- Sentinel 除了流量控制以外,对调用链路中不稳定的资源进行熔断降级也是保障高可用的重要措施之一。由于调用关系的复杂性,如果调用链路中的某个资源不稳定,最终会导致请求发生堆积。
- Sentinel 熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联错误。
- 当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断(默认行为是抛出 DegradeException)。
- 当访问系统失败超过一定的次数后,对该接口进行熔断的操作。
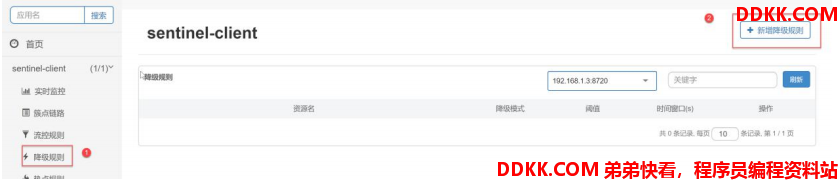
我们可以发现,降级策略分为 3 种: - RT,平均响应时间 (DEGRADE_GRADE_RT):当 1s 内持续进入 5 个请求,对应时刻的平均响应时间(秒级)均超过阈值(count,以 ms 为单位),那么在接下的时间窗口(DegradeRule 中的 timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地熔断(抛出 DegradeException)。注意 Sentinel 默认统计的 RT 上限是 4900 ms,超出此阈值的都会算作 4900 ms,若需要变更此上限可以通过启动配置项 -Dcsp.sentinel.statistic.max.rt=xxx 来配置
- 异常比例 (DEGRADE_GRADE_EXCEPTION_RATIO):当资源的每秒请求量 >= 5,并且每秒异常总数占通过量的比值超过阈值(DegradeRule 中的 count)之后,资源进入降级状态,即在接下的时间窗口(DegradeRule 中的 timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地返回。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。
- 异常数 (DEGRADE_GRADE_EXCEPTION_COUNT):当资源近 1 分钟的异常数目超过阈值之后会进行熔断。注意由于统计时间窗口是分钟级别的,若 timeWindow 小于 60s, 则结束熔断状态后仍可能再进入熔断状态。
1.RT
当 1s 内持续进入 5 个请求,对应时刻的平均响应时间(秒级)均超过阈值(count,以 ms 为单位),那么在接下的时间窗口(DegradeRule 中的 timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地熔断(抛出 DegradeException)
1.1 添加测试接口
@GetMapping("/rt")
public ResponseEntity<String> rt() throws InterruptedException {
TimeUnit.SECONDS.sleep(1);
return ResponseEntity.ok("ok") ;
}
1.2 添加降级的规则
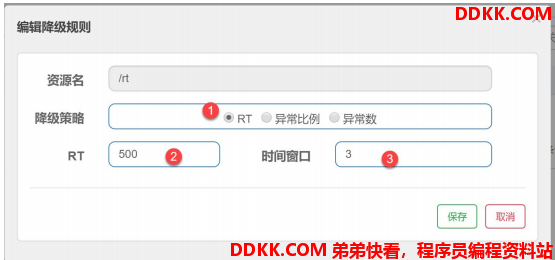
在 1s 内,进入 5 个请求,若相应时间都超过 500ms ,则在接下来的 3s ,都执行熔断的机制
1.3 测试
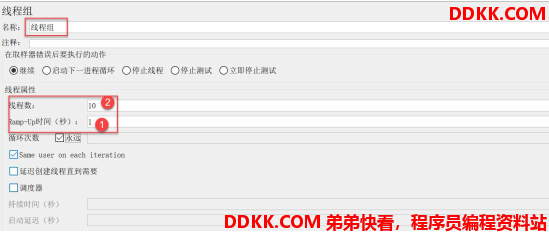
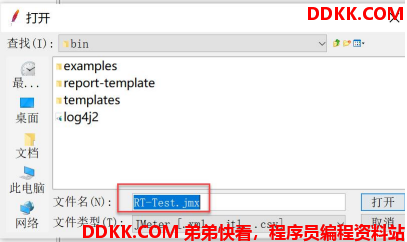
打开 Apache jmeter 。 添加一个线程组:
1 s 10 个线程同时发请求。
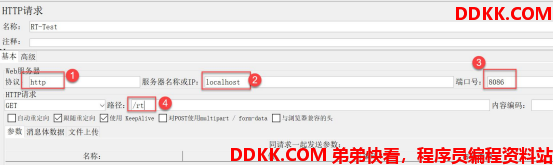
添加一个取样器:

添加我们要测试的接口:
启动测试:
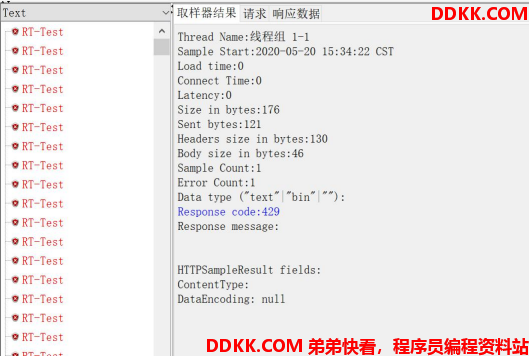
查看结果:

2.异常比例
当资源的每秒请求量 >= 5,并且每秒异常总数占通过量的比值超过阈值之后,资源进入降级状态,在接下来的时间窗口内,程序都会快速失败
2.1 添加接口
@GetMapping("/exception")
public ResponseEntity<String> exception() throws InterruptedException {
throw new RuntimeException("就是不想成功!") ;
}
2.2 添加降级规则
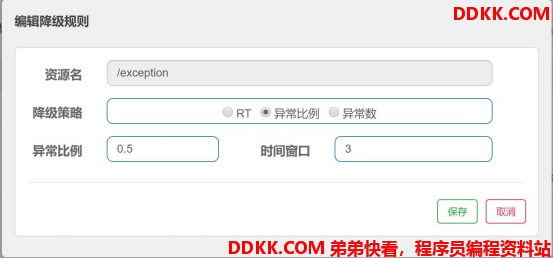
上面的配置含义是:如果/exception 的 QPS 大于 5,并且每秒钟的请求异常比例大于 0.5 的话,那么在未来的 3 秒钟(时间窗口)内,sentinel 断路器打开,该 api 接口不可用。
也就是说,如果一秒内有 10 个请求进来,超过 5 个以上都出错,那么会触发熔断,1 秒钟内这个接口不可用。
2.3 测试
打开 Jmeter,修改请求的地址:
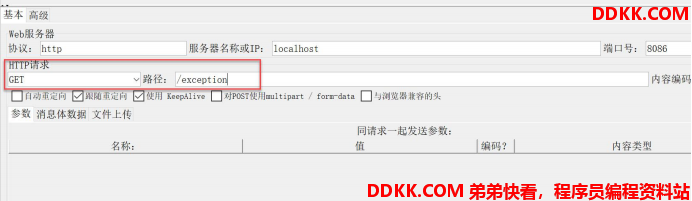
开始测试。
在浏览器打开:
http://localhost:8086/exception
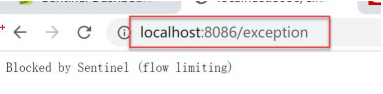
直接被熔断,停止 jemter,等待 3s,在此访问:
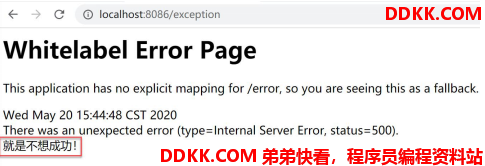
3.异常数
当策略为异常数时表示:当指定时间窗口内,请求异常数大于等于某个值时,触发降级。继续使用上面的接口测试
3.1 添加规则
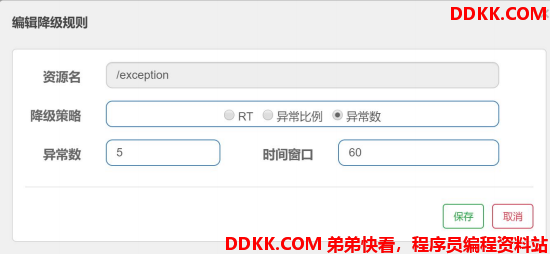
上面的规则表示:在 60 秒内,访问/exception 请求异常的次数大于等于 5,则触发降级。
3.2 测试该规则
可以看到,当第 5 次访问的时候成功触发了降级。