Redis 字典结构
1. 介绍
字典又称为符号表(symbol table)、关联数组(associative array)或映射(map),是一种用于保存键值对(key-value pair)的抽象数据结构。例如:redis中的所有key到value的映射,就是通过字典结构维护,还有hash类型的键值。
通过redis中的命令感受一下哈希键。
127.0.0.1:6379> HSET user name Mike
(integer) 1
127.0.0.1:6379> HSET user passwd 123456
(integer) 1
127.0.0.1:6379> HSET user sex male
(integer) 1
127.0.0.1:6379> HLEN user //user就是一个包含3个键值对的哈希键
(integer) 3
127.0.0.1:6379> HGETALL user
1) "name"
2) "Mike"
3) "passwd"
4) "123456"
5) "sex"
6) "male"
user键在底层实现就是一个字典,字典包含3个键值对。
2. 字典的实现
redis的字典是由哈希表实现的,一个哈希表有多个节点,每个节点保存一个键值对。
2.1 哈希表
redis中哈希表定义在dict.h/dictht中。
typedef struct dictht { //哈希表
dictEntry **table; //存放一个数组的地址,数组存放着哈希表节点dictEntry的地址。
unsigned long size; //哈希表table的大小,初始化大小为4
unsigned long sizemask; //用于将哈希值映射到table的位置索引。它的值总是等于(size-1)。
unsigned long used; //记录哈希表已有的节点(键值对)数量。
} dictht;
2.2 哈希表节点
哈希表的table指向的数组存放这dictEntry类型的地址。也定义在dict.h/dictEntryt中。
ypedef struct dictEntry {
void *key; //key
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v; //value
struct dictEntry *next; //指向下一个hash节点,用来解决hash键冲突(collision)
} dictEntry;
下图展现的就是通过链接法(chaining) 来解决冲突的方法。
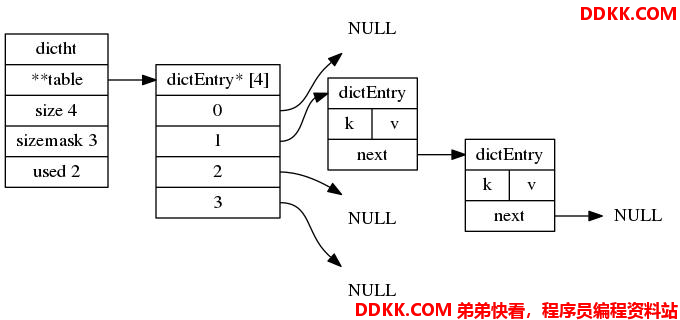
2.3 字典
字典结构定义在dict.h/dict中。
typedef struct dict {
dictType *type; //指向dictType结构,dictType结构中包含自定义的函数,这些函数使得key和value能够存储任何类型的数据。
void *privdata; //私有数据,保存着dictType结构中函数的参数。
dictht ht[2]; //两张哈希表。
long rehashidx; //rehash的标记,rehashidx==-1,表示没在进行rehash
int iterators; //正在迭代的迭代器数量
} dict;
dictType类型保存着 操作字典不同类型key和value的方法 的指针。
typedef struct dictType {
unsigned int (*hashFunction)(const void *key); //计算hash值的函数
void *(*keyDup)(void *privdata, const void *key); //复制key的函数
void *(*valDup)(void *privdata, const void *obj); //复制value的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2); //比较key的函数
void (*keyDestructor)(void *privdata, void *key); //销毁key的析构函数
void (*valDestructor)(void *privdata, void *obj); //销毁val的析构函数
} dictType;
下图展现的就是刚才命令user哈希键所展现的内部结构:
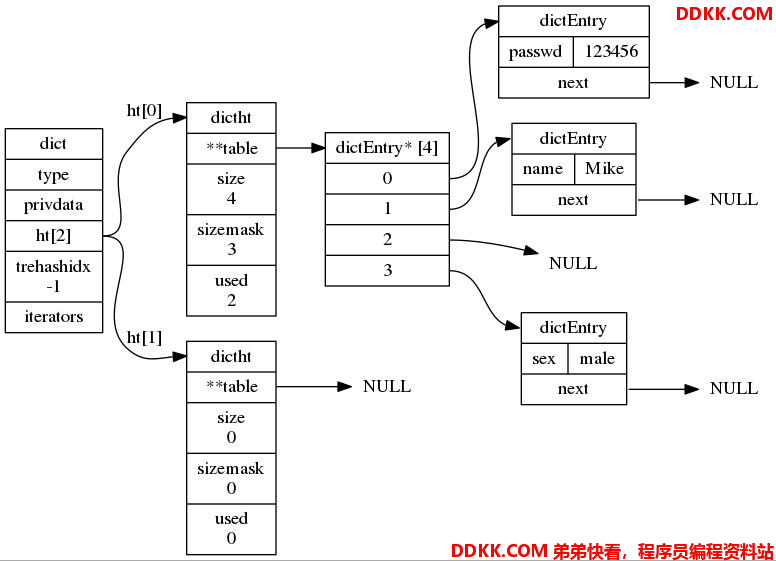
3. 哈希算法
Thomas Wang认为好的hash函数具有两个好的特点:
1、 hash函数是可逆的;
2、 具有雪崩效应,意思是,输入值1bit位的变化会造成输出值1/2的bit位发生变化;
3.1 计算int整型哈希值的哈希函数
unsigned int dictIntHashFunction(unsigned int key) //用于计算int整型哈希值的哈希函数
{
key += ~(key << 15);
key ^= (key >> 10);
key += (key << 3);
key ^= (key >> 6);
key += ~(key << 11);
key ^= (key >> 16);
return key;
}
3.2 MurmurHash2哈希算法
当字典被用作数据库的底层实现,或者哈希键的底层实现时,redis用MurmurHash2算法来计算哈希值,能产生32-bit或64-bit哈希值。
unsigned int dictGenHashFunction(const void *key, int len) { //用于计算字符串的哈希值的哈希函数
/* 'm' and 'r' are mixing constants generated offline.
They're not really 'magic', they just happen to work well. */
//m和r这两个值用于计算哈希值,只是因为效果好。
uint32_t seed = dict_hash_function_seed;
const uint32_t m = 0x5bd1e995;
const int r = 24;
/* Initialize the hash to a 'random' value */
uint32_t h = seed ^ len; //初始化
/* Mix 4 bytes at a time into the hash */
const unsigned char *data = (const unsigned char *)key;
//将字符串key每四个一组看成uint32_t类型,进行运算的到h
while(len >= 4) {
uint32_t k = *(uint32_t*)data;
k *= m;
k ^= k >> r;
k *= m;
h *= m;
h ^= k;
data += 4;
len -= 4;
}
/* Handle the last few bytes of the input array */
switch(len) {
case 3: h ^= data[2] << 16;
case 2: h ^= data[1] << 8;
case 1: h ^= data[0]; h *= m;
};
/* Do a few final mixes of the hash to ensure the last few
* bytes are well-incorporated. */
h ^= h >> 13;
h *= m;
h ^= h >> 15;
return (unsigned int)h;
}
3.3 djb哈希算法
djb哈希算法,算法的思想是利用字符串中的ascii码值与一个随机seed,通过len次变换,得到最后的hash值。
unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len) { //用于计算字符串的哈希值的哈希函数
unsigned int hash = (unsigned int)dict_hash_function_seed;
while (len--)
hash = ((hash << 5) + hash) + (tolower(*buf++)); /* hash * 33 + c */
return hash;
}
4. rehash
当哈希表的大小不能满足需求,就可能会有两个或者以上数量的键被分配到了哈希表数组上的同一个索引上,于是就发生冲突(collision) ,在Redis中解决冲突的办法是链接法(separate chaining) 。但是需要尽可能避免冲突,希望哈希表的负载因子(load factor) ,维持在一个合理的范围之内,就需要对哈希表进行扩展或收缩。
Redis对哈希表的rehash操作步骤如下:
1、 扩展或收缩;
- 扩展:ht[1]的大小为第一个大于等于ht[0].used * 2的 2n 。
- 收缩:ht[1]的大小为第一个大于等于ht[0].used的 2n 。
2、 将所有的ht[0]上的节点rehash到ht[1]上;
3、 释放ht[0],将ht[1]设置为第0号表,并创建新的ht[1];
源码再此:
- 扩展操作
static int _dictExpandIfNeeded(dict *d) //扩展d字典,并初始化
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK; //正在进行rehash,直接返回
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); //如果字典(的 0 号哈希表)为空,那么创建并返回初始化大小的 0 号哈希表
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
//1. 字典已使用节点数和字典大小之间的比率接近 1:1
//2. 能够扩展的标志为真
//3. 已使用节点数和字典大小之间的比率超过 dict_force_resize_ratio
if (d->ht[0].used >= d->ht[0].size && (dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2); //扩展为节点个数的2倍
}
return DICT_OK;
}
- 收缩操作:
int dictResize(dict *d) //缩小字典d
{
int minimal;
//如果dict_can_resize被设置成0,表示不能进行rehash,或正在进行rehash,返回出错标志DICT_ERR
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
minimal = d->ht[0].used; //获得已经有的节点数量作为最小限度minimal
if (minimal < DICT_HT_INITIAL_SIZE)//但是minimal不能小于最低值DICT_HT_INITIAL_SIZE(4)
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal); //用minimal调整字典d的大小
}
扩展和收缩操作都调用了dictExpand()函数,该函数通过计算传入的第二个大小参数进行计算,算出一个最接近2n的realsize,然后进行扩展或收缩,dictExpand()函数源码如下:
int dictExpand(dict *d, unsigned long size) //根据size调整或创建字典d的哈希表
{
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size); //获得一个最接近2^n的realsize
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht[0].used > size) //正在rehash或size不够大返回出错标志
return DICT_ERR;
/* Rehashing to the same table size is not useful. */
if (realsize == d->ht[0].size) return DICT_ERR; //如果新的realsize和原本的size一样则返回出错标志
/* Allocate the new hash table and initialize all pointers to NULL */
//初始化新的哈希表的成员
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) { //如果ht[0]哈希表为空,则将新的哈希表n设置为ht[0]
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n; //如果ht[0]非空,则需要rehash
d->rehashidx = 0; //设置rehash标志位为0,开始渐进式rehash(incremental rehashing)
return DICT_OK;
}
收缩或者扩展哈希表需要将ht[0]表中的所有键全部rehash到ht[1]中,但是rehash操作不是一次性、集中式完成的,而是分多次,渐进式,断续进行的,这样才不会对服务器性能造成影响。因此下面介绍渐进式rehash。
5. 渐进式rehash(incremental rehashing)
渐进式rehash的关键:
1、 字典结构dict中的一个成员rehashidx,当rehashidx为-1时表示不进行rehash,当rehashidx值为0时,表示开始进行rehash;
2、 在rehash期间,每次对字典的添加、删除、查找、或更新操作时,都会判断是否正在进行rehash操作,如果是,则顺带进行单步rehash,并将rehashidx+1;
3、 当rehash时进行完成时,将rehashidx置为-1,表示完成rehash;
源码在此:
static void _dictRehashStep(dict *d) { //单步rehash
if (d->iterators == 0) dictRehash(d,1); //当迭代器数量不为0,才能进行1步rehash
}
int dictRehash(dict *d, int n) { //n步进行rehash
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0; //只有rehashidx不等于-1时,才表示正在进行rehash,否则返回0
while(n-- && d->ht[0].used != 0) { //分n步,而且ht[0]上还有没有移动的节点
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
//确保rehashidx没有越界,因为rehashidx是从-1开始,0表示已经移动1个节点,它总是小于hash表的size的
assert(d->ht[0].size > (unsigned long)d->rehashidx);
//第一个循环用来更新 rehashidx 的值,因为有些桶为空,所以 rehashidx并非每次都比原来前进一个位置,而是有可能前进几个位置,但最多不超过 10。
//将rehashidx移动到ht[0]有节点的下标,也就是table[d->rehashidx]非空
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx]; //ht[0]下标为rehashidx有节点,得到该节点的地址
/* Move all the keys in this bucket from the old to the new hash HT */
//第二个循环用来将ht[0]表中每次找到的非空桶中的链表(或者就是单个节点)拷贝到ht[1]中
while(de) {
unsigned int h;
nextde = de->next; //备份下一个节点的地址
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask; //获得计算哈希值并得到哈希表中的下标h
//将该节点插入到下标为h的位置
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
//更新两个表节点数目计数器
d->ht[0].used--;
d->ht[1].used++;
//将de指向以一个处理的节点
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL; //迁移过后将该下标的指针置为空
d->rehashidx++; //更新rehashidx
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) { //ht[0]上已经没有节点了,说明已经迁移完成
zfree(d->ht[0].table); //释放hash表内存
d->ht[0] = d->ht[1]; //将迁移过的1号哈希表设置为0号哈希表
_dictReset(&d->ht[1]); //重置ht[1]哈希表
d->rehashidx = -1; //rehash标志关闭
return 0; //表示前已完成
}
/* More to rehash... */
return 1; //表示还有节点等待迁移
}
6. 迭代器
redis在字典结构也定义了迭代器
typedef struct dictIterator {
dict *d; //被迭代的字典
long index; //迭代器当前所指向的哈希表索引位置
int table, safe; //table表示正迭代的哈希表号码,ht[0]或ht[1]。safe表示这个迭代器是否安全。
dictEntry *entry, *nextEntry; //entry指向当前迭代的哈希表节点,nextEntry则指向当前节点的下一个节点。
/* unsafe iterator fingerprint for misuse detection. */
long long fingerprint; //避免不安全迭代器的指纹标记
} dictIterator;
迭代器分为安全迭代器和不安全迭代器:
- 非安全迭代器只能进行Get等读的操作, 而安全迭代器则可以进行iterator支持的任何操作。
- 由于dict结构中保存了safe iterators的数量,如果数量不为0, 是不能进行下一步的rehash的; 因此安全迭代器的存在保证了遍历数据的准确性。
- 在非安全迭代器的迭代过程中, 会通过fingerprint方法来校验iterator在初始化与释放时字典的hash值是否一致; 如果不一致说明迭代过程中发生了非法操作.