负载均衡
看源码主要看这几个问题:
- 负载均衡策略什么时候获取到到
- 负载均衡前的准备过程
- 负载均衡四种策略解析
1. 获取负载均衡策略
负载均衡策略到获取,也是在消费者远程调用的过程中:
org.apache.dubbo.rpc.proxy.InvokerInvocationHandler#invoke
org.apache.dubbo.rpc.cluster.support.wrapper.MockClusterInvoker#invoke
org.apache.dubbo.rpc.cluster.support.AbstractClusterInvoker#invoke
//org.apache.dubbo.rpc.cluster.support.AbstractClusterInvoker#invoke
public Result invoke(final Invocation invocation) throws RpcException {
checkWhetherDestroyed();
// binding attachments into invocation.
Map<String, String> contextAttachments = RpcContext.getContext().getAttachments();
if (contextAttachments != null && contextAttachments.size() != 0) {
((RpcInvocation) invocation).addAttachments(contextAttachments);
}
// 服务路由
List<Invoker<T>> invokers = list(invocation);
// 获取负载均衡策略
LoadBalance loadbalance = initLoadBalance(invokers, invocation);
RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation);
return doInvoke(invocation, invokers, loadbalance);
}
核心代码就在initLoadBalance,比较简单,SPI的方式:
//org.apache.dubbo.rpc.cluster.support.AbstractClusterInvoker#initLoadBalance
protected LoadBalance initLoadBalance(List<Invoker<T>> invokers, Invocation invocation) {
if (CollectionUtils.isNotEmpty(invokers)) {
//DEFAULT_LOADBALANCE = "random",默认加权随机算法
return ExtensionLoader.getExtensionLoader(LoadBalance.class).getExtension(invokers.get(0).getUrl().getMethodParameter(RpcUtils.getMethodName(invocation), LOADBALANCE_KEY, DEFAULT_LOADBALANCE));
} else {
return ExtensionLoader.getExtensionLoader(LoadBalance.class).getExtension(DEFAULT_LOADBALANCE);
}
}
2. 负载均衡前的准备过程(粘连接的处理)
获取到以后,继续跟doInvoke方法,默认容错走的是FailoverClusterInvoker:
//org.apache.dubbo.rpc.cluster.support.FailoverClusterInvoker#doInvoke
public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
...
// 用于存放所有被调用过的invoker(局部变量)
// 该集合用于重试时,该集合中存放的一定是有问题的invoker
List<Invoker<T>> invoked = new ArrayList<Invoker<T>>(copyInvokers.size()); // invoked invokers.
...
for (int i = 0; i < len; i++) {
...
// 负载均衡
Invoker<T> invoker = select(loadbalance, invocation, copyInvokers, invoked);
// 将选择到的invoker添加到已经使用的列表invoked
invoked.add(invoker);
RpcContext.getContext().setInvokers((List) invoked);
try {
// 远程调用
Result result = invoker.invoke(invocation);
...
return result;
} catch (RpcException e) {
...
} catch (Throwable e) {
le = new RpcException(e.getMessage(), e);
} finally {
providers.add(invoker.getUrl().getAddress());
}
} // end-for
...
}
负载均衡的逻辑就在select(loadbalance, invocation, copyInvokers, invoked)方法中,其中有一个注意点,invoked集合存放了一次请求中所有被调用过的invoker(局部变量),新的请求来了invoked又是一个新的集合,这个集合专门用于容错机制的重试的,该集合中的invoker肯定是这次请求中调用失败过的invoker:
protected Invoker<T> select(LoadBalance loadbalance, Invocation invocation,
List<Invoker<T>> invokers, List<Invoker<T>> selected) throws RpcException {
// 若invoker集合为空,则直接结束
if (CollectionUtils.isEmpty(invokers)) {
return null;
}
// 获取远程调用的方法名
String methodName = invocation == null ? StringUtils.EMPTY : invocation.getMethodName();
// 获取该方法的sticky属性
// DEFAULT_CLUSTER_STICKY = false,默认不是粘连接
boolean sticky = invokers.get(0).getUrl()
.getMethodParameter(methodName, CLUSTER_STICKY_KEY, DEFAULT_CLUSTER_STICKY);
//ignore overloaded method
// 若缓存中的stickyInvoker不为空,说明该invoker刚被使用过,
// 但invokers列表中又没有该invoker,则说明该invoker在被使用过后宕机、或者被路由排除掉了等情况
if (stickyInvoker != null && !invokers.contains(stickyInvoker)) {
stickyInvoker = null;
}
//ignore concurrency problem
// 若开启了粘连连接,且stickyInvoker也不空,且selected中不包含这个invoker(注意,selected集合中
// 存放的都是有问题的invoker),则在stickyInvoker可用的前提下,就不用再做负载均衡了,直接返回这个
// 粘连的stickyInvoker即可
if (sticky && stickyInvoker != null && (selected == null || !selected.contains(stickyInvoker))) {
// availablecheck为true则检测stickyInvoker的可用性
if (availablecheck && stickyInvoker.isAvailable()) {
return stickyInvoker;
}
}
// 负载均衡选择一个invoker
Invoker<T> invoker = doSelect(loadbalance, invocation, invokers, selected);
if (sticky) {
stickyInvoker = invoker;
}
return invoker;
}
即该方法主要在处理粘连接的逻辑,具体负载均衡的实现在doSelect中。
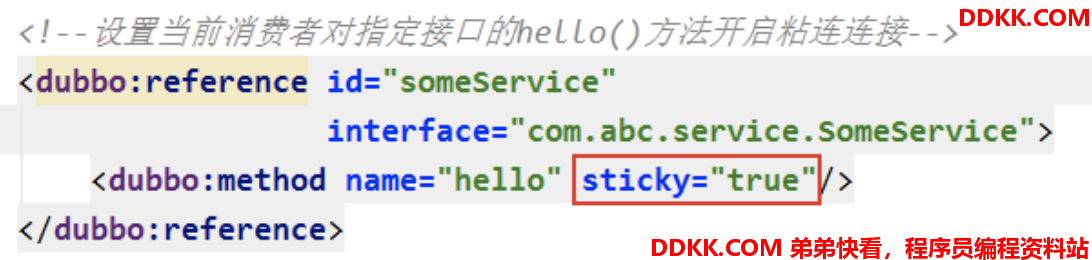
粘连连接(可以理解为简易版的路由)
所谓粘连连接是指,让所有客户端要访问的同一接口的同一方法,尽可能是的由同一Inovker 提供服务。其用于限定流向。粘连连接仅能设置在消费者端,其可以设置为接口级别,也可以设置为方法级别。方法级别是,仅该方法启用粘连连接。接口级别则是指,接口中每一个方法均启用了粘连连接,不用再逐个方法设置了。
仅作用于 Dubbo 服务暴露协议。用于减少长连接数量。粘连连接的开启将自动开启延迟连接。

继续看doSelect方法:
//org.apache.dubbo.rpc.cluster.support.AbstractClusterInvoker#doSelect
private Invoker<T> doSelect(LoadBalance loadbalance, Invocation invocation,
List<Invoker<T>> invokers, List<Invoker<T>> selected) throws RpcException {
if (CollectionUtils.isEmpty(invokers)) {
return null;
}
// 若只有一个invoker,则直接返回即可,无需再负载均衡
if (invokers.size() == 1) {
return invokers.get(0);
}
// 负载均衡
Invoker<T> invoker = loadbalance.select(invokers, getUrl(), invocation);
//If the invoker is in the selected or invoker is unavailable && availablecheck is true, reselect.
// 若选择出的invoker包含在selected集合中,则说明该invoker有问题,之前调用失败过
// 或者选择出的这个invoker在进行单独可用性检测时,发现不可用,
// 若出现以上两种情况,则进行重新负载均衡选择
if ((selected != null && selected.contains(invoker))
|| (!invoker.isAvailable() && getUrl() != null && availablecheck)) {
try {
// 重新负载均衡
Invoker<T> rInvoker = reselect(loadbalance, invocation, invokers, selected, availablecheck);
// 若再次选择出的invoker不为null,则直接返回(没有做可用性判断,在reselecti里保证了)
if (rInvoker != null) {
invoker = rInvoker;
} else {
//Check the index of current selected invoker, if it's not the last one, choose the one at index+1.
// 获取当前那个有问题的invoker的索引
int index = invokers.indexOf(invoker);
try {
//Avoid collision 轮询选择下一个invoker,也没有做可用性判断
invoker = invokers.get((index + 1) % invokers.size());
} catch (Exception e) {
logger.warn(e.getMessage() + " may because invokers list dynamic change, ignore.", e);
}
}
} catch (Throwable t) {
logger.error("cluster reselect fail reason is :" + t.getMessage() + " if can not solve, you can set cluster.availablecheck=false in url", t);
}
}
return invoker;
}
现在我们先看loadbalance.select(invokers, getUrl(), invocation)方法:
//org.apache.dubbo.rpc.cluster.loadbalance.AbstractLoadBalance#select
public <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) {
if (CollectionUtils.isEmpty(invokers)) {
return null;
}
if (invokers.size() == 1) {
return invokers.get(0);
}
// 调用具体负载均衡策略重写的doSelect()
return doSelect(invokers, url, invocation);
}
可以看到这里会调用doSelect,就是具体的策略的实现。最后跟。
回到doSelect,看下reselect(loadbalance, invocation, invokers, selected, availablecheck)方法,重新负载均衡:
//org.apache.dubbo.rpc.cluster.support.AbstractClusterInvoker#reselect
private Invoker<T> reselect(LoadBalance loadbalance, Invocation invocation,
List<Invoker<T>> invokers, List<Invoker<T>> selected, boolean availablecheck) throws RpcException {
//Allocating one in advance, this list is certain to be used.
List<Invoker<T>> reselectInvokers = new ArrayList<>(
invokers.size() > 1 ? (invokers.size() - 1) : invokers.size());
// First, try picking a invoker not in selected.
// 遍历所有提供者列表,找出所有可用的invoker,存放到reselectInvokers集合
for (Invoker<T> invoker : invokers) {
// 若当前遍历的invoker不可用,则放弃该invoker
if (availablecheck && !invoker.isAvailable()) {
continue;
}
// 若当前遍历的invoker不包含在selected集合中才加入到reselectInvokers中
if (selected == null || !selected.contains(invoker)) {
reselectInvokers.add(invoker);
}
}
// 若reselectInvokers集合不空,则对该集合进行负载均衡
if (!reselectInvokers.isEmpty()) {
return loadbalance.select(reselectInvokers, getUrl(), invocation);
}
// Just pick an available invoker using loadbalance policy
// 代码走到这里,说明reselectInvokers集合目前为空
// 若selected不空,则从selected中查找出所有可用的invoker,将其存放到reselectInvokers
// 因为有可能因为网络波动等原因,只是突然不可用,之后又恢复了
if (selected != null) {
for (Invoker<T> invoker : selected) {
if ((invoker.isAvailable()) // available first
&& !reselectInvokers.contains(invoker)) {
//selected中是有可能包含重复的invoker的
reselectInvokers.add(invoker);
}
}
}
// 若reselectInvokers集合不空,则对该集合进行负载均衡
if (!reselectInvokers.isEmpty()) {
return loadbalance.select(reselectInvokers, getUrl(), invocation);
}
return null;
}
下面我们就要开始看真正的负载均衡策略了。
3. 负载均衡策略解析
Dubbo 内置了四种负载均衡策略。
(1) random
加权随机算法,是 Dubbo 默认的负载均衡算法。权重越大,获取到负载的机率就越大。权重相同,则会随机分配。
应用场景:其适用于提供者主机性能差别较大,几乎纯粹根据主机性能进行负载均衡的情况。
先看图:
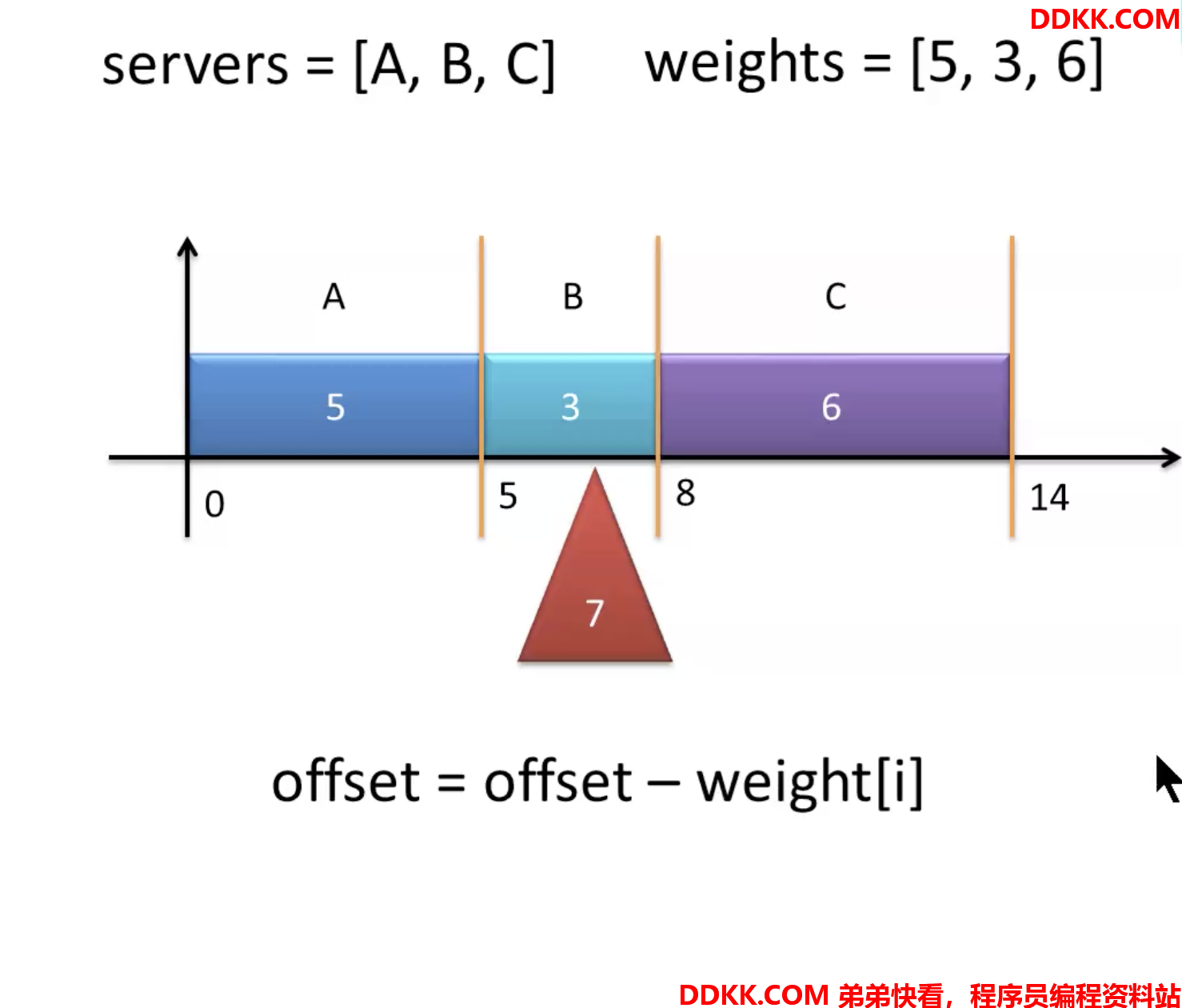
Dubbo加权随机算法执行流程示意图:
假设有三台服务器,ABC,权重分别为5,3,6
把所有权重相加,组成x轴,[0,14)
其中[0,5)认为是服务器A,[5,8)是B,[8,14)是C
然后在0到14之间生成一个随机数,假设是7,7在[5,8)之间,所以选B算法:只要满足生成的随机数按顺序依次减去服务器对应到权重,只要结果<0,则认为,此时减去权重的服务器就是要选择的服务器
例如:
7- 5 = 2 > 0 A
2- 3 = -1 < 0 B ,所以选B
权重设置方式:
只能给提供者设置,并且只能是服务级别,如果不设置,weight默认是100预热时间设置方方式:
只能给提供者设置,并且只能是服务级别,如果不设置,预热时间默认是10分钟


看代码:
//org.apache.dubbo.rpc.cluster.loadbalance.RandomLoadBalance#doSelect
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// Number of invokers 提供者数量
int length = invokers.size();
// Every invoker has the same weight?
// 用于标识所有提供者的权重是否相同
boolean sameWeight = true;
// the weight of every invokers 用于存放所有提供者的权重
int[] weights = new int[length];
// the first invoker's weight 获取第一个invoker的权重
int firstWeight = getWeight(invokers.get(0), invocation);
weights[0] = firstWeight;
// The sum of weights
int totalWeight = firstWeight;
// 为每个invoker获取权重,并计算权重之和,并判断是否所有权重相同
for (int i = 1; i < length; i++) {
int weight = getWeight(invokers.get(i), invocation);
// save for later use
weights[i] = weight;
// Sum
totalWeight += weight;
if (sameWeight && weight != firstWeight) {
sameWeight = false;
}
}
// 处理权重不同的情况
if (totalWeight > 0 && !sameWeight) {
// If (not every invoker has the same weight & at least one invoker's weight>0), select randomly based on totalWeight.
// 生成一个[0,totalWeight)的随机数,totalWeight必须正数
int offset = ThreadLocalRandom.current().nextInt(totalWeight);
// Return a invoker based on the random value.
for (int i = 0; i < length; i++) {
//依次减去每个主机到权重,一旦结果<0后,则返回当前遍历到主机
offset -= weights[i];
if (offset < 0) {
return invokers.get(i);
}
}
}
// If all invokers have the same weight value or totalWeight=0, return evenly.
// 若权重相同,则随机选择一个
return invokers.get(ThreadLocalRandom.current().nextInt(length));
}
上面代码中还有一个核心方法org.apache.dubbo.rpc.cluster.loadbalance.AbstractLoadBalance#getWeight获取权重还没没有分析,涉及到预热权重的逻辑:
//org.apache.dubbo.rpc.cluster.loadbalance.AbstractLoadBalance#getWeight
protected int getWeight(Invoker<?> invoker, Invocation invocation) {
// 获取权重
int weight = invoker.getUrl().getMethodParameter(invocation.getMethodName(), WEIGHT_KEY, DEFAULT_WEIGHT);
if (weight > 0) {
// 获取invoker的启动时间戳
long timestamp = invoker.getUrl().getParameter(REMOTE_TIMESTAMP_KEY, 0L);
if (timestamp > 0L) {
// 计算当前invoker已经启动了多久
int uptime = (int) (System.currentTimeMillis() - timestamp);
// 获取预热时间
int warmup = invoker.getUrl().getParameter(WARMUP_KEY, DEFAULT_WARMUP);
// 若已经启动,且尚未到达预热时间,计算预热权重
if (uptime > 0 && uptime < warmup) {
weight = calculateWarmupWeight(uptime, warmup, weight);
}
}
}
// 权重是一个非负整数
return weight >= 0 ? weight : 0;
}
计算预热权重,calculateWarmupWeight:
//org.apache.dubbo.rpc.cluster.loadbalance.AbstractLoadBalance#calculateWarmupWeight
static int calculateWarmupWeight(int uptime, int warmup, int weight) {
// 以下语句等价于该式子:ww = uptime / (warmup / weight) = (uptime / warmup) * weight
// 即等于 权重*(已经启动时间/预热时间)
int ww = (int) ((float) uptime / ((float) warmup / (float) weight));
// 预热权重的最大值为配置文件中设置的权重
return ww < 1 ? 1 : (ww > weight ? weight : ww);
}
(2) leastactive
加权最小活跃度调度算法。活跃度越小,其优选级就越高,被调度到的机率就越高。活跃度相同,则按照加权随机算法进行负载均衡。
其应用场景:其适应于主机性能差别不是很大的场景。其是根据各个 invoker 任务处理数量、压力进行负载均衡。
活跃度:一个提供者只要正在处理一个请求,它的活跃度就是1,正在处理两个请求,活跃度就是2,如果正在处理两个,其中一个结束了,活跃度就变成1了,
即活跃度是当前invoker正在处理的请求数量,最小是0
//org.apache.dubbo.rpc.cluster.loadbalance.LeastActiveLoadBalance#doSelect
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// Number of invokers
int length = invokers.size();
// The least active value of all invokers 初始化最小活跃度
int leastActive = -1;
// The number of invokers having the same least active value (leastActive)
// 计数器,记录具有最小活跃度的invoker的数量
int leastCount = 0;
// The index of invokers having the same least active value (leastActive)
// 记录具有最小活跃度的invoker的索引
int[] leastIndexes = new int[length];
// the weight of every invokers 记录所有提供者的权重
int[] weights = new int[length];
// The sum of the warmup weights of all the least active invokes
// 具有最小活跃度的所有invoker的权重之和
int totalWeight = 0;
// The weight of the first least active invoke
// 具有最小活跃度的所有invoker中,第一个invoker的权重
int firstWeight = 0;
// Every least active invoker has the same weight value?
// 标识具有最小活跃度的invoker的权重是否全部相同
boolean sameWeight = true;
// Filter out all the least active invokers
// 遍历所有invoker,找到具有最小活跃度的所有invoker,并计算出相关数据
for (int i = 0; i < length; i++) {
Invoker<T> invoker = invokers.get(i);
// Get the active number of the invoke
// 获取当前遍历invoker的活跃度,其默认值为0
int active = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName()).getActive();
// Get the weight of the invoke configuration. The default value is 100.
// 获取当前invoker权重,默认100
int afterWarmup = getWeight(invoker, invocation);
// save for later use
weights[i] = afterWarmup;
// If it is the first invoker or the active number of the invoker is less than the current least active number
// 只有当第一次遍历时leastActive的值才会是-1,其它情况,最小都是0
// 只有当第一次遍历时,或者之后发现更小的活跃度,则初始化统计数据,从新开始记
if (leastActive == -1 || active < leastActive) {
// Reset the active number of the current invoker to the least active number
// 重新记录目前最小活跃度
leastActive = active;
// Reset the number of least active invokers
// 重新记录具有最小活跃度的invoker的数量
leastCount = 1;
// Put the first least active invoker first in leastIndexes
// 重新记录具有最小活跃度的invoker的索引
leastIndexes[0] = i;
// Reset totalWeight
// 重新记录具有最小活跃度的所有invoker的权重之和
totalWeight = afterWarmup;
// Record the weight the first least active invoker
// 重新记录具有最小活跃度的所有invoker中,第一个invoker的权重
firstWeight = afterWarmup;
// Each invoke has the same weight (only one invoker here)
// 重新标记具有最小活跃度的invoker的权重是否全部相同
sameWeight = true;
// If current invoker's active value equals with leaseActive, then accumulating.
} else if (active == leastActive) {
// 统计具有同样最小活跃度的invoker的信息
// Record the index of the least active invoker in leastIndexes order
// 记录具有最小活跃度的invoker的索引
leastIndexes[leastCount++] = i;
// Accumulate the total weight of the least active invoker
// 记录具有最小活跃度的所有invoker的权重之和
totalWeight += afterWarmup;
// If every invoker has the same weight?
if (sameWeight && i > 0
&& afterWarmup != firstWeight) {
//标记具有最小活跃度的invoker的权重是否全部相同
sameWeight = false;
}
}
} // end-for
// Choose an invoker from all the least active invokers
// 若具有最小活跃度的invoker只有一个,则直接返回这一个
if (leastCount == 1) {
// If we got exactly one invoker having the least active value, return this invoker directly.
return invokers.get(leastIndexes[0]);
}
// 下面就是加权随机算法
if (!sameWeight && totalWeight > 0) {
// If (not every invoker has the same weight & at least one invoker's weight>0), select randomly based on
// totalWeight.
int offsetWeight = ThreadLocalRandom.current().nextInt(totalWeight);
// Return a invoker based on the random value.
for (int i = 0; i < leastCount; i++) {
int leastIndex = leastIndexes[i];
offsetWeight -= weights[leastIndex];
if (offsetWeight < 0) {
return invokers.get(leastIndex);
}
}
}
// If all invokers have the same weight value or totalWeight=0, return evenly.
return invokers.get(leastIndexes[ThreadLocalRandom.current().nextInt(leastCount)]);
}
看下获取活跃度的方法int active = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName()).getActive()
//org.apache.dubbo.rpc.RpcStatus#getStatus(org.apache.dubbo.common.URL, java.lang.String)
public static RpcStatus getStatus(URL url, String methodName) {
String uri = url.toIdentityString();
//private static final ConcurrentMap<String, ConcurrentMap<String, RpcStatus>> METHOD_STATISTICS = new ConcurrentHashMap<String, ConcurrentMap<String, RpcStatus>>();
ConcurrentMap<String, RpcStatus> map = METHOD_STATISTICS.get(uri);
if (map == null) {
METHOD_STATISTICS.putIfAbsent(uri, new ConcurrentHashMap<String, RpcStatus>());
map = METHOD_STATISTICS.get(uri);
}
RpcStatus status = map.get(methodName);
if (status == null) {
map.putIfAbsent(methodName, new RpcStatus());
status = map.get(methodName);
}
return status;
}
//org.apache.dubbo.rpc.RpcStatus#getActive
public int getActive() {
//private final AtomicInteger active = new AtomicInteger();
return active.get();
}
(3) roundrobin
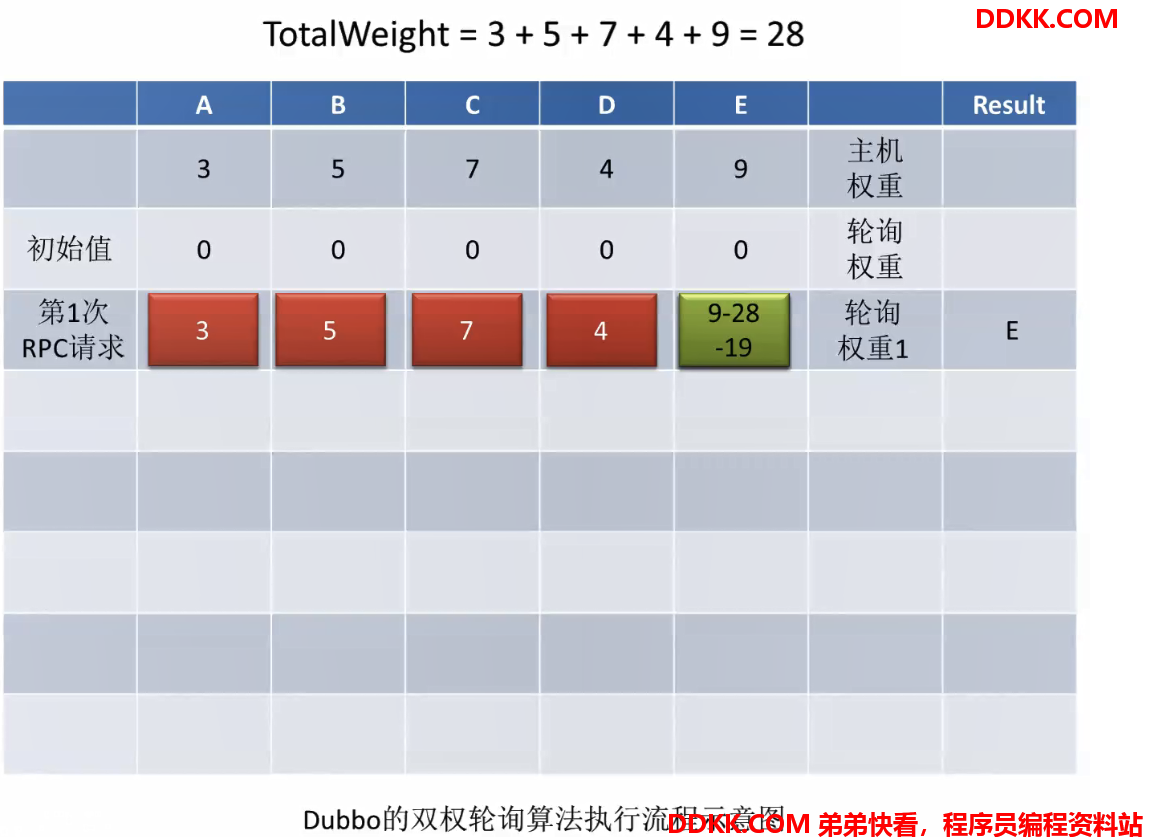
双权重轮询算法,是结合主机权重与轮询权重的、方法级别的轮询算法。
看图:
主机权重:就是上面两种算法中用到的weight
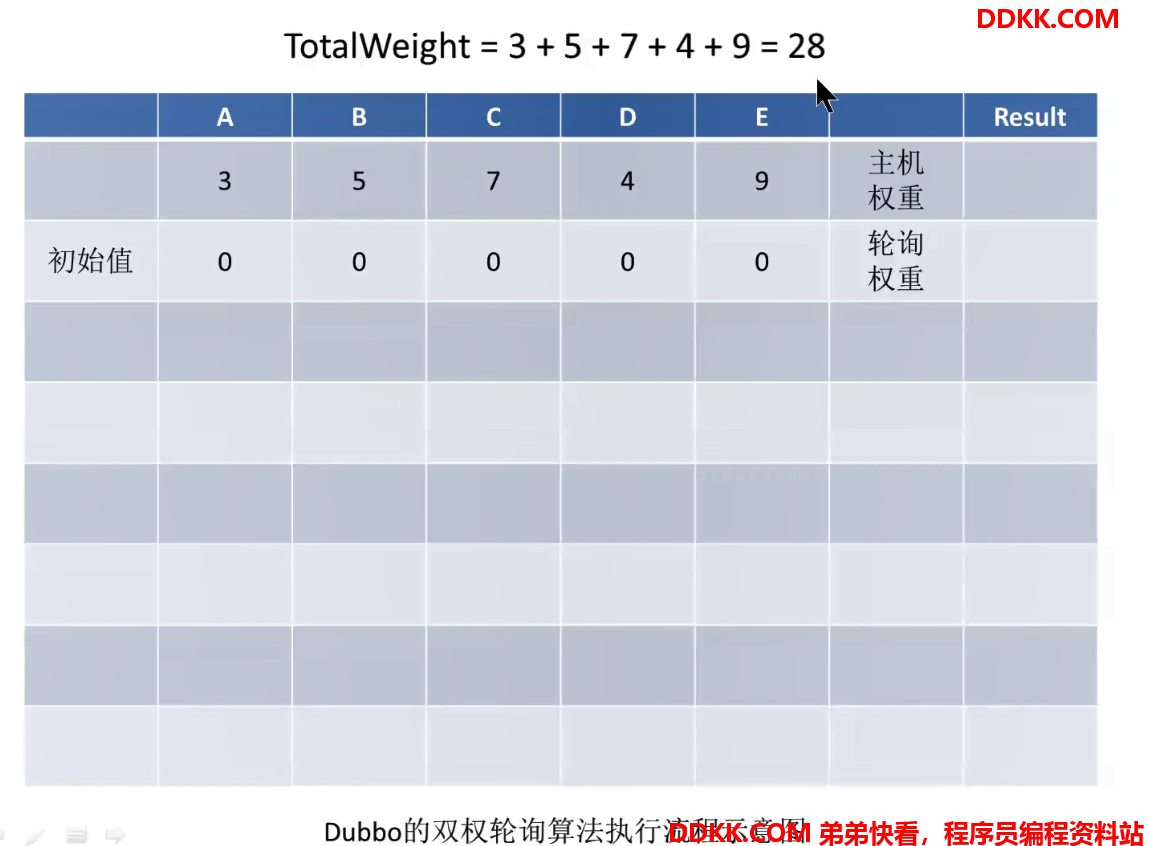
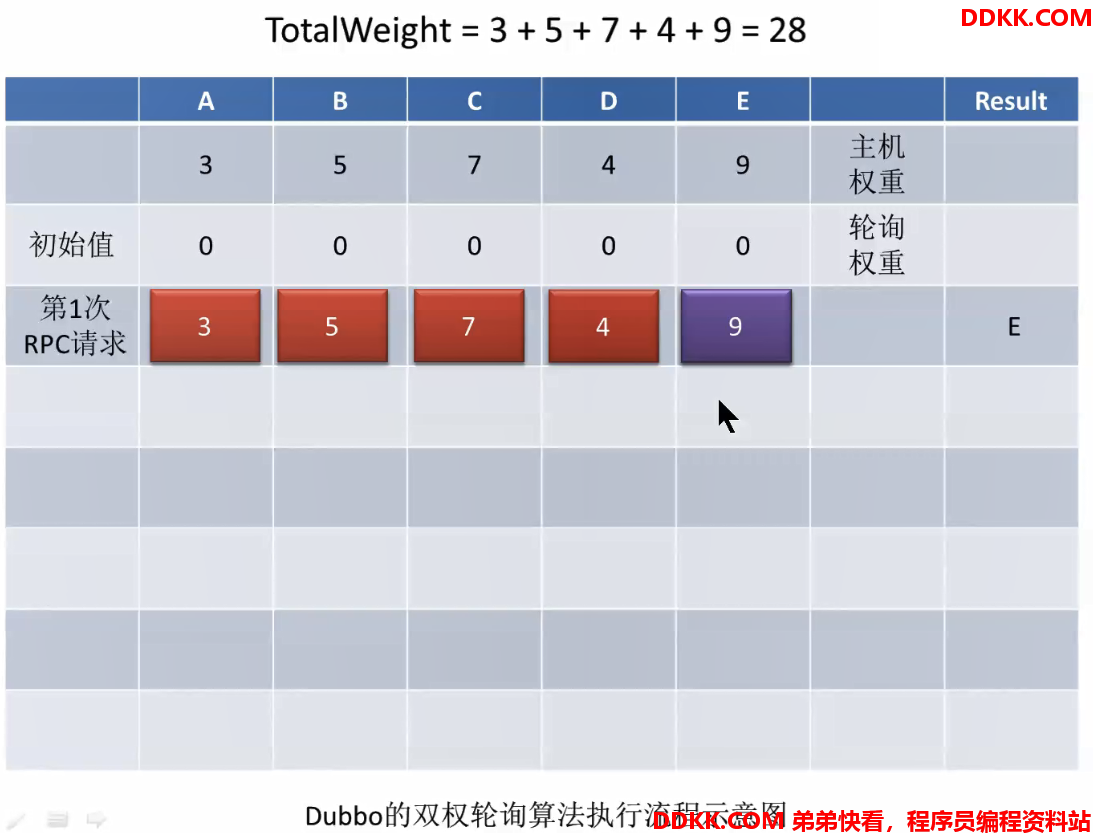
双权重轮询算法执行流程示意图:
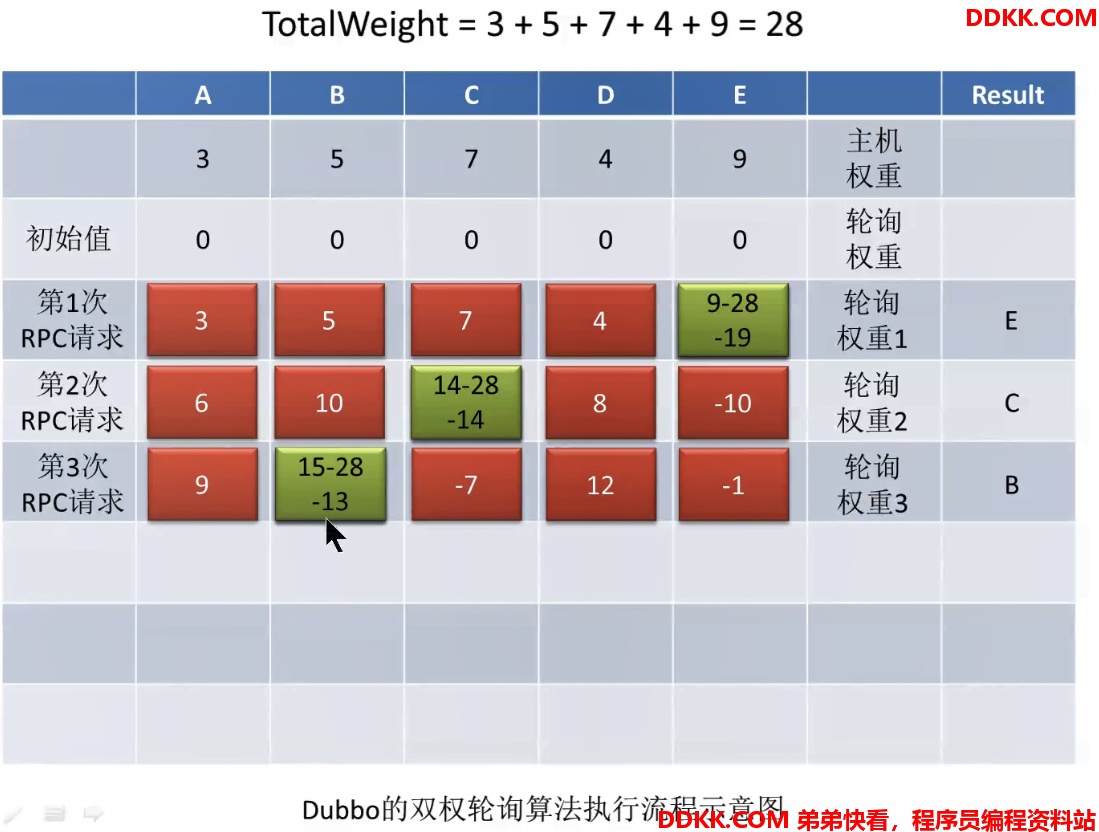
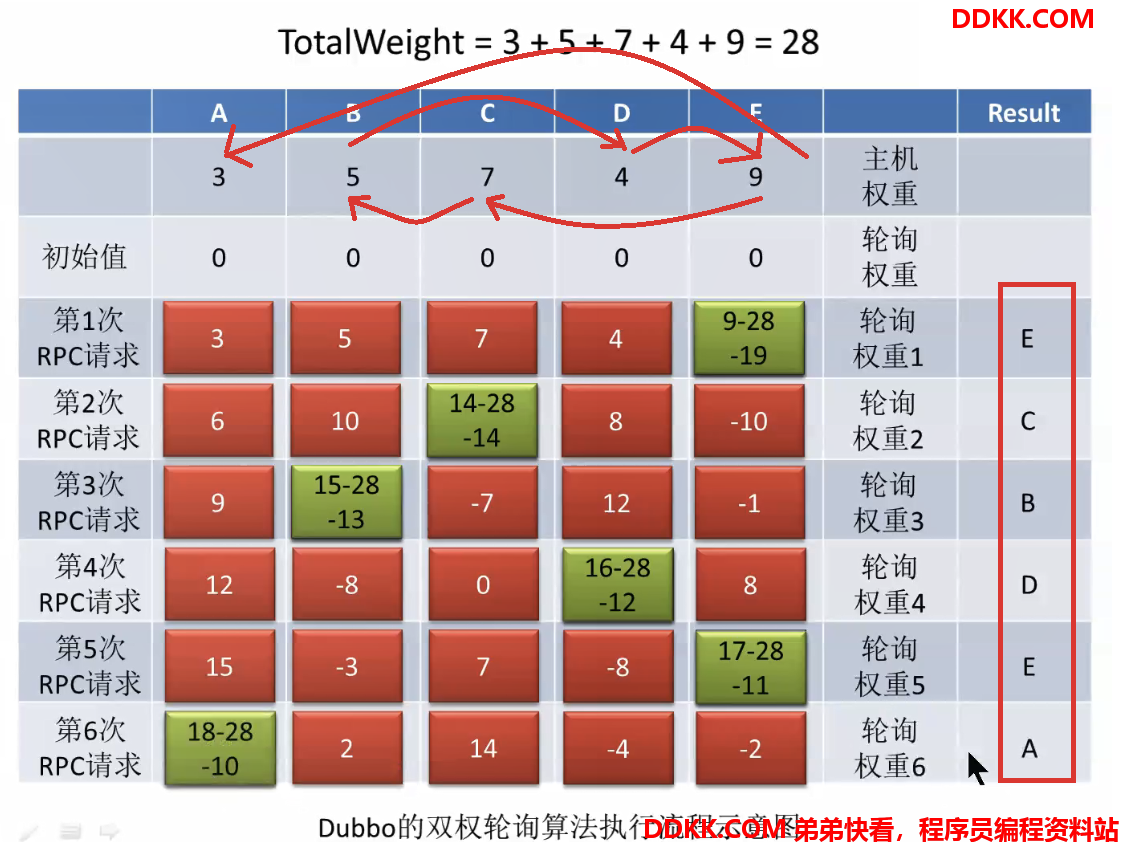
一开始,所有主机的轮询权重都是0第一次请求后,轮询权重会进行加权,加的就是主机权重,然后选出轮询权重最大的主机(invoker),即E
选出以后把选出的invoker的轮询权重置为最小的,通过让其减去totalWeight,即9-28=-19
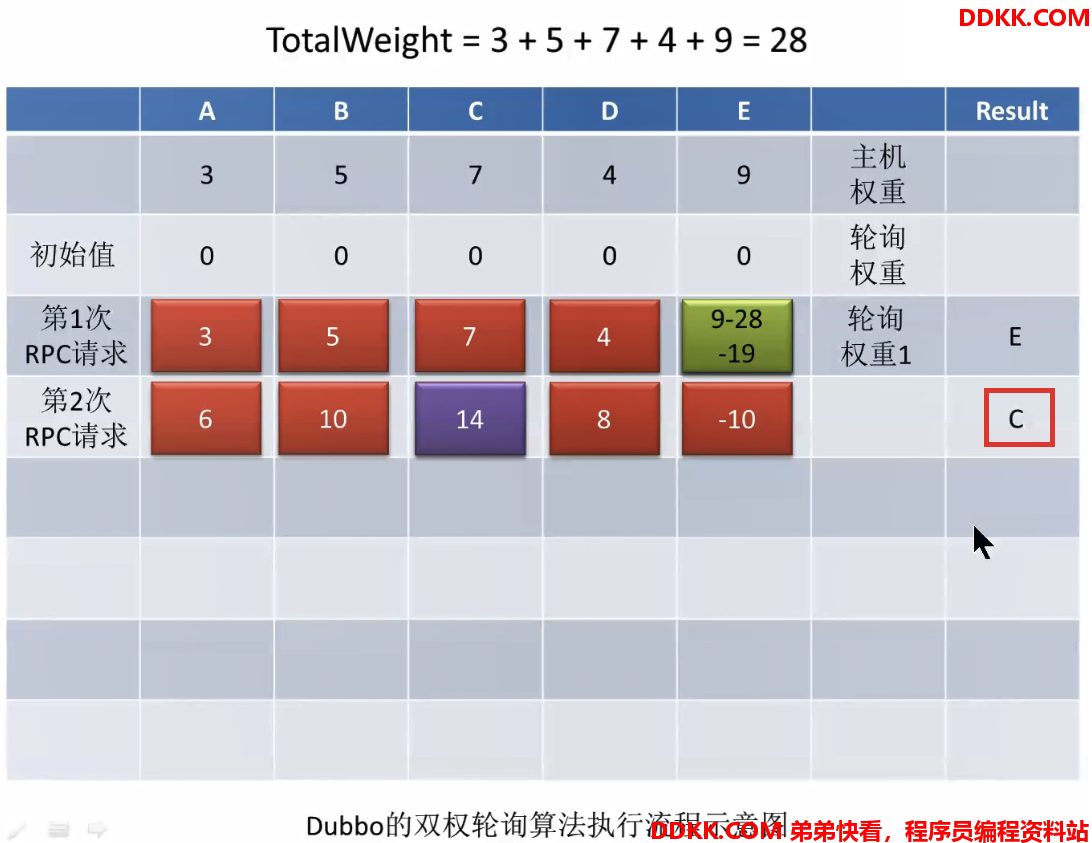
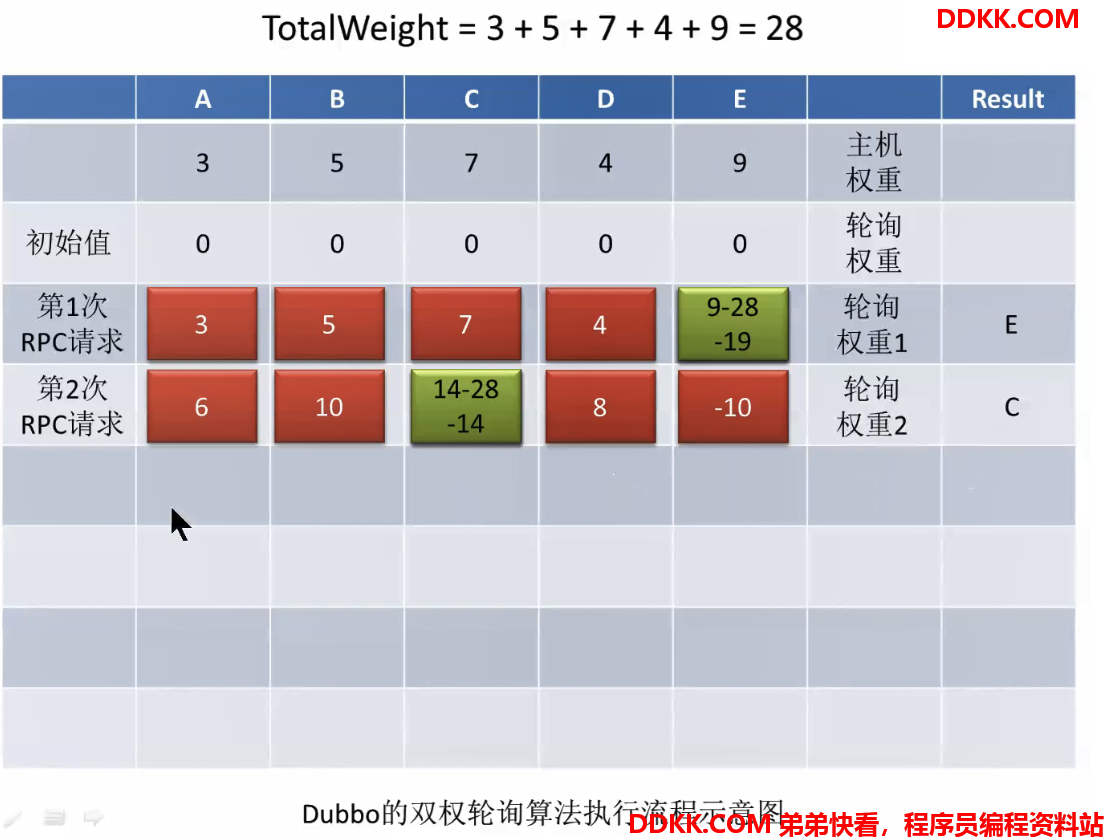
此时就是一轮负载均衡后的结果。第二次请求过来,再次为每个主机的轮询权重加权,是在上一次的基础之上再加上自己的主机权重,加权以后再次选出轮询权重最大的主机(invoker),此时是C:
选出以后再次把选出的invoker的轮询权重其减去totalWeight,即14-28=-14
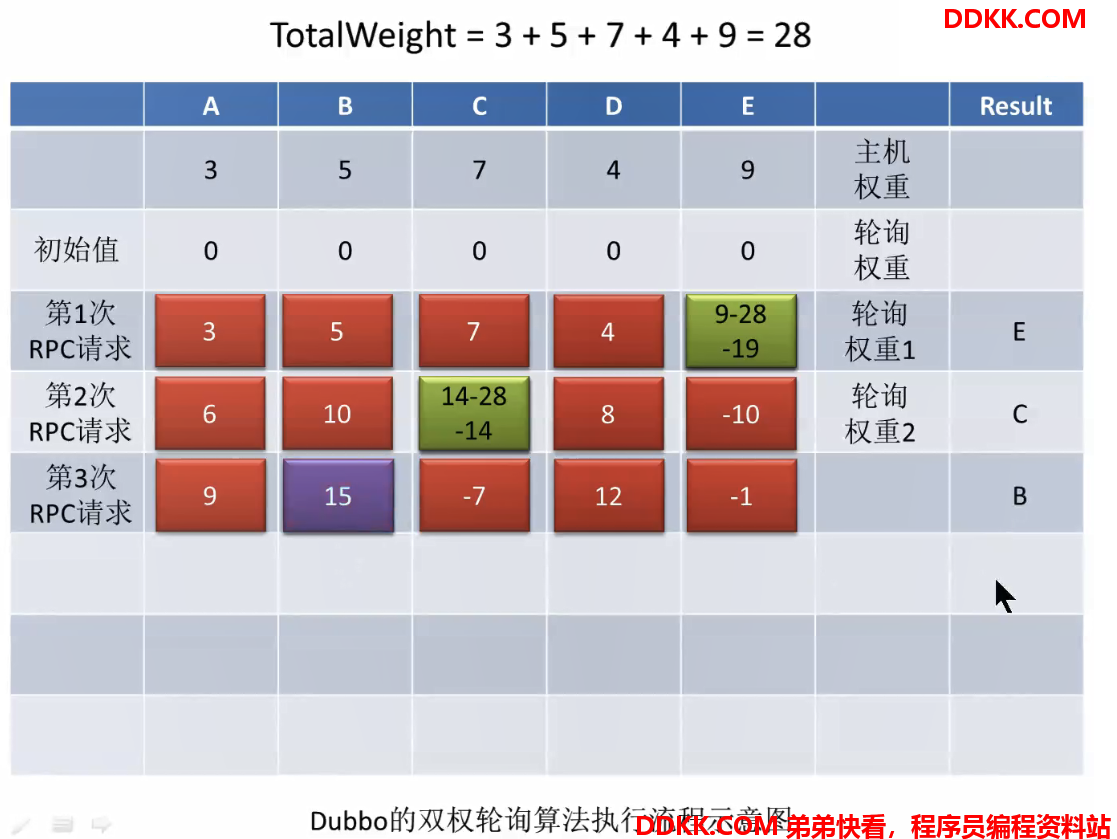
以此类推,第三次请求:
多次请求的效果:
可以看到并不是纯粹按照主机权重大小顺序选择分析:通过算法,可以看出每个主机一但被选择到返回以后,其轮询权重就会减去所有主机的主机权重之和,变成最小,每次轮询会加上自己的主机权重,慢慢增长,而主机权重越大的主机,增长的速度越快,再次变成最大需要的轮询次数越少,造成的效果就是,
权重越大的主机,被选择到的频率越高
现在我们看代码实现:
public class RoundRobinLoadBalance extends AbstractLoadBalance {
public static final String NAME = "roundrobin";
// 回收期,默认60秒(invoker有可能会失效,超过这个时间一直没有加权,invoker会被回收)
private static final int RECYCLE_PERIOD = 60000;
// 双层map
// 外层map的key是全限定性方法名
// 外层map的value是内层map
// 内层map的key是invoker的url 例如,dubbo://192.168.0.106:20880/com.abc.service.SomeService
// 内层map的value是轮询权重实例
// 这个内层map的意义是:一个方法的所有提供者及其轮询权重
private ConcurrentMap<String, ConcurrentMap<String, WeightedRoundRobin>> methodWeightMap = new ConcurrentHashMap<String, ConcurrentMap<String, WeightedRoundRobin>>();
private AtomicBoolean updateLock = new AtomicBoolean();
// 轮询权重(内部类)
protected static class WeightedRoundRobin {
// 主机权重
private int weight;
// 轮询权重实例的当前值
private AtomicLong current = new AtomicLong(0);
// 当前轮询权重最后一次的加权时间
private long lastUpdate;
public int getWeight() {
return weight;
}
// 为当前轮询权重设置主机权重,注意,其会将当前轮询权重值清零
public void setWeight(int weight) {
this.weight = weight;
current.set(0);
}
// 轮询权重加权(加主机权重)
public long increaseCurrent() {
return current.addAndGet(weight);
}
// 使当前轮询权重变为最小(减去了所有invoker的主机权重之和)
public void sel(int total) {
current.addAndGet(-1 * total);
}
public long getLastUpdate() {
return lastUpdate;
}
public void setLastUpdate(long lastUpdate) {
this.lastUpdate = lastUpdate;
}
}
//上面看过以后现在看doSelect方法:
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// 获取全限定性方法名,外层map的key
String key = invokers.get(0).getUrl().getServiceKey() + "." + invocation.getMethodName();
// 从缓存中获取该方法对应的内层map
ConcurrentMap<String, WeightedRoundRobin> map = methodWeightMap.get(key);
// 若这个内层map为空,则创建一个内层map再放入缓存
if (map == null) {
methodWeightMap.putIfAbsent(key, new ConcurrentHashMap<String, WeightedRoundRobin>());
map = methodWeightMap.get(key);
}
int totalWeight = 0;
// 初始化最大的轮询权重
long maxCurrent = Long.MIN_VALUE;
long now = System.currentTimeMillis();
// 记录这次负载均衡选出的主机
Invoker<T> selectedInvoker = null;
// 记录选出的主机的轮询权重实例
WeightedRoundRobin selectedWRR = null;
// 遍历所有invoker,找到具有最大轮询权重的invoker,并计算出了主机权重之和
for (Invoker<T> invoker : invokers) {
// 获取内层map的key,即invoker的url
String identifyString = invoker.getUrl().toIdentityString();
// 从缓存中获取当前invoker对应的轮询权重
WeightedRoundRobin weightedRoundRobin = map.get(identifyString);
// 获取当前invoker的主机权重
int weight = getWeight(invoker, invocation);
// 若缓存中的轮询权重为null,则创建一个,再放入缓存
if (weightedRoundRobin == null) {
weightedRoundRobin = new WeightedRoundRobin();
weightedRoundRobin.setWeight(weight);
map.putIfAbsent(identifyString, weightedRoundRobin);
}
// 若当前invoker的主机权重与缓存中轮询权重中封装的主机权重值不同
// 处理预热时权重变化的情况、或者通过管控平台修改的情况
// 若不相同,重新更新主机权重
if (weight != weightedRoundRobin.getWeight()) {
//weight changed
weightedRoundRobin.setWeight(weight);
}
// 轮询权重加权,并返回加权后的值
long cur = weightedRoundRobin.increaseCurrent();
// 记录当前加权的时间戳
weightedRoundRobin.setLastUpdate(now);
// 若当前invoker的轮询权重值大于最大轮询权重值,则记录下相关信息
if (cur > maxCurrent) {
maxCurrent = cur;
selectedInvoker = invoker;
selectedWRR = weightedRoundRobin;
}
// 将当前invoker的主机权重添加到总权重
totalWeight += weight;
} // end-for
// 下面这个if是用于清除所有失效的invoker
// updateLock的值默认为false,表示未上锁
// 若当前最新的invoker列表大小与缓存中提供者数量不同,
// 这个不同,只可能是invoker出现了宕机,数量比缓存中的少了
//(因为如果是新的invoker,上面循环的时候会在map中放入新的轮询权重实例)
if (!updateLock.get() && invokers.size() != map.size()) {
// 通过CAS使updateLock的值为true,加锁
if (updateLock.compareAndSet(false, true)) {
try {
// copy -> modify -> update reference
// 创建一个新的内层map
ConcurrentMap<String, WeightedRoundRobin> newMap = new ConcurrentHashMap<String, WeightedRoundRobin>();
// 使用老的内层map初始化新的内层map
newMap.putAll(map);
// 迭代新的内层map
Iterator<Entry<String, WeightedRoundRobin>> it = newMap.entrySet().iterator();
// 查找并清除所有超出回收期的invoker
while (it.hasNext()) {
Entry<String, WeightedRoundRobin> item = it.next();
// item.getValue().getLastUpdate() 表示当前迭代的invoker的轮询权重最后一次加权时间
// 若加权更新时间间隔超出了回收期,则将该invoker清除
if (now - item.getValue().getLastUpdate() > RECYCLE_PERIOD) {
it.remove();
}
}
// 将更新过的内层map写入到缓存
methodWeightMap.put(key, newMap);
} finally {
// 开锁
updateLock.set(false);
}
}
}
// 使当前选择出的invoker的轮询权重值变为最小,并返回这个invoker
if (selectedInvoker != null) {
selectedWRR.sel(totalWeight);
return selectedInvoker;
}
// should not happen here
return invokers.get(0);
}
}
(4) consistenthash
一致性hash 算法。其是一个方法参数级别的负载均衡。对于同一调用方法的、相同实参的、远程调用请求,其会被路由到相同的 invoker。其是以调用方法的指定实参的 hash 值为 key 进行 invoker 选择的。
先看图:
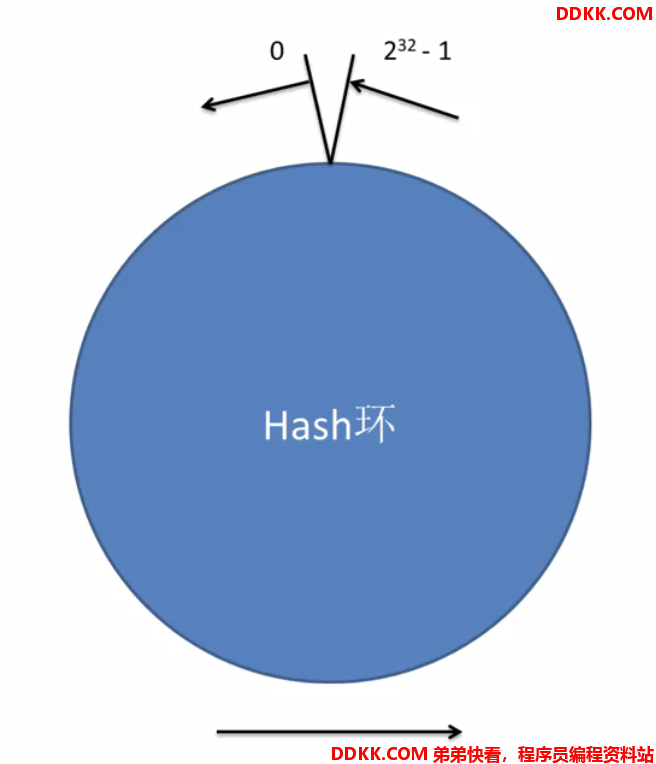
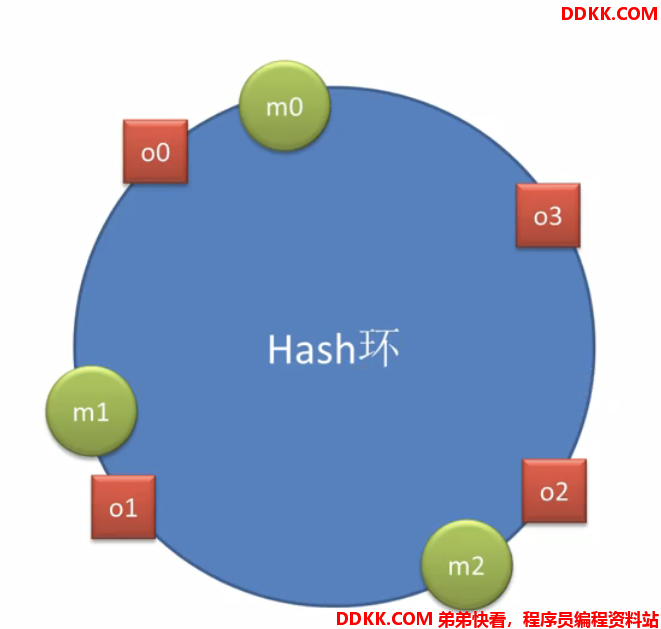
一致性hash算法:
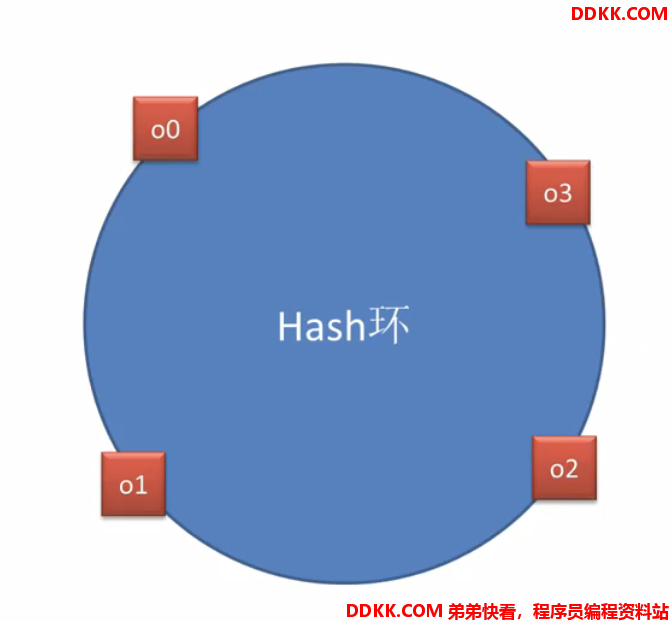
假设环上有4个对象,分别代表4次请求,根据请求某个key算出hash值,对应环上位置:
现在要找机器,假如有三个机器m0,m1,m2,根据某种算法算出hash值,也落在这个hash环上,对应环上的位置:
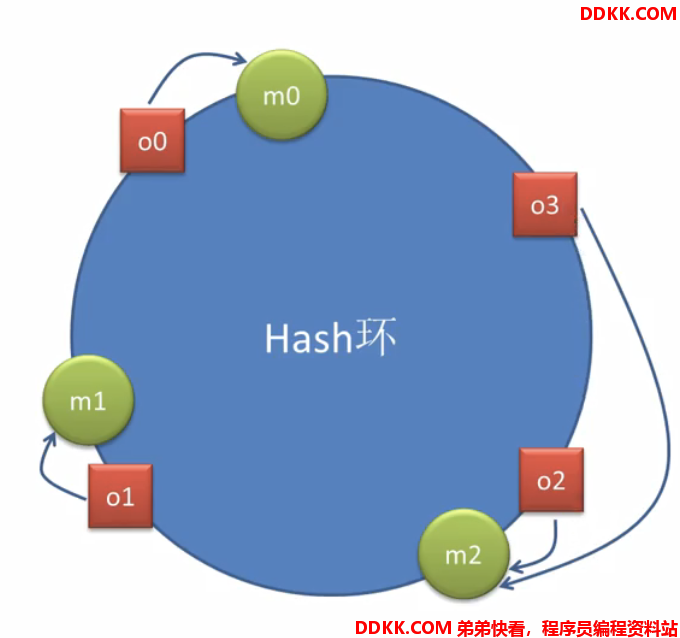
接着做选择,比如o0请求,应该找哪个机器?在根据某种算法,比如说按照顺时针方向在环上找最近的机器:
这个就是一致性hash环上的一致性hash选择算法dubbo的一致性hash负载均衡要比这个复杂,因为上面这个算法存在一个问题:
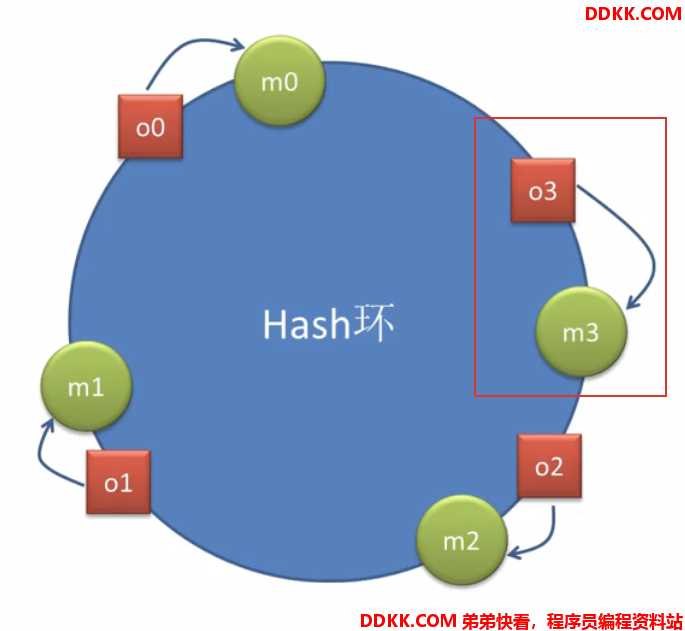
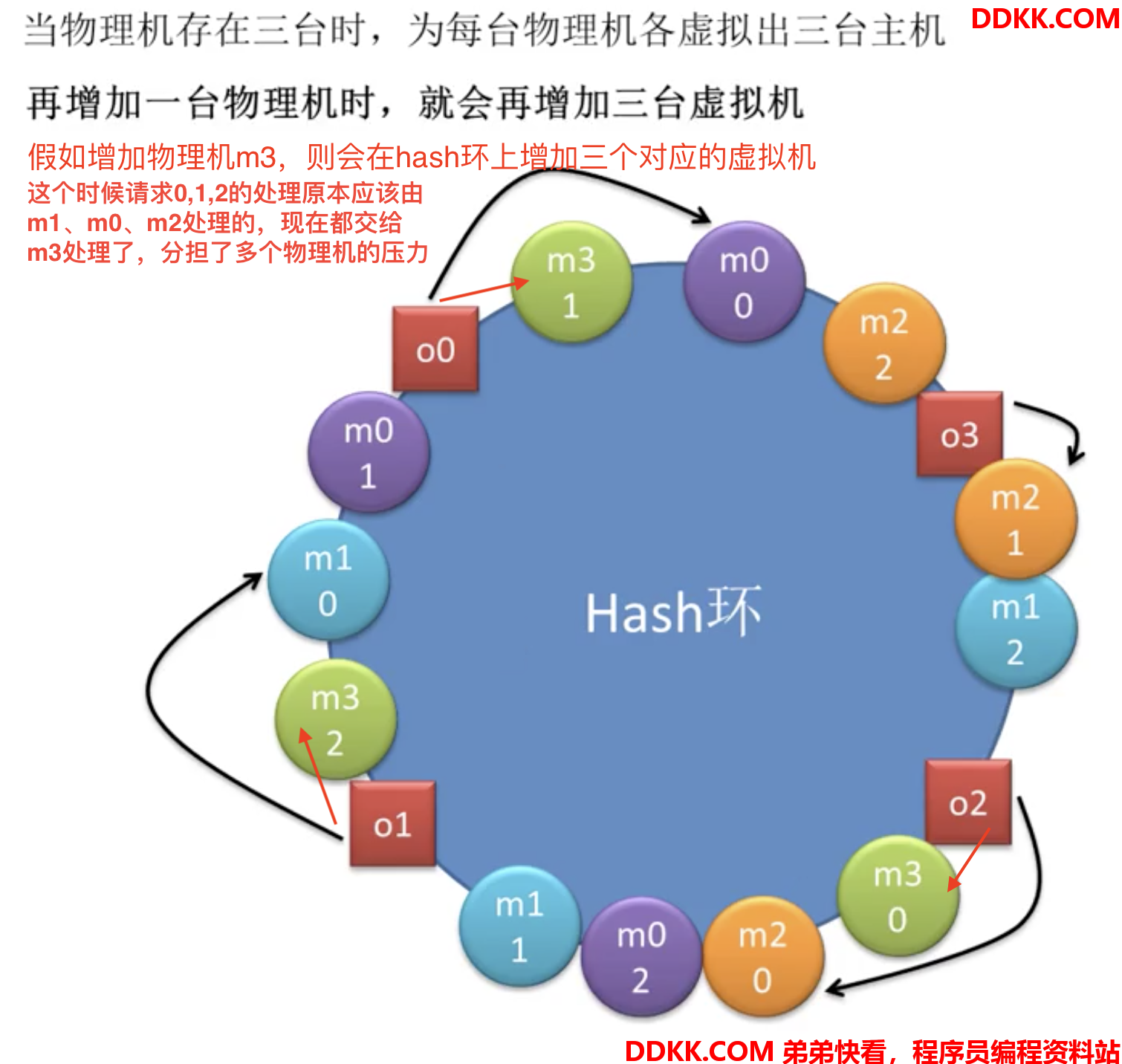
比如增加一个主机m3,对于3号请求来说,顺时针方向离它最近的主机就变成了m3:
也就是说增加一个机器后,只会对原有机器里面,离它最近的机器有影响(根据算法,方向不一样)
上图就是增加m3机器后只会影响m2机器,把m2机器的负载均衡掉了,对m0和m1不影响,同样道理,要是减少机器,去掉m3,就会加大m2机器的压力
即提供者机器扩容或缩容,只会对增加的机器离得最近的机器负载有影响,对其他机器没影响所以对此做了一个改进:
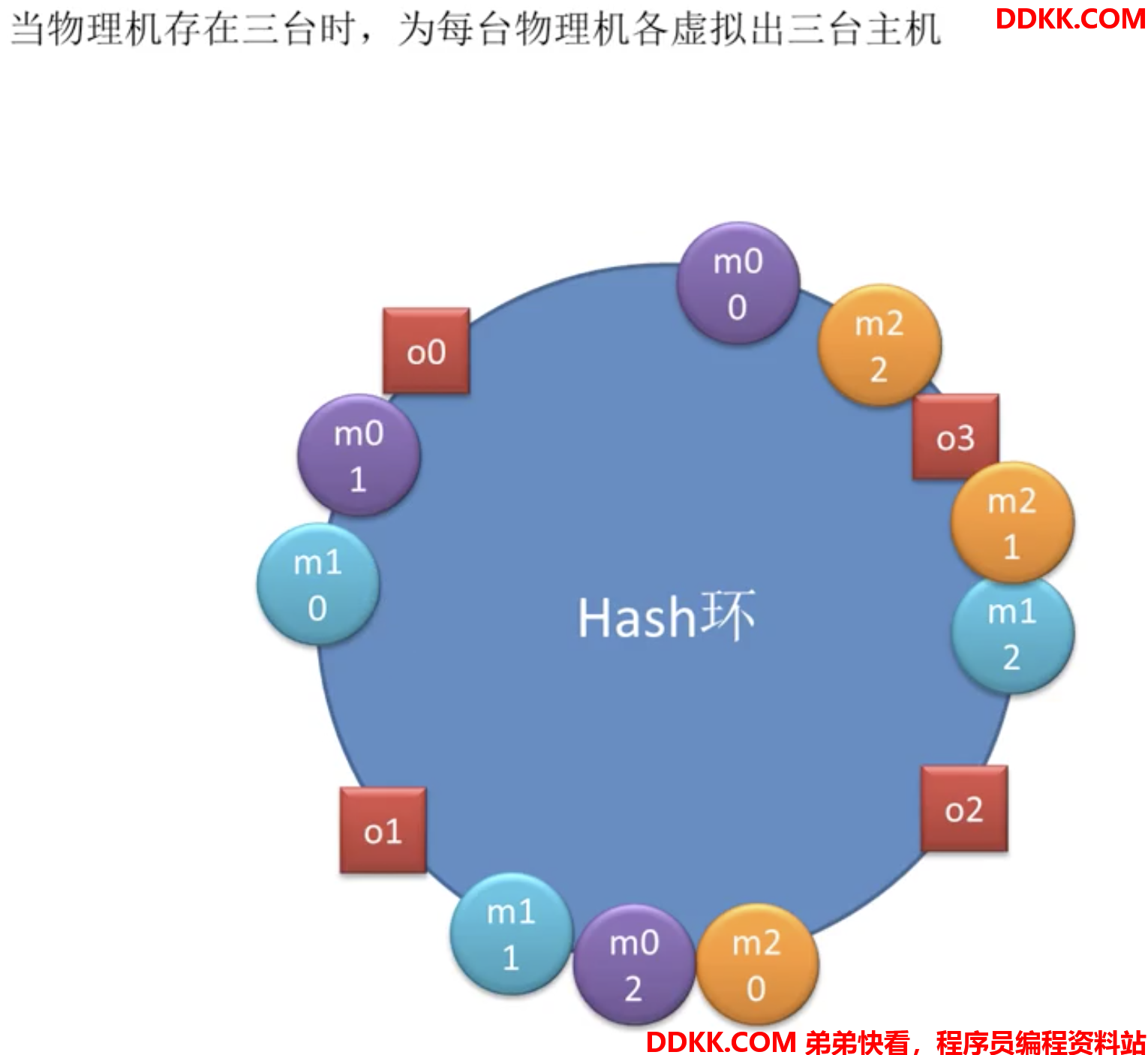
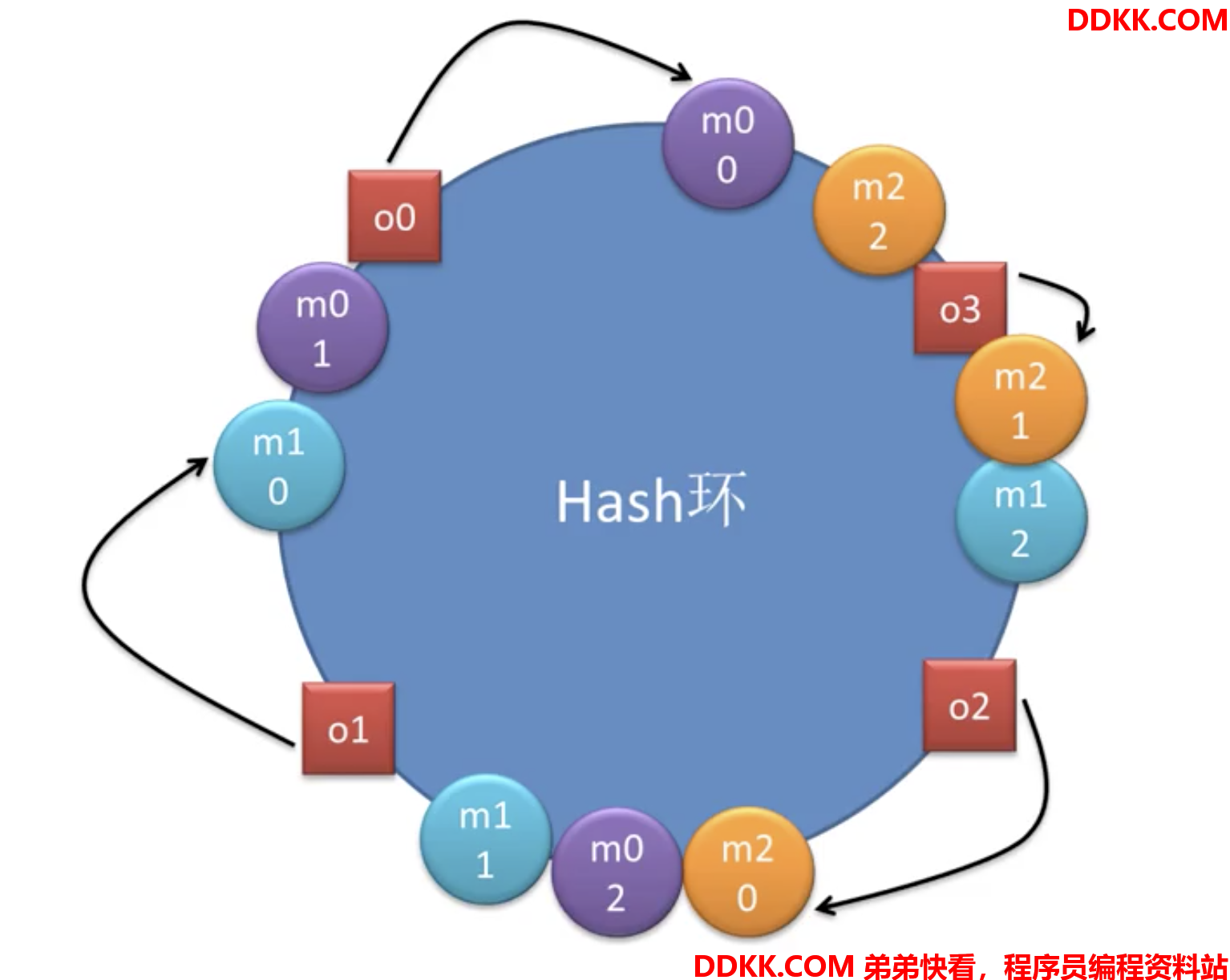
为每一个主机创建一堆虚拟主机放在环上
每个请求依然按照顺时针方法找最近的主机:
此时o0找到的是m0-0虚拟主机,对应将由m0物理主机处理
o1找到m1-0,将由m1物理主机处理
o2找到m2-0,将由m2物理主机处理
o3找到m2-1,将由m2物理主机处理假如在增加一台物理机,就会再增加三台虚拟机:
dubbo用的就是这种算法。
在dubbo中是如何配置一致性hash负载均衡算法?
假设有个服务:
public interface DemoService2 {
//xxx方法中有三个参数
String xxx(String name, String depart, int age);
}
对应的消费者配置:
<dubbo:reference id="demoService2" check="false" mock="true"
interface="org.apache.dubbo.demo.DemoService2">
<dubbo:method name="xxx">
<!-- 1,2的意思是把xxx方法的第二个和第三个参数(索引0开始)的实参值进行字符串拼接 -->
<!-- 拼接形成的新字符串的hash值将作为在hash环上的落点 -->
<!-- value不指定默认是0 -->
<dubbo:parameter key="hash.arguments" value="1,2"/>
<!-- 对每一个该方法的提供者invoker虚拟出来160个虚拟机(默认就是160 ) -->
<dubbo:parameter key="hash.nodes" value="160"/>
</dubbo:method>
</dubbo:reference>
现在看源码
public class ConsistentHashLoadBalance extends AbstractLoadBalance {
...
// 一致性hash选择器缓存map
// key:全限性方法名
// value:该方法对应的一致性hash选择器
private final ConcurrentMap<String, ConsistentHashSelector<?>> selectors = new ConcurrentHashMap<String, ConsistentHashSelector<?>>();
@SuppressWarnings("unchecked")
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// 获取远程调用的方法名称
String methodName = RpcUtils.getMethodName(invocation);
// 获取全限定性方法名
String key = invokers.get(0).getUrl().getServiceKey() + "." + methodName;
// 获取invokers列表的hashCode
int identityHashCode = System.identityHashCode(invokers);
// 从缓存map中获取当前调用方法的一致性hash选择器
ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key);
// 若选择器为null则创建一个新的选择器,并缓存到map中
if (selector == null || selector.identityHashCode != identityHashCode) {
selectors.put(key, new ConsistentHashSelector<T>(invokers, methodName, identityHashCode));
selector = (ConsistentHashSelector<T>) selectors.get(key);
}
// 根据请求使用选择器选择一个invoker
return selector.select(invocation);
}
...
}
我们先跟ConsistentHashSelector的构造,看如何创建选择器:
//它是ConsistentHashLoadBalance的静态内部类
private static final class ConsistentHashSelector<T> {
//红黑树实现的Map
private final TreeMap<Long, Invoker<T>> virtualInvokers;
private final int replicaNumber;
private final int identityHashCode;
private final int[] argumentIndex;
ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) {
// 创建一个TreeMap来保存所有虚拟提供者
// value为虚拟invoker
// key为该虚拟invoker对应的hashCode
this.virtualInvokers = new TreeMap<Long, Invoker<T>>();
this.identityHashCode = identityHashCode;
URL url = invokers.get(0).getUrl();
// 获取配置的hash.nodes属性值,即为每个物理invoker生成的虚拟invoker数量,默认160
this.replicaNumber = url.getMethodParameter(methodName, HASH_NODES, 160);
// 获取配置的hash.arguments属性值,并以逗号分隔解析出指定的数值,默认"0"
String[] index = COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, HASH_ARGUMENTS, "0"));
// 将解析出的字符串转化为整型数后存放到argumentIndex数组中
argumentIndex = new int[index.length];
for (int i = 0; i < index.length; i++) {
argumentIndex[i] = Integer.parseInt(index[i]);
}
// 遍历所有物理invoker,为每一个物理invoker生成指定数量的虚拟invoker
// 所谓虚拟invoker,简单来说,就是一个TreeMap中的Entry,key为一个hashCode,
// 而value则为其对应的物理invoker
// 这里的hashCode生成算法,需要一个32位字节的整数。
for (Invoker<T> invoker : invokers) {
// 获取当前遍历invoker的地址 ip:port
String address = invoker.getUrl().getAddress();
// 这里为什么要除以4?因为我们的hash环大小是32位字节的整数
// 而md5算法生成的是128位,所以md5生成一次可以分四段用
for (int i = 0; i < replicaNumber / 4; i++) {
// md5算法能够生成一个128位字节的byte[]
byte[] digest = md5(address + i);
// 使用32位整数生成一个hashCode。故一个digest可以生成4个hashCode。
// 由于digest是128位,将其平均分为四段,每段用于生成一个hashCode。
// 0-31,32-63,64-95,96-128
for (int h = 0; h < 4; h++) {
// 使用32位整数生成一个hashCode
long m = hash(digest, h);
// 将生成的hashCode与物理invoker配对,存放到map中
virtualInvokers.put(m, invoker);
}
}
}
}
...
}
接下来看选择器如何选择的,selector.select(invocation)方法:
private static final class ConsistentHashSelector<T> {
...
//看select方法:
public Invoker<T> select(Invocation invocation) {
// toKey()方法中的参数为远程调用时的实参列表
// 将远程调用方法的指定实参通过字符串拼接形成key
String key = toKey(invocation.getArguments());
// 根据这个实参形成的key,生成一个摘要
byte[] digest = md5(key);
// 使用摘要的0-31字节生成一个hashCode
return selectForKey(hash(digest, 0));
}
private String toKey(Object[] args) {
StringBuilder buf = new StringBuilder();
// 拼接所有远程调用方法中被指用于运算hashCode值的实参值,
// 即对指定非负的值进行拼接,将来用于计算hashCode值
for (int i : argumentIndex) {
//防止索引越界
if (i >= 0 && i < args.length) {
buf.append(args[i]);
}
}
return buf.toString();
}
private Invoker<T> selectForKey(long hash) {
// 根据提交的实参拼接串的hashCode从virtualInvokers中获取相应的Entry对象
Map.Entry<Long, Invoker<T>> entry = virtualInvokers.ceilingEntry(hash);
// 若没有对应的虚拟invoker,则默认选择treeMap中的第一个虚拟invoker
if (entry == null) {
entry = virtualInvokers.firstEntry();
}
// 返回该虚拟提供者中封装的物理invoker
return entry.getValue();
}
...
}
主要看virtualInvokers.ceilingEntry(hash)方法:
/**
* @throws ClassCastException {@inheritDoc}
* @throws NullPointerException if the specified key is null
* and this map uses natural ordering, or its comparator
* does not permit null keys
* @since 1.6
*/
//java.util.TreeMap#ceilingEntry
public Map.Entry<K,V> ceilingEntry(K key) {
return exportEntry(getCeilingEntry(key));
}
/**
* Gets the entry corresponding to the specified key; if no such entry
* exists, returns the entry for the least key greater than the specified
* key; if no such entry exists (i.e., the greatest key in the Tree is less
* than the specified key), returns {@code null}.
* 获取与指定键对应的项;如果不存在这样的项,则返回大于指定键的最小键的项;
* 如果不存在这样的条目(例如,树中的最大键小于指定的键),返回{@code null}。
*/
final Entry<K,V> getCeilingEntry(K key) {
Entry<K,V> p = root;
while (p != null) {
int cmp = compare(key, p.key);
if (cmp < 0) {
if (p.left != null)
p = p.left;
else
return p;
} else if (cmp > 0) {
if (p.right != null) {
p = p.right;
} else {
Entry<K,V> parent = p.parent;
Entry<K,V> ch = p;
while (parent != null && ch == parent.right) {
ch = parent;
parent = parent.parent;
}
return parent;
}
} else
return p;
}
return null;
}
4. 负载均衡总结
random:应用场景,其适用于提供者主机性能差别较大(性能强的主机,权重可以配置更高),几乎纯粹根据主机性能进行负载均衡的情况。
leastactive:应用场景,其适应于主机性能差别不是很大的场景。其是根据各个 invoker 任务处理数量、压力进行负载均衡。
roundrobin:和random相比它是方法级别的,而random是服务级别的,主要也是依赖权重。
consistenthash:它是方法参数级别的,前三种算法主要是基于主机性能考虑的,都是依赖权重的,而这种和主机性能关系不大。