说是集合运算,实际上可能不是真正意义上的集合,因为查询结果可能包含重复的记录,所以可能不满足集合的元素互异性,但还是使用这样的称呼吧!
基本格式
输入的查询1
<集合运算>
输入的查询2
[ORDER BY子句]
可以看到是对两个查询的结果集,用中间的集合运算来判断每一行是否要包含在运算结果里,并可以用最后的ORDER BY子句对结果集进行排序。
注意,集合(虽然这里是多集,没有互异性)是有无序性的,所以两个被操作的集合(查询)是不能包含ORDER BY子句的,而最后的外部的ORDER BY子句也仅仅是对最终结果集排序输出而已。
此外,参与集合运算的两个查询生成的集合必须包含相同的列数,且相应的列数据类型兼容。
ANSI SQL对以下的每种集合运算都支持DISTINCT和ALL选项。前者对输入的两个多集消除重复行成为真正的集合再参与运算,结果也是集合;后者则不这样做,而仅仅是用两个多集来做运算,结果也是多集。在集合运算里DISTINCT是隐式的,不要写出来。
先建立两张表用来实验:
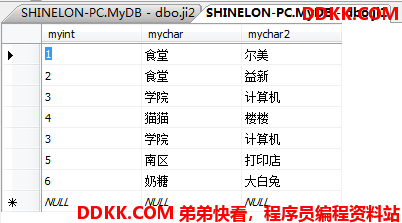
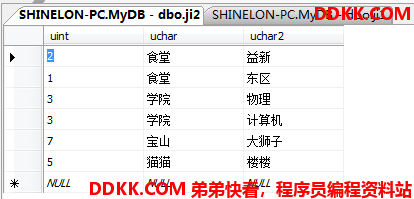
并集运算
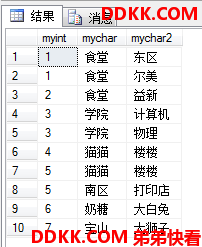
UNION ALL
直接返回两个多集的所有行为结果集,不会进行比较,也不会删除重复行。
USE MyDB;
SELECT * FROM dbo.ji1
UNION ALL
SELECT * FROM dbo.ji2;

UNION(隐含DISTINCT)
这个运算会先把两个多集去重变成集合,然后对集合做并集运算,返回的当然也是集合,不会有重复行。
USE MyDB;
SELECT * FROM dbo.ji1
UNION
SELECT * FROM dbo.ji2;
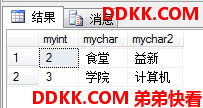
交集运算
INTERSECT(隐含DISTINCT)
这个运算会先把两个多集去重变成集合,然后对集合做交集运算,返回的也是集合。
USE MyDB;
SELECT * FROM dbo.ji1
INTERSECT
SELECT * FROM dbo.ji2;
INTERSECT ALL的替代方案
ANSI SQL支持带ALL的INTERSECT运算,意思是对两个多集中产生交集的行,取各自的重复次数中较小的那个(也就是逻辑上只相交了这么多次)。
但SQL Server 2008还没有实现这种运算,下面给出一种替代方案:
用开窗函数对两张多集的表利用要生成集合的列进行分区,得到的就是每个相同元素在一个区里,然后进行排序得到一个区内的行号,并将这个号作为一个新的列。这样,原本区分不开的相同元素就因为这个区内行号的不同而区分开了,这时候,利用普通的INTERSECT就可以得到那些元素相同而且行号相同的了(如123456和1234编号的做普通交集得到的就是1234的,符合前面的要求)。注意ORDER BY子句里SELECT常量表示行的排列顺序不重要。
USE MyDB;
SELECT
ROW_NUMBER()
OVER(
PARTITION BY myint,mychar,mychar2
ORDER BY (SELECT 0)
) AS rownum,
myint,mychar,mychar2
FROM dbo.ji1
INTERSECT
SELECT
ROW_NUMBER()
OVER(
PARTITION BY uint,uchar,uchar2
ORDER BY (SELECT 0)
) AS rownum,
uint,uchar,uchar2
FROM dbo.ji2;
这个例子不太好没能凸显出和刚才那个非ALL的结果的区别。
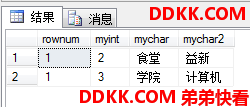
然后只要把整个查询上定义一个表表达式(上一节学了),比如CTE,就可以去掉行号了:
USE MyDB;
--下面定义成了一个CTE
WITH INS_ALL
AS
(
SELECT
ROW_NUMBER()
OVER(
PARTITION BY myint,mychar,mychar2
ORDER BY (SELECT 0)
) AS rownum,
myint,mychar,mychar2
FROM dbo.ji1
INTERSECT
SELECT
ROW_NUMBER()
OVER(
PARTITION BY uint,uchar,uchar2
ORDER BY (SELECT 0)
) AS rownum,
uint,uchar,uchar2
FROM dbo.ji2
)
--从这个CTE里取出需要的列,就去掉行号了
SELECT myint,mychar,mychar2
FROM INS_ALL;
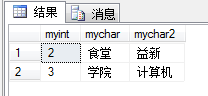
差集运算
EXCEPT(隐含DISTINCT)
同样是先把多集变成集合,然后对集合做差集运算,差集A-B意思就是出现在A中而不出现在B中的那些元素。
USE MyDB;
SELECT * FROM dbo.ji1
EXCEPT
SELECT * FROM dbo.ji2;
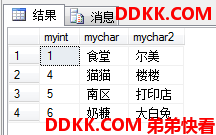
EXCEPT ALL的替代方案
ANSI SQL支持带ALL的EXCEPT运算,意思是对两个多集中产生交集的行,如果在前一个集合中出现x次,在后一个集合中出现y次,而且x>y,那么在运算结果中这个行将出现x-y次(也就是逻辑上不在后者中发生碰撞的前者中的那些行)。
但SQL Server 2008还没有实现这种运算,下面给出一种替代方案:
和刚才学的INTERSECT ALL的替代方案思想是一样的,只要给重复行开窗成为一个区,然后区内赋予行号,再将这样的两个集合(这回有了区内唯一行号肯定不是多集了)进行普通的EXCEPT运算,如123456和1234号得到的肯定是56号的,就实现了EXCEPT ALL的替代。下面同样还是扔进CTE里然后最后去除行号。
USE MyDB;
--下面定义成了一个CTE
WITH INS_ALL
AS
(
SELECT
ROW_NUMBER()
OVER(
PARTITION BY myint,mychar,mychar2
ORDER BY (SELECT 0)
) AS rownum,
myint,mychar,mychar2
FROM dbo.ji1
EXCEPT
SELECT
ROW_NUMBER()
OVER(
PARTITION BY uint,uchar,uchar2
ORDER BY (SELECT 0)
) AS rownum,
uint,uchar,uchar2
FROM dbo.ji2
)
--从这个CTE里取出需要的列,就去掉行号了
SELECT myint,mychar,mychar2
FROM INS_ALL;
这次还是很明显的,多了一行<计算机>,因为在第一个多集中出现了2次,在第二个多集中出现了1次,所以最后要有2-1=1次。
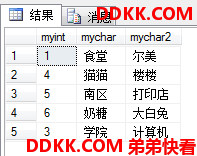
集合运算的优先级
INTERSECT的优先级比UNION和EXCEPT的高,UNION和EXCEPT的优先级相等。所以先处理INTERSECT,然后按从左到右的顺序依次处理优先级相同的后两者。
USE MyDB;
SELECT * FROM dbo.ji1
UNION ALL
SELECT * FROM dbo.ji2
INTERSECT
SELECT * FROM dbo.ji1;

为楼楼默哀。