Redis中的链表包括list、ziplist、quicklist三种,list常用来内部操作,ziplist和quicklist用来存储KV,也就是lpush、rpush等命令形成的对象。
list设计与实现
list的设计分为三部分:链表节点、迭代器、链表。这三部分示意如下:
typedef struct listNode {
// 双向链表
struct listNode *prev;
struct listNode *next;
// 链表的值
void *value;
} listNode;
typedef struct listIter {
listNode *next;
// 迭代方向
int direction;
} listIter;
typedef struct list {
// 链表的收尾节点
listNode *head;
listNode *tail;
// 链表节点复制函数
void *(*dup)(void *ptr);
// 链表节点释放函数
void (*free)(void *ptr);
// 链表节点比较函数
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
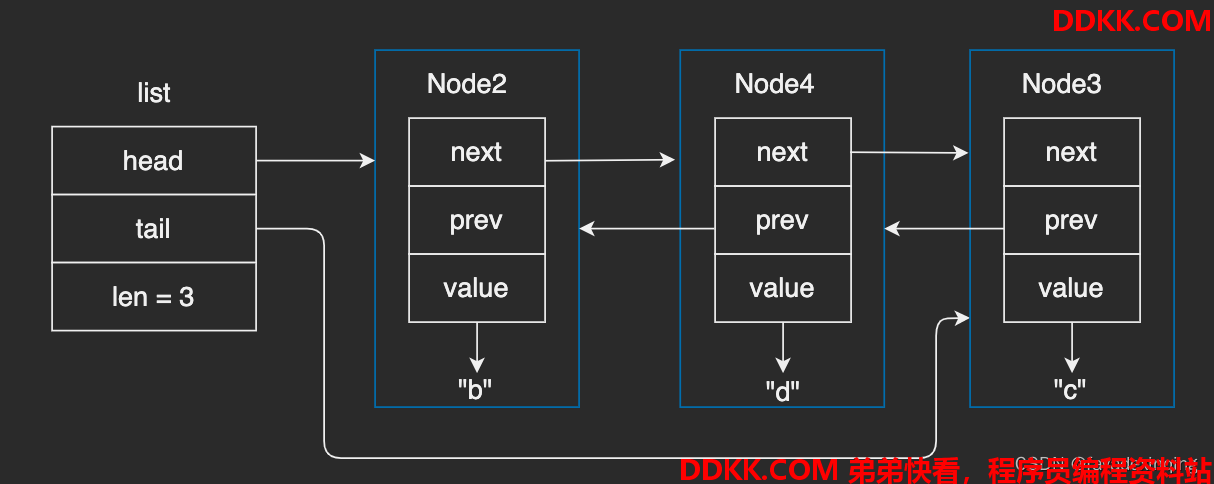
链表的API都很简单,示意图如下:
调用listCreate,创建一个空链表:

调用listAddNodeHead,插入一个字符串"a":
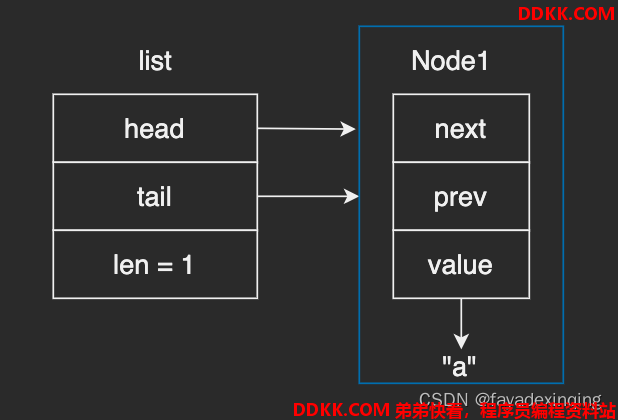
调用listAddNodeHead,插入一个字符串"b":
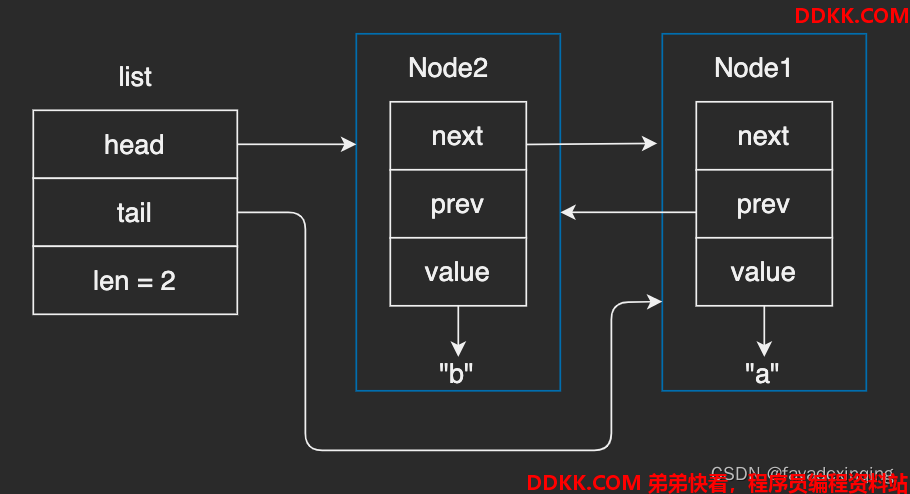
调用listAddNodeTail,插入一个字符串"c":
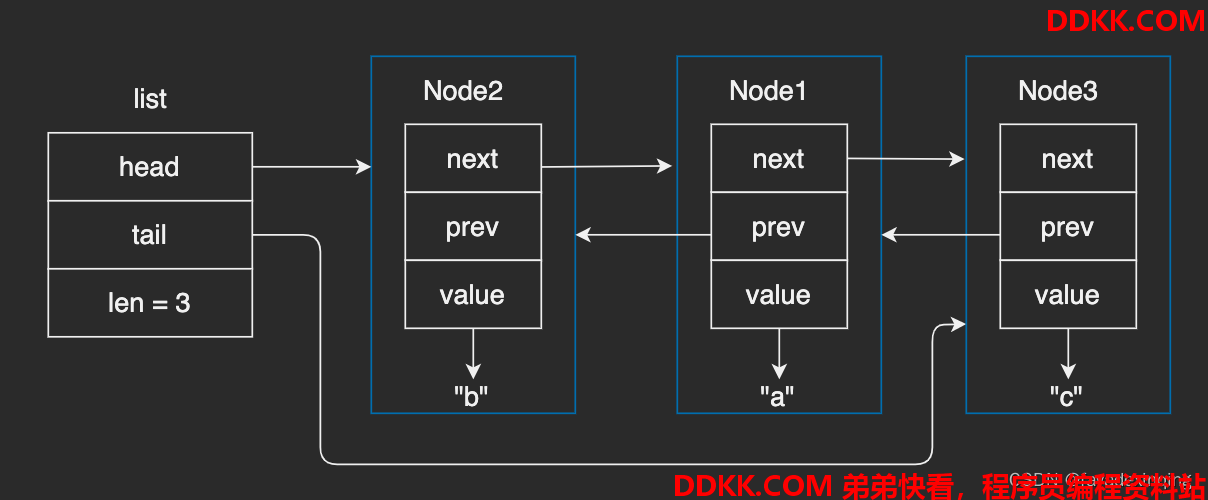
调用listInsertNode,在"b"后面插入一个字符串"d":
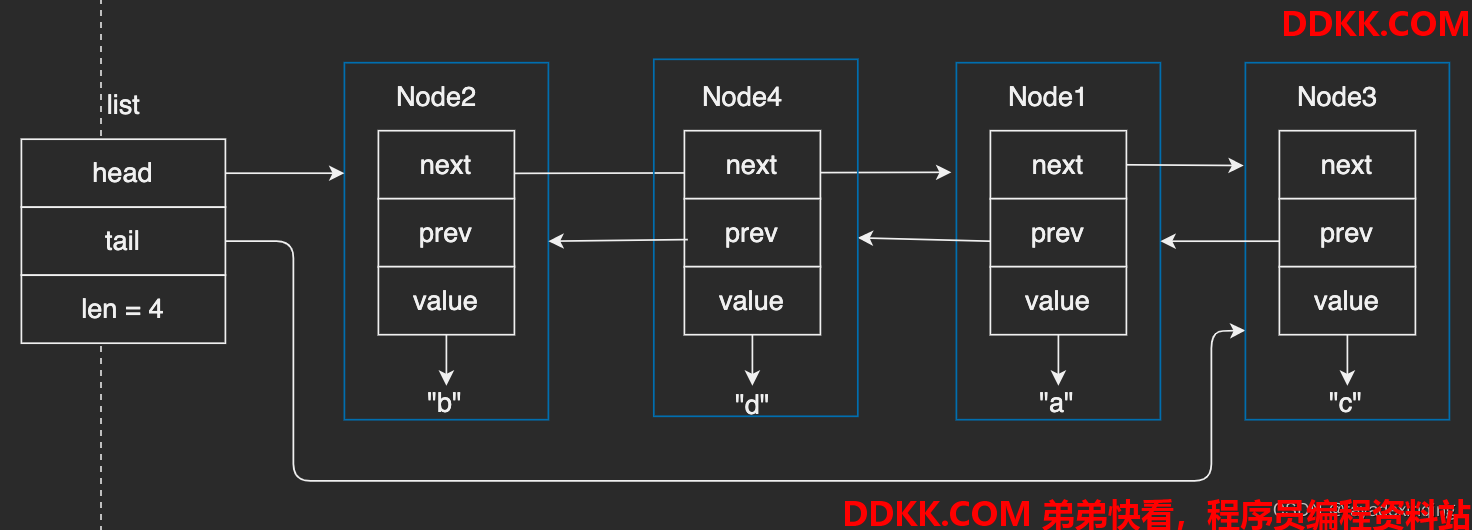
调用listDelNode,删除节点"a":
迭代器的API:
1、 申请迭代器;
2、 调用listNext,如果向后遍历,取节点的next,直到NULL;如果向前遍历,取节点的prev,直到NULL;
在Redis5.0版本之前,list也会存储KV,但是在Redis5.0版本之后,被quicklist取代,主要原因还是内存,一个list节点包含前后连个指针,在64位机器上,就占用16byte的内存。
ziplist设计与实现
ziplist为内存紧凑链表,占用一整块连续的内存空间,ziplist的设计在ziplist.c的注释中说明的很清楚,这里翻译一下:
一个ziplist的内存布局:

一个ziplist的额外内存占用为4+4+2+1 = 11byte
其中entry的内部布局:

prevlen:前一个entry内存量,用来从ziplist后往前遍历;如果prevlen < 254,则占用1byte;否则占用5byte,其中最高byte固定为254,后面4byte表示真正的前一个entry内存量
encoding:编码方式,对于字符串和整数有不同的编码方式:
1、 |00pppppp|-长度不超过63的字符串(6bits),低6bit表示字符串长度;
2、 |01pppppp|qqqqqqqq|-长度不超过16383的字符串(14bits),低14bit表示字符串长度;
3、 |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt|-长度大于16384的字符串,只有低4byte表示字符串长度;
4、 |11000000|-编码为int16_t的整数(2byte);
5、 |11010000|-编码为int32_t的整数(4byte);
6、 |11100000|-编码为int64_t的整数(8byte);
7、 |11110000|-编码为24bit的整数(3byte);
8、 |11111110|-编码为8bit的整数(1byte);
9、 |1111xxxx|-xxxx在0000和1101之间,编码为4bit的整数;
10、 |11111111|-zl结束标志符;
entry的额外内存在prevlen和encoding上,最大为5+5=10byte,通常情况下为1+1=2byte,小于list中单个节点额外的16byte,同时为了节省内存,对于长度不同的数据,都有不同的编码方式,尤其对于prevlen的解释。
这样做虽然使得内存更加紧凑,节省内存,但是也存在一些缺点:
1、 添加节点、更新节点、删除节点等操作增加了很多复杂性;
2、 由于是一块内存,不可避免的需要很多memcpy、realloc等内存拷贝和分配操作,比如:在entryB之前插入entryA,entryB会更新自己的prevlen,有可能使得prevlen从1byte变成5byte,这样整体会重新分配一次内存,同时调用memcpy;如果entryB更新prevlen,导致在entryB之后的entryC也更新了prevlen,如果再次从1byte变成5byte,就会产生级联更新删除节点也有类似的风险;
3、 ziplist在查找时,需要遍历然后比较,时间复杂度是O(n);
基于以上原因,ziplist存储的entry数量不可能太多。Redis中存储list时,起初采用ziplist存储,当entry数量超过阈值时,会转化为quicklist。
quicklist设计与实现
quicklist结合了list和ziplist的优点,在节省内存的同时,简化了ziplist的插入、删除等操作,一定程度上可以避免连锁更新,其总体设计类似于std::deque。与list一样,分为三部分:节点、迭代器、链表,三部分的代码如下:
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
typedef struct quicklistIter {
const quicklist *quicklist;
quicklistNode *current;
unsigned char *zi;
long offset; /* offset in current ziplist */
int direction;
} quicklistIter;
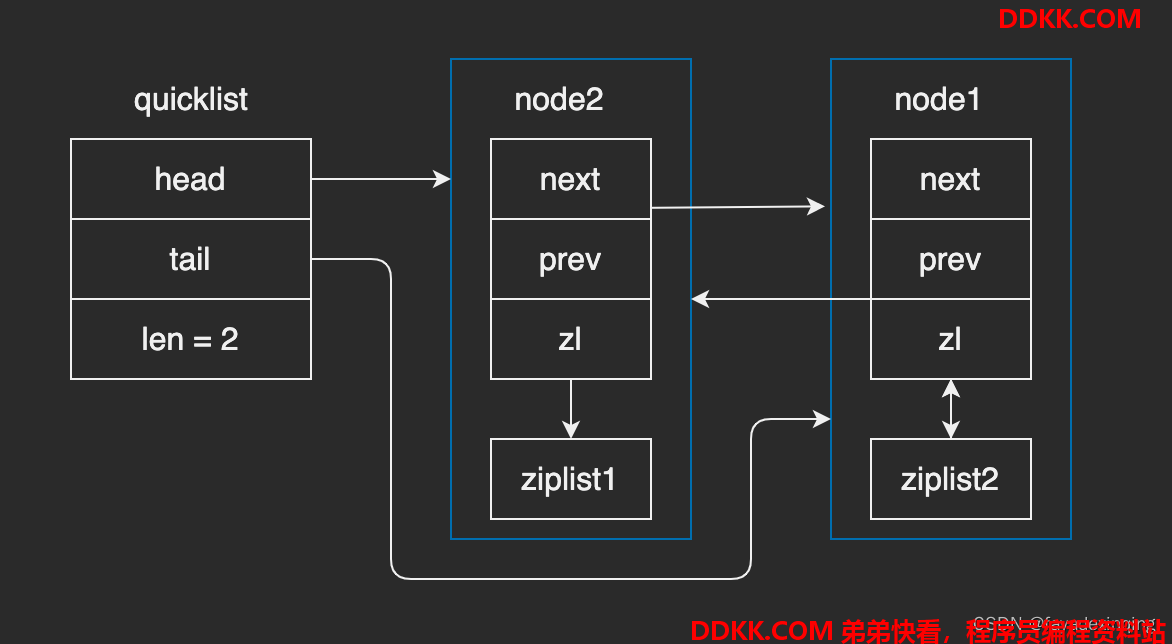
可以看出:
- quicklistNode就是一个ziplist,同时加入prev、next前后指针将其串联到quicklist中
- 每个quicklist中维护首尾节点
- 本质上quicklist和list结构一样,只不过每个节点是一个ziplist
- 另外quicklist支持节点压缩,当quicklist中的节点数量超过quicklist::compress规定的长度时,就会将quicklist中的中间节点压缩,以此来节省空间;但是需要读取节点内容时,会增加一次解压的代价。
- quicklist::fill用来控制扇出,当插入的entry总大小超过这个阈值时,需要新建quicknode,这样一定程度上可以避免连锁更新
quicklist的API较多,以插入节点为例:
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head;
if (likely(
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
// 判断是否可以在当前节点中插入entry
quicklist->head->zl =
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(quicklist->head);
} else {
// 新建quicklistnode插入
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(node);
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
quicklist->count++;
quicklist->head->count++;
return (orig_head != quicklist->head);
}
_quicklistNodeAllowInsert会计算新插入元素后的大小,判断该大小是否满足quicklist::fill扇出要求
REDIS_STATIC int _quicklistNodeAllowInsert(const quicklistNode *node,
const int fill, const size_t sz) {
if (unlikely(!node))
return 0;
int ziplist_overhead;
/* size of previous offset */
// 计算ziplist中的prevlen
if (sz < 254)
ziplist_overhead = 1;
else
ziplist_overhead = 5;
/* size of forward offset */
// 计算ziplist中的encoding增加长度
if (sz < 64)
ziplist_overhead += 1;
else if (likely(sz < 16384))
ziplist_overhead += 2;
else
ziplist_overhead += 5;
/* new_sz overestimates if 'sz' encodes to an integer type */
unsigned int new_sz = node->sz + sz + ziplist_overhead;
// 判断是否满足quicklist::fill的要求
if (likely(_quicklistNodeSizeMeetsOptimizationRequirement(new_sz, fill)))
return 1;
else if (!sizeMeetsSafetyLimit(new_sz))
return 0;
else if ((int)node->count < fill)
return 1;
else
return 0;
}