一,深入理解cas底层的执行原理
1,什么是cas
在讲底层原理之前,一定需要先了解JMM的内存模型以及多线程的通信机制,可以查看我写的前几篇文章。
Compare And Swap:顾名思义,就是比较与交换的意思。cas是一个指令,底层是一个无锁的算法,可以在并发场景中保证数据的原子性。
cas主要是针对某一个变量,对该值在不同线程位置的比较与交换,通过自旋的方式,实现主内存值,工作内存的旧值和工作内存的新值直接的操作,通过比较主内存的变量值和工作内存的初始值是否相等,来判断是否可以将工作内存的新值对主内存的值进行替换的操作。cas的比较与交换是一个原子操作,要么同时成功,要么同时失败。
但是cas并不是在java层面直接去实现,而是要借助于硬件底层去实现,如下面一些常见的比较与交换的方法中,都是通过调用native方法区实现的。
public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5);
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
而上面的四个参数,分别对应的是:对象,偏移量,工作内存初始值,工作内存新值
2,cas的自旋原理
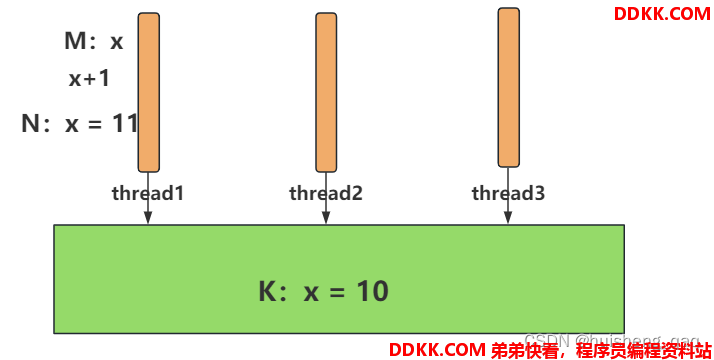
接下来先举一个例子,假设此时主内存中有一个值x等于10,然后有三个工作线程thread1,thread2,thread3,用K表示主内存中的x,用M表示工作线程中的x,用N表示工作线程修改后的值,假设此时三个工作线程同时去对这个工作线程的x的值做一个类加操作,在用cas的情况下,来讲一下底层的实现逻辑
假设此时线程thread1获取到了这个x值,此时线程thread1的M值为10,N值为11,随后进行比较操作,如果此时主内存的值还是10,那么CAS就会认为此时还没有线程改过这个值,此时M的值等于K,比较成功后再进行交换,此时工作内存的K对应的x值就是11
但是可能也会出现另外一种情况,此时线程thread1中M的值还是10,N为11,但是此时线程2先对主内存的值进行修改,就是此时K的值变成了11,在比较的时候,发现旧值M和主内存的K值不一样,那么就比较失败,那么就不能进行交换
如果此时直接将这次失败直接丢弃,那么很显然不能保证cas的原子性,cas内部是这样做的,他会携带最新的值继续自旋,此时线程1的M值变成了11,N值变成了12,M值再和K值相比,如果比较一致,则将最新的12交换,如果比较失败,则继续携带最新值轮询,一直重复下去,这样就能保证原子性了
再了解完整个代码流程之后,再来看一段AtomicInteger类的incrementAndGet()的自增操作
//var1:对象 var2:偏移量,找到对应的变量值
//var4:值1 var5:内存中的值,旧值
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
//获取旧值,内存中的值
var5 = this.getIntVolatile(var1, var2);
//比较与交换,如果var5和var1的值相对,则将最新值var5+var4写回
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
//将旧值返回,返回后进行+1操作
return var5;
}
3,cas的底层实现原理
cas是一个指令,具体如何实现的,这就得看jvm层面的逻辑了。由于这个涉及到多线程之间的通信问题,因此需要考虑线程间的可见性和有序性,在hotspot虚拟机中,由于cas本身就是一个原子指令,所以在jvm底层,就直接在方法中加了一个 #lock 的前缀指令,这样就实现了一个类似于内存屏障的功能,这样就保证了线程之间的有序性和可见性。
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
这里的第二个参数是一个偏移量,通过第一个参数的对象头加上压缩指针来确认x的位置。
在Hotspot虚拟机的底层源码中,主要的核心cas算法是通过Atomic::cmpxchg 方法来实现的。在这个方法中,第一个参数是要交换的值,第二个参数是偏移量,第三个参数是比较的值
#atomic_linux_x86.inline.hpp
inline jint Atomic::cmpxchg(jint exchange_value, volatile jint* dest, jint compare_value) {
int mp = os::is_MP();
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
首先会判断当前的执行环境是否为多处理器环境,目前一个cpu中基本是有两个处理器的
int mp = os::is_MP();
如果上面判断是一个多核处理器架构,那么就会在方法前面加一个 Lock 前缀指令,这样就保证了后面的比较与交换之间的原子性
(LOCK_IF_MP(%4)
随后通过cmpxchg方法进行比较与交换的操作,这里的%1和%3代表的是第1个和第三个参数。并且在调用这个方法的时候,在操作系统底层会进行一个总线加锁的机制,就是一把独占锁,整体操作变成一个串行操作。
cmpxchgl %1,(%3)
如果是=a,那么代表比较与交换成功,则直接将exchange_value值返回
"=a" (exchange_value)
如果是r,那么就代表比较与交换失败,那么返回的值就是内存里面的值
"r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
上面的源码是linux_x86系统的源码,不同的操作系统之间,其底层实现也不同
4,cas的缺陷以及不足
4.1,长时间自旋耗费cpu资源
cas是通过无锁算法来保证数据的同步的,synchronized,lock等是通过加锁的方式来保证数据的同步的,并且要涉及到用户态和内核态之间的来回切换,但是cas是不需要来回切换的,而是不断的自旋加配合底层硬件来解决
但是cas也会出现一个问题,在并发量比较大的时候,就会需要不断的进行自旋的操作,此时就会占用大量的cpu,从而影响整个系统的性能和效率。因此需要通过不同的场景来判断是否使用CAS
4.2,只能有一个共享变量的操作
虽然上面谈到了比较和交换的操作,但是整个流程都是围绕一个对象来进行的,如果存在多个对象就得多写几个cas的程序,这也是cas的一个缺陷。
4.4,ABA问题
依旧是下图,假设thread1获取到值,此时thread2也拿到了值,将值改成11,比较交换之后,此时主内存的值为11,但是thread3拿到值后,又通过比较交换将值改成了10,此时正好轮到thread1来进行比较交换,发现主内存的值和thread1的原始值是一样的,就认为此时还没有线程改了这个值,于是进行比较交换操作
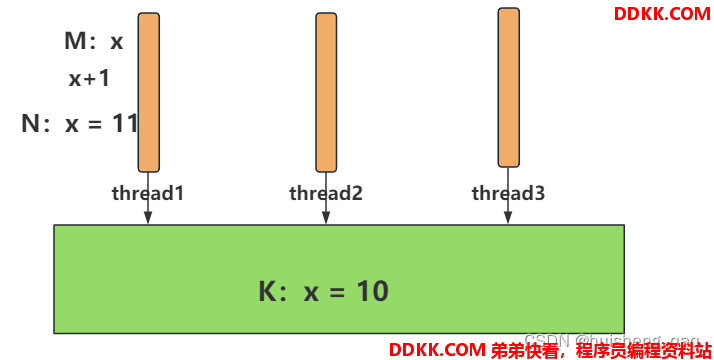
其实是已经被别的线程将值修改了,但是当前线程认为该值还没有被修改过。
如男女朋友分手了,但是女方又恋爱了,又分手,然后男方再次找到女方,发现女方还是单身,男方就认为这段时间女方没有恋爱,但是女方期间谈了多少次男方并不知情,并且可能给男方带回一个小朋友…,所以说,这种问题是很严重的
那么如何解决这种ABA问题,直接看Atomic里面是怎么解决的吧,在Atomic包下面有一个AtomicStampedReference 类,在该类中有一个静态内部类 Pair,里面除了一个对象的引用之外,另外增加了一个stamp的一个版本,这个有点类似于乐观锁,每被操作一次,版本号就加1,通过这种加版本号来保证这个变量是否被更改过。
private static class Pair<T> {
final T reference;
final int stamp;
private Pair(T reference, int stamp) {
this.reference = reference;
this.stamp = stamp;
}
static <T> Pair<T> of(T reference, int stamp) {
return new Pair<T>(reference, stamp);
}
}
其创建对象的方式如下,第一个参数表示初始值,第二个参数表示版本。
AtomicStampedReference atomicStampedReference = new AtomicStampedReference(1,1);
// 构造方法如下
public AtomicStampedReference(V initialRef, int initialStamp) {
pair = Pair.of(initialRef, initialStamp);
}
当然了,除了加版本号之外,还有一个加标记的方式解决,其原理很简单,就是只要被加载过,那么就给他一个mark标记,在atomic原子包下面就有这么一个类 AtomicMarkableReference
public class AtomicMarkableReference<V> {
private static class Pair<T> {
final T reference;
final boolean mark;
private Pair(T reference, boolean mark) {
this.reference = reference;
this.mark = mark;
}
static <T> Pair<T> of(T reference, boolean mark) {
return new Pair<T>(reference, mark);
}
}
}
在里面的静态内部类中,除了引用之外,还存在一个布尔类型的mark标志位,只有被加载过,那么就对这个标志位设置一个true。
5,通过Atomic举例cas
首先定义一个AtomicInteger的原子类,随后进行一个值更新的操作
//这里初始化为0,这个0是当前线程的初始值
AtomicInteger atomicInteger = new AtomicInteger(0);
// 0是主内存中的最新值,10是要更新的值
atomicInteger.compareAndSet(0,10);
随后再次分析这个compareAndSet方法,可以发现里面调用了这个compareAndSwapInt方法
public final boolean compareAndSet(int expect, int update) {
//比较与交换
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
如果主内存的最新值和当前线程的初始值一致,则进行更新的操作,否则携带最新值继续进行自旋的操作。
6,总结
cas比较和交换,通过jmm的java内存模型,借助于自旋的方式不断的去进行比较与交换,在每个对象的比较与交换中,主要是通过调用jvm的native本地方法去实现,从而去调用操作系统,在操作系统底层,cas借助了锁总线的串行方法来保证整个命令的原子操作,从而可以保证最终结果的一致性。
相对于其他的重锁,cas底层采用的是无锁算法,通过#lock前缀指令达到内存屏障的效果,从而保证数据的可见性,一致性和有序性,其内部需要花费的时间,也远远小于其他的重锁,如synchronized等。