能有如上4种,它的读法,可以看rdbLoadLen()函数的源码:可以从这个函数中看出,不同编码类型,保存值的长度所占的字节数。
- 我们读一值对象,先读1字节的长度,因此八进制的300对应二进制的1100 0000,它的最高两位是11,十进制是3,对应RDB_ENCVAL类型,并且返回0。
// 返回一个从rio读出的len值,如果该len值不是整数,而是被编码后的值,那么将isencoded设置为1
uint32_t rdbLoadLen(rio *rdb, int *isencoded) {
unsigned char buf[2];
uint32_t len;
int type;
// 默认为没有编码
if (isencoded) *isencoded = 0;
// 将rio中的值读到buf中
if (rioRead(rdb,buf,1) == 0) return RDB_LENERR;
// (buf[0]&0xC0)>>6 = (1100 000 & buf[0]) >> 6 = buf[0]的最高两位
type = (buf[0]&0xC0)>>6;
// 一个编码过的值,返回解码值,设置编码标志
if (type == RDB_ENCVAL) {
/* Read a 6 bit encoding type. */
if (isencoded) *isencoded = 1;
return buf[0]&0x3F; //取出剩下六位表示的长度值
// 一个6位长的值
} else if (type == RDB_6BITLEN) {
/* Read a 6 bit len. */
return buf[0]&0x3F; //取出剩下六位表示的长度值
// 一个14位长的值
} else if (type == RDB_14BITLEN) {
/* Read a 14 bit len. */
// 从buf+1读出1个字节的值
if (rioRead(rdb,buf+1,1) == 0) return RDB_LENERR;
return ((buf[0]&0x3F)<<8)|buf[1]; //取出除最高两位的长度值
// 一个32位长的值
} else if (type == RDB_32BITLEN) {
/* Read a 32 bit len. */
// 读出4个字节的值
if (rioRead(rdb,&len,4) == 0) return RDB_LENERR;
return ntohl(len); //转换为主机序的值
} else {
rdbExitReportCorruptRDB(
"Unknown length encoding %d in rdbLoadLen()",type);
return -1; /* Never reached. */
}
}
- 然后回到创建字符串对象的函数rdbGenericLoadStringObject(),rdbLoadLen()函数的返回值是0,对应RDB_ENC_INT8,然后又调用了rdbLoadIntegerObject()函数。
// 根据flags,将从rio读出一个字符串对象进行编码
void *rdbGenericLoadStringObject(rio *rdb, int flags) {
int encode = flags & RDB_LOAD_ENC; //编码
int plain = flags & RDB_LOAD_PLAIN; //原生的值
int isencoded;
uint32_t len;
// 从rio中读出一个字符串对象,编码类型保存在isencoded中,所需的字节为len
len = rdbLoadLen(rdb,&isencoded);
// 如果读出的对象被编码(isencoded被设置为1),则根据不同的长度值len映射到不同的整数编码
if (isencoded) {
switch(len) {
case RDB_ENC_INT8:
case RDB_ENC_INT16:
case RDB_ENC_INT32:
// 以上三种类型的整数编码,根据flags返回不同类型值
return rdbLoadIntegerObject(rdb,len,flags);
case RDB_ENC_LZF:
// 如果是压缩后的字符串,进行构建压缩字符串编码对象
return rdbLoadLzfStringObject(rdb,flags);
default:
rdbExitReportCorruptRDB("Unknown RDB string encoding type %d",len);
}
}
// 如果len值错误,则返回NULL
if (len == RDB_LENERR) return NULL;
// 如果不是原生值
if (!plain) {
// 根据encode编码类型创建不同的字符串对象
robj *o = encode ? createStringObject(NULL,len) :
createRawStringObject(NULL,len);
// 设置o对象的值,从rio中读出来,如果失败,释放对象返回NULL
if (len && rioRead(rdb,o->ptr,len) == 0) {
decrRefCount(o);
return NULL;
}
return o;
// 如果设置了原生值
} else {
// 分配空间
void *buf = zmalloc(len);
// 从rio中读出来
if (len && rioRead(rdb,buf,len) == 0) {
zfree(buf);
return NULL;
}
return buf; //返回
}
}
- 当传入的编码是RDB_ENC_INT8时。它又从后面读取了1字节。后面的八进制值\n,对应十进制为64,因此redis-bits
所对应的值为64,也就是64位的Redis服务器。
// 将rio中的整数值根据不同的编码读出来,并根据flags构建成一个不同类型的值并返回
void *rdbLoadIntegerObject(rio *rdb, int enctype, int flags) {
int plain = flags & RDB_LOAD_PLAIN; //无格式
int encode = flags & RDB_LOAD_ENC; //字符串对象
unsigned char enc[4];
long long val;
// 根据不同的整数编码类型,从rio中读出整数值到enc中
if (enctype == RDB_ENC_INT8) {
if (rioRead(rdb,enc,1) == 0) return NULL;
val = (signed char)enc[0];
} else if (enctype == RDB_ENC_INT16) {
uint16_t v;
if (rioRead(rdb,enc,2) == 0) return NULL;
v = enc[0]|(enc[1]<<8);
val = (int16_t)v;
} else if (enctype == RDB_ENC_INT32) {
uint32_t v;
if (rioRead(rdb,enc,4) == 0) return NULL;
v = enc[0]|(enc[1]<<8)|(enc[2]<<16)|(enc[3]<<24);
val = (int32_t)v;
} else {
val = 0; /* anti-warning */
rdbExitReportCorruptRDB("Unknown RDB integer encoding type %d",enctype);
}
// 如果是整数,转换为字符串类型返回
if (plain) {
char buf[LONG_STR_SIZE], *p;
int len = ll2string(buf,sizeof(buf),val);
p = zmalloc(len);
memcpy(p,buf,len);
return p;
// 如果是编码过的整数值,则转换为字符串对象,返回
} else if (encode) {
return createStringObjectFromLongLong(val);
} else {
// 返回一个字符串对象
return createObject(OBJ_STRING,sdsfromlonglong(val));
}
}
此时,也就介绍完了所有规则,后面的分析和之前的如出一辙,因此,不在继续分析了。SAVE和LOAD是相反的过程,因此可以反过来理解。
我将RDB持久化所有的源码放在了github上,欢迎阅读:Redis 3.2 源码注释