数据类型
字符串常量用单引号括起来,表示Unicode时前面要加一个N。
按类型分
普通字符(单字节):CHAR、VARCHAR
Unicode字符(双字节):NCHAR、NVARCHAR
按是否变长分
固定长度:CHAR、NCHAR
(对于固定长度的,定义是多长就会留出多长的空间)
可变长度:VARCHAR、NVARCHAR
(对于变长的,按字符串实际长度保存数据,外加两个额外字节保存数据的偏移值,定义长度只代表最大不超过这么长)
变长的消耗存储空间更少,所以读操作更快,但对其更新时可能要进行扩展导致数据移动,故更新效率较低。
排序规则
注意排序规则不仅印象排序,也影响比较时是否认为是同一个东西。可以在四种级别上定义排序规则:SQL Server实例、数据库、列、表达式。
实例的排序规则在安装时决定,数据库的排序规则可以在创建时用COLLATE子句指定,列的排序规则可以在定义时用COLLATE子句指定,表达式的排序规则可以用COLLATE子句修改。否则都使用实例的排序规则。
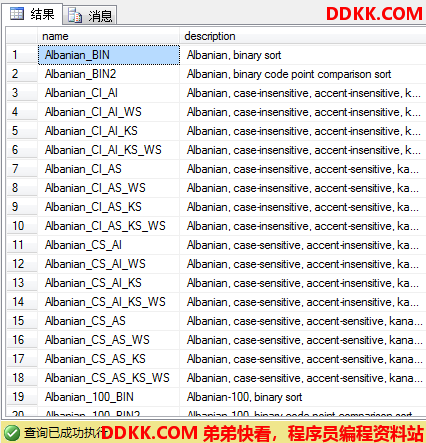
查看所有的排序规则及其描述:
SELECT name,description
FROM sys.fn_helpcollations();
表达式测试(比较时默认不区分大小写):
USE MyDB;
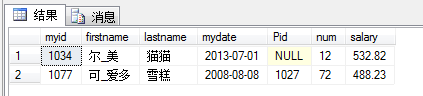
SELECT firstname,myid
FROM dbo.ok
WHERE firstname=N'eMmm尔美';
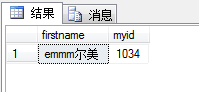
用COLLATE子句修改表达式排序规则后:
USE MyDB;
SELECT firstname,myid
FROM dbo.ok
WHERE firstname
COLLATE Latin1_General_CS_AS
=N'eMmm尔美';
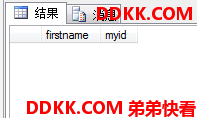
因为区分了大小写所以得到了空表。
运算符和函数
串联字符串
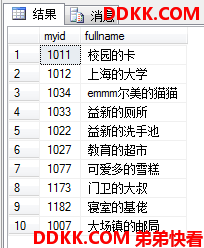
USE MyDB;
SELECT myid,
firstname+N'的'+lastname AS fullname
FROM dbo.ok;
接下来新建一张表做实验:
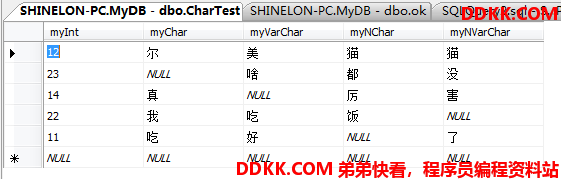
将NULL变成空字符串
如果对这张表尝试四个列字符串合并输出:
USE MyDB;
SELECT myChar+myVarChar+myNChar+myNVarChar AS sumChar
FROM dbo.CharTest;
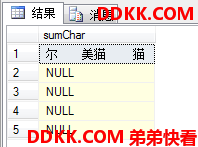
出现NULL值的整个都是NULL了。
可以使用COALESCE函数,这个函数接受一系列输入值,返回第一个不为NULL的值:
USE MyDB;
SELECT myChar+myVarChar+COALESCE(myNChar,N'')+myNVarChar AS sumChar
FROM dbo.CharTest;
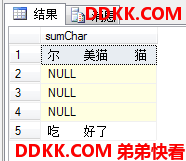
可以看到这一类的NULL被替换成了空字符串。
另外一种不推荐的方式是,修改SQL Server的标准行为:
SET CONCAT_NULL_YIELDS_NULL OFF; --改变处理串联的方式(执行后NULL视为空串)
USE MyDB;
SELECT myChar+myVarChar+myNChar+myNVarChar AS sumChar
FROM dbo.CharTest;
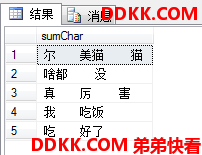
不建议任何修改SQL Server标准行为的行为!修改回来:
SET CONCAT_NULL_YIELDS_NULL ON; --改回来
SUBSTRING和LEFT和RIGHT
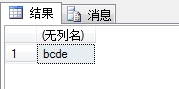
SELECT SUBSTRING('abcdefghi',2,4); --从第2个开始向后4个
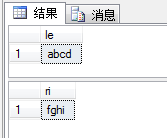
SELECT LEFT('abcdefghi',4) AS le; --从左4个
SELECT RIGHT('abcdefghi',4) AS ri; --从右4个
LEN和DATALENGTH
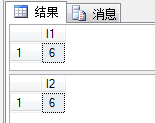
SELECT LEN('我lzh胖虎') AS l1; --字符数
SELECT LEN(N'我lzh胖虎') AS l2; --字符数
SELECT DATALENGTH('我lzh胖虎') AS l1; --字节数
SELECT DATALENGTH(N'我lzh胖虎') AS l2; --字节数
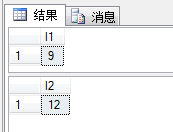
可以看到Unicode里英文字母也要占2个字节。
CHARINDEX
在第二个参数中找第一个参数第一次出现的位置,第三个参数指定从哪里开始查(默认从头部查)。
SELECT CHARINDEX('ok','e啊哇ok但也不ok吗');
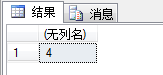
SELECT CHARINDEX('ok','e啊哇ok但也不ok吗',5);
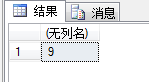
PATINDEX
在第二个参数中找第一个参数指定的模式第一次出现的位置。
SELECT PATINDEX('%ok%','e啊哇ok但也不ok吗');
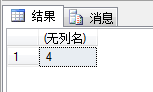
REPLACE
将字符串中出现的所有某个字符串替换为另一个字符串。
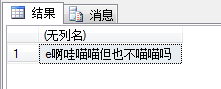
SELECT REPLACE('e啊哇ok但也不ok吗','ok','喵喵');
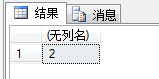
可用来计算某个子串出现的次数:
SELECT (
LEN('e啊哇ok但也不ok吗')
-LEN(REPLACE('e啊哇ok但也不ok吗','ok',''))
)/
LEN('ok');
REPLICATE
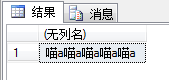
以指定的次数复制字符串。
SELECT REPLICATE('喵a',5);
STUFF
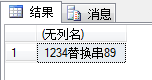
在第一个参数串中删除从第二个参数开始,第三个参数长度的子串,然后将第四个参数串插到这个位置。
SELECT STUFF('123456789',5,3,'替换串');
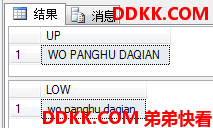
UPPER和LOWER
大小写转换。
SELECT UPPER('Wo PangHu DaQian') AS UP;
SELECT LOWER('Wo PangHu DaQian') AS LOW;
LIKE谓词使用的通配符
在我的Linux笔记里学了Shell是少有的具有通配符这个概念的语言,这里SQL也是一个具有通配符概念的语言。注意通配符是完全匹配,在学Linux时强调过这点!因为之前学过了,用法都是一样的,具体通配符是哪个可能不同,这里就只画个表不实验了。
通配符表
| 通配符 | 意义 |
|---|---|
| % | 任意长度的字符串 |
| _ | 任意一个字符 |
| [] | 匹配其内任意一个字符 |
| [-] | 匹配一个范围内任意一个字符 |
| [^] | 匹配不属于其内的任意一个字符 |
ESCAPE转义
和Shell不同,SQL的转义字符是自己设定的。用ESCAPE子句设定一个确保不会在数据中出现的字符作转义字符,然后就可以用它后面跟着特殊字符(如% _ [ ])让它失去特殊意义以匹配其本身了。
USE MyDB;
SELECT *
FROM dbo.ok
WHERE firstname LIKE N'%!_%' ESCAPE '!'; --用'!'作为转义符对'_'转义