查询语句中,FROM是逻辑上最先处理的,在FROM子句中可以用表运算符对输入的表进行操作,它们有:
| 表运算符 | 标准 |
|---|---|
| JOIN | ANSI标准 |
| APPLY | T-SQL对标准的扩展 |
| PIVOT | T-SQL对标准的扩展 |
| UNPIVOT | T-SQL对标准的扩展 |
这节只学习JOIN和三种联结,它们有:
| 联结类型 | 步骤 |
|---|---|
| 交叉联结 | 笛卡尔积 |
| 内联结 | 笛卡尔积->过滤 |
| 外联结 | 笛卡尔积->过滤->添加外部行 |
先建立两张表实验用:
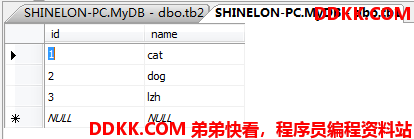
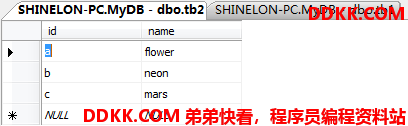
(注意操作多个表时,如果在FROM里指定了别名,那么在SELECT里应用别名.列名,否则应用表名.列名的方式,避免产生歧义!)
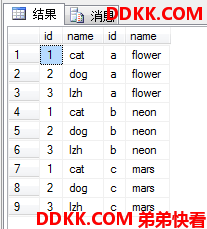
交叉联结
就是对两个表做笛卡尔积,也就是一个表中每一行都要和另一个表中每一行结合在一起成为新的行。
注意以下的语法演示中为了突出语法,SELECT了全部(*),实际上这样SQL Server解析要有开销,实际用时不这样做,并且因为用了全部(*),我也没有指定别名,也没有用表名.列名的方式,这样并不好。
ANSI SQL-92语法(推荐)
USE MyDB;
SELECT *
FROM dbo.tb1
CROSS JOIN dbo.tb2; --交叉联结(CROSS JOIN)
ANSI SQL-89语法(不推荐)
USE MyDB;
SELECT *
FROM dbo.tb1,
dbo.tb2; --交叉联结(只用一个逗号)

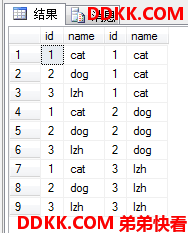
自交叉联结
对同一个表自己进行交叉联结,这次用规范的写法来演示:
USE MyDB;
SELECT
B1.id,B1.name,
B2.id,B2.name
FROM dbo.tb1 AS B1
CROSS JOIN dbo.tb1 AS B2;
内联结
先做笛卡尔积,然后用用户指定的谓词进行过滤。
ANSI SQL-92语法(推荐)
USE MyDB;
SELECT *
FROM dbo.tb1 AS E1
JOIN dbo.tb2 AS E2
ON E1.id+ASCII('a')-1=ASCII(E2.id); --用了ON子句
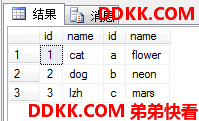
注意!ON子句也只接受TRUE,拒绝FASLE和UNKNOWN。
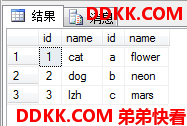
ANSI SQL-89语法(不推荐)
USE MyDB;
SELECT *
FROM dbo.tb1 AS E1,dbo.tb2 AS E2
WHERE E1.id+ASCII('a')-1=ASCII(E2.id); --ANSI SQL-89没有ON子句
为什么推荐ANSI SQL-92?
如果想写一条内联结,忘记指定联结条件,ANSI SQL-92语法会报错:
USE MyDB;
SELECT *
FROM dbo.tb1
JOIN dbo.tb2;
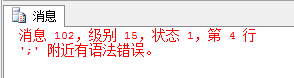
而使用ANSI SQL-89则完全会变成交叉联结:
USE MyDB;
SELECT *
FROM dbo.tb1,
dbo.tb2;
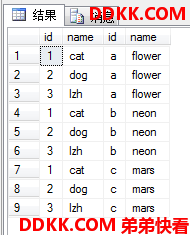
前者是语法分析器就能告知的错误,后者则完全成了逻辑错误,这就非常危险了,因为得到的数据是错的自己还可能不知道。所以推荐用ANSI SQL-92做内联结,至于交叉联结,出于一致性也推荐用ANSI SQL-92标准。
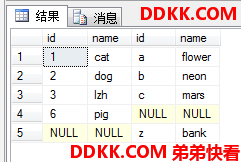
外联结
外联结是ANSI SQL-92中才被引入的。
先在表中分别添加一行和另一个表没什么关系(这个关系是前面用的那个ASCII偏移值)的行:
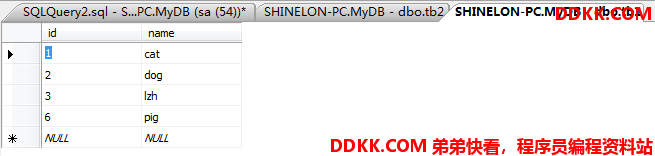
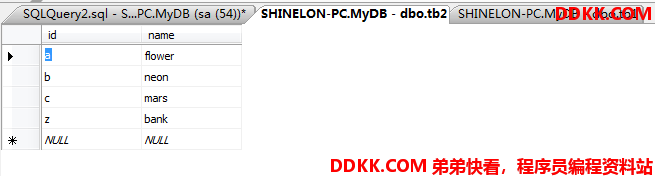
外联结用
LEFT/RIGHT/FULL [OUTER] JOIN
这样的格式,OUTER写不写都行。
其中LEFT表示左边的表示保留的,RIGHT表示右边的表是保留的,FULL表示两个表都是保留的。
首先对两个表先作内联结(笛卡尔积->过滤),然后对于保留表中按照ON条件在另一个表中完全匹配不到行的那些保留表中的行,强制追加一个行,但这些追加行毕竟没有匹配,所以行中来自另一表中的那些列被置为NULL。
USE MyDB;
SELECT *
FROM dbo.tb1 AS E1
LEFT JOIN dbo.tb2 AS E2 --左外
ON E1.id+ASCII('a')-1=ASCII(E2.id);
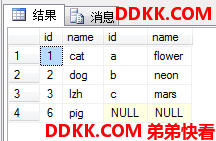
USE MyDB;
SELECT *
FROM dbo.tb1 AS E1
RIGHT JOIN dbo.tb2 AS E2 --右外
ON E1.id+ASCII('a')-1=ASCII(E2.id);
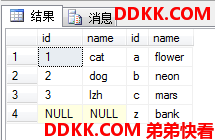
USE MyDB;
SELECT *
FROM dbo.tb1 AS E1
FULL JOIN dbo.tb2 AS E2 --全外
ON E1.id+ASCII('a')-1=ASCII(E2.id);